
najnowsze wiadomości

Modele wizualno-językowe dla wsparcia decyzji operatora
Modele językowe i VLM-y wspierające decyzje operatorów Modele językowe i VLM-y znajdują się w centrum nowoczesnego wsparcia decyzji dla złożonych operacji. Po pierwsze, modele językowe opisują klasę systemów, które przewidują tekst i wykonują polecenia. Następnie VLM-y łączą dane wizualne z rozumowaniem tekstowym, dzięki czemu system może interpretować obrazy i odpowiadać na pytania. Na przykład modele […]

Modele wizualno-językowe do wnioskowania wielokamerowego
1. Vision-language: Definition and Role in Multi-Camera Reasoning Vision-language odnosi się do metod łączących dane wizualne i język naturalny, dzięki czemu systemy potrafią opisywać, pytać i wnioskować o scenach. Model vision-language mapuje piksele na słowa i z powrotem. Ma na celu odpowiadanie na pytania, generowanie podpisów i wspieranie podejmowania decyzji. W konfiguracjach z jedną kamerą […]

Zaawansowane modele wizualno-językowe w kontekście alarmów
VLM-y i systemy AI: architektura modelu wizualno-językowego do obsługi alarmów Wizja i AI łączą się w praktycznych systemach, które przekształcają surowe wideo w znaczenie. W tym rozdziale wyjaśniam, jak VLM-y wpisują się w systemy AI do obsługi alarmów. Najpierw przydaje się podstawowa definicja. Model wizualno-językowy łączy enkoder wizji z modelem językowym, aby powiązać obrazy i […]
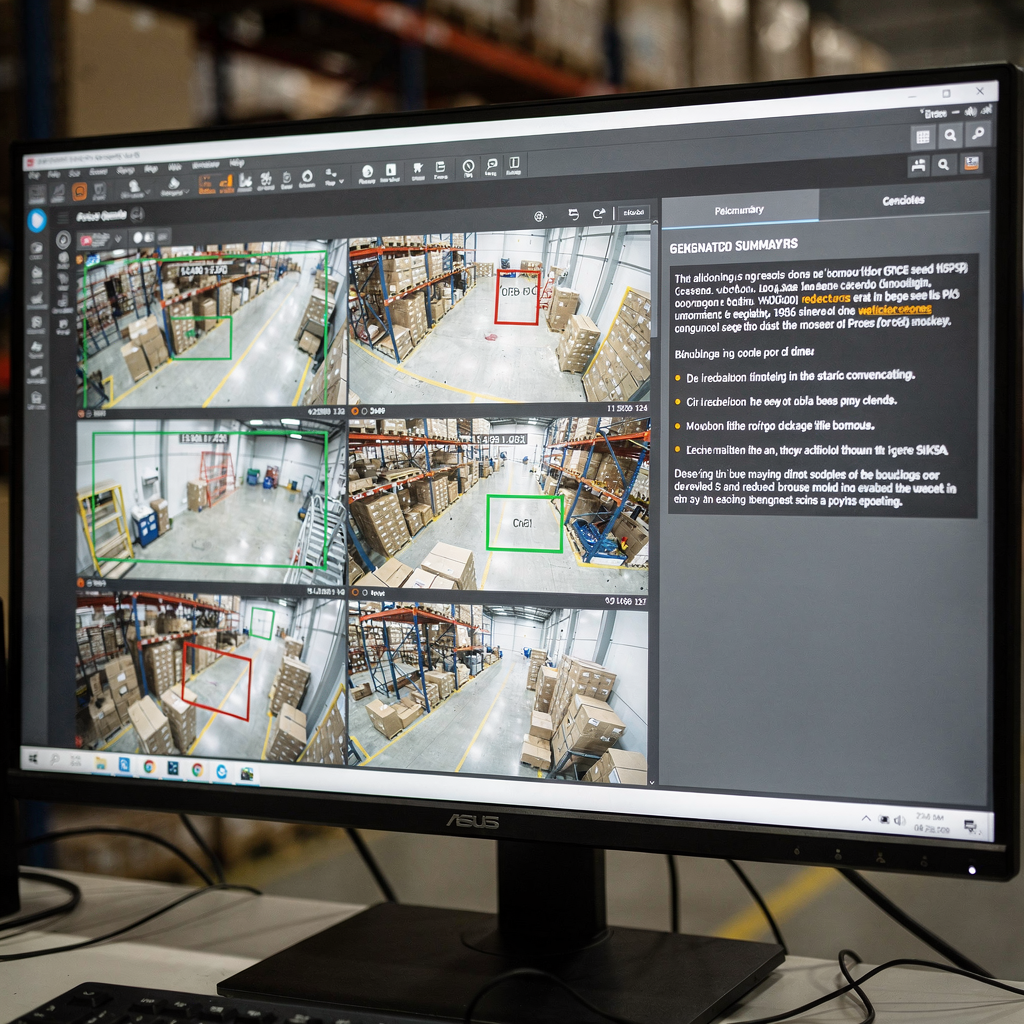
Modele języka wizualnego do podsumowywania wideo
Zrozumienie roli wideo w multimodalnej sztucznej inteligencji Po pierwsze, wideo jest najbogatszym sensorem dla wielu problemów w świecie rzeczywistym. Ponadto wideo niesie zarówno sygnały przestrzenne, jak i czasowe. Dalej, piksele wizualne, ruch i dźwięk łączą się, tworząc długie sekwencje klatek, które wymagają starannego przetwarzania. W związku z tym modele muszą uchwycić szczegóły przestrzenne i dynamikę […]

Modele wizualno-językowe do opisu wydarzeń
Jak działają modele wizualno‑językowe: przegląd multimodalnej sztucznej inteligencji Modele wizualno‑językowe działają przez połączenie danych wizualnych i rozumowania tekstowego. Najpierw enkoder wizualny wydobywa cechy z obrazów i klatek wideo. Następnie enkoder lub dekoder językowy mapuje te cechy na tokeny, które model językowy może przetwarzać. Ten wspólny proces pozwala jednoczesnemu rozumieniu i generowaniu opisów łączących elementy wizualne […]

Modele wizualno-językowe do analizy incydentów
VLM-y: rola i możliwości w rozumieniu incydentów Po pierwsze, VLM-y szybko rozwinęły się na przecięciu widzenia komputerowego i przetwarzania języka naturalnego. Ponadto VLM-y łączą sygnały wizualne i tekstowe, aby tworzyć rozumowanie multimodalne. Następnie model wizja‑język łączy cechy obrazu z tokenami językowymi, dzięki czemu maszyny mogą opisywać incydenty. Potem VLM-y reprezentują sceny, obiekty i działania w […]