
latest news

Vision-language models for forensic video anomaly detection
vlms Vision-language models present a new way to process images or videos and text together. First, they combine computer vision encoders with language encoders. Next, they fuse those representations in a shared latent space so a single system can reason about visual signals and human language. In the context of forensic video anomaly detection this […]

Vision language models for Milestone XProtect
vision language model summarises hours of footage into concise text with generative AI Vision language model technology turns long video timelines into readable incident narratives, and this shift matters for real teams. Also, these systems combine image and language processing to create human-like descriptions of what the camera captured. For example, advanced models will generate […]
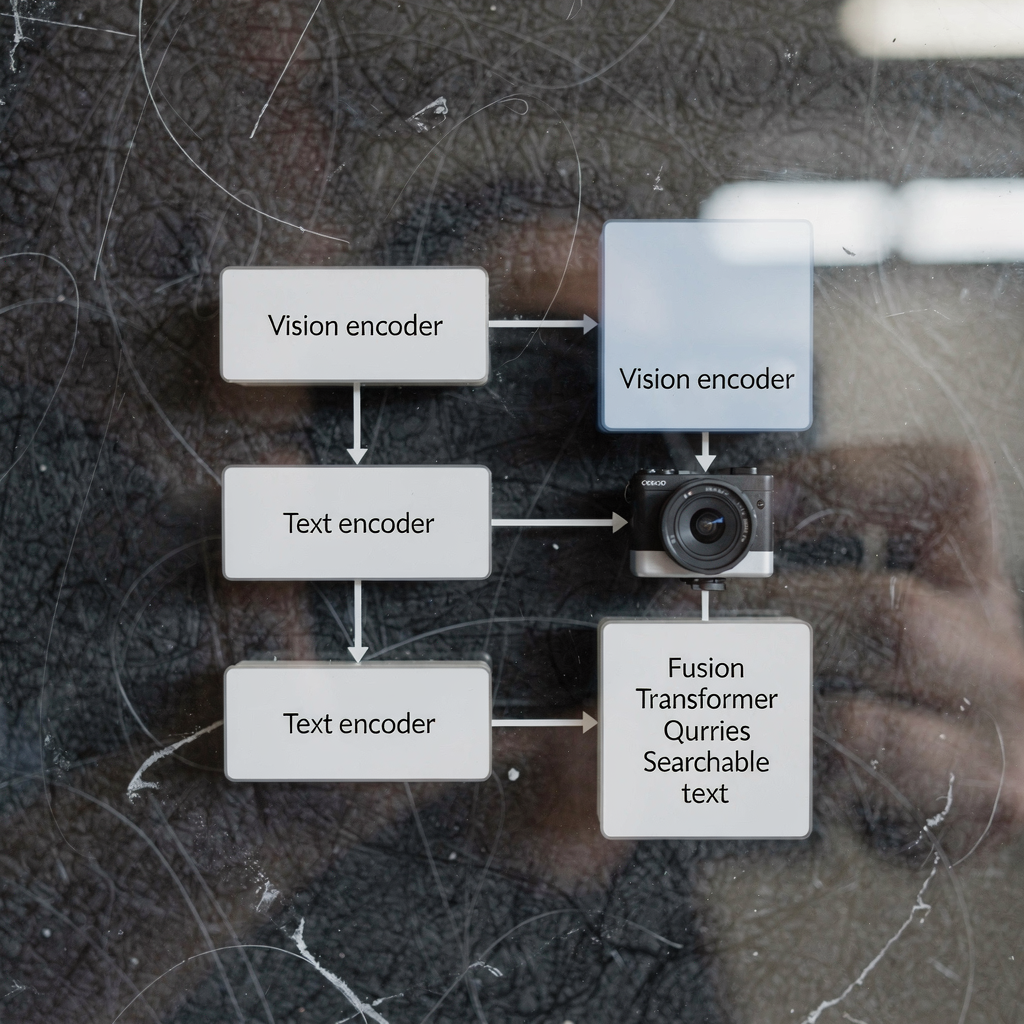
Vision-language Models for VMS Integration with VLMS
language model and vision language model: introduction A language model predicts text. In VMS contexts a language model maps words, phrases, and commands to probabilities and actions. A vision language model adds vision to that capability. It combines visual input with textual reasoning so VMS operators can ask questions and receive human-readable descriptions. This contrast […]

AI vision-language models for surveillance analytics
ai systems and agentic ai in video management AI systems now shape modern video management. First, they ingest video feeds and enrich them with metadata. Next, they help operators decide what matters. In security settings, agentic AI takes those decisions further. Agentic AI can orchestrate workflows, act within predefined permissions, and follow escalation rules. For […]

Vision language models for operator decision support
language models and vlms for operator decision support Language models and VLMS sit at the center of modern decision support for complex operators. First, language models describe a class of systems that predict text and follow instructions. Next, VLMS combine visual inputs with text reasoning so a system can interpret images and answer questions. For […]

Vision-language models for multi-camera reasoning
1. Vision-language: Definition and Role in Multi-Camera Reasoning Vision-language refers to methods that bridge visual input and natural language so systems can describe, query, and reason about scenes. A vision-language model maps pixels to words and back. It aims to answer questions, generate captions, and support decision making. In single-camera setups the mapping is simpler. […]