
Category: Industry applications

Forensic video analysis with AI forensic video search
Understanding AI-powered video analytics in modern forensic investigations AI-powered video analytics transform how investigators handle recorded video. First, AI turns raw video streams into searchable descriptions. Next, operators can find an object of interest without guessing camera IDs. For modern forensic teams this reduces friction. Furthermore, it reduces the time that analysts spend on low-value […]

Forensic video search for CCTV systems with AI
AI-driven video analytics to accelerate forensic investigations in video surveillance AI-driven video analytics now form the backbone of modern forensic work. First, motion detection and face recognition algorithms reduce the time analysts spend manually reviewing footage. For example, motion filters and targeted tracking can cut manually reviewing by up to 50% when combined with smart […]

Forensic video search for control rooms
Forensic investigations and video surveillance in control rooms Control rooms are the nerve centre for many modern forensic investigations. They collect live and recorded signals from CCTV, access control systems, sensors, and smart devices. As a result, operators see consolidated situational displays and can coordinate responses. Centralisation helps teams perform a unified search across multiple […]

Forensic video search software
forensic search software: unify video surveillance streams Modern forensic systems must unify fragmented feeds, and they must do so quickly. Many sites run multiple camera vendors, and each camera stream comes in different formats. Forensic teams face siloed camera networks, incompatible VMS, and isolated logs that slow an investigation. A unified approach centralizes video streams, […]

Vision-language models for forensic video anomaly detection
vlms Vision-language models present a new way to process images or videos and text together. First, they combine computer vision encoders with language encoders. Next, they fuse those representations in a shared latent space so a single system can reason about visual signals and human language. In the context of forensic video anomaly detection this […]
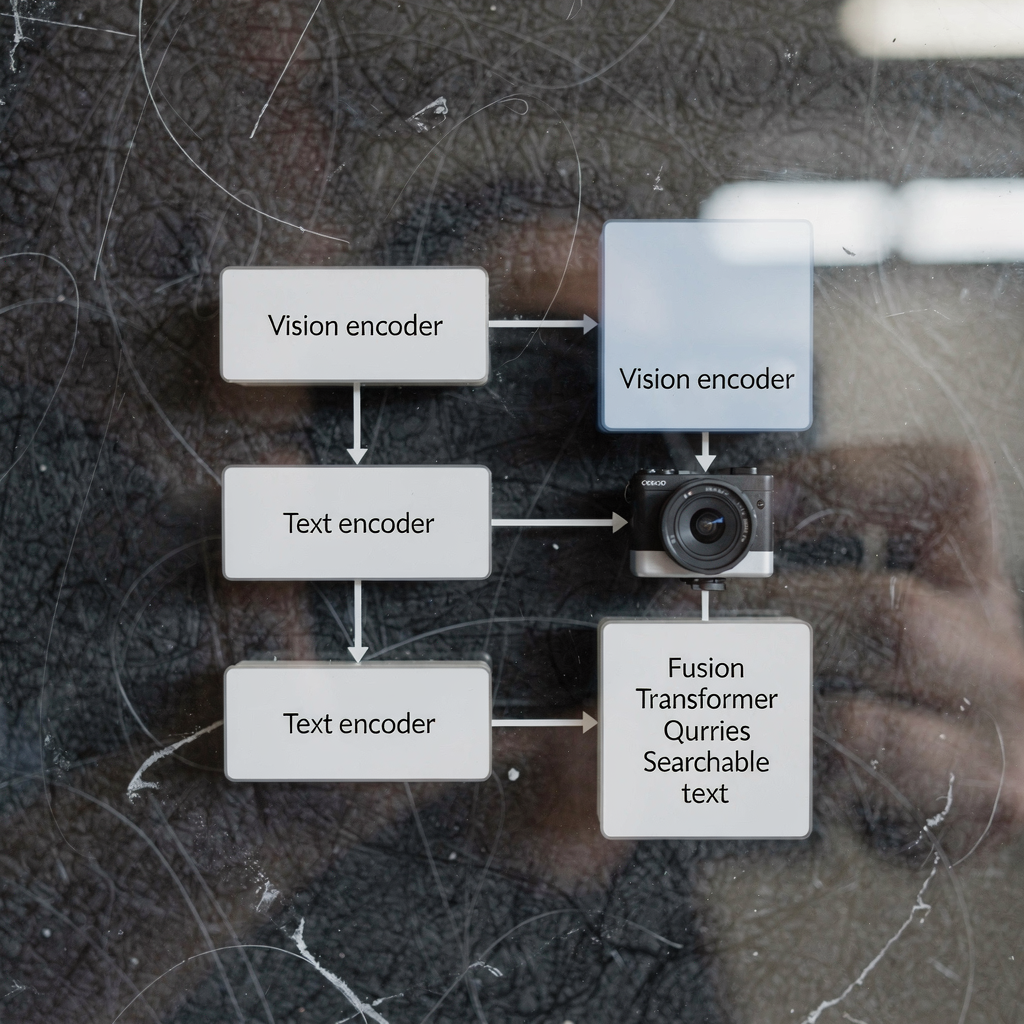
Vision-language Models for VMS Integration with VLMS
language model and vision language model: introduction A language model predicts text. In VMS contexts a language model maps words, phrases, and commands to probabilities and actions. A vision language model adds vision to that capability. It combines visual input with textual reasoning so VMS operators can ask questions and receive human-readable descriptions. This contrast […]

AI vision-language models for surveillance analytics
ai systems and agentic ai in video management AI systems now shape modern video management. First, they ingest video feeds and enrich them with metadata. Next, they help operators decide what matters. In security settings, agentic AI takes those decisions further. Agentic AI can orchestrate workflows, act within predefined permissions, and follow escalation rules. For […]

Vision language models for operator decision support
language models and vlms for operator decision support Language models and VLMS sit at the center of modern decision support for complex operators. First, language models describe a class of systems that predict text and follow instructions. Next, VLMS combine visual inputs with text reasoning so a system can interpret images and answer questions. For […]

Advanced vision language models for alarm context
vlms and ai systems: architecture of vision language model for alarms Vision and AI meet in practical systems that turn raw video into meaning. In this chapter I explain how vlms fit into ai systems for alarm handling. First, a basic definition helps. A vision language model combines a vision encoder with a language model […]
Vision Language Models for Video Summarization
Understanding the Role of video in Multimodal AI First, video is the richest sensor for many real-world problems. Also, video carries both spatial and temporal signals. Next, visual pixels, motion, and audio combine to form long sequences of frames that require careful handling. Therefore, models must capture spatial detail and temporal dynamics. Furthermore, they must […]