
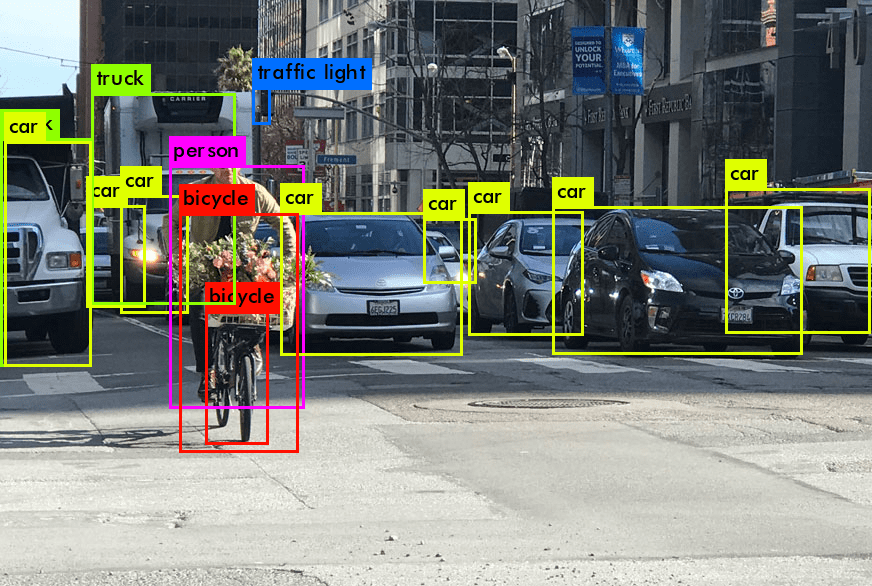
Inleiding tot Objectdetectie in Beeldherkenning (computer vision)
Objectdetectie, een fundamentele taak in beeldherkenning (computer vision), heeft de manier waarop machines de visuele wereld interpreteren revolutionair veranderd. In tegenstelling tot beeldclassificatie, waarbij het doel is om een heel beeld te classificeren, kan objectdetectie worden gebruikt om objecten binnen een afbeelding of videoframe (wat hetzelfde is als een afbeelding/foto) te identificeren en te lokaliseren. Dit proces omvat het herkennen van het specifieke object, objectlokalisatie en het bepalen van de positie ervan door middel van een begrenzingskader. Objectdetectie overbrugt de kloof tussen beeldclassificatie en complexere taken zoals beeldsegmentatie, waarbij het doel is om elk pixel van de afbeelding te labelen als behorend tot een bepaald enkel object.
De opkomst van diepgaand leren, met name het gebruik van Convolutional Neural Networks (CNN’s), heeft objectdetectie aanzienlijk vooruitgeholpen. Deze neurale netwerken verwerken en analyseren visuele gegevens effectief, waardoor ze ideaal zijn voor het detecteren van objecten in een afbeelding of video. Belangrijke ontwikkelingen zoals YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) en op regiovoorstellen gebaseerde netwerken zoals Mask R-CNN hebben de nauwkeurigheid en efficiëntie van objectdetectiesystemen verder verbeterd. Deze modellen kunnen detectie in realtime uitvoeren, een cruciale factor voor toepassingen zoals autonoom rijden of realtime bewaking.
Bovendien heeft de integratie van machine learning-technieken objectdetectiesystemen in staat gesteld om verschillende objecten in complexe omgevingen te classificeren en te segmenteren. Deze vaardigheid is van vitaal belang voor een reeks toepassingen, van voetgangersdetectie in slimme stadsinfrastructuren tot kwaliteitscontrole in de productie.
Het begrijpen van de dataset voor objectdetectie
De basis van elk succesvol objectdetectiesysteem ligt in zijn dataset. Een dataset voor objectdetectie bestaat uit afbeeldingen of video’s die zijn geannoteerd om een detector te trainen. Deze annotaties omvatten meestal begrenzingsvakken rond objecten en labels die de klasse van elk object aangeven. De kwaliteit, diversiteit en grootte van de dataset spelen een cruciale rol in de prestaties van objectdetectiemodellen. Bijvoorbeeld, grotere datasets met een grote verscheidenheid aan objecten en scenario’s stellen het neurale netwerk in staat om robuustere en meer generaliseerbare kenmerken te leren.
Datasets zoals PASCAL VOC, MS COCO en ImageNet zijn van groot belang geweest voor de vooruitgang van objectdetectie. Ze bieden een breed scala aan geannoteerde afbeeldingen, van alledaagse objecten tot specifieke scenario’s, wat helpt bij de ontwikkeling van veelzijdige en nauwkeurige detectiemodellen. Deze datasets faciliteren niet alleen de training van modellen, maar dienen ook als benchmarks om de prestaties van verschillende objectdetectiealgoritmen te evalueren en te vergelijken.
Het trainen van een model voor objectdetectie omvat ook het gebruik van technieken zoals transfer learning, waarbij een model dat vooraf getraind is op een grote dataset, wordt verfijnd met een kleinere, specifieke dataset. Deze aanpak is bijzonder voordelig wanneer de beschikbare data voor objectdetectie beperkt is of wanneer het trainen van een model vanaf nul rekenkundig duur is.
Samenvattend is de dataset een cruciaal onderdeel in objectdetectie, dat direct invloed heeft op het vermogen van een model om objecten nauwkeurig te detecteren in verschillende contexten en omgevingen. Naarmate aanverwante beeldherkenning (computer vision) taken en technologie blijven evolueren, blijft het creëren en verfijnen van datasets een belangrijk aandachtspunt voor onderzoekers en praktijkmensen in het veld.
Verkenning van objectdetectiemodellen: van traditioneel tot diepgaand leren
Objectdetectie is een taak binnen beeldherkenning (computer vision) die aanzienlijk is geëvolueerd, vooral met de vooruitgang van diepgaande leertechnologieën. Oorspronkelijk steunde objectdetectie op eenvoudigere beeldherkenningstechnieken en machine learning-algoritmen, waarbij kenmerken voor objectclassificatie handmatig werden vervaardigd en de modellen werden getraind om objecten in afbeeldingen te detecteren op basis van deze kenmerken. De introductie van diepgaand leren, met name diepe Convolutionele Neurale Netwerken (CNN’s), heeft dit veld gerevolutioneerd. CNN’s leren automatisch kenmerkhierarchieën uit de gegevens, wat een nauwkeurigere objectdetectie en semantische segmentatie mogelijk maakt. Deze overgang naar diepgaande leermodellen markeerde een aanzienlijke verbetering in de mogelijkheden voor objectdetectie.
Vroege CNN-gebaseerde objectdetectiemodellen, zoals R-CNN, gebruikten een methode voor het voorstellen van regio’s om potentiële locaties van objecten in een afbeelding te identificeren en vervolgens elke regio te classificeren. Opvolgers zoals Fast R-CNN en Faster R-CNN verbeterden dit door de detectienauwkeurigheid en verwerkingssnelheid te verhogen. Verdere ontwikkelingen leidden tot de introductie van Mask R-CNN, dat de mogelijkheden van zijn voorgangers uitbreidde door een tak toe te voegen voor pixelniveau-segmentatie, wat gedetailleerde objectlokalisatie en -herkenning mogelijk maakt.
YOLO: Real-time objectdetectie revolutioneren
In het domein van real-time objectdetectie vertegenwoordigt het YOLO (You Only Look Once) model een belangrijke doorbraak. YOLO conceptualiseert objectdetectie uniek als een enkel regressieprobleem, waarbij direct de coördinaten van de begrenzingsvakken en de klassenwaarschijnlijkheden vanuit de beeldpixels in één evaluatie worden voorspeld. Deze aanpak stelt YOLO in staat om uitzonderlijke verwerkingssnelheden te bereiken, essentieel voor toepassingen die real-time detectie vereisen zoals voetgangersdetectie en voertuigvolgsystemen in slimme steden.
De architectuur van YOLO verwerkt het hele beeld tijdens de training, waardoor het contextuele informatie over objectklassen en hun verschijning kan begrijpen. Dit contrasteert met op regiovoorstellen gebaseerde methoden, die sommige contextuele details kunnen missen. De real-time verwerkingscapaciteit van YOLO maakt het onmisbaar in scenario’s die snelle en nauwkeurige objectdetectie vereisen. De YOLO model familie, inclusief geavanceerde versies zoals YOLOv3 en YOLOv4, heeft de grenzen verlegd wat betreft detectiesnelheid en nauwkeurigheid, en heeft YOLO gevestigd als een state-of-the-art systeem in real-time objectdetectie tot aan YOLOv8.
Objectdetectie real-time videoanalyse op de drone tijdens het vliegen met visionplatform.ai en onze NVIDIA Jetson Edge computer gemonteerd op de drone. We veranderen ELKE camera in een AI-camera.
Belangrijke componenten in objectdetectie: Classificatie en begrenzingsvak
De introductie tot objectdetectie onthult twee fundamentele aspecten: classificatie en het begrenzingsvak. Classificatie verwijst naar het identificeren van de objectklasse (bijv. voetganger, voertuig) in een afbeelding. Het is een cruciale stap om onderscheid te maken tussen verschillende objectcategorieën binnen een detectiesysteem. Het begrenzingsvak, aan de andere kant, betreft het lokaliseren van het object binnen de afbeelding, meestal weergegeven door coördinaten die het object omlijnen. Samen vormen deze componenten de basis van objectdetectie en -tracking.
Objectdetectie kan modellen helpen, zoals de YOLO-familie van modellen en de Single Shot Multibox Detector (SSD), de combinatie van classificatie en begrenzingsvakken zorgt voor detectienauwkeurigheid. Deze modellen, vaak ontwikkeld en gedeeld op platforms zoals GitHub, gebruiken op diepgaand leren gebaseerde benaderingen. Ze kunnen ook worden gebruikt zonder een regel code op beeldherkenning platforms (computer vision) zoals visionplatform.ai. Ze zijn in staat om meerdere objecten in een afbeelding te detecteren en de locatie van elk object nauwkeurig te voorspellen met een begrenzingsvak eromheen. Deze dubbele aanpak is essentieel in verschillende gebruiksscenario’s van objectdetectie, variërend van gezichtsdetectie in beveiligingssystemen tot anomaliedetectie in industriële instellingen.
De rol van diepgaand leren bij objectdetectie
Methoden voor diepgaand leren hebben beeldherkenning (computer vision) en objectdetectie gerevolutioneerd. Deze methoden, voornamelijk met behulp van diepe neurale netwerken zoals CNN’s, hebben nauwkeurigere objectdetectie en semantische segmentatie mogelijk gemaakt. TensorFlow, een populaire open-source bibliotheek voor machine learning en diepgaand leren, biedt robuuste tools om diepgaande leermodellen te trainen en te implementeren voor objectdetectie.
De effectiviteit van diepgaand leren in objectdetectie kan worden waargenomen in de toepassing ervan op complexe taken zoals voetgangersdetectie en tekstdetectie. Deze modellen leren hiërarchieën van kenmerken voor nauwkeurige objectdetectie, wat een aanzienlijke verbetering is ten opzichte van traditionele machine learning-algoritmen die handmatig ontworpen kenmerken vereisten. Op diepgaand leren gebaseerde objectdetectiemodellen worden doorgaans beoordeeld op basis van hun detectienauwkeurigheid en snelheid, waardoor ze ideaal zijn voor realtime toepassingen.
Met de vooruitgang van technieken voor diepgaand leren zijn objectdetectiesystemen veelzijdiger geworden, in staat om een breed scala aan taken op het gebied van beeldherkenning (computer vision) te behandelen, waaronder objecttracking, detectie van personen en beeldherkenning. Deze vooruitgang heeft geleid tot de ontwikkeling van robuuste algoritmen voor objectdetectie die objecten betrouwbaar kunnen classificeren en lokaliseren, zelfs in uitdagende omgevingen.
Segmentatie en Objectherkenning: Verbeterde Detectie met Gedetailleerde Analyse
De introductie tot objectdetectie in beeldherkenning (computer vision) leidt vaak tot het verkennen van gerelateerde taken zoals segmentatie en objectherkenning. Terwijl objectdetectie objecten identificeert en lokaliseert binnen een afbeelding, gaat segmentatie een stap verder door de afbeelding te verdelen in segmenten om de analyse te vereenvoudigen of de representatie ervan te veranderen. Objectherkenning daarentegen, houdt in dat het specifieke object dat aanwezig is in de afbeelding wordt geïdentificeerd.
Technieken gebaseerd op diepgaand leren, vooral diepe convolutionele neurale netwerken, hebben deze gebieden aanzienlijk vooruitgeholpen. Segmentatie, in het bijzonder semantische segmentatie, is essentieel om de context te begrijpen waarbinnen objecten bestaan in afbeeldingen. Dit is cruciaal in gebruikssituaties zoals medische beeldvorming, waarbij nauwkeurige identificatie van weefsels of anomalieën essentieel is. Objectdetectie-algoritmen die segmentatie omvatten, zoals Mask R-CNN, bieden gedetailleerde inzichten door niet alleen de “omlijstende box rond” een object te lokaliseren, maar ook de exacte “vorm van het object” af te bakenen.
Het verwerken van de invoerafbeelding: De reis door objectdetectiesystemen
Het proces van objectdetectie begint met een invoerafbeelding, die verschillende stadia doorloopt binnen een detectienetwerk. Aanvankelijk wordt de afbeelding voorbewerkt om aan de vereisten van het objectdetectiemodel te voldoen. Dit kan het aanpassen van de grootte, normalisatie en augmentatie omvatten. Vervolgens wordt de afbeelding ingevoerd in een diepgaand leermodel, meestal een type model zoals CNN’s, voor kenmerkextractie.
De geëxtraheerde kenmerken worden vervolgens gebruikt om objecten te classificeren en hun locatie te voorspellen. Objectdetectie die in realtime scenario’s wordt gebruikt, zoals voetgangersdetectie of voertuigtracking, vereist dat het model de invoerafbeelding snel analyseert en nauwkeurige “voorspelde begrenzingsvakken” levert voor elk “aanwezig object”. Dit is waar modellen zoals YOLO uitblinken, en bieden snelle en efficiënte verwerking geschikt voor realtime toepassingen.
Het trainen van een model voor dergelijke complexe taken omvat een aanzienlijke hoeveelheid gegevens voor objectdetectie. Deze gegevens, meestal bestaande uit diverse afbeeldingen met geannoteerde objecten, helpen het model om verschillende objectcategorieën en hun kenmerken te leren. Populaire objectdetectiekaders zoals TensorFlow bieden tools en bibliotheken om deze modellen efficiënt te bouwen, te trainen en te implementeren. Het hele proces benadrukt de synergie tussen beeldherkenning (computer vision) en beeldverwerkingstechnieken, machine learning-algoritmen en diepgaande leermethoden, resulterend in een robuust objectdetectiesysteem.
Gebruikscases van objectdetectie in verschillende industrieën
Objectdetectie, aangedreven door op diep leren gebaseerde modellen, heeft toepassingen gevonden in diverse industrieën, elk met unieke vereisten en uitdagingen. Deze modellen worden typisch beoordeeld op basis van hun nauwkeurigheid, snelheid en het vermogen om meerdere objecten onder verschillende omstandigheden te detecteren. In de gezondheidszorg helpt objectdetectie bij het identificeren van afwijkingen in medische beeldvorming, wat aanzienlijk bijdraagt aan vroege diagnose en behandelplanning. In de detailhandel speelt het een cruciale rol bij de analyse van klantengedrag en voorraadbeheer.
Een opmerkelijke gebruikscase van objectdetectie is in de automobielindustrie, waar het cruciaal is voor de ontwikkeling van autonome voertuigen. Hier is het vermogen om twee objecten te detecteren en te onderscheiden, zoals voetgangers en andere voertuigen, van het grootste belang voor de veiligheid. Objectdetectiesystemen, die gebruik maken van geavanceerde algoritmen en neurale netwerken, stellen deze voertuigen in staat om veilig te navigeren door hun omgeving nauwkeurig te interpreteren.
TensorFlow in Object Detection: Het benutten van diepgaande leermodellen
TensorFlow, een open-source framework beschikbaar op platforms zoals GitHub, is synoniem geworden met het bouwen en implementeren van diepgaande leermodellen, vooral op het gebied van objectdetectie. Zijn uitgebreide bibliotheek stelt ontwikkelaars in staat om een model vanaf nul te bouwen of gebruik te maken van vooraf getrainde modellen voor objectdetectie. De flexibiliteit van TensorFlow in het omgaan met verschillende mechanismen voor objectvoorstellen en de efficiënte verwerking van grote datasets maken het een voorkeurskeuze voor veel ontwikkelaars.
Bij objectdetectie is de leerbenadering cruciaal. TensorFlow faciliteert de implementatie van complexe algoritmen die kunnen onderscheiden tussen ‘detectie versus classificatie’ taken, essentieel voor genuanceerde objectdetectiescenario’s. Het platform ondersteunt een breed scala aan modellen, van die welke intensieve rekenbronnen vereisen tot lichtgewicht modellen geschikt voor mobiele apparaten. Deze aanpasbaarheid zorgt ervoor dat op TensorFlow gebaseerde modellen kunnen worden ingezet in verschillende omgevingen, van servergebaseerde systemen tot randapparaten zoals de Jetson Nano Orin, Jetson NX Orin of Jetson AGX Orin, waardoor de reikwijdte en toegankelijkheid van objectdetectietechnologie wordt vergroot.
Het YOLO-model in detail verkennen
Het YOLO (You Only Look Once) model, een op diep leren gebaseerd raamwerk voor objectdetectie, vertegenwoordigt een significante verschuiving in de leerbenadering voor het detecteren van objecten. In tegenstelling tot traditionele modellen waarbij het systeem eerst potentiële regio’s voorstelt (objectvoorstel) en vervolgens elke regio classificeert, past YOLO een enkel neuraal netwerk toe op de volledige afbeelding, waarbij het begrenzingskaders en klassewaarschijnlijkheden voor meerdere objecten in één evaluatie voorspelt. Deze benadering, die zich richt op de gehele afbeelding in plaats van op afzonderlijke voorstellen, stelt YOLO in staat om objecten effectief in realtime te detecteren.
YOLO-modellen worden doorgaans beoordeeld op hun snelheid en nauwkeurigheid bij het detecteren van meerdere objecten. In scenario’s waar twee objecten dicht bij elkaar liggen, is het vermogen van YOLO om ze nauwkeurig te onderscheiden cruciaal. De architectuur van het model stelt het in staat om de context binnen een afbeelding te begrijpen, waardoor het robuust is in complexe omgevingen. Deze capaciteit is het resultaat van zijn unieke netwerkdesign, dat tijdens de voorspelling naar de gehele afbeelding kijkt, waardoor het contextuele informatie kan vastleggen die mogelijk wordt gemist wanneer men zich concentreert op delen van de afbeelding.
Gegevens voor Objectdetectie: Verzameling en Gebruik
Het succes van elk model voor objectdetectie, inclusief die gebaseerd op deep learning-frameworks zoals YOLO, hangt sterk af van de kwaliteit en hoeveelheid gegevens die gebruikt worden voor training. Het proces om een model voor objectdetectie te bouwen begint met gegevensverzameling, wat inhoudt dat een diverse set afbeeldingen wordt verzameld en geannoteerd met labels en begrenzingsvakken. Deze gegevensverzameling is een cruciale stap in de training van een model, omdat het de basis biedt waarvan het model kan leren.
De gegevens voor objectdetectie moeten een breed scala aan scenario’s en objecttypen omvatten om ervoor te zorgen dat het model goed kan generaliseren naar nieuwe, ongeziene afbeeldingen. Dit omvat rekening houden met variaties in objectgrootte, lichtomstandigheden en achtergronden. Geannoteerde datasets beschikbaar op platforms zoals GitHub bieden een waardevolle bron voor het trainen en benchmarken van objectdetectiemodellen.
In de leerbenadering voor objectdetectie wordt het model getraind om ‘object versus geen object’ te detecteren en de gedetecteerde objecten te classificeren. Deze training omvat niet alleen het herkennen van de aanwezigheid van een object, maar ook het nauwkeurig bepalen van de locatie binnen de afbeelding. Het gebruik van geavanceerde deep learning-methoden en grote, geannoteerde datasets heeft de detectienauwkeurigheid en betrouwbaarheid van objectdetectiemodellen aanzienlijk verhoogd, waardoor ze essentiële hulpmiddelen zijn geworden in verschillende beeldherkenning (computer vision) toepassingen.
Detectie versus Herkenning: De Verschillen Begrijpen
In het veld van beeldherkenning (computer vision) is het cruciaal om het verschil tussen ‘detectie versus herkenning’ te onderscheiden. Detectie houdt in dat objecten binnen een afbeelding worden gelokaliseerd, meestal met behulp van begrenzingsvakken, terwijl herkenning dieper ingaat op het identificeren van de specifieke aard of klasse van de gedetecteerde objecten. Dit onderscheid is belangrijk bij het op maat maken van beeldherkenningssystemen (computer vision) voor specifieke toepassingen. Bijvoorbeeld, terwijl een detectiesysteem voldoende kan zijn om auto’s op een weg te tellen, zou een herkenningssysteem nodig zijn om onderscheid te maken tussen automodellen.
De complexiteit van herkenningstaken vereist meestal geavanceerdere modellen in vergelijking met detectietaken. Herkenning omvat vaak niet alleen het identificeren dat een object aanwezig is, maar ook het classificeren ervan in een van de verschillende mogelijke categorieën. Dit proces vereist een meer genuanceerd begrip van de kenmerken van het object en is cruciaal in scenario’s waar gedetailleerde identificatie essentieel is, zoals het onderscheiden tussen goedaardige en kwaadaardige cellen in medische beeldvorming.
Conclusie en toekomstige trends in objectdetectie
Ter afsluiting is het duidelijk dat objectdetectie een snel evoluerend veld is, met voortdurend nieuwe ontwikkelingen. Toekomstige trends zullen waarschijnlijk gericht zijn op het verbeteren van nauwkeurigheid, snelheid en het vermogen om complexere scènes te hanteren. De integratie van AI met andere technologieën zoals augmented reality en het Internet der Dingen (IoT) opent nieuwe horizonten voor toepassingen van objectdetectie.
Bovendien stimuleert de vraag naar efficiëntere en minder data-intensieve modellen onderzoek naar few-shot learning en onbegeleide leerbenaderingen. Deze methoden zijn gericht op het effectief trainen van modellen met beperkte gegevens, wat een van de belangrijke uitdagingen in het veld aanpakt. Naarmate de technologie vordert, kunnen we meer innovatieve oplossingen verwachten, die de mogelijkheden en toepassingen van objectdetectie in verschillende sectoren verbeteren, van gezondheidszorg tot autonome voertuigen.
De voortdurende verfijning van modellen en algoritmen in objectdetectie zal ongetwijfeld bijdragen aan geavanceerdere en nauwkeurigere systemen, waardoor het belang ervan in het domein van beeldherkenning (computer vision) en daarbuiten wordt versterkt.
FAQ over Objectdetectie: De Kernconcepten Begrijpen
Duik in de essentie van objectdetectie met onze FAQ-sectie. Hier behandelen we veelgestelde vragen, waarbij we verduidelijken hoe objectdetectie werkt, de toepassingen ervan en de technologie erachter. Of je nu nieuw bent in beeldherkenning (computer vision) of je kennis wilt verfijnen, deze antwoorden bieden beknopte inzichten in de spannende wereld van objectdetectie.
Wat is Objectdetectie?
Objectdetectie is een oplossing voor beeldherkenning (computer vision) die objecten identificeert en lokaliseert binnen een afbeelding of video. Het herkent niet alleen de aanwezigheid van objecten, maar geeft ook hun posities aan met begrenzingsvakken. Het systeem kent vertrouwensniveaus toe aan voorspellingen, wat de waarschijnlijkheid van nauwkeurigheid aangeeft. Objectdetectie verschilt van beeldherkenning, die een klasse label toewijst aan een afbeelding, en beeldsegmentatie, die objecten op pixelniveau identificeert.
Hoe Werkt Objectdetectie?
Objectdetectie omvat over het algemeen twee fasen: het detecteren van potentiële objectregio’s (Region of Interest, of RoI) en vervolgens het classificeren van deze regio’s. Op diep leren gebaseerde benaderingen, vooral met behulp van neurale netwerken zoals Convolutional Neural Networks (CNNs), zijn gebruikelijk. Modellen zoals R-CNN, YOLO en SSD analyseren eerst de afbeelding om RoI’s te vinden en classificeren vervolgens elk RoI in objectcategorieën, vaak met behulp van kenmerken die zijn geleerd tijdens training op datasets zoals COCO of ImageNet.
Wat zijn de Typen Objectdetectiemodellen?
Populaire objectdetectiemodellen omvatten R-CNN en zijn varianten (Fast R-CNN, Faster R-CNN en Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) en CenterNet. Deze modellen verschillen in hun benadering van het identificeren van RoI’s en het classificeren ervan. R-CNN-modellen gebruiken regiovoorstellen, terwijl YOLO en SSD rechtstreeks begrenzingsvakken voorspellen vanuit de afbeelding, wat de snelheid en efficiëntie verbetert.
Wat is het Verschil Tussen Objectdetectie en Objectherkenning?
Objectdetectie en objectherkenning zijn verschillende taken. Objectdetectie omvat het lokaliseren van objecten binnen een afbeelding en het identificeren van hun grenzen, meestal met begrenzingsvakken. Objectherkenning gaat een stap verder door niet alleen te lokaliseren, maar ook de objecten te classificeren in vooraf gedefinieerde categorieën, zoals het onderscheiden tussen verschillende soorten dieren, voertuigen of andere items.
Hoe worden Objectdetectiemodellen Getraind?
Het trainen van objectdetectiemodellen omvat het voeden van een neuraal netwerk met gelabelde afbeeldingen. Deze afbeeldingen zijn geannoteerd met begrenzingsvakken rond objecten en hun overeenkomstige klasse labels. Het neurale netwerk leert patronen en kenmerken te herkennen uit deze trainingsafbeeldingen. De effectiviteit van de training hangt af van de diversiteit en grootte van de dataset, waarbij grotere, gevarieerde datasets leiden tot nauwkeurigere en generaliseerbare modellen. Modellen worden vaak getraind met behulp van frameworks zoals TensorFlow of PyTorch.
Wat zijn de Toepassingen van Objectdetectie?
Objectdetectie wordt veel gebruikt in verschillende velden. In beveiliging en bewaking helpt het bij gezichtsdetectie en het monitoren van activiteiten. In de detailhandel helpt het bij het analyseren van klantgedrag en het beheren van voorraden. In autonome voertuigen is het cruciaal voor het identificeren van obstakels en veilig navigeren. Objectdetectie vindt ook toepassingen in de gezondheidszorg voor het identificeren van afwijkingen in medische afbeeldingen, en in de landbouw voor het monitoren van gewassen en plagen.
Wat is YOLO in Objectdetectie?
YOLO (You Only Look Once) is een populair objectdetectiemodel bekend om zijn snelheid en efficiëntie. In tegenstelling tot traditionele modellen die een afbeelding in delen verwerken, onderzoekt YOLO de hele afbeelding in één keer, waardoor het aanzienlijk sneller is. Dit maakt het ideaal voor toepassingen voor real-time objectdetectie. YOLO heeft verschillende versies, waarbij YOLOv5 en YOLOv8 de meest recente zijn, die verbeteringen bieden in nauwkeurigheid en snelheid.
Hoe Nauwkeurig zijn Objectdetectiemodellen?
De nauwkeurigheid van objectdetectiemodellen varieert afhankelijk van hun architectuur en de kwaliteit van de trainingsgegevens. Modellen zoals YOLOv4 en YOLOv5 tonen hoge nauwkeurigheid, vaak met precisiepercentages boven de 90% onder ideale omstandigheden. De nauwkeurigheid wordt gemeten met behulp van metrieken zoals mAP (mean Average Precision) en IoU (Intersection over Union). De mAP voor topmodellen op standaarddatasets zoals MS COCO kan zo hoog zijn als 60-70%.
Wat is de Rol van Convolutional Neural Networks in Objectdetectie?
Convolutional Neural Networks (CNNs) spelen een cruciale rol in objectdetectie, voornamelijk in kenmerkextractie. Ze verwerken afbeeldingen door convolutielagen om belangrijke kenmerken te leren en te identificeren, die cruciaal zijn voor het detecteren van objecten. Modellen zoals R-CNN, Faster R-CNN en SSD gebruiken CNNs vanwege hun efficiëntie in het omgaan met afbeeldingsgegevens, wat de nauwkeurigheid en snelheid van objectdetectie aanzienlijk verbetert.
Hoe te Beginnen met het Bouwen van een Objectdetectiemodel?
Om te beginnen met het bouwen van een objectdetectiemodel, definieer eerst de objecten die je wilt detecteren. Verzamel en annoteer een dataset met afbeeldingen die deze objecten bevatten. Gebruik tools zoals TensorFlow of PyTorch om een model op deze dataset te trainen. Begin met een eenvoudige architectuur zoals SSD of YOLO voor een gemakkelijkere implementatie. Experimenteer met verschillende configuraties en hyperparameters om de prestaties van je model te optimaliseren.