
latest news

AI vision-language models for surveillance analytics
ai systems and agentic ai in video management AI systems now shape modern video management. First, they ingest video feeds and enrich them with metadata. Next, they help operators decide what matters. In security settings, agentic AI takes those decisions further. Agentic AI can orchestrate workflows, act within predefined permissions, and follow escalation rules. For […]

Vision language models for operator decision support
language models and vlms for operator decision support Language models and VLMS sit at the center of modern decision support for complex operators. First, language models describe a class of systems that predict text and follow instructions. Next, VLMS combine visual inputs with text reasoning so a system can interpret images and answer questions. For […]

Advanced vision language models for alarm context
vlms and ai systems: architecture of vision language model for alarms Vision and AI meet in practical systems that turn raw video into meaning. In this chapter I explain how vlms fit into ai systems for alarm handling. First, a basic definition helps. A vision language model combines a vision encoder with a language model […]
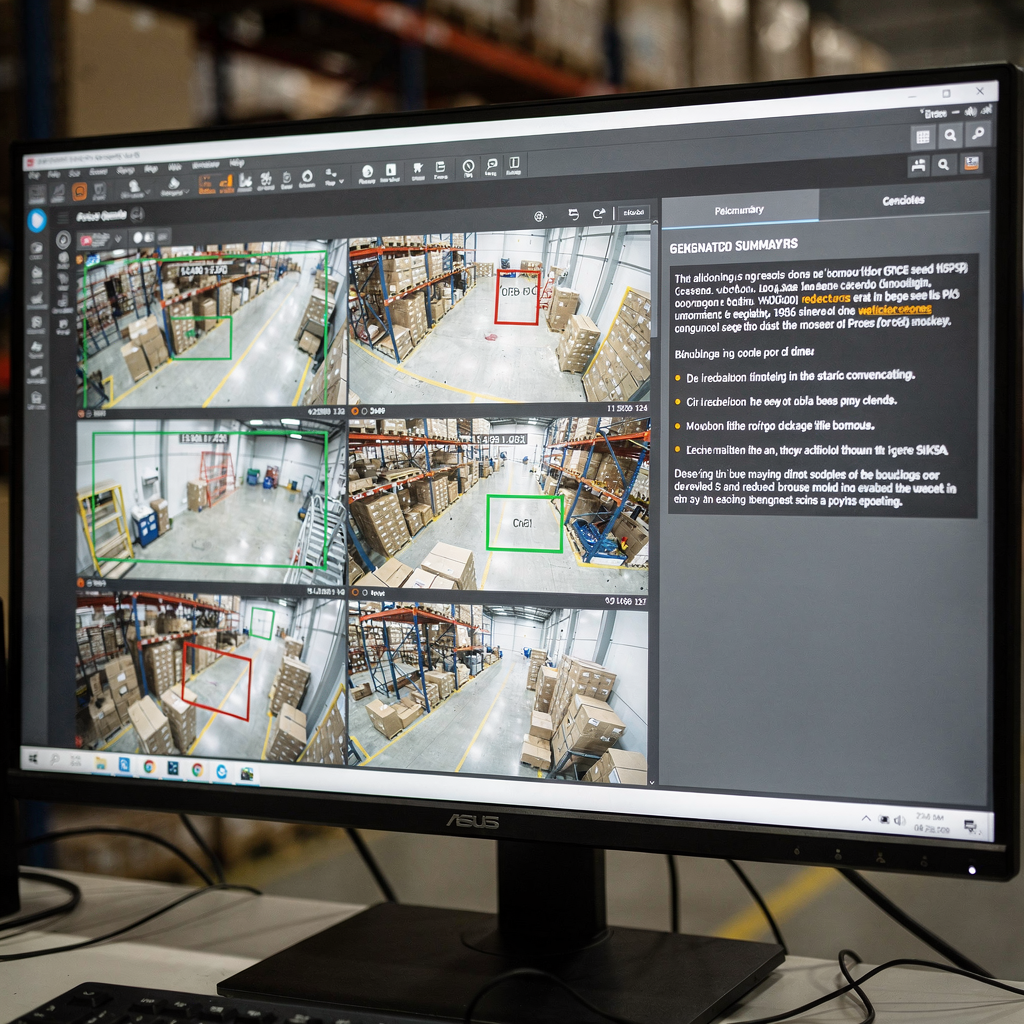
Vision Language Models for Video Summarization
Understanding the Role of video in Multimodal AI First, video is the richest sensor for many real-world problems. Also, video carries both spatial and temporal signals. Next, visual pixels, motion, and audio combine to form long sequences of frames that require careful handling. Therefore, models must capture spatial detail and temporal dynamics. Furthermore, they must […]

Vision language models for event description
How vision language models work: a multimodal ai overview Vision language models work by bridging visual data and textual reasoning. First, a visual encoder extracts features from images and video frames. Then, a language encoder or decoder maps those features into tokens that a language model can process. Also, this joint process lets a single […]

Vision-language models for incident understanding
vlms: Role and Capabilities in Incident Understanding First, vlms have grown fast at the intersection of computer vision and natural language. Also, vlms combine visual and textual signals to create multimodal reasoning. Next, a vision-language model links image features to language tokens so machines can describe incidents. Then, vlms represent scenes, objects, and actions in […]