
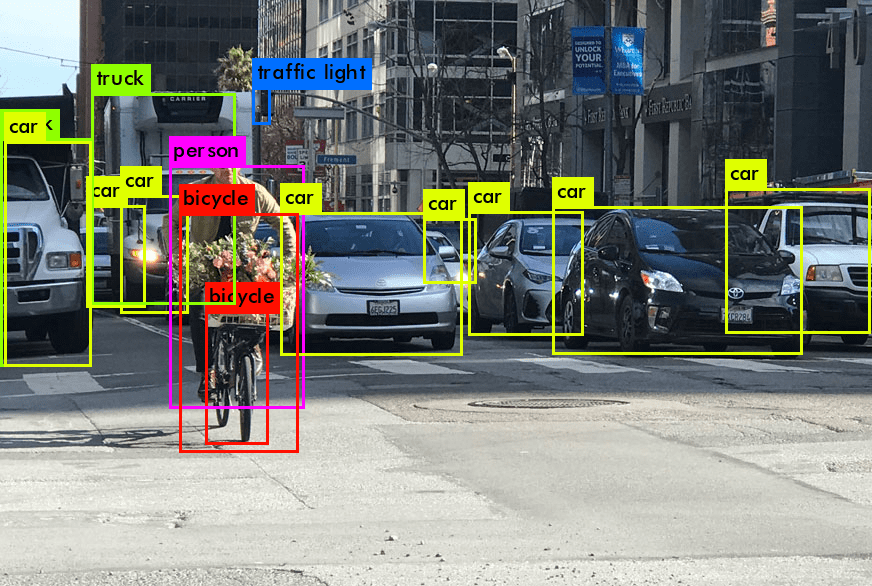
Einführung in die Bilderkennung (Computer Vision) und das YOLO-Modell
Bilderkennung (Computer Vision), ein Bereich der künstlichen Intelligenz, zielt darauf ab, Maschinen die Fähigkeit zu geben, die visuelle Welt zu interpretieren und zu verstehen. Es umfasst das Erfassen, Verarbeiten und Analysieren von Bildern oder Videos, um Aufgaben zu automatisieren, die das menschliche Sehsystem ausführen kann. Dieses sich schnell entwickelnde Feld umfasst verschiedene Anwendungen, von der Gesichtserkennung und Objektverfolgung bis hin zu fortgeschritteneren Aktivitäten wie autonomes Fahren. Die Entwicklung der Bilderkennung (Computer Vision) stützt sich stark auf große Datensätze, ausgeklügelte Algorithmen und leistungsstarke Rechenressourcen.
Ein Durchbruch in diesem Bereich war die Entwicklung des YOLO-Modells (You Only Look Once). Als ein hochmodernes Objekterkennungsmodell konzipiert, revolutionierte YOLO den Ansatz zur Erkennung von Objekten in Bildern. Traditionelle Erkennungsmodelle beinhalteten oft einen zweistufigen Prozess: zuerst das Identifizieren von Interessensgebieten und dann das Klassifizieren dieser Bereiche. Im Gegensatz dazu innovierte YOLO, indem es sowohl die Klassifizierungen als auch die Begrenzungsrahmen in einem einzigen Durchgang durch das neuronale Netzwerk vorhersagte, was den Prozess erheblich beschleunigte und die Fähigkeiten zur Echtzeiterkennung verbesserte.
Dieses Objekterkennungsmodell hat mehrere Iterationen durchlaufen, wobei jede Version neue Funktionen und Verbesserungen einführte. YOLOv8, die neueste Version von Ultralytics, baut auf dem Erfolg seiner Vorgänger wie YOLOv5 auf. Es integriert fortschrittliche maschinelle Lerntechniken, um Genauigkeit und Geschwindigkeit zu verbessern, was es zu einer beliebten Wahl für Bilderkennungsaufgaben (Computer Vision) macht. Die Open-Source-Natur der YOLO-Modelle, wie das YOLOv8-Repository auf GitHub, hat weiterhin zu ihrer weit verbreiteten Annahme und kontinuierlichen Entwicklung beigetragen.
Die Wirksamkeit von YOLO bei der Objekterkennung, Instanzsegmentierung und Klassifizierungsaufgaben hat es zu einem Grundpfeiler in Bilderkennungsprojekten (Computer Vision) gemacht. Indem es den Prozess der Identifizierung und Kategorisierung von Objekten innerhalb von Bildern vereinfacht, helfen YOLO-Modelle wie YOLOv8 Maschinen, die visuelle Welt genauer und effizienter zu verstehen.
YOLOv8: Der neue Maßstab in der Bilderkennung (computer vision)
YOLOv8 repräsentiert den Höhepunkt des Fortschritts im Bereich der Bilderkennung (computer vision) und steht als neuer Maßstab in Modellen zur Objekterkennung. Entwickelt von Ultralytics, bringt diese Version der YOLO-Modellreihe bedeutende Fortschritte gegenüber ihrem Vorgänger, YOLOv5, und früheren YOLO-Versionen. YOLOv8 ist mit einer Reihe neuer Funktionen ausgestattet, die seine Erkennungsfähigkeiten verbessern und es genauer und effizienter machen als je zuvor.
Eine der bemerkenswerten Weiterentwicklungen in YOLOv8 ist die Übernahme der ankerfreien Erkennung. Dieser neue Ansatz weicht von der traditionellen Abhängigkeit von Ankerboxen ab, die ein Grundpfeiler in früheren YOLO-Modellen waren. Die ankerfreie Erkennung vereinfacht die Architektur des Modells und verbessert seine Fähigkeit, Objektstandorte genauer vorherzusagen. Diese Verbesserung ist besonders vorteilhaft in Szenarien, in denen der Datensatz Objekte mit unterschiedlichen Formen und Größen enthält.
Das YOLOv8-Modell zeichnet sich auch bei Segmentierungsaufgaben aus, einem kritischen Aspekt der Bilderkennung (computer vision). Ob es um Objekterkennung, Instanzsegmentierung oder allgemeinere Segmentierungsmodelle geht, das YOLOv8, insbesondere das YOLOv8 Nano-Modell, zeigt eine bemerkenswerte Kompetenz. Seine Fähigkeit, verschiedene Teile eines Bildes präzise zu segmentieren und zu klassifizieren, macht es in vielfältigen Anwendungen hochwirksam, von der medizinischen Bildgebung bis zur Navigation autonomer Fahrzeuge.
Ein weiterer wichtiger Aspekt von YOLOv8 ist sein Python-Paket, das eine einfache Integration und Nutzung in Python-basierten Projekten ermöglicht. Diese Zugänglichkeit ist entscheidend, insbesondere angesichts der Beliebtheit von Python in den Gemeinschaften der Datenwissenschaft und des maschinellen Lernens. Entwickler können ein YOLOv8-Modell auf einem benutzerdefinierten Datensatz mit PyTorch, einem führenden Framework für tiefes Lernen, trainieren. Diese Flexibilität ermöglicht maßgeschneiderte Lösungen für spezifische Herausforderungen der Bilderkennung (computer vision).
Die Leistung von YOLOv8 wird weiterhin durch seine modernsten Modellleistungsmetriken gesteigert. Diese Metriken zeigen die Fähigkeit des Modells, Objekte mit hoher Genauigkeit und Geschwindigkeit zu erkennen, entscheidende Faktoren bei Echtzeitanwendungen. Zusätzlich, als Open-Source-Modell auf GitHub verfügbar, profitiert YOLOv8 von kontinuierlichen Verbesserungen und Beiträgen aus der globalen Entwicklergemeinschaft.
Zusammenfassend setzt YOLOv8 einen neuen Maßstab im Bereich der Bilderkennung (computer vision). Seine Fortschritte in der Objekterkennung, Segmentierung und allgemeinen Modellleistung machen es zu einem unschätzbaren Werkzeug für Entwickler und Forscher, die die Grenzen dessen, was in der KI-gesteuerten visuellen Interpretation möglich ist, erweitern möchten.
YOLOv8-Architektur: Das Rückgrat neuer Fortschritte in der Bilderkennung (computer vision)
Die YOLOv8-Architektur stellt einen bedeutenden Sprung im Bereich der Bilderkennung (computer vision) dar und setzt einen neuen Standard für den Stand der Technik. Als neueste Version von YOLO führt YOLOv8 mehrere Verbesserungen gegenüber seinen Vorgängern wie YOLOv5 und früheren YOLO-Versionen ein. Das Verständnis der YOLOv8-Architektur ist entscheidend für diejenigen, die das Modell für spezialisierte Objekterkennungsaufgaben trainieren möchten.
Eines der zentralen Merkmale von YOLOv8 ist sein ankerfreier Erkennungskopf, eine Abkehr vom traditionellen Ankerkastenansatz, der in früheren Versionen von YOLO verwendet wurde. Diese Änderung vereinfacht das Modell, während sie die Genauigkeit bei der Objekterkennung beibehält und in vielen Fällen sogar verbessert. YOLOv8 unterstützt eine breite Palette von Anwendungen, von der Echtzeit-Objekterkennung bis zur Bildsegmentierung.
Das YOLOv8-Modell ist auf Effizienz und Leistung ausgelegt. Das Open-Source-Modell von YOLOv8 kann mit verschiedenen Datensätzen trainiert werden, einschließlich des weit verbreiteten COCO-Datensatzes. Diese Flexibilität ermöglicht es den Benutzern, das Modell für spezifische Bedürfnisse anzupassen, ob für allgemeine Objekterkennung oder spezialisierte Aufgaben wie die Haltungsschätzung.
Die Architektur von YOLOv8 ist sowohl für Geschwindigkeit als auch für Genauigkeit optimiert, ein entscheidender Faktor bei Echtzeitanwendungen. Das Design des Modells umfasst auch Verbesserungen bei der Bildsegmentierung, was es zu einem umfassenden Modell für Erkennung und Bildsegmentierung macht. Die Ultralytics YOLO-Serie, insbesondere YOLOv8, war schon immer an der Spitze der Weiterentwicklung von Bilderkennungsmodellen (computer vision), und YOLOv8 setzt diese Tradition fort.
Für diejenigen, die mit YOLOv8 beginnen möchten, bietet das Ultralytics-Repository umfangreiche Ressourcen. Das auf GitHub verfügbare Repository bietet detaillierte Anweisungen zum Trainieren des YOLOv8-Modells, einschließlich der Einrichtung der Trainingsumgebung und des Ladens von Modellgewichten.
YOLOv8 Objekterkennungsmodell: Revolutionierung der Erkennung und Segmentierung
Das YOLOv8 Objekterkennungsmodell ist die neueste Ergänzung der YOLO-Serie, erstellt von Joseph Redmon und Ali Farhadi. Es steht an der Spitze der Fortschritte im Bereich der Bilderkennung (computer vision), und verkörpert den neuen Stand der Technik sowohl in der Objekterkennung als auch in der Bildsegmentierung. Die Fähigkeiten von YOLOv8 gehen über die bloße Objekterkennung hinaus; es zeichnet sich auch in Aufgaben wie der Instanzsegmentierung und der Echtzeiterkennung aus, was es zu einem vielseitigen Werkzeug für eine Vielzahl von Anwendungen macht.
YOLOv8 verwendet einen innovativen Ansatz zur Erkennung, indem es Funktionen integriert, die es zu einem hochpräzisen Objekterkenner machen. Das Modell beinhaltet einen ankerfreien Erkennungskopf, der den Erkennungsprozess vereinfacht und die Genauigkeit erhöht. Dies ist eine bedeutende Abkehr von der Ankerkastenmethode, die in früheren YOLO-Versionen verwendet wurde.
Das Training des YOLOv8-Modells ist ein unkomplizierter Prozess, insbesondere mit den Ressourcen, die im YOLOv8 GitHub-Repository bereitgestellt werden. Das Repository enthält detaillierte Anweisungen, wie das Modell mit einem benutzerdefinierten Datensatz trainiert werden kann, was den Benutzern ermöglicht, das Modell auf ihre spezifischen Bedürfnisse zuzuschneiden. Beispielsweise kann das Training von Modellen an einem Datensatz für 100 Epochen eine deutlich verbesserte Modellleistung erbringen, wie die Bewertungen am Validierungsset zeigen.
Darüber hinaus ist die Architektur von YOLOv8 so gestaltet, dass sie die Aufgaben der Objekterkennung und Bildsegmentierung effektiv unterstützt. Diese Vielseitigkeit zeigt sich in seiner Anwendung in verschiedenen Bereichen, von der Überwachung bis zum autonomen Fahren. YOLOv8 führt neue Funktionen ein, die seine Effizienz steigern, wie Verbesserungen in den letzten zehn Trainingsepochen, die das Lernen und die Genauigkeit des Modells optimieren.
Zusammenfassend stellt YOLOv8 einen bedeutenden Fortschritt in der YOLO-Serie und im breiteren Feld der Bilderkennung (computer vision) dar. Seine hochmoderne Architektur und Funktionen machen es zur idealen Wahl für Entwickler und Forscher, die fortschrittliche Erkennungs- und Segmentierungsmodelle in ihren Projekten implementieren möchten. Das Ultralytics-Repository ist ein ausgezeichneter Ausgangspunkt für alle, die die Fähigkeiten von YOLOv8 erkunden und in realen Szenarien einsetzen möchten.
YOLOv8 Annotationsformat: Vorbereitung der Daten für das Training
Die Vorbereitung der Daten für das Training ist ein entscheidender Schritt in der Entwicklung jedes Bilderkennungsmodells (computer vision), und YOLOv8 bildet keine Ausnahme. Das Annotationsformat von YOLOv8 spielt dabei eine zentrale Rolle, da es das Lernen und die Genauigkeit des Modells direkt beeinflusst. Eine korrekte Annotation stellt sicher, dass das Modell die verschiedenen Elemente innerhalb eines Datensatzes korrekt identifizieren und daraus lernen kann, was für eine effektive Objekterkennung und Bildsegmentierung entscheidend ist.
Das Annotationsformat von YOLOv8 ist einzigartig und unterscheidet sich von anderen Formaten, die in der Bilderkennung (computer vision) verwendet werden. Es erfordert eine präzise Detailierung von Objekten in Bildern, typischerweise durch Begrenzungsrahmen und Beschriftungen. Jedes Objekt in einem Bild wird mit einem Begrenzungsrahmen markiert, und diese Rahmen werden mit Klassen beschriftet, die das Modell identifizieren muss. Dieses Format ist entscheidend für das Training des YOLOv8-Modells, da es dem Modell hilft, den Standort und die Kategorie jedes Objekts innerhalb eines Bildes zu verstehen.
Die Vorbereitung eines Datensatzes für YOLOv8 beinhaltet die Annotation einer großen Anzahl von Bildern, was ein zeitaufwändiger Prozess sein kann. Der Aufwand ist jedoch wesentlich für eine hohe Modellleistung. Die Qualität und Genauigkeit der Annotationen wirken sich direkt auf die Lernfähigkeit des Modells und seine Fähigkeit, genaue Vorhersagen zu treffen, aus.
Für diejenigen, die ein YOLOv8-Modell trainieren möchten, ist das Verständnis und die Implementierung des richtigen Annotationsformats entscheidend. Dieser Prozess beinhaltet in der Regel die Verwendung von spezialisierten Annotationstools, die es den Benutzern ermöglichen, Begrenzungsrahmen zu zeichnen und sie entsprechend zu beschriften. Der annotierte Datensatz wird dann verwendet, um das Modell zu trainieren, indem es lernt, Objekte basierend auf den bereitgestellten Beschriftungen und Koordinaten der Begrenzungsrahmen zu erkennen und zu kategorisieren.
YOLOv8 trainieren: Eine Schritt-für-Schritt-Anleitung
Das Training von YOLOv8 ist ein Prozess, der sorgfältige Vorbereitung und Durchführung erfordert, um optimale Modellleistung zu erreichen. Der Trainingsprozess umfasst mehrere Schritte, von der Einrichtung der Umgebung bis zur Feinabstimmung des Modells auf einem spezifischen Datensatz. Hier ist eine schrittweise Anleitung zum Trainieren von YOLOv8:
- Einrichtung der Umgebung: Der erste Schritt besteht darin, die Trainingsumgebung einzurichten. Dies beinhaltet die Installation der notwendigen Software und Abhängigkeiten. YOLOv8, ein auf Python basierendes Modell, erfordert eine Python-Umgebung mit Bibliotheken wie PyTorch.
- Datenvorbereitung: Als Nächstes bereiten Sie Ihren Datensatz gemäß dem YOLOv8-Annotierungsformat vor. Dies beinhaltet das Annotieren von Bildern mit Begrenzungsrahmen und Labels, um die Objekte zu definieren, die das Modell erkennen lernen muss.
- Konfigurieren des Modells: Bevor das Training beginnt, konfigurieren Sie das YOLOv8-Modell gemäß Ihren Anforderungen. Dies könnte die Anpassung von Parametern wie Lernrate, Batch-Größe und Anzahl der Epochen beinhalten.
- Training des Modells: Mit der eingerichteten Umgebung und den vorbereiteten Daten können Sie den Trainingsprozess starten. Dies beinhaltet das Einspeisen des annotierten Datensatzes in das Modell und das Erlauben, dass es aus den Daten lernt. Das Modell passt iterativ seine Gewichte und Verzerrungen an, um Fehler bei der Erkennung zu minimieren.
- Leistungsbewertung: Nach dem Training bewerten Sie die Leistung des Modells anhand von Metriken wie Präzision, Rückruf und durchschnittliche Genauigkeit (mAP). Dies hilft zu verstehen, wie gut das Modell Objekte in Bildern erkennen und klassifizieren kann.
- Feinabstimmung: Basierend auf der Bewertung müssen Sie möglicherweise das Modell feinabstimmen. Dies könnte das erneute Training des Modells mit angepassten Parametern oder die Bereitstellung zusätzlicher Trainingsdaten beinhalten.
- Bereitstellung: Sobald das Modell trainiert und feinabgestimmt ist, ist es bereit für den Einsatz in realen Anwendungen.
Das Training eines YOLOv8-Modells erfordert Aufmerksamkeit für Details und ein tiefes Verständnis dafür, wie das Modell funktioniert. Der Aufwand lohnt sich jedoch mit einem robusten, genauen und effizienten Objekterkennungsmodell, das für verschiedene Anwendungen in der Bilderkennung (computer vision) geeignet ist.
YOLOv8 in realen Anwendungen einsetzen
Der Einsatz von YOLOv8 in realen Anwendungen ist ein entscheidender Schritt, um seine fortschrittlichen Fähigkeiten zur Objekterkennung zu nutzen. Eine erfolgreiche Implementierung übersetzt die theoretische Kompetenz des Modells in praktische, umsetzbare Lösungen in verschiedenen Branchen. Hier ist ein umfassender Leitfaden für den Einsatz von YOLOv8:
- Die richtige Plattform wählen: Der erste Schritt besteht darin zu entscheiden, wo das YOLOv8-Modell eingesetzt werden soll. Dies kann von Cloud-basierten Servern für großangelegte Anwendungen bis hin zu Edge-Geräten für Echtzeitverarbeitung vor Ort reichen, wie die End-to-End Bilderkennung (computer vision) Lösung von visionplatform.ai.
- Optimierung des Modells: Abhängig von der Einsatzplattform kann es notwendig sein, das YOLOv8-Modell für die Leistung zu optimieren. Techniken wie Modellquantisierung oder Beschneidung können verwendet werden, um die Modellgröße zu reduzieren, ohne die Genauigkeit wesentlich zu beeinträchtigen, was es für Geräte mit begrenzten Rechenressourcen geeignet macht.
- Integration in bestehende Systeme: In vielen Fällen muss das YOLOv8-Modell in bestehende Software- oder Hardwaresysteme integriert werden. Dies erfordert ein gründliches Verständnis dieser Systeme und die Fähigkeit, das YOLOv8-Modell mit geeigneten APIs oder Software-Frameworks zu verbinden.
- Testen und Validieren: Vor dem vollständigen Einsatz ist es entscheidend, das Modell in einer kontrollierten Umgebung zu testen, um sicherzustellen, dass es wie erwartet funktioniert. Dies beinhaltet die Validierung der Genauigkeit, Geschwindigkeit und Zuverlässigkeit des Modells unter verschiedenen Bedingungen.
- Bereitstellung und Überwachung: Nach dem Testen wird das Modell auf der gewählten Plattform eingesetzt. Eine kontinuierliche Überwachung ist wesentlich, um sicherzustellen, dass das Modell korrekt und effizient über die Zeit funktioniert. Dies hilft auch dabei, etwaige Probleme, die nach der Bereitstellung auftreten können, zu identifizieren und zu beheben.
- Updates und Wartung: Wie jede Software könnte auch das eingesetzte YOLOv8-Modell periodische Updates für Verbesserungen oder zur Bewältigung neuer Herausforderungen benötigen. Regelmäßige Wartung stellt sicher, dass das Modell effektiv und sicher bleibt.
Der effektive Einsatz von YOLOv8 erfordert einen strategischen Ansatz, unter Berücksichtigung von Faktoren wie dem Betriebsumfeld, Rechenbeschränkungen und Integrationsherausforderungen. Wenn dies richtig gemacht wird, kann YOLOv8 die Fähigkeiten von Systemen in Sektoren wie Sicherheit, Gesundheitswesen, Verkehr und Einzelhandel erheblich verbessern.
YOLOv8 vs YOLOv5: Vergleich von Objekterkennungsmodellen
Der Vergleich von YOLOv8 und YOLOv5 ist entscheidend, um die Fortschritte bei Objekterkennungsmodellen zu verstehen und zu entscheiden, welches Modell für eine spezifische Anwendung besser geeignet ist. Beide Modelle sind in ihren Fähigkeiten auf dem neuesten Stand der Technik, haben jedoch unterschiedliche Merkmale und Leistungskennzahlen.
- Modellarchitektur: YOLOv8 führt mehrere architektonische Verbesserungen gegenüber YOLOv5 ein. Dazu gehören Verbesserungen in den Erkennungsschichten und die Integration neuer Technologien wie ankerfreie Erkennung, die die Genauigkeit und Effizienz des Modells verbessern.
- Genauigkeit und Geschwindigkeit: YOLOv8 hat Verbesserungen in Genauigkeit und Erkennungsgeschwindigkeit im Vergleich zu YOLOv5 gezeigt. Dies ist besonders in herausfordernden Erkennungsszenarien mit kleinen oder überlappenden Objekten deutlich.
- Training und Flexibilität: Beide Modelle bieten Flexibilität beim Training und ermöglichen es den Benutzern, auf benutzerdefinierten Datensätzen zu trainieren. YOLOv8 bietet jedoch fortschrittlichere Funktionen für das Feintuning des Modells, was zu einer besseren Leistung bei spezifischen Aufgaben führen kann.
- Eignung für Anwendungen: Während YOLOv5 nach wie vor eine leistungsstarke Option für viele Anwendungen bleibt, sind die Fortschritte von YOLOv8 besser für Szenarien geeignet, in denen maximale Genauigkeit und Geschwindigkeit entscheidend sind.
- Gemeinschaft und Unterstützung: Beide Modelle profitieren von starker Gemeinschaftsunterstützung und werden weit verbreitet eingesetzt, was kontinuierliche Verbesserungen und umfangreiche Ressourcen für Entwickler sicherstellt.
Zusammenfassend bleibt YOLOv5 ein robustes und effizientes Modell für die Objekterkennung, während YOLOv8 die neuesten Fortschritte auf diesem Gebiet darstellt und verbesserte Genauigkeit und Leistung bietet. Die Wahl zwischen den beiden hängt von den spezifischen Anforderungen der Anwendung ab, einschließlich Faktoren wie Rechenressourcen, Komplexität der Erkennungsaufgabe und der Notwendigkeit einer Echtzeitverarbeitung.
Erkundung der Varianten von YOLO-Modellen
Die YOLO (You Only Look Once) Serie umfasst eine Reihe von Modellen, die für verschiedene Anwendungen in der Objekterkennung zugeschnitten sind, wobei sich jedes in Größe, Geschwindigkeit und Genauigkeit unterscheidet. Vom leichten YOLOv8n-Modell, das für Edge-Geräte konzipiert ist, bis hin zum hochgenauen YOLOv8x, das für eingehende Forschungen geeignet ist, bedienen diese Varianten unterschiedliche Rechenumgebungen und Anwendungsanforderungen. Diese Erkundung bietet einen Überblick über die verschiedenen Arten von YOLO-Modellen und hebt ihre einzigartigen Eigenschaften und optimalen Einsatzfälle hervor.
| Attribut / Modell | YOLOv8n (Nano) | YOLOv8s (Klein) | YOLOv8m (Mittel) | YOLOv8l (Groß) | YOLOv8x (X-Groß) | |
|---|---|---|---|---|---|---|
| Größe | Sehr klein | Klein | Mittel | Groß | Sehr groß | |
| Geschwindigkeit | Sehr schnell | Schnell | Mäßig | Langsam | Sehr langsam | |
| Genauigkeit | Niedriger | Mäßig | Hoch | Sehr hoch | Höchste | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Auflösung | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
Der Vergleich von Yolo mit früheren Modellen wie YOLOv5, YOLOv6, YOLOv7 und YOLOv8 zeigt, dass YOLOv8 sowohl besser als auch schneller ist als seine Vorgängerversionen.
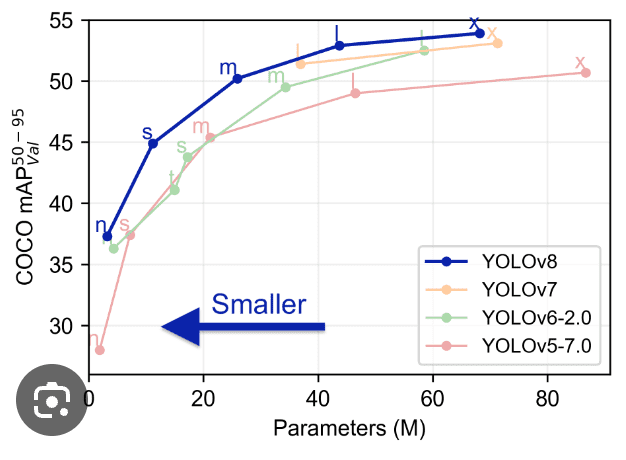
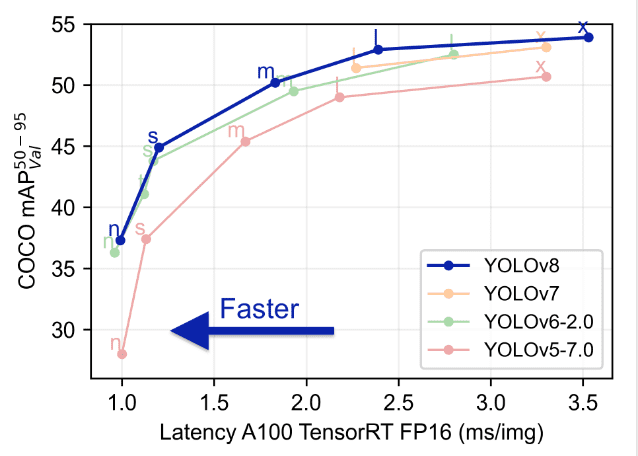
Erweiterte Funktionen in YOLOv8: Verbesserung der Modellleistung
Die Modellleistung von YOLOv8 sticht im Bereich der Bilderkennung (computer vision) hervor, dank einer Reihe von fortschrittlichen Funktionen, die seine Fähigkeiten erweitern. Diese Funktionen tragen erheblich zum Status von YOLOv8 als ein Modell der Spitzenklasse für Objekterkennung und -segmentierung bei. Ein genauerer Blick auf diese Funktionen zeigt, warum YOLOv8 eine Top-Wahl für Entwickler und Forscher ist:
- Ankerfreie Erkennung: YOLOv8 entfernt sich von traditionellen Ankerboxen zu einem ankerfreien Erkennungssystem. Dies vereinfacht die Architektur des Modells, einschließlich des YOLOv8 Nano-Modells, und verbessert seine Fähigkeit, Objektstandorte genau vorherzusagen, insbesondere bei Bildern mit unterschiedlichen Objektformen und -größen.
- Verbesserte konvolutionale Schichten: YOLOv8 führt Änderungen in seinen konvolutionalen Blöcken durch, indem es die bisherigen
6x6Konvolutionen durch3x3ersetzt. Diese Änderung verbessert die Fähigkeit des Modells, detaillierte Merkmale aus Bildern zu extrahieren und zu lernen, was die Gesamterkennungsgenauigkeit verbessert. - Mosaik-Datenerweiterung: Einzigartig für YOLOv8 ist die Implementierung der Mosaik-Datenerweiterung während des Trainings. Diese Technik fügt vier verschiedene Bilder zusammen, was die Fähigkeit des Modells verbessert, Objekte in verschiedenen Kontexten und Hintergründen zu erkennen. Allerdings schaltet YOLOv8 diese Erweiterung in den letzten zehn Trainingsepochen aus, um die Leistung zu optimieren.
- PyTorch-Integration: Als Python-Paket profitiert YOLOv8 von einer nahtlosen Integration mit PyTorch, einem führenden Framework im Bereich des maschinellen Lernens. Diese Integration vereinfacht den Prozess des Trainings und der Bereitstellung des Modells, insbesondere bei der Arbeit mit benutzerdefinierten Datensätzen.
- Objekterkennung in mehreren Maßstäben: Die Architektur von YOLOv8 ist für die Objekterkennung in mehreren Maßstäben konzipiert. Diese Funktion ermöglicht es dem Modell, Objekte unterschiedlicher Größe innerhalb eines Bildes genau zu erkennen, was es vielseitig in verschiedenen Anwendungsszenarien macht.
- Echtzeitverarbeitungsfähigkeiten: Einer der bedeutendsten Vorteile von YOLOv8 ist seine Fähigkeit zur Echtzeit-Objekterkennung. Diese Funktion ist entscheidend für Anwendungen, die eine sofortige Analyse und Reaktion erfordern, wie autonomes Fahren und Echtzeitüberwachung.
Diese erweiterten Funktionen unterstreichen die Fähigkeit von YOLOv8 als ein leistungsstarkes Werkzeug im Bereich der Bilderkennung (computer vision). Seine Kombination aus Genauigkeit, Geschwindigkeit und Flexibilität macht es zu einer ausgezeichneten Wahl für ein breites Spektrum von Anwendungen zur Objekterkennung und -segmentierung.
Erste Schritte mit YOLOv8: Von der Einrichtung bis zur Bereitstellung
Der Einstieg in YOLOv8 kann, besonders für Neulinge im Bereich der Bilderkennung (computer vision), einschüchternd erscheinen. Mit der richtigen Anleitung kann jedoch das Einrichten und Bereitstellen von YOLOv8 ein strukturierter Prozess sein. Hier ist eine schrittweise Anleitung, um mit YOLOv8 zu beginnen:
- Verstehen der Grundlagen: Bevor Sie sich mit YOLOv8 befassen, ist es entscheidend, ein grundlegendes Verständnis der Konzepte der Bilderkennung (computer vision) und der Prinzipien hinter Objekterkennungsmodellen zu haben. Dieses grundlegende Wissen hilft dabei, zu verstehen, wie YOLOv8 funktioniert.
- Einrichten der Umgebung: Der erste technische Schritt beinhaltet das Einrichten der Programmierumgebung. Dies umfasst die Installation von Python, PyTorch und anderen notwendigen Bibliotheken. Die YOLOv8-Dokumentation bietet detaillierte Anleitungen zum Einrichtungsprozess.
- Zugriff auf YOLOv8-Ressourcen: Das GitHub-Repository von YOLOv8 ist eine wertvolle Ressource. Es enthält den Code des Modells, vortrainierte Gewichte und umfangreiche Dokumentation. Sich mit diesen Ressourcen vertraut zu machen, ist entscheidend für eine erfolgreiche Implementierung.
- Training des Modells: Um YOLOv8 zu trainieren, benötigen Sie einen Datensatz. Für Anfänger ist die Verwendung eines Standarddatensatzes wie COCO ratsam. Der Trainingsprozess beinhaltet das Feinabstimmen des Modells auf Ihren spezifischen Datensatz, um dessen Leistung für Ihre Anwendung zu optimieren.
- Bewertung des Modells: Nach dem Training bewerten Sie die Leistung des Modells anhand von Standardmetriken wie Präzision, Recall und durchschnittlicher Genauigkeit (mAP). Dieser Schritt ist entscheidend, um sicherzustellen, dass das Modell Objekte genau erkennt.
- Bereitstellung: Mit einem trainierten und getesteten Modell, wie dem YOLOv8 Nano-Modell, ist der nächste Schritt die Bereitstellung. Dies könnte auf einem Server für webbasierte Anwendungen oder auf einem Edge-Gerät für die Echtzeitverarbeitung mit visionplatform.ai erfolgen.
- Kontinuierliches Lernen: Das Feld der Bilderkennung (computer vision) entwickelt sich schnell weiter. Auf dem neuesten Stand zu bleiben und kontinuierlich zu lernen, ist der Schlüssel, um YOLOv8 effektiv zu nutzen, was Sie effektiv über eine Bilderkennungsplattform (computer vision platform) tun können.
Der Einstieg in YOLOv8 umfasst eine Mischung aus theoretischem Verständnis und praktischer Anwendung. Indem Sie diesen Schritten folgen, können Sie YOLOv8 erfolgreich implementieren und in verschiedenen Aufgaben der Bilderkennung (computer vision) nutzen, um sein volles Potenzial bei der Objekterkennung und Bildsegmentierung auszuschöpfen.
Die Zukunft der Bilderkennung (computer vision): Neuerungen in YOLOv8 und darüber hinaus
Die Zukunft der Bilderkennung (computer vision) ist ungemein vielversprechend, wobei YOLOv8 als das neueste und fortschrittlichste Modell der YOLO-Serie die Führung übernimmt. Die Einführung von YOLOv8 markiert einen bedeutenden Meilenstein in der fortlaufenden Entwicklung der Bilderkennungstechnologien (computer vision) und bietet beispiellose Genauigkeit und Effizienz bei der Objekterkennung. Hier sind die Neuerungen in YOLOv8 und die Auswirkungen auf die Zukunft der Bilderkennung (computer vision):
- Technologische Fortschritte: YOLOv8 hat mehrere technologische Verbesserungen gegenüber seinen Vorgängern eingeführt. Dazu gehören effizientere konvolutionale Netzwerke, ankerfreie Erkennung und verbesserte Algorithmen für die Echtzeit-Objekterkennung.
- Erhöhte Zugänglichkeit und Anwendung: Mit YOLOv8 wird das Feld der Bilderkennung (computer vision) für eine breitere Benutzergruppe zugänglicher, einschließlich derjenigen ohne umfangreiche Programmierkenntnisse. Diese Demokratisierung der Technologie fördert Innovationen und ermutigt zu vielfältigen Anwendungen in verschiedenen Sektoren.
- Integration mit aufkommenden Technologien: Die Kompatibilität von YOLOv8 mit fortschrittlichen maschinellen Lernframeworks und seine Fähigkeit zur Integration mit anderen Spitzentechnologien, wie erweiterter Realität und Robotik, signalisieren eine Zukunft, in der Bilderkennungslösungen (computer vision) zunehmend vielseitig und leistungsfähig sind.
- Verbesserte Leistungskennzahlen: YOLOv8 hat neue Maßstäbe in der Modellleistung gesetzt, insbesondere in Bezug auf Genauigkeit und Verarbeitungsgeschwindigkeit. Diese Verbesserung ist entscheidend für Anwendungen, die eine Echtzeitanalyse erfordern, wie autonome Fahrzeuge und Technologien für intelligente Städte.
- Vorhersagen für zukünftige Entwicklungen: Blickt man nach vorne, können wir weitere Fortschritte bei Bilderkennungsmodellen (computer vision) erwarten, mit noch größerer Genauigkeit, Geschwindigkeit und Anpassungsfähigkeit. Die Integration von KI mit Bilderkennung (computer vision) wird wahrscheinlich weiterhin fortschreiten und zu ausgefeilteren und autonomen Systemen führen.
Die kontinuierliche Entwicklung von YOLOv8 und ähnlichen Modellen ist ein Beleg für die dynamische Natur des Feldes der Bilderkennung (computer vision). Mit dem Fortschritt der Technologie können wir erwarten, mehr bahnbrechende Innovationen zu sehen, die die Grenzen dessen neu definieren, was Bilderkennungssysteme (computer vision) erreichen können.
Fazit: Die Auswirkungen von YOLOv8 auf die Bilderkennung (computer vision) und KI
Zusammenfassend hat YOLOv8 einen erheblichen Einfluss auf das Gebiet der Bilderkennung (computer vision) und KI gehabt. Seine fortschrittlichen Funktionen und Fähigkeiten stellen einen bedeutenden Sprung nach vorne in der Technologie der Objekterkennung dar. Die Auswirkungen von YOLOv8s Fortschritten gehen über den technischen Bereich hinaus und beeinflussen verschiedene Industrien und Anwendungen:
- Fortschritte in der Objekterkennung: YOLOv8 hat mit seiner verbesserten Genauigkeit, Geschwindigkeit und Effizienz einen neuen Standard in der Objekterkennung gesetzt. Dies hat Auswirkungen auf eine breite Palette von Anwendungen, von Sicherheit und Überwachung bis hin zu Gesundheitswesen, Herstellung, Logistik und Umweltüberwachung.
- Demokratisierung der KI-Technologie: Indem YOLOv8 fortschrittliche Bilderkennungstechnologie (computer vision) wie das YOLOv8-Repository zugänglicher und benutzerfreundlicher macht, hat YOLOv8 die Tür für eine breitere Palette von Benutzern und Entwicklern geöffnet, um zu innovieren und KI-gesteuerte Lösungen zu schaffen.
- Verbesserte Anwendungen in der realen Welt: Die praktischen Anwendungen von YOLOv8 in realen Szenarien sind umfangreich. Seine Fähigkeit, genaue, Echtzeit-Objekterkennung zu bieten, macht es zu einem unschätzbaren Werkzeug in Bereichen wie autonomes Fahren, industrielle Automatisierung und Initiativen für intelligente Städte.
- Inspiration für zukünftige Innovationen: Der Erfolg von YOLOv8 dient als Inspiration für zukünftige Entwicklungen in der Bilderkennung (computer vision) und KI. Es bereitet den Weg für weitere Forschungen und Innovationen und erweitert die Grenzen dessen, was diese Technologien erreichen können.
Zusammenfassend hat YOLOv8 nicht nur die technischen Aspekte der Bilderkennung (computer vision) vorangebracht, sondern auch zur breiteren Evolution der KI beigetragen. Seine Auswirkungen zeigen sich in den verbesserten Fähigkeiten von KI-Systemen und den neuen Möglichkeiten, die es für Innovationen und praktische Anwendungen in verschiedenen Bereichen eröffnet. Während wir das Potenzial von KI und Bilderkennung (computer vision) weiter erforschen, wird YOLOv8 zweifellos als Meilenstein in dieser Reise des technologischen Fortschritts in Erinnerung bleiben.
Häufig gestellte Fragen zu YOLOv8
Da YOLOv8 weiterhin das Feld der Bilderkennung (computer vision) revolutioniert, tauchen zahlreiche Fragen bezüglich seiner Fähigkeiten, Anwendungen und technischen Aspekte auf. Dieser FAQ-Bereich zielt darauf ab, klare und prägnante Antworten auf einige der häufigsten Fragen über YOLOv8 zu geben. Ob Sie ein erfahrener Entwickler sind oder gerade erst anfangen, diese Antworten werden Ihr Verständnis dieses hochmodernen Objekterkennungsmodells vertiefen.
Was ist YOLOv8 und worin unterscheidet es sich von früheren YOLO-Versionen?
YOLOv8 ist die neueste Iteration in der YOLO-Serie von Echtzeit-Objektdetektoren und bietet Spitzenleistungen in Bezug auf Genauigkeit und Geschwindigkeit. Es baut auf den Fortschritten früherer Versionen wie YOLOv5 auf, mit Verbesserungen einschließlich fortschrittlicher Backbone- und Neck-Architekturen, einem ankerfreien geteilten Ultralytics-Kopf für verbesserte Genauigkeit und einem optimalen Gleichgewicht zwischen Genauigkeit und Geschwindigkeit für die Echtzeit-Objekterkennung. Es bietet auch eine Reihe von vortrainierten Modellen für verschiedene Aufgaben und Leistungsanforderungen.
Wie verbessert die ankerfreie Erkennung in YOLOv8 die Objekterkennung?
YOLOv8 verwendet einen ankerfreien Erkennungsansatz, indem es direkt die Zentren von Objekten vorhersagt, was die Modellarchitektur vereinfacht und die Genauigkeit verbessert. Diese Methode ist besonders effektiv bei der Erkennung von Objekten verschiedener Formen und Größen. Durch die Reduzierung der Anzahl von Boxvorhersagen beschleunigt es den Prozess der Nicht-Maximum-Unterdrückung, der entscheidend für die Verfeinerung der Erkennungsergebnisse ist, und macht YOLOv8 effizienter und genauer im Vergleich zu seinen Vorgängern, die Ankerboxen verwendeten.
Was sind die wichtigsten Innovationen und Verbesserungen in der Architektur von YOLOv8?
YOLOv8 führt mehrere bedeutende architektonische Innovationen ein, darunter das CSPNet-Backbone für effiziente Merkmalsextraktion und den PANet-Kopf, der die Robustheit gegen Objektverdeckung und Skalenvariationen erhöht. Seine Mosaik-Datenaugmentation während des Trainings setzt das Modell einer breiteren Palette von Szenarien aus, was seine Verallgemeinerbarkeit verbessert. YOLOv8 kombiniert auch überwachtes und unüberwachtes Lernen, was zu seiner verbesserten Erkennungsleistung bei Objekterkennungs- und Instanzsegmentierungsaufgaben beiträgt.
Um mit der Verwendung von YOLOv8 für Ihre Objekterkennungsaufgaben zu beginnen, sollten Sie zunächst das YOLOv8 Python-Paket installieren. Dann importieren Sie in Ihrem Python-Skript das YOLOv8-Modul, erstellen eine Instanz der YOLOv8-Klasse und laden die vortrainierten Gewichte. Verwenden Sie anschließend die Methode detect, um die Objekterkennung in einem Bild durchzuführen. Die Ergebnisse enthalten Informationen über erkannte Objekte, einschließlich ihrer Klassen, Vertrauenswerte und Begrenzungsrahmenkoordinaten.
Welche praktischen Anwendungen hat YOLOv8 in verschiedenen Branchen?
YOLOv8 hat vielseitige Anwendungen in verschiedenen Branchen aufgrund seiner hohen Geschwindigkeit und Genauigkeit. In autonomen Fahrzeugen unterstützt es die Echtzeit-Objektidentifikation und -klassifikation. Es wird in Überwachungssystemen für die Echtzeit-Objekterkennung und -erkennung verwendet. Einzelhändler nutzen YOLOv8 zur Analyse des Kundenverhaltens und zur Bestandsverwaltung. Im Gesundheitswesen unterstützt es die detaillierte Analyse medizinischer Bilder, was die Diagnose und Patientenversorgung verbessert.
Wie schneidet YOLOv8 im COCO-Dataset ab und was bedeutet das für seine Genauigkeit?
YOLOv8 zeigt bemerkenswerte Leistungen im COCO-Dataset, einem Standard-Benchmark für Objekterkennungsmodelle. Seine durchschnittliche Präzision (mAP) variiert je nach Modellgröße, wobei das größte Modell, YOLOv8x, die höchste mAP erreicht. Dies unterstreicht signifikante Verbesserungen in der Genauigkeit im Vergleich zu früheren YOLO-Versionen. Die hohe mAP zeigt eine überlegene Genauigkeit bei der Erkennung einer breiten Palette von Objekten unter verschiedenen Bedingungen.
Was sind die Einschränkungen von YOLOv8 und gibt es Szenarien, in denen es möglicherweise nicht die beste Wahl ist?
Trotz seiner beeindruckenden Leistung hat YOLOv8 Einschränkungen, insbesondere bei der Unterstützung von Modellen, die mit hohen Auflösungen wie 1280 trainiert wurden. Für Anwendungen, die eine hochauflösende Inferenz erfordern, ist YOLOv8 möglicherweise nicht ideal. Für die meisten Anwendungen übertrifft es jedoch frühere Modelle in Genauigkeit und Leistung. Seine ankerfreien Erkennungen und verbesserte Architektur machen es für eine breite Palette von Bilderkennungsprojekten (computer vision) geeignet.
Kann ich YOLOv8 auf einem benutzerdefinierten Dataset trainieren und welche Tipps gibt es für ein effektives Training?
Ja, YOLOv8 kann auf benutzerdefinierten Datasets trainiert werden. Ein effektives Training beinhaltet das Experimentieren mit Datenaugmentationstechniken, insbesondere Mosaikaugmentation, und das Optimieren von Hyperparametern wie Lernrate, Batch-Größe und Anzahl der Epochen. Regelmäßige Bewertungen und Feinabstimmungen sind entscheidend, um die Leistung zu maximieren. Die Wahl des richtigen Datasets und Trainingsregimes ist der Schlüssel dafür, dass das Modell gut auf neue Daten generalisiert.
Was sind die wichtigsten Schritte, um YOLOv8 in einer realen Umgebung einzusetzen?
Das Einsetzen von YOLOv8 beinhaltet die Optimierung des Modells für die Zielplattform, die Integration in bestehende Systeme und das Testen auf Genauigkeit und Zuverlässigkeit. Kontinuierliches Monitoring nach der Bereitstellung gewährleistet einen effizienten Betrieb. Bei Edge-Geräten könnte die Modell-Optimierung Quantisierung oder Beschneidung umfassen. Regelmäßige Updates und Wartungen sind wesentlich, um das Modell in verschiedenen Anwendungen effektiv und sicher zu halten.
Wie sieht die Zukunft für YOLOv8 und seine Anwendungen in der Bilderkennung aus?
Die Zukunft von YOLOv8 in der Bilderkennung (computer vision) sieht vielversprechend aus, mit Potenzial für noch größere Genauigkeit, Geschwindigkeit und Vielseitigkeit. Seine sich entwickelnde Technologie, einschließlich Objekterkennung und Instanzsegmentierung, könnte neue Anwendungen in Bereichen wie medizinischer Bildgebung, Wildtierschutz und fortschrittlicheren autonomen Systemen finden. Kontinuierliche Forschungs- und Entwicklungsanstrengungen werden wahrscheinlich die Grenzen von YOLOv8 weiter verschieben und seine Position als führendes Objekterkennungsmodell weiter festigen.