
Het laatste nieuws

Vision-taalmodellen voor beslissingsondersteuning van operators
taalmodellen en vlms voor beslissingsondersteuning van operators Taalmodellen en VLMs staan centraal in moderne beslissingsondersteuning voor complexe operators. Ten eerste beschrijven taalmodellen een klasse systemen die tekst voorspellen en instructies opvolgen. Vervolgens combineren VLMs visuele invoer met tekstredenering zodat een systeem beelden kan interpreteren en vragen kan beantwoorden. Bijvoorbeeld kunnen vision-language-modellen een afbeelding koppelen aan […]

Visie-taalmodellen voor multi-camera redenering
1. Vision-language: Definitie en rol in multi-camera redenering Vision-language verwijst naar methoden die visuele input en natuurlijke taal overbruggen zodat systemen scènes kunnen beschrijven, bevragen en redeneren. Een vision-language model zet pixels om in woorden en terug. Het heeft tot doel vragen te beantwoorden, bijschriften te genereren en besluitvorming te ondersteunen. In opstellingen met één […]

Geavanceerde visuele taalmodellen voor alarmcontext
vlms and ai systems: architecture of vision language model for alarms Vision and AI meet in practical systems that turn raw video into meaning. In this chapter I explain how vlms fit into ai systems for alarm handling. First, a basic definition helps. A vision language model combines a vision encoder with a language model […]
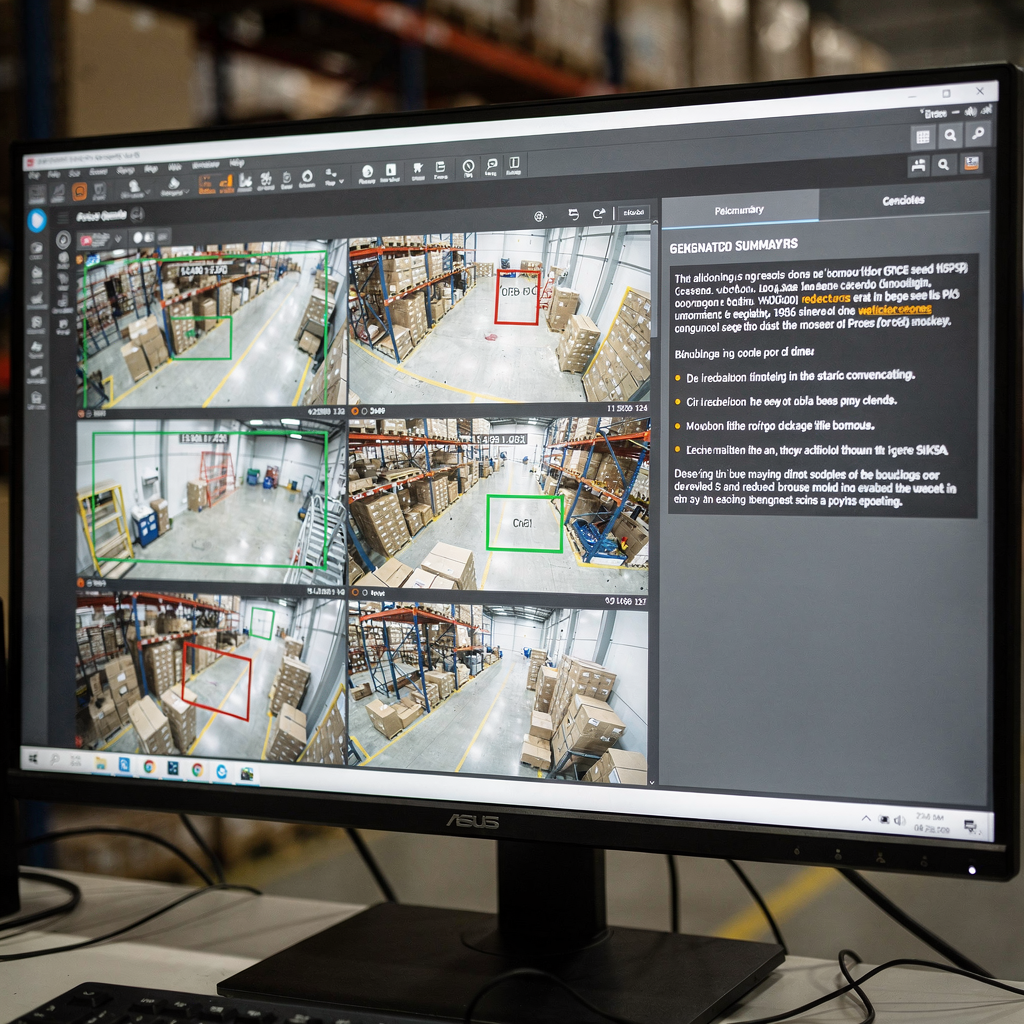
Vision-taalmodellen voor videosamenvatting
De rol van video in multimodale AI begrijpen Eerst is video de rijkste sensor voor veel problemen in de echte wereld. Daarnaast draagt video zowel ruimtelijke als temporele signalen. Vervolgens combineren visuele pixels, beweging en audio zich tot lange reeksen frames die zorgvuldig moeten worden verwerkt. Daarom moeten modellen ruimtelijke details en temporele dynamiek vastleggen. […]

Visuele taalmodellen voor het beschrijven van evenementen
Hoe vision-language-modellen werken: een overzicht van multimodale AI Vision language-modellen werken door visuele data en tekstueel redeneren met elkaar te verbinden. Eerst haalt een visuele encoder kenmerken uit afbeeldingen en videoframes. Daarna zet een taalencoder of -decoder die kenmerken om in tokens die een taalmodel kan verwerken. Dit gezamenlijke proces maakt het mogelijk dat één […]

Vision-language-modellen voor incidentbegrip
vlms: Rol en mogelijkheden bij het begrijpen van incidenten Ten eerste zijn vlms snel gegroeid op het snijvlak van computer vision en natuurlijke taal. Ook combineren vlms visuele en tekstuele signalen om multimodaal redeneren mogelijk te maken. Vervolgens koppelt een vision-language-model afbeeldingskenmerken aan taaltokens zodat machines incidenten kunnen beschrijven. Daarna representeren vlms scènes, objecten en […]