

Recherche vidéo médico-légale pour les salles de contrôle
Enquêtes médico-légales et vidéosurveillance dans les salles de contrôle Les salles de contrôle sont le centre névralgique de nombreuses enquêtes médico-légales modernes. Elles collectent des signaux en direct et enregistrés provenant des systèmes de vidéosurveillance, des systèmes de contrôle d’accès, des capteurs et des appareils connectés. En conséquence, les opérateurs disposent d’affichages situationnels consolidés et […]

Logiciel de recherche vidéo médico-légale
logiciel de recherche médico-légale : unifier les flux de vidéosurveillance Les systèmes médico-légaux modernes doivent unifier des flux fragmentés, et ils doivent le faire rapidement. De nombreux sites utilisent plusieurs fournisseurs de caméras, et chaque flux présente des formats différents. Les équipes médico-légales sont confrontées à des réseaux de caméras cloisonnés, à des VMS incompatibles […]

Modèles vision-langage pour la détection d’anomalies dans les vidéos médico-légales
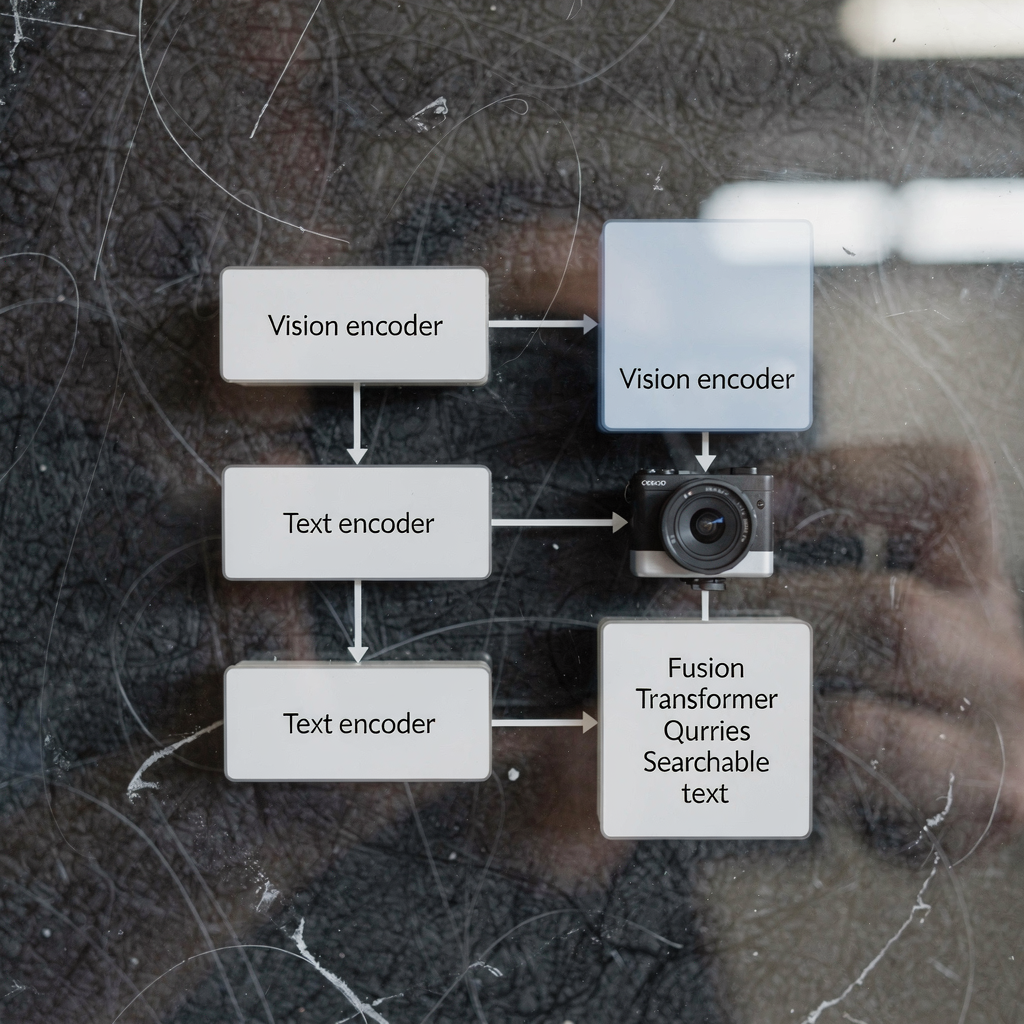
Modèles vision-langage (VLMs) Les modèles vision-langage offrent une nouvelle manière de traiter conjointement images ou vidéos et texte. D’abord, ils combinent des encodeurs de vision par ordinateur avec des encodeurs de langage. Ensuite, ils fusionnent ces représentations dans un espace latent partagé afin qu’un système unique puisse raisonner à la fois sur les signaux visuels […]

Modèles de langage visuel pour Milestone XProtect
Un modèle vision‑langage résume des heures d’enregistrement en texte concis grâce à l’IA générative La technologie des modèles vision‑langage transforme de longues séquences vidéo en récits d’incident lisibles, et cette évolution a un impact réel pour les équipes opérationnelles. Ces systèmes associent le traitement d’images et de langage pour créer des descriptions proches du langage […]
Modèles vision-langage pour l’intégration des VMS avec VLMS
modèle de langage et modèle vision-langage : introduction Un modèle de langage prédit du texte. Dans les contextes VMS, un modèle de langage associe mots, expressions et commandes à des probabilités et des actions. Un modèle vision-langage ajoute la vision à cette capacité. Il combine des entrées visuelles avec un raisonnement textuel afin que les […]

Modèles de vision-langage IA pour l’analyse de la vidéosurveillance
systèmes d’IA et IA agentique dans la gestion vidéo Les systèmes d’IA façonnent désormais la gestion vidéo moderne. D’abord, ils ingèrent les flux vidéo et les enrichissent de métadonnées. Ensuite, ils aident les opérateurs à décider de ce qui importe. Dans les environnements de sécurité, l’IA agentique va plus loin dans ces décisions. Une IA […]