
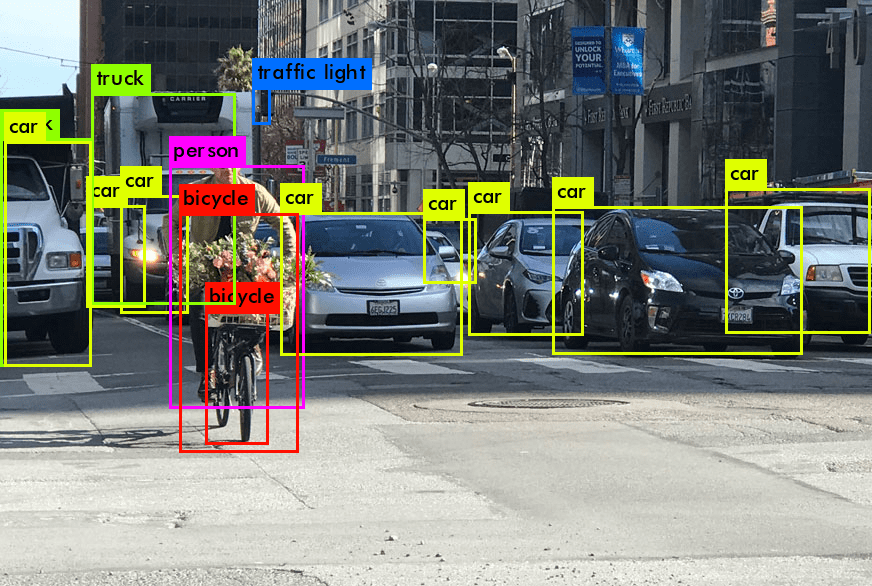
Introducción a la detección de objetos en el reconocimiento de imágenes (computer vision)
El uso de la detección de objetos, una tarea fundamental del reconocimiento de imágenes (computer vision), ha revolucionado la manera en que las máquinas interpretan el mundo visual. A diferencia de la clasificación de imágenes, donde el objetivo es clasificar una imagen completa, la detección de objetos se puede utilizar para identificar y localizar objetos dentro de una imagen o cuadro de video (que es lo mismo que una imagen / foto). Este proceso incluye reconocer el objeto específico, localizar el objeto y determinar su posición mediante un cuadro delimitador. La detección de objetos cierra la brecha entre la clasificación de imágenes y tareas más complejas como la segmentación de imágenes, donde el objetivo es etiquetar cada píxel de la imagen como perteneciente a un objeto particular.
La aparición del aprendizaje profundo, particularmente el uso de Redes Neuronales Convolucionales (CNNs), ha avanzado significativamente la detección de objetos. Estas redes neuronales procesan y analizan eficazmente los datos visuales, haciéndolas ideales para detectar objetos en una imagen o video. Desarrollos clave como YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) y redes basadas en propuestas de regiones como Mask R-CNN han mejorado aún más la precisión y eficiencia de los sistemas de detección de objetos. Estos modelos pueden realizar detecciones en tiempo real, un factor crucial para aplicaciones como la conducción autónoma o la vigilancia en tiempo real.
Además, la integración de técnicas de aprendizaje automático ha permitido que los sistemas de detección de objetos clasifiquen y segmenten varios objetos en entornos complejos. Esta capacidad es vital para una variedad de aplicaciones, desde la detección de peatones en infraestructuras de ciudades inteligentes hasta control de calidad en la fabricación.
Entendiendo el conjunto de datos para la detección de objetos
La base de cualquier sistema de detección de objetos exitoso radica en su conjunto de datos. Un conjunto de datos para la detección de objetos consiste en imágenes o videos anotados para entrenar un detector. Estas anotaciones típicamente incluyen cajas delimitadoras alrededor de los objetos y etiquetas que indican la clase de cada objeto. La calidad, diversidad y tamaño del conjunto de datos juegan un papel crucial en el rendimiento de los modelos de detección de objetos. Por ejemplo, conjuntos de datos más grandes con una amplia variedad de objetos y escenarios permiten que la red neuronal aprenda características más robustas y generalizables.
Conjuntos de datos como PASCAL VOC, MS COCO e ImageNet han sido instrumentales en el avance de la detección de objetos. Proporcionan una amplia gama de imágenes anotadas, desde objetos cotidianos hasta escenarios específicos, ayudando en el desarrollo de modelos de detección versátiles y precisos. Estos conjuntos de datos no solo facilitan el entrenamiento de modelos, sino que también sirven como puntos de referencia para evaluar y comparar el rendimiento de varios algoritmos de detección de objetos.
Entrenar un modelo para la detección de objetos también implica usar técnicas como el aprendizaje por transferencia, donde un modelo preentrenado en un conjunto de datos grande se ajusta con un conjunto de datos más pequeño y específico. Este enfoque es particularmente beneficioso cuando los datos disponibles para la detección de objetos son limitados o cuando entrenar un modelo desde cero es computacionalmente costoso.
En resumen, el conjunto de datos es un componente crucial en la detección de objetos, influyendo directamente en la capacidad de un modelo para detectar objetos con precisión en diferentes contextos y entornos. A medida que las tareas y la tecnología relacionadas con el reconocimiento de imágenes (computer vision) continúan evolucionando, la creación y refinamiento de conjuntos de datos siguen siendo un enfoque clave para investigadores y profesionales en el campo.
Explorando modelos de detección de objetos: desde los tradicionales hasta el aprendizaje profundo
La detección de objetos es una tarea de reconocimiento de imágenes (computer vision) que ha evolucionado significativamente, especialmente con el avance de las tecnologías de aprendizaje profundo. Originalmente, la detección de objetos se basaba en técnicas de reconocimiento de imágenes más simples y algoritmos de aprendizaje automático, donde las características para la clasificación de objetos se elaboraban manualmente y los modelos se entrenaban para detectar objetos en imágenes basadas en estas características. La introducción del aprendizaje profundo, particularmente las Redes Neuronales Convolucionales profundas (CNN), revolucionó este campo. Las CNN aprenden automáticamente jerarquías de características a partir de los datos, lo que permite una detección de objetos más precisa y una segmentación semántica. Esta transición a modelos de aprendizaje profundo marcó una mejora significativa en las capacidades de detección de objetos.
Los primeros modelos de detección de objetos basados en CNN, como R-CNN, empleaban un método de propuesta de regiones para identificar ubicaciones potenciales de objetos en una imagen y luego clasificaban cada región. Sucesores como Fast R-CNN y Faster R-CNN mejoraron esto al aumentar la precisión de detección y la velocidad de procesamiento. Desarrollos posteriores llevaron a la introducción de Mask R-CNN, que extendió las capacidades de sus predecesores al agregar una rama para la segmentación a nivel de píxel, facilitando la localización y reconocimiento detallado de objetos.
YOLO: Revolucionando la detección de objetos en tiempo real
En el ámbito de la detección de objetos en tiempo real, el modelo YOLO (You Only Look Once) representa un avance significativo. YOLO conceptualiza de manera única la detección de objetos como un único problema de regresión, prediciendo directamente las coordenadas del cuadro delimitador y las probabilidades de clase desde los píxeles de la imagen en una sola evaluación. Este enfoque permite que YOLO alcance velocidades de procesamiento excepcionales, esenciales para aplicaciones que requieren detección en tiempo real como la detección de peatones y el seguimiento de vehículos en ciudades inteligentes.
La arquitectura de YOLO procesa la imagen completa durante el entrenamiento, lo que le permite entender la información contextual sobre las clases de objetos y su apariencia. Esto contrasta con los métodos basados en propuestas de regiones, que podrían pasar por alto algunos detalles contextuales. La capacidad de procesamiento en tiempo real de YOLO lo hace indispensable en escenarios que demandan una detección de objetos rápida y precisa. La familia de modelos YOLO, incluyendo versiones avanzadas como YOLOv3 y YOLOv4, ha ampliado los límites en términos de velocidad y precisión de detección, estableciendo a YOLO como un sistema de vanguardia en la detección de objetos en tiempo real avanzando hasta YOLOv8.
Análisis de video en tiempo real para la detección de objetos en el drone mientras vuela con visionplatform.ai y nuestro computador NVIDIA Jetson Edge montado en el drone. Convertimos CUALQUIER cámara en una cámara AI.
Componentes clave en la detección de objetos: Clasificación y Caja delimitadora
La introducción a la detección de objetos revela dos aspectos fundamentales: la clasificación y la caja delimitadora. La clasificación se refiere a identificar la clase del objeto (por ejemplo, peatón, vehículo) en una imagen. Es un paso crítico para distinguir entre diferentes categorías de objetos dentro de un sistema de detección. La caja delimitadora, por otro lado, implica localizar el objeto dentro de la imagen, generalmente representado por coordenadas que delimitan el objeto. Juntos, estos componentes forman la base de la detección y seguimiento de objetos.
La detección de objetos puede ayudar a modelos, como la familia de modelos YOLO y el Detector Multibox de Disparo Único (SSD), la combinación de clasificación y cajas delimitadoras asegura la precisión de la detección. Estos modelos, a menudo desarrollados y compartidos en plataformas como GitHub, utilizan enfoques basados en aprendizaje profundo. También pueden usarse sin una línea de código en plataformas de reconocimiento de imágenes (https://visionplatform.ai/computer-vision-platform/) (computer vision) como visionplatform.ai. Son capaces de detectar múltiples objetos en una imagen y predecir con precisión la ubicación de cada objeto con una caja delimitadora alrededor de él. Este enfoque dual es esencial en varios casos de uso de la detección de objetos, que van desde la detección de rostros en sistemas de seguridad hasta la detección de anomalías en entornos industriales.
El papel del aprendizaje profundo en la detección de objetos
Los métodos de aprendizaje profundo han revolucionado el reconocimiento de imágenes (computer vision) y la detección de objetos. Estos métodos, que involucran principalmente redes neuronales profundas como las CNN, han permitido una detección de objetos más precisa y una segmentación semántica. TensorFlow, una biblioteca de código abierto popular para el aprendizaje automático y el aprendizaje profundo, ofrece herramientas robustas para entrenar y desplegar modelos de aprendizaje profundo para la detección de objetos.
La efectividad del aprendizaje profundo en la detección de objetos se puede observar en su aplicación a tareas complejas como la detección de peatones y la detección de texto. Estos modelos aprenden jerarquías de características para una detección de objetos precisa, mejorando significativamente sobre los algoritmos tradicionales de aprendizaje automático que requerían características diseñadas manualmente. Los modelos de detección de objetos basados en aprendizaje profundo suelen evaluarse según su precisión de detección y velocidad, lo que los hace ideales para aplicaciones en tiempo real.
Con el avance de las técnicas de aprendizaje profundo, los sistemas de detección de objetos se han vuelto más versátiles, capaces de manejar una amplia gama de tareas de reconocimiento de imágenes (computer vision) incluyendo el seguimiento de objetos, la detección de personas y el reconocimiento de imágenes. Este avance ha llevado al desarrollo de algoritmos de detección de objetos robustos que pueden clasificar y localizar objetos de manera confiable, incluso en entornos desafiantes.
Segmentación y reconocimiento de objetos: Mejorando la detección con análisis detallado
La introducción a la detección de objetos en reconocimiento de imágenes (computer vision) a menudo conduce a la exploración de tareas relacionadas como la segmentación y el reconocimiento de objetos. Mientras que la detección de objetos identifica y localiza objetos dentro de una imagen, la segmentación va un paso más allá dividiendo la imagen en segmentos para simplificar su análisis o cambiar su representación. Por otro lado, el reconocimiento de objetos implica identificar el objeto específico presente en la imagen.
Las técnicas basadas en aprendizaje profundo, especialmente las redes neuronales convolucionales profundas, han avanzado significativamente estas áreas. La segmentación, particularmente la segmentación semántica, es integral para entender el contexto en el que existen los objetos en las imágenes. Esto es crucial en casos de uso como la imagenología médica, donde la identificación precisa de tejidos o anomalías es esencial. Los algoritmos de detección de objetos que incluyen segmentación, como Mask R-CNN, proporcionan detalles precisos al no solo localizar el «cuadro delimitador alrededor» de un objeto, sino también delineando la «forma exacta del objeto».
Procesamiento de la imagen de entrada: El recorrido a través de los sistemas de detección de objetos
El proceso de detección de objetos comienza con una imagen de entrada, que pasa por varias etapas dentro de una red de detección. Inicialmente, la imagen se preprocesa para ajustarse a los requisitos del modelo de detección de objetos. Esto puede involucrar redimensionamiento, normalización y aumento. A continuación, la imagen se introduce en un modelo de aprendizaje profundo, típicamente un tipo de modelo como las CNNs, para la extracción de características.
Las características extraídas se utilizan luego para clasificar objetos y predecir su ubicación. La detección de objetos utilizada en escenarios en tiempo real, como la detección de peatones o el seguimiento de vehículos, requiere que el modelo analice rápidamente la imagen de entrada y proporcione «cuadros delimitadores predichos» precisos para cada «objeto presente». Aquí es donde modelos como YOLO sobresalen, ofreciendo un procesamiento rápido y eficiente adecuado para aplicaciones en tiempo real.
Entrenar un modelo para tareas tan complejas implica una cantidad sustancial de datos para la detección de objetos. Estos datos, que generalmente comprenden imágenes diversas con objetos anotados, ayudan al modelo a aprender diversas categorías de objetos y sus características. Marcos de detección de objetos populares como TensorFlow ofrecen herramientas y bibliotecas para construir, entrenar e implementar estos modelos de manera eficiente. Todo el proceso destaca la sinergia entre técnicas de procesamiento de imágenes y reconocimiento de imágenes (computer vision), algoritmos de aprendizaje automático y métodos de aprendizaje profundo, culminando en un sistema robusto de detección de objetos.
Casos de uso de la detección de objetos en diversas industrias
La detección de objetos, impulsada por modelos basados en aprendizaje profundo, ha encontrado aplicaciones en diversas industrias, cada una con requisitos y desafíos únicos. Estos modelos generalmente se evalúan según su precisión, velocidad y capacidad para detectar múltiples objetos bajo condiciones variables. En el sector de la salud, la detección de objetos ayuda a identificar anomalías en imágenes médicas, contribuyendo significativamente al diagnóstico temprano y la planificación del tratamiento. En el comercio minorista, juega un papel vital en el análisis del comportamiento del cliente y la gestión de inventarios.
Un caso de uso notable de la detección de objetos es en la industria automotriz, donde es crucial para el desarrollo de vehículos autónomos. Aquí, la capacidad de detectar y diferenciar entre dos objetos, como peatones y otros vehículos, es fundamental para la seguridad. Los sistemas de detección de objetos, utilizando algoritmos avanzados y redes neuronales, permiten que estos vehículos naveguen de manera segura interpretando con precisión su entorno.
TensorFlow en Detección de Objetos: Aprovechando Modelos de Aprendizaje Profundo
TensorFlow, un marco de trabajo de código abierto disponible en plataformas como GitHub, se ha convertido en sinónimo de construcción y despliegue de modelos de aprendizaje profundo, especialmente en el campo de la detección de objetos. Su biblioteca integral permite a los desarrolladores construir un modelo desde cero o utilizar modelos preentrenados para la detección de objetos. La flexibilidad de TensorFlow para manejar diversos mecanismos de propuesta de objetos y su eficiente procesamiento de grandes conjuntos de datos lo hacen la elección preferida de muchos desarrolladores.
En la detección de objetos, el enfoque de aprendizaje es crítico. TensorFlow facilita la implementación de algoritmos complejos que pueden diferenciar tareas de ‘detección vs. clasificación’, esenciales para escenarios de detección de objetos matizados. La plataforma admite una amplia gama de modelos, desde aquellos que requieren recursos computacionales intensivos hasta modelos ligeros adecuados para dispositivos móviles. Esta adaptabilidad asegura que los modelos basados en TensorFlow puedan ser desplegados en diversos entornos, desde sistemas basados en servidores hasta dispositivos de borde como el Jetson Nano Orin, Jetson NX Orin o Jetson AGX Orin, expandiendo el alcance y la accesibilidad de la tecnología de detección de objetos.
Explorando el modelo YOLO en profundidad
El modelo YOLO (You Only Look Once), un marco basado en aprendizaje profundo para la detección de objetos, representa un cambio significativo en el enfoque de aprendizaje para detectar objetos. A diferencia de los modelos tradicionales donde el sistema primero propone regiones potenciales (propuesta de objeto) y luego clasifica cada región, YOLO aplica una única red neuronal a la imagen completa, prediciendo cajas delimitadoras y probabilidades de clase para múltiples objetos en una evaluación. Este enfoque, centrado en la imagen completa en lugar de en propuestas separadas, permite que YOLO detecte objetos en tiempo real de manera efectiva.
Los modelos YOLO generalmente se evalúan según su velocidad y precisión en la detección de múltiples objetos. En escenarios donde dos objetos están cerca uno del otro, la capacidad de YOLO para distinguir entre ellos con precisión es crucial. La arquitectura del modelo le permite entender el contexto dentro de una imagen, haciéndolo robusto en entornos complejos. Esta capacidad es el resultado de su diseño de red único, que observa la imagen completa durante la predicción, capturando así información contextual que podría perderse al centrarse en partes de la imagen.
Datos para la Detección de Objetos: Recopilación y Utilización
El éxito de cualquier modelo de detección de objetos, incluidos aquellos basados en marcos de aprendizaje profundo como YOLO, depende en gran medida de la calidad y cantidad de datos utilizados para el entrenamiento. El proceso para construir un modelo de detección de objetos comienza con la recopilación de datos, que implica reunir un conjunto diverso de imágenes y anotarlas con etiquetas y cuadros delimitadores. Esta recopilación de datos es un paso crítico en el entrenamiento de un modelo, ya que proporciona la base para que el modelo aprenda.
Los datos para la detección de objetos deben abarcar una amplia variedad de escenarios y tipos de objetos para asegurar que el modelo pueda generalizar bien a nuevas imágenes no vistas. Esto incluye tener en cuenta variaciones en el tamaño de los objetos, las condiciones de iluminación y los fondos. Los conjuntos de datos anotados disponibles en plataformas como GitHub ofrecen un recurso valioso para el entrenamiento y la evaluación comparativa de modelos de detección de objetos.
En el enfoque de aprendizaje para la detección de objetos, el modelo se entrena para detectar ‘objeto versus no objeto’ y para clasificar los objetos detectados. Este entrenamiento implica no solo reconocer la presencia de un objeto, sino también determinar con precisión su ubicación dentro de la imagen. El uso de métodos avanzados de aprendizaje profundo y conjuntos de datos grandes y anotados ha aumentado sustancialmente la precisión y la fiabilidad de los modelos de detección de objetos, haciéndolos herramientas esenciales en diversas aplicaciones de reconocimiento de imágenes (computer vision).
Detección vs. Reconocimiento: Entendiendo las Diferencias
En el campo del reconocimiento de imágenes (computer vision), es crucial diferenciar entre ‘detección vs. reconocimiento’. La detección implica localizar objetos dentro de una imagen, típicamente usando cajas delimitadoras, mientras que el reconocimiento profundiza más, con el objetivo de identificar la naturaleza específica o clase de los objetos detectados. Esta distinción es importante para adaptar los sistemas de reconocimiento de imágenes (computer vision) para aplicaciones específicas. Por ejemplo, mientras que un sistema de detección podría ser suficiente para contar coches en una carretera, un sistema de reconocimiento sería necesario para diferenciar entre modelos de coches.
La complejidad de las tareas de reconocimiento generalmente exige modelos más sofisticados en comparación con las tareas de detección. El reconocimiento a menudo implica no solo identificar que un objeto está presente, sino también clasificarlo en una de varias categorías posibles. Este proceso requiere una comprensión más matizada de las características del objeto y es crucial en escenarios donde la identificación detallada es esencial, como diferenciar entre células benignas y malignas en imágenes médicas.
Conclusión y tendencias futuras en la detección de objetos
A medida que concluimos, es evidente que la detección de objetos es un campo en rápida evolución, con nuevos avances que surgen continuamente. Las tendencias futuras probablemente se centrarán en mejorar la precisión, la velocidad y la capacidad para manejar escenas más complejas. La integración de la IA con otras tecnologías como la realidad aumentada y el Internet de las Cosas (IoT) abre nuevos horizontes para las aplicaciones de detección de objetos.
Además, la demanda de modelos más eficientes y menos intensivos en datos está impulsando la investigación hacia enfoques de aprendizaje con pocos ejemplos y aprendizaje no supervisado. Estos métodos apuntan a entrenar modelos de manera efectiva con datos limitados, abordando uno de los desafíos significativos en el campo. A medida que la tecnología avanza, podemos anticipar soluciones más innovadoras, mejorando las capacidades y aplicaciones de la detección de objetos en varios sectores, desde la salud hasta los vehículos autónomos.
El refinamiento continuo de modelos y algoritmos en la detección de objetos sin duda contribuirá a sistemas más sofisticados y precisos, consolidando su importancia en el ámbito del reconocimiento de imágenes (computer vision) y más allá.
Preguntas frecuentes sobre la detección de objetos: Entendiendo los conceptos clave
Sumérgete en los aspectos esenciales de la detección de objetos con nuestra sección de preguntas frecuentes. Aquí, abordamos preguntas comunes, aclarando cómo funciona la detección de objetos, sus aplicaciones y la tecnología detrás de ella. Ya sea que seas nuevo en el reconocimiento de imágenes (computer vision) o busques refinar tu conocimiento, estas respuestas proporcionan una visión concisa del emocionante mundo de la detección de objetos.
¿Qué es la detección de objetos?
La detección de objetos es una solución de reconocimiento de imágenes (computer vision) que identifica y localiza objetos dentro de una imagen o video. No solo reconoce la presencia de objetos, sino que también señala sus posiciones con cuadros delimitadores. El sistema asigna niveles de confianza a las predicciones, indicando la probabilidad de precisión. La detección de objetos es distinta del reconocimiento de imágenes, que asigna una etiqueta de clase a una imagen, y de la segmentación de imágenes, que identifica objetos a nivel de píxel.
¿Cómo funciona la detección de objetos?
La detección de objetos generalmente implica dos etapas: detectar regiones de objetos potenciales (Región de Interés, o RoI) y luego clasificar estas regiones. Los enfoques basados en aprendizaje profundo, especialmente utilizando redes neuronales como las Redes Neuronales Convolucionales (CNNs), son comunes. Modelos como R-CNN, YOLO y SSD primero analizan la imagen para encontrar RoIs y luego clasifican cada RoI en categorías de objetos, a menudo utilizando características aprendidas durante el entrenamiento en conjuntos de datos como COCO o ImageNet.
¿Cuáles son los tipos de modelos de detección de objetos?
Los modelos de detección de objetos populares incluyen R-CNN y sus variantes (Fast R-CNN, Faster R-CNN y Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) y CenterNet. Estos modelos difieren en su enfoque para identificar RoIs y clasificarlos. Los modelos R-CNN utilizan propuestas de región, mientras que YOLO y SSD predicen cuadros delimitadores directamente desde la imagen, mejorando la velocidad y la eficiencia.
¿Cuál es la diferencia entre la detección de objetos y el reconocimiento de objetos?
La detección de objetos y el reconocimiento de objetos son tareas distintas. La detección de objetos implica localizar objetos dentro de una imagen e identificar sus límites, típicamente con cuadros delimitadores. El reconocimiento de objetos va un paso más allá al no solo localizar, sino también clasificar los objetos en categorías predefinidas, como distinguir entre diferentes tipos de animales, vehículos u otros artículos.
¿Cómo se entrenan los modelos de detección de objetos?
El entrenamiento de modelos de detección de objetos implica alimentar una red neuronal con imágenes etiquetadas. Estas imágenes están anotadas con cuadros delimitadores alrededor de los objetos y sus etiquetas de clase correspondientes. La red neuronal aprende a reconocer patrones y características de estas imágenes de entrenamiento. La efectividad del entrenamiento depende de la diversidad y el tamaño del conjunto de datos, con conjuntos de datos más grandes y variados que conducen a modelos más precisos y generalizables. Los modelos a menudo se entrenan utilizando marcos como TensorFlow o PyTorch.
¿Cuáles son los usos de la detección de objetos?
La detección de objetos se utiliza ampliamente en varios campos. En seguridad y vigilancia, ayuda en la detección de rostros y el monitoreo de actividades. En el comercio minorista, ayuda en el análisis del comportamiento del cliente y la gestión de inventarios. En vehículos autónomos, es crucial para identificar obstáculos y navegar de manera segura. La detección de objetos también encuentra aplicaciones en la atención médica para identificar anomalías en imágenes médicas y en la agricultura para el monitoreo de cultivos y plagas.
¿Qué es YOLO en la detección de objetos?
YOLO (You Only Look Once) es un modelo de detección de objetos popular conocido por su velocidad y eficiencia. A diferencia de los modelos tradicionales que procesan una imagen en partes, YOLO examina toda la imagen en un solo paso, lo que lo hace significativamente más rápido. Esto lo hace ideal para aplicaciones de detección de objetos en tiempo real. YOLO tiene varias versiones, siendo YOLOv5 y YOLOv8 las más recientes, ofreciendo mejoras en precisión y velocidad.
¿Qué tan precisos son los modelos de detección de objetos?
La precisión de los modelos de detección de objetos varía dependiendo de su arquitectura y la calidad de los datos de entrenamiento. Modelos como YOLOv4 y YOLOv5 demuestran una alta precisión, a menudo con tasas de precisión superiores al 90% en condiciones ideales. La precisión se mide utilizando métricas como mAP (Precisión Media Promedio) y IoU (Intersección sobre Unión). El mAP para los modelos principales en conjuntos de datos estándar como MS COCO puede ser tan alto como 60-70%.
¿Cuál es el papel de las Redes Neuronales Convolucionales en la detección de objetos?
Las Redes Neuronales Convolucionales (CNNs) juegan un papel crítico en la detección de objetos, principalmente en la extracción de características. Procesan imágenes a través de capas convolucionales para aprender e identificar características clave, que son cruciales para detectar objetos. Modelos como R-CNN, Faster R-CNN y SSD utilizan CNNs por su eficiencia en el manejo de datos de imágenes, mejorando significativamente la precisión y la velocidad de la detección de objetos.
¿Cómo comenzar a construir un modelo de detección de objetos?
Para comenzar a construir un modelo de detección de objetos, primero define los objetos que deseas detectar. Reúne y anota un conjunto de datos con imágenes que contengan estos objetos. Utiliza herramientas como TensorFlow o PyTorch para entrenar un modelo en este conjunto de datos. Comienza con una arquitectura simple como SSD o YOLO para una implementación más fácil. Experimenta con diferentes configuraciones y hiperparámetros para optimizar el rendimiento de tu modelo.