
le ultime notizie

Ricerca video forense per sale di controllo
Indagini forensi e videosorveglianza nelle sale di controllo Le sale di controllo sono il centro nevralgico di molte indagini forensi moderne. Raccogliono segnali in diretta e registrati da CCTV, sistemi di controllo accessi, sensori e dispositivi smart. Di conseguenza, gli operatori vedono display situazionali consolidati e possono coordinare le risposte. La centralizzazione aiuta le squadre […]

Software di ricerca video forense
software di ricerca forense: unificare i flussi di videosorveglianza I moderni sistemi forensi devono unificare flussi frammentati, e devono farlo rapidamente. Molti siti utilizzano più fornitori di telecamere, e ogni stream video arriva in formati diversi. Le squadre forensi si trovano ad affrontare reti di telecamere isolate, VMS incompatibili e log separati che rallentano le […]

Modelli visione-linguaggio per il rilevamento di anomalie nei video forensi
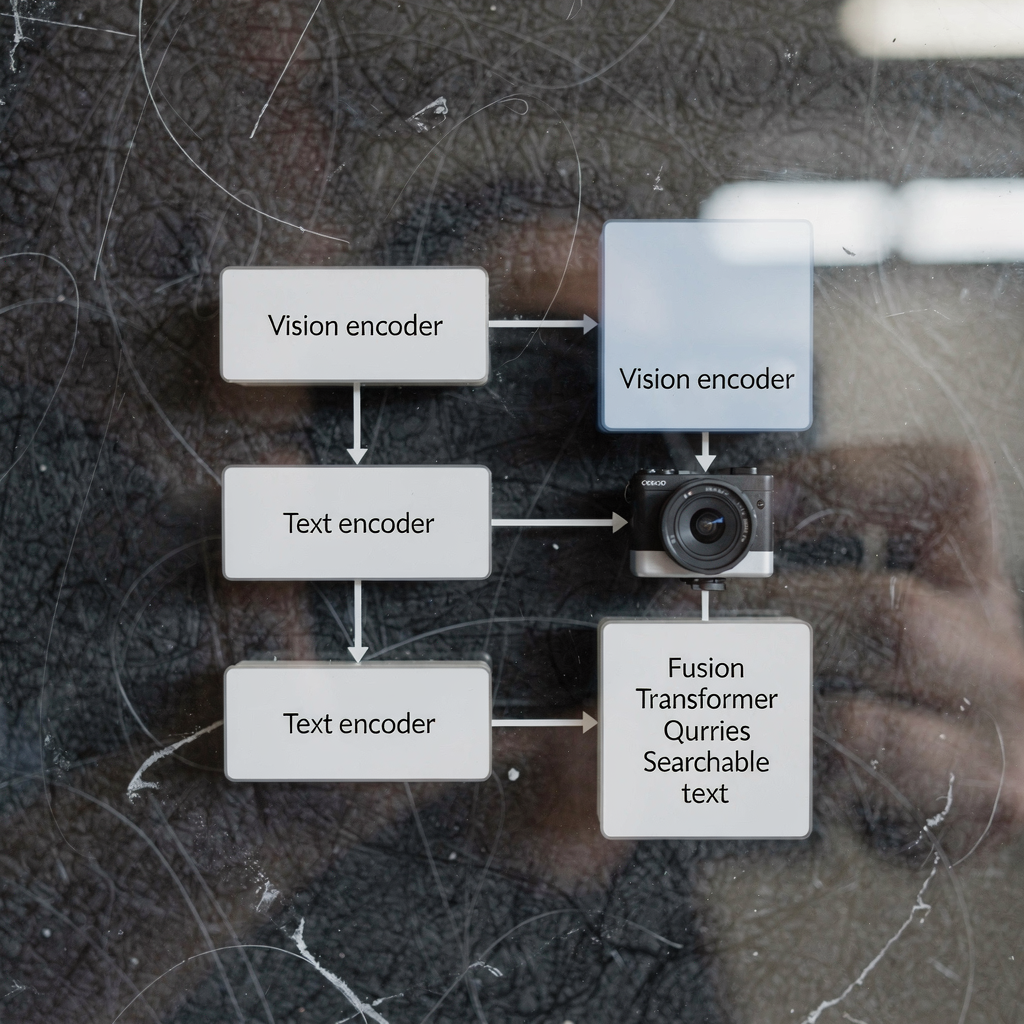
Modelli visione-linguaggio (VLM) I modelli visione-linguaggio presentano un nuovo modo di processare immagini o video e testo insieme. Prima combinano encoder di visione artificiale con encoder linguistici. Poi fondono quelle rappresentazioni in uno spazio latente condiviso in modo che un unico sistema possa ragionare su segnali visivi e linguaggio umano. Nel contesto del rilevamento di […]

Modelli di linguaggio visivo per Milestone XProtect
vision language model riassume ore di riprese in testo conciso con AI generativa La tecnologia dei modelli vision-language converte lunghe timeline video in resoconti di incidente leggibili, e questo cambiamento è importante per i team reali. Inoltre, questi sistemi combinano l’elaborazione delle immagini e del linguaggio per creare descrizioni simili a quelle umane di ciò […]
Modelli di visione e linguaggio per l’integrazione dei VMS con VLMS
modello linguistico e modello visione-linguaggio: introduzione Un modello linguistico predice testo. Nei contesti VMS un modello linguistico associa parole, frasi e comandi a probabilità e azioni. Un modello visione-linguaggio aggiunge la visione a questa capacità. Combina input visivi con ragionamento testuale in modo che gli operatori VMS possano porre domande e ricevere descrizioni leggibili dall’uomo. […]

Modelli vision-language di intelligenza artificiale per l’analisi della sorveglianza
ai systems and agentic ai in video management I sistemi AI ora plasmano la gestione video moderna. Innanzitutto, acquisiscono feed video e li arricchiscono con metadati. Successivamente, aiutano gli operatori a decidere cosa è importante. In contesti di sicurezza, l’agentic AI porta queste decisioni oltre. Un agent AI può orchestrare workflow, agire entro permessi predefiniti […]