
die neuesten Nachrichten
Vision-Language-Modelle für die VMS-Integration mit VLMS
Sprachmodell und Vision-Language-Modell: Einführung Ein Sprachmodell sagt Text voraus. In VMS-Kontexten ordnet ein Sprachmodell Wörter, Phrasen und Befehle Wahrscheinlichkeiten und Aktionen zu. Ein Vision-Language-Modell ergänzt diese Fähigkeit um visuelle Eingaben. Es kombiniert visuelle Daten mit textueller Verarbeitung, sodass VMS-Bediener Fragen stellen und menschenlesbare Beschreibungen erhalten können. Dieser Unterschied zwischen reinen Textmodellen und multimodalen VLMs ist […]

KI-Vision-Language-Modelle für Überwachungsanalysen
KI-Systeme und agentische KI im Videomanagement KI-Systeme prägen heute das moderne Videomanagement. Zuerst nehmen sie Video‑Feeds auf und reichern diese mit Metadaten an. Danach helfen sie Bedienkräften zu entscheiden, was relevant ist. In Sicherheitsumgebungen gehen agentische KI‑Systeme diese Entscheidungen einen Schritt weiter. Ein KI‑Agent kann Workflows orchestrieren, innerhalb vordefinierter Berechtigungen handeln und Eskalationsregeln folgen. Beispielsweise […]

Visuelle Sprachmodelle zur Entscheidungsunterstützung von Operatoren
sprachmodelle und vlms für die Entscheidungsunterstützung von Operatoren Sprachmodelle und VLMs stehen im Zentrum moderner Entscheidungsunterstützung für komplexe Operatoren. Zunächst beschreiben Sprachmodelle eine Klasse von Systemen, die Text vorhersagen und Anweisungen folgen. VLMs kombinieren visuelle Eingaben mit textbasiertem Denken, sodass ein System Bilder interpretieren und Fragen dazu beantworten kann. Zum Beispiel können Vision-Language-Modelle ein Bild […]

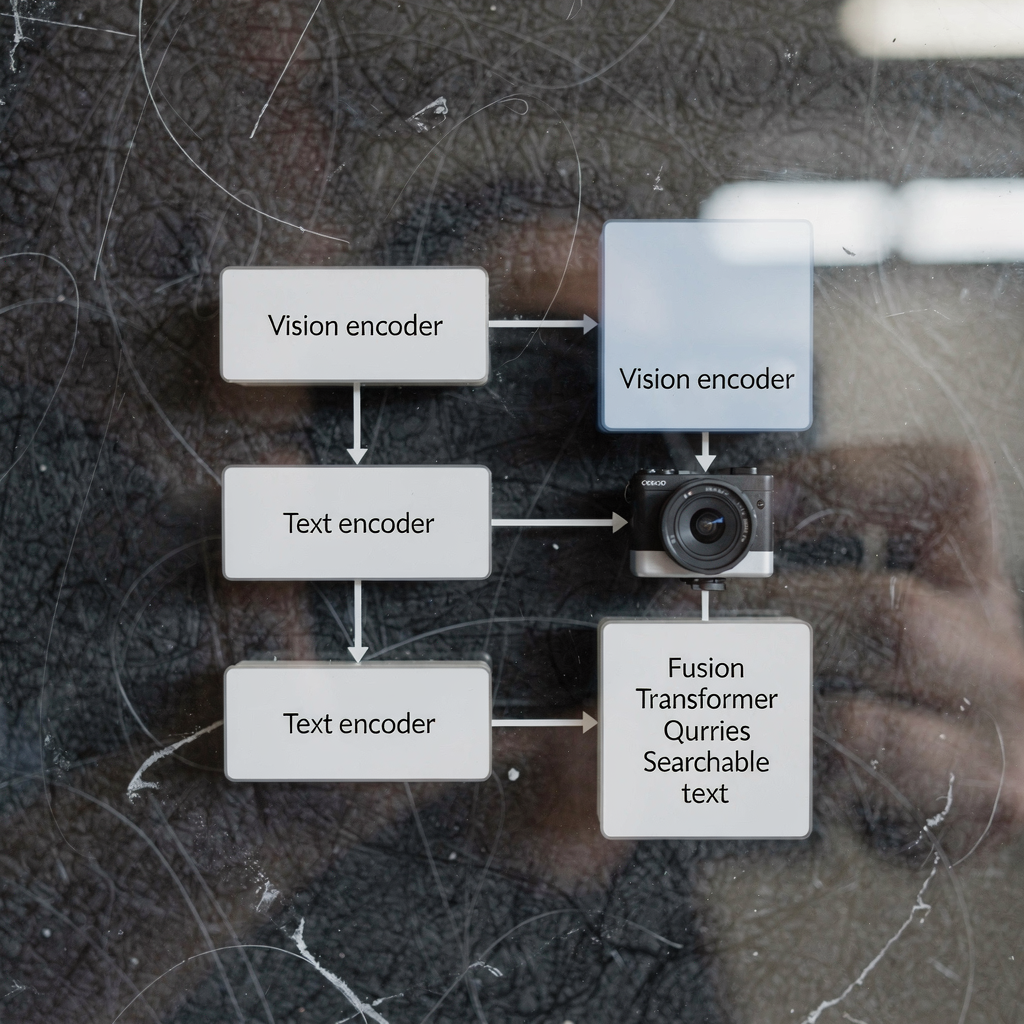
Fortgeschrittene Vision-Sprachmodelle für Alarmkontexte
VLMs und KI-Systeme: Architektur eines Vision-Language-Modells für Alarme Vision und KI treffen in praktischen Systemen aufeinander, die rohe Videoaufnahmen in Bedeutung verwandeln. In diesem Kapitel erkläre ich, wie VLMs in KI-Systeme für Alarmbearbeitung passen. Zuerst hilft eine grundlegende Definition. Ein Vision-Language-Modell kombiniert einen Vision-Encoder mit einem Sprachmodell, um Bilder und Wörter zu verknüpfen. Der Vision-Encoder […]
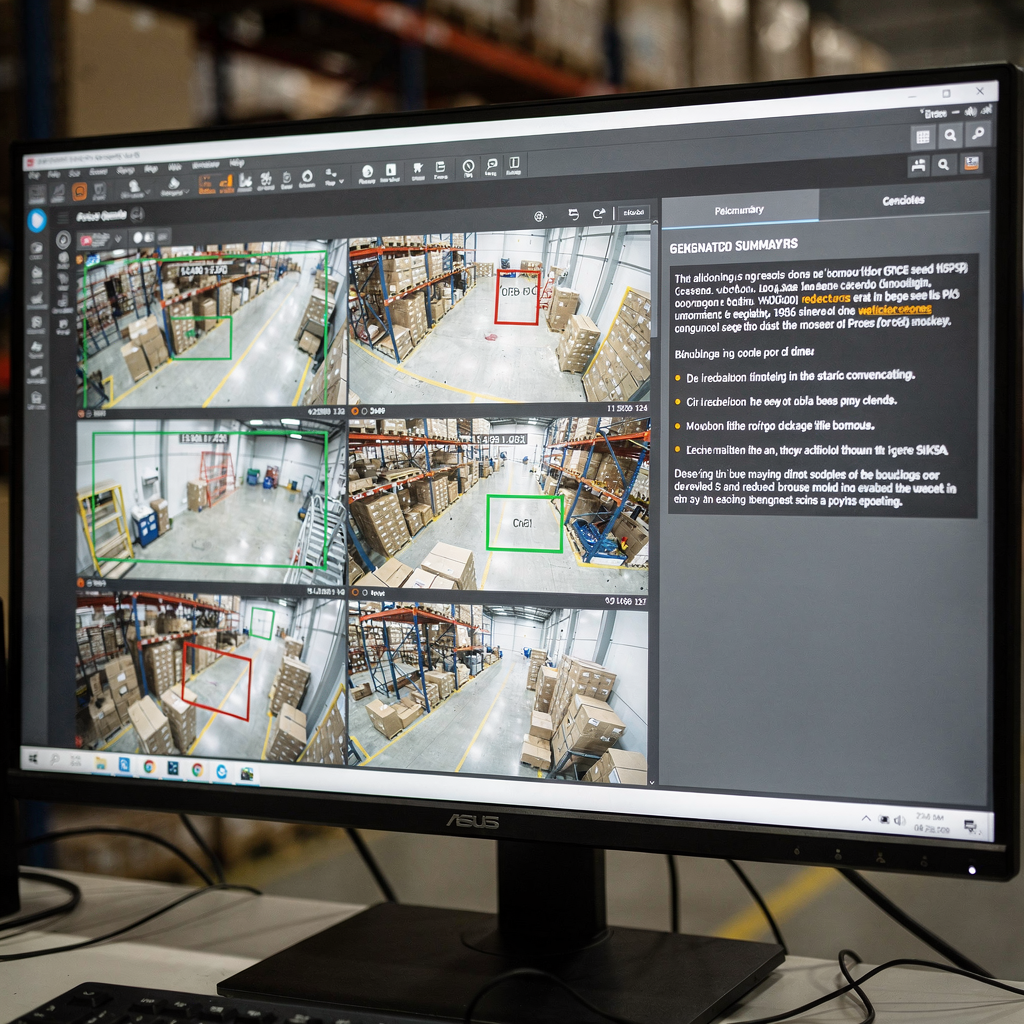
Vision-Language-Modelle für die Videozusammenfassung
Die Rolle von Video im multimodalen KI-Kontext verstehen Erstens ist Video der reichhaltigste Sensor für viele reale Probleme. Außerdem trägt Video sowohl räumliche als auch zeitliche Signale. Weiterhin kombinieren visuelle Pixel, Bewegung und Audio zu langen Bildsequenzen, die sorgfältig behandelt werden müssen. Daher müssen Modelle räumliche Details und zeitliche Dynamik erfassen. Darüber hinaus müssen sie […]

Visuelle Sprachmodelle zur Ereignisbeschreibung
Wie Vision-Language-Modelle funktionieren: Ein Überblick über multimodale KI Vision-Language-Modelle funktionieren, indem sie visuelle Daten und textuelle Schlussfolgerungen verbinden. Zuerst extrahiert ein visueller Encoder Merkmale aus Bildern und Videoframes. Dann mappt ein Sprachencoder oder -decoder diese Merkmale in Tokens, die ein Sprachmodell verarbeiten kann. Dieser gemeinsame Prozess ermöglicht es außerdem einem einzelnen Modell, Beschreibungen zu verstehen […]