
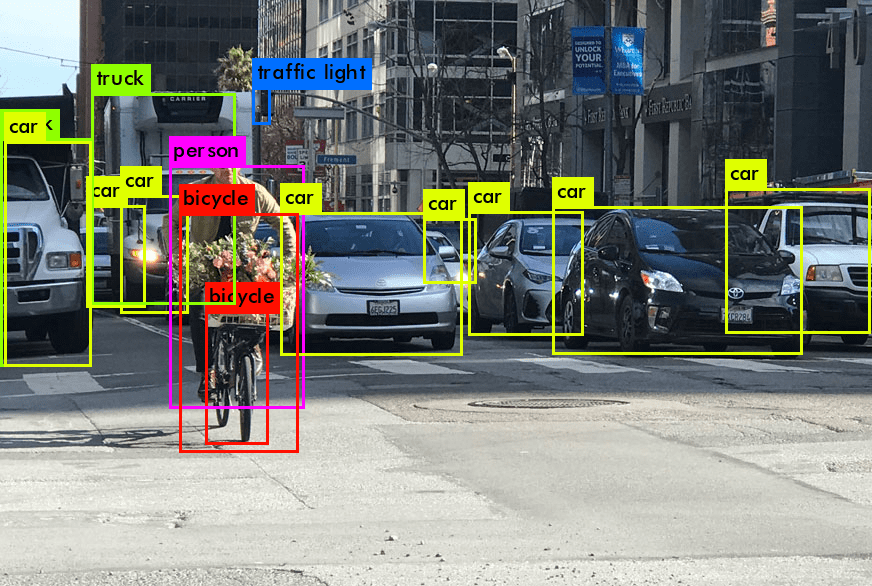
Introducción al reconocimiento de imágenes (computer vision) y el modelo YOLO
El reconocimiento de imágenes, un campo de la inteligencia artificial, tiene como objetivo dotar a las máquinas de la capacidad de interpretar y comprender el mundo visual. Involucra la captura, procesamiento y análisis de imágenes o videos para automatizar tareas que el sistema visual humano puede realizar. Este campo en rápida evolución abarca diversas aplicaciones, desde el reconocimiento facial y el seguimiento de objetos hasta actividades más avanzadas como la conducción autónoma. El desarrollo del reconocimiento de imágenes depende en gran medida de grandes conjuntos de datos, algoritmos sofisticados y recursos computacionales potentes.
Un avance en este campo se produjo con el desarrollo del modelo YOLO (You Only Look Once). Diseñado como un modelo de detección de objetos de última generación, YOLO revolucionó el enfoque para detectar objetos en imágenes. Los modelos de detección tradicionales a menudo involucraban un proceso de dos pasos: primero identificar las regiones de interés y luego clasificar esas regiones. En contraste, YOLO innovó al predecir tanto las clasificaciones como las cajas delimitadoras en una sola pasada a través de la red neuronal, acelerando significativamente el proceso y mejorando las capacidades de detección en tiempo real.
Este modelo de detección de objetos ha pasado por varias iteraciones, con cada versión introduciendo nuevas características y mejoras. YOLOv8, la última versión de Ultralytics, se basa en el éxito de sus predecesores como YOLOv5. Incorpora técnicas avanzadas de aprendizaje automático para mejorar la precisión y la velocidad, lo que lo convierte en una opción popular para tareas de reconocimiento de imágenes. La naturaleza de código abierto de los modelos YOLO, como el repositorio YOLOv8 en GitHub, ha contribuido aún más a su adopción generalizada y desarrollo continuo.
La efectividad de YOLO en tareas de detección de objetos, segmentación de instancias y clasificación ha hecho que sea un elemento básico en proyectos de reconocimiento de imágenes. Al simplificar el proceso de identificar y categorizar objetos dentro de imágenes, modelos YOLO como YOLOv8 ayudan a las máquinas a comprender el mundo visual de manera más precisa y eficiente.
YOLOv8: El nuevo estado del arte en reconocimiento de imágenes (computer vision)
YOLOv8 representa el pináculo del progreso en el ámbito del reconocimiento de imágenes (computer vision), estableciéndose como el nuevo estado del arte en modelos de detección de objetos. Desarrollado por Ultralytics, esta versión de la serie de modelos YOLO presenta avances significativos sobre su predecesor, YOLOv5, y versiones anteriores de YOLO. YOLOv8 viene equipado con una gama de nuevas características que mejoran sus capacidades de detección, haciéndolo más preciso y eficiente que nunca.
Uno de los avances notables en YOLOv8 es su adopción de la detección sin anclas (anchor-free detection). Este nuevo enfoque se desvía de la dependencia tradicional en cajas de anclaje, que eran un elemento básico en los modelos YOLO anteriores. La detección sin anclas simplifica la arquitectura del modelo y mejora su capacidad para predecir ubicaciones de objetos con mayor precisión. Esta mejora es particularmente beneficiosa en escenarios donde el conjunto de datos incluye objetos de formas y tamaños variados.
El modelo YOLOv8 también sobresale en tareas de segmentación, un aspecto crítico del reconocimiento de imágenes (computer vision). Ya sea para la detección de objetos o la segmentación de instancias o modelos de segmentación más generales, YOLOv8, especialmente el modelo YOLOv8 Nano, demuestra una competencia notable. Su capacidad para segmentar y clasificar con precisión diferentes partes de una imagen lo hace altamente efectivo en aplicaciones diversas, desde la imagen médica hasta la navegación de vehículos autónomos.
Otro aspecto clave de YOLOv8 es su paquete de Python, que facilita la integración y uso en proyectos basados en Python. Esta accesibilidad es crucial, especialmente considerando la popularidad de Python en las comunidades de ciencia de datos y aprendizaje automático. Los desarrolladores pueden entrenar un modelo YOLOv8 en un conjunto de datos personalizado utilizando PyTorch, un marco de aprendizaje profundo líder. Esta flexibilidad permite soluciones a medida para desafíos específicos del reconocimiento de imágenes (computer vision).
El rendimiento de YOLOv8 se ve aún más potenciado por sus métricas de rendimiento de modelo de última generación. Estas métricas muestran la capacidad del modelo para detectar objetos con alta precisión y velocidad, factores cruciales en aplicaciones en tiempo real. Además, como un modelo de código abierto disponible en GitHub, YOLOv8 se beneficia de mejoras continuas y contribuciones de la comunidad global de desarrolladores.
En conclusión, YOLOv8 establece un nuevo referente en el campo del reconocimiento de imágenes (computer vision). Sus avances en detección de objetos, segmentación y rendimiento general del modelo lo convierten en una herramienta invaluable para desarrolladores e investigadores que buscan ampliar los límites de lo que es posible en la interpretación visual impulsada por IA.
Arquitectura YOLOv8: La columna vertebral de los nuevos avances en reconocimiento de imágenes (computer vision)
La arquitectura YOLOv8 representa un salto significativo en el campo del reconocimiento de imágenes (computer vision), estableciendo un nuevo estándar de vanguardia. Como la última versión de YOLO, YOLOv8 introduce varias mejoras sobre sus predecesores, como YOLOv5 y versiones anteriores de YOLO. Comprender la arquitectura YOLOv8 es crucial para aquellos que buscan entrenar el modelo para tareas especializadas de detección de objetos.
Una de las características fundamentales de YOLOv8 es su cabeza de detección libre de anclas, una desviación del enfoque tradicional de cajas de anclas utilizado en versiones anteriores de YOLO. Este cambio simplifica el modelo mientras mantiene, y en muchos casos mejora, la precisión en la detección de objetos. YOLOv8 admite una amplia gama de aplicaciones, desde la detección de objetos en tiempo real hasta la segmentación de imágenes.
El modelo YOLOv8 está diseñado para eficiencia y rendimiento. El modelo YOLOv8 de código abierto puede ser entrenado en diversos conjuntos de datos, incluyendo el ampliamente utilizado conjunto de datos COCO. Esta flexibilidad permite a los usuarios adaptar el modelo para necesidades específicas, ya sea para detección de objetos en general o tareas especializadas como la estimación de poses.
La arquitectura de YOLOv8 está optimizada tanto para velocidad como para precisión, un factor crucial en aplicaciones en tiempo real. El diseño del modelo también incluye mejoras en la segmentación de imágenes, haciéndolo un modelo integral de detección y segmentación de imágenes. La serie YOLO de Ultralytics, particularmente YOLOv8, siempre ha estado a la vanguardia en el avance de modelos de reconocimiento de imágenes (computer vision), y YOLOv8 continúa esta tradición.
Para aquellos que buscan comenzar con YOLOv8, el repositorio de Ultralytics proporciona amplios recursos. El repositorio, disponible en GitHub, ofrece instrucciones detalladas sobre cómo entrenar el modelo YOLOv8, incluyendo la configuración del entorno de entrenamiento y la carga de pesos del modelo.
Modelo de Detección de Objetos YOLOv8: Revolucionando la Detección y Segmentación
El modelo de detección de objetos YOLOv8 es la adición más reciente a la serie YOLO, creado por Joseph Redmon y Ali Farhadi. Se sitúa a la vanguardia en el campo de los avances en reconocimiento de imágenes (computer vision), encarnando el nuevo estado del arte tanto en detección de objetos como en segmentación de imágenes. Las capacidades de YOLOv8 se extienden más allá de la mera detección de objetos; también sobresale en tareas como la segmentación de instancias y la detección en tiempo real, lo que lo convierte en una herramienta versátil para una variedad de aplicaciones.
YOLOv8 utiliza un enfoque innovador para la detección, integrando características que lo convierten en un detector de objetos altamente preciso. El modelo incorpora una cabeza de detección libre de anclas, que simplifica el proceso de detección y mejora la precisión. Esto representa un cambio significativo respecto al método de cajas de anclas utilizado en versiones anteriores de YOLO.
El entrenamiento del modelo YOLOv8 es un proceso sencillo, especialmente con los recursos proporcionados en el repositorio de GitHub de YOLOv8. El repositorio incluye instrucciones detalladas sobre cómo entrenar el modelo utilizando un conjunto de datos personalizado, lo que permite a los usuarios adaptar el modelo a sus necesidades específicas. Por ejemplo, entrenar modelos en un conjunto de datos durante 100 épocas puede producir una mejora significativa en el rendimiento del modelo, como lo demuestran las evaluaciones en el conjunto de validación.
Además, la arquitectura de YOLOv8 está diseñada para soportar eficazmente tareas de detección de objetos y segmentación de imágenes. Esta versatilidad es evidente en su aplicación en diversos dominios, desde la vigilancia hasta la conducción autónoma. YOLOv8 introduce nuevas características que mejoran su eficiencia, como mejoras en las últimas diez épocas de entrenamiento, que optimizan el aprendizaje y la precisión del modelo.
En resumen, YOLOv8 representa un avance significativo en la serie YOLO y en el campo más amplio del reconocimiento de imágenes (computer vision). Su arquitectura y características de última generación lo convierten en una opción ideal para desarrolladores e investigadores que buscan implementar modelos avanzados de detección y segmentación en sus proyectos. El repositorio de Ultralytics es un excelente punto de partida para cualquiera interesado en explorar las capacidades de YOLOv8 y desplegarlo en escenarios del mundo real.
Formato de Anotación YOLOv8: Preparando Datos para el Entrenamiento
Preparar datos para el entrenamiento es un paso crítico en el desarrollo de cualquier modelo de reconocimiento de imágenes (computer vision), y YOLOv8 no es la excepción. El formato de anotación YOLOv8 juega un papel fundamental en este proceso, ya que influye directamente en el aprendizaje y la precisión del modelo. Una anotación adecuada asegura que el modelo pueda identificar y aprender correctamente de los diversos elementos dentro de un conjunto de datos, lo cual es crucial para la detección efectiva de objetos y la segmentación de imágenes.
El formato de anotación de YOLOv8 es único y distinto de otros formatos utilizados en reconocimiento de imágenes (computer vision). Requiere un detallado preciso de los objetos en las imágenes, típicamente a través de cajas delimitadoras y etiquetas. Cada objeto en una imagen está marcado con una caja delimitadora, y estas cajas están etiquetadas con clases que el modelo necesita identificar. Este formato es crítico para entrenar el modelo YOLOv8, ya que ayuda al modelo a entender la ubicación y categoría de cada objeto dentro de una imagen.
Preparar un conjunto de datos para YOLOv8 implica anotar una gran cantidad de imágenes, lo cual puede ser un proceso que consume mucho tiempo. Sin embargo, el esfuerzo es esencial para lograr un alto rendimiento del modelo. La calidad y precisión de las anotaciones impactan directamente en la capacidad del modelo para aprender y hacer predicciones precisas.
Para aquellos que buscan entrenar un modelo YOLOv8, entender e implementar el formato de anotación correcto es clave. Este proceso típicamente involucra el uso de herramientas de anotación especializadas que permiten a los usuarios dibujar cajas delimitadoras y etiquetarlas adecuadamente. El conjunto de datos anotado se utiliza luego para entrenar el modelo, enseñándole a reconocer y categorizar objetos basados en las etiquetas proporcionadas y las coordenadas de las cajas delimitadoras.
Entrenamiento de YOLOv8: Una guía paso a paso
El entrenamiento de YOLOv8 es un proceso que requiere una preparación y ejecución cuidadosas para lograr un rendimiento óptimo del modelo. El proceso de entrenamiento involucra varios pasos, desde configurar el entorno hasta ajustar el modelo en un conjunto de datos específico. Aquí tienes una guía paso a paso para entrenar YOLOv8:
- Configuración del entorno: El primer paso es configurar el entorno de entrenamiento. Esto implica instalar el software y las dependencias necesarias. YOLOv8, siendo un modelo basado en Python, requiere un entorno Python con bibliotecas como PyTorch.
- Preparación de datos: A continuación, prepara tu conjunto de datos de acuerdo con el formato de anotación de YOLOv8. Esto implica anotar imágenes con cuadros delimitadores y etiquetas para definir los objetos que el modelo necesita aprender a detectar.
- Configuración del modelo: Antes de comenzar el entrenamiento, configura el modelo YOLOv8 según tus requisitos. Esto podría implicar ajustar parámetros como la tasa de aprendizaje, el tamaño del lote y el número de épocas.
- Entrenamiento del modelo: Con el entorno y los datos preparados, puedes comenzar el proceso de entrenamiento. Esto implica alimentar el conjunto de datos anotado al modelo y permitirle aprender de los datos. El modelo ajusta iterativamente sus pesos y sesgos para minimizar errores en la detección.
- Evaluación del rendimiento: Después del entrenamiento, evalúa el rendimiento del modelo utilizando métricas como precisión, recuperación y Precisión Media Promedio (mAP). Esto ayuda a entender qué tan bien puede el modelo detectar y clasificar objetos en imágenes.
- Ajuste fino: Basado en la evaluación, podrías necesitar ajustar el modelo. Esto podría implicar reentrenar el modelo con parámetros ajustados o proporcionarle datos de entrenamiento adicionales.
- Despliegue: Una vez que el modelo está entrenado y ajustado, está listo para su implementación en aplicaciones del mundo real.
Entrenar un modelo YOLOv8 requiere atención al detalle y un profundo entendimiento de cómo funciona el modelo. Sin embargo, el esfuerzo se ve recompensado con un modelo de detección de objetos robusto, preciso y eficiente, adecuado para diversas aplicaciones en reconocimiento de imágenes (computer vision).
Implementación de YOLOv8 en Aplicaciones del Mundo Real
Implementar YOLOv8 en aplicaciones del mundo real es un paso crítico para aprovechar sus avanzadas capacidades de detección de objetos. La implementación exitosa traduce la competencia teórica del modelo en soluciones prácticas y accionables en diversas industrias. Aquí tienes una guía completa para implementar YOLOv8:
- Elegir la Plataforma Adecuada: El primer paso es decidir dónde se implementará el modelo YOLOv8. Esto podría variar desde servidores basados en la nube para aplicaciones a gran escala hasta dispositivos de borde para procesamiento en tiempo real y en el sitio, como la solución de plataforma de reconocimiento de imágenes (https://visionplatform.eu-1.slashinfra.nl/computer-vision-platform/) de visionplatform.ai.
- Optimización del Modelo: Dependiendo de la plataforma de implementación, podría ser necesario optimizar el modelo YOLOv8 para el rendimiento. Técnicas como la cuantificación del modelo o la poda pueden usarse para reducir el tamaño del modelo sin comprometer significativamente la precisión, haciéndolo adecuado para dispositivos con recursos informáticos limitados.
- Integración con Sistemas Existentes: En muchos casos, será necesario integrar el modelo YOLOv8 en sistemas de software o hardware existentes. Esto requiere un entendimiento profundo de estos sistemas y la capacidad de interfaz del modelo YOLOv8 utilizando APIs o marcos de software apropiados.
- Pruebas y Validación: Antes de la implementación a gran escala, es crucial probar el modelo en un entorno controlado para asegurar que funciona como se espera. Esto implica validar la precisión, velocidad y fiabilidad del modelo bajo diferentes condiciones.
- Implementación y Monitoreo: Una vez probado, implementa el modelo en la plataforma elegida. El monitoreo continuo es esencial para asegurar que el modelo opera correctamente y de manera eficiente a lo largo del tiempo. Esto también ayuda a identificar y corregir cualquier problema que pueda surgir después de la implementación.
- Actualizaciones y Mantenimiento: Como cualquier software, el modelo YOLOv8 implementado podría requerir actualizaciones periódicas para mejoras o para abordar nuevos desafíos. El mantenimiento regular asegura que el modelo siga siendo efectivo y seguro.
Implementar YOLOv8 de manera efectiva exige un enfoque estratégico, considerando factores como el entorno operativo, limitaciones computacionales, y desafíos de integración. Cuando se hace correctamente, YOLOv8 puede mejorar significativamente las capacidades de sistemas en sectores como seguridad, salud, transporte y comercio minorista.
YOLOv8 vs YOLOv5: Comparando modelos de detección de objetos
Comparar YOLOv8 y YOLOv5 es esencial para entender los avances en los modelos de detección de objetos y decidir cuál modelo es más adecuado para una aplicación específica. Ambos modelos son de última generación en sus capacidades, pero tienen características y métricas de rendimiento distintas.
- Arquitectura del Modelo: YOLOv8 introduce varias mejoras arquitectónicas sobre YOLOv5. Estas incluyen mejoras en las capas de detección y la integración de nuevas tecnologías como la detección sin anclajes, que mejora la precisión y eficiencia del modelo.
- Precisión y Velocidad: YOLOv8 ha mostrado mejoras en precisión y velocidad de detección comparado con YOLOv5. Esto es particularmente evidente en escenarios de detección desafiantes que involucran objetos pequeños o superpuestos.
- Entrenamiento y Flexibilidad: Ambos modelos ofrecen flexibilidad en el entrenamiento, permitiendo a los usuarios entrenar con conjuntos de datos personalizados. Sin embargo, YOLOv8 proporciona características más avanzadas para el ajuste fino del modelo, lo que puede llevar a un mejor rendimiento en tareas específicas.
- Adecuación para la Aplicación: Mientras que YOLOv5 sigue siendo una opción poderosa para muchas aplicaciones, los avances de YOLOv8 lo hacen más adecuado para escenarios donde la máxima precisión y velocidad son cruciales.
- Comunidad y Soporte: Ambos modelos se benefician de un fuerte apoyo comunitario y son ampliamente utilizados, asegurando la mejora continua y extensos recursos para los desarrolladores.
En conclusión, mientras que YOLOv5 sigue siendo un modelo robusto y eficiente para la detección de objetos, YOLOv8 representa los últimos avances en el campo, ofreciendo una precisión y rendimiento mejorados. La elección entre los dos depende de los requisitos específicos de la aplicación, incluyendo factores como los recursos computacionales, la complejidad de la tarea de detección y la necesidad de procesamiento en tiempo real.
Explorando las Variantes de Modelos YOLO
La serie YOLO (You Only Look Once) abarca una gama de modelos diseñados para diversas aplicaciones en la detección de objetos, cada uno difiere en tamaño, velocidad y precisión. Desde el modelo YOLOv8n ligero, diseñado para dispositivos de borde, hasta el YOLOv8x altamente preciso, adecuado para investigaciones profundas, estas variantes atienden a diversos entornos informáticos y requisitos de aplicación. Esta exploración proporciona una visión general de los diferentes tipos de modelos YOLO, destacando sus características únicas y casos de uso óptimos.
| Atributo / Modelo | YOLOv8n (Nano) | YOLOv8s (Pequeño) | YOLOv8m (Mediano) | YOLOv8l (Grande) | YOLOv8x (Extra Grande) | |
|---|---|---|---|---|---|---|
| Tamaño | Muy Pequeño | Pequeño | Mediano | Grande | Muy Grande | |
| Velocidad | Muy Rápido | Rápido | Moderado | Lento | Muy Lento | |
| Precisión | Menor | Moderada | Alta | Muy Alta | La Más Alta | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Resolución | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
Comparando Yolo con modelos anteriores como YOLOv5, YOLOv6, YOLOv7 y YOLOv8 muestra que YOLOv8 es tanto mejor como más rápido que sus versiones anteriores.
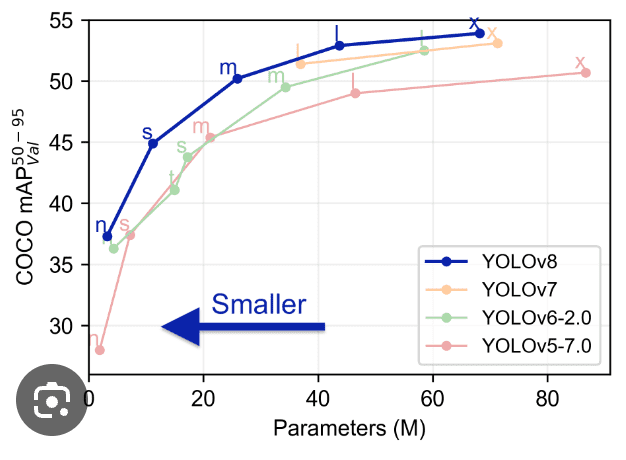
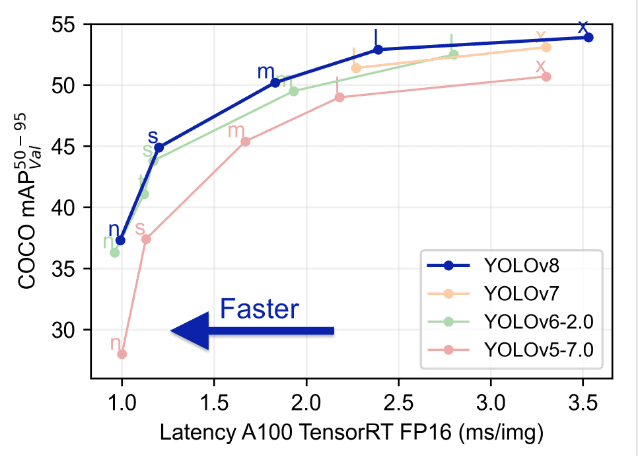
Características avanzadas en YOLOv8: Mejorando el rendimiento del modelo
El rendimiento del modelo YOLOv8 se destaca en el campo del reconocimiento de imágenes (computer vision), gracias a un conjunto de características avanzadas que mejoran sus capacidades. Estas características contribuyen significativamente al estatus de YOLOv8 como un modelo de última generación para tareas de detección y segmentación de objetos. Un análisis profundo de estas características revela por qué YOLOv8 es una opción principal para desarrolladores e investigadores:
- Detección sin anclajes: YOLOv8 se aleja de las cajas de anclaje tradicionales hacia un sistema de detección sin anclajes. Esto simplifica la arquitectura del modelo, incluyendo el modelo YOLOv8 Nano, y mejora su capacidad para predecir con precisión la ubicación de los objetos, especialmente para imágenes con formas y tamaños de objetos diversos.
- Capas convolucionales mejoradas: YOLOv8 introduce cambios en sus bloques convolucionales, reemplazando las convoluciones
6x6anteriores por unas de3x3. Este cambio mejora la capacidad del modelo para extraer y aprender características detalladas de las imágenes, mejorando su precisión de detección general. - Mejora de datos con Mosaico: Único en YOLOv8 es la implementación de la mejora de datos con mosaico durante el entrenamiento. Esta técnica une cuatro imágenes diferentes, mejorando la capacidad del modelo para detectar objetos en contextos y fondos variados. Sin embargo, YOLOv8 desactiva estratégicamente esta mejora en las últimas diez épocas de entrenamiento para optimizar el rendimiento.
- Integración con PyTorch: Como paquete de Python, YOLOv8 se beneficia de una integración perfecta con PyTorch, un marco líder en aprendizaje automático. Esta integración simplifica el proceso de entrenamiento y despliegue del modelo, especialmente cuando se trabaja con conjuntos de datos personalizados.
- Detección de objetos a múltiples escalas: La arquitectura de YOLOv8 está diseñada para la detección de objetos a múltiples escalas. Esta característica permite que el modelo detecte con precisión objetos de diferentes tamaños dentro de una imagen, haciéndolo versátil en diferentes escenarios de aplicación.
- Capacidades de procesamiento en tiempo real: Una de las ventajas más significativas de YOLOv8 es su capacidad para realizar detección de objetos en tiempo real. Esta característica es crucial para aplicaciones que requieren un análisis y respuesta inmediatos, como la conducción autónoma y la vigilancia en tiempo real.
Estas características avanzadas subrayan la capacidad de YOLOv8 como una herramienta poderosa en el ámbito del reconocimiento de imágenes (computer vision). Su combinación de precisión, velocidad y flexibilidad lo convierte en una excelente opción para un amplio espectro de aplicaciones de detección y segmentación de objetos.
Comenzando con YOLOv8: Desde la Configuración hasta el Despliegue
Comenzar con YOLOv8, especialmente para aquellos nuevos en el campo del reconocimiento de imágenes (computer vision), puede parecer desalentador. Sin embargo, con la guía adecuada, configurar y desplegar YOLOv8 puede ser un proceso simplificado. Aquí tienes una guía paso a paso para comenzar con YOLOv8:
- Entendiendo lo Básico: Antes de sumergirte en YOLOv8, es crucial tener un entendimiento básico de los conceptos de reconocimiento de imágenes y los principios detrás de los modelos de detección de objetos. Este conocimiento fundamental ayudará a comprender cómo opera YOLOv8.
- Configurando el Entorno: El primer paso técnico involucra configurar el entorno de programación. Esto incluye instalar Python, PyTorch y otras librerías necesarias. La documentación de YOLOv8 proporciona una guía detallada sobre el proceso de configuración.
- Accediendo a los Recursos de YOLOv8: El repositorio de GitHub de YOLOv8 es un recurso valioso. Contiene el código del modelo, pesos preentrenados y documentación extensa. Familiarizarse con estos recursos es crucial para una implementación exitosa.
- Entrenando el Modelo: Para entrenar YOLOv8, necesitas un conjunto de datos. Para principiantes, se aconseja usar un conjunto de datos estándar como COCO. El proceso de entrenamiento implica ajustar el modelo a tu conjunto de datos específico para optimizar su rendimiento para tu aplicación.
- Evaluando el Modelo: Después del entrenamiento, evalúa el rendimiento del modelo utilizando métricas estándar como precisión, recall y Precisión Media Promedio (mAP). Este paso es crucial para asegurar que el modelo está detectando objetos de manera precisa.
- Despliegue: Con un modelo entrenado y probado, como el modelo YOLOv8 Nano, el siguiente paso es el despliegue. Esto podría ser en un servidor para aplicaciones basadas en la web o en un dispositivo de borde para procesamiento en tiempo real usando visionplatform.ai.
- Aprendizaje Continuo: El campo del reconocimiento de imágenes está evolucionando rápidamente. Mantenerse actualizado con los últimos avances y aprender continuamente es clave para usar efectivamente YOLOv8 que haces efectivamente a través de una plataforma de reconocimiento de imágenes.
Comenzar con YOLOv8 implica una mezcla de comprensión teórica y aplicación práctica. Siguiendo estos pasos, uno puede implementar y utilizar exitosamente YOLOv8 en diversas tareas de reconocimiento de imágenes, aprovechando su pleno potencial en detección de objetos y segmentación de imágenes.
El futuro del reconocimiento de imágenes (computer vision): Novedades en YOLOv8 y más allá
El futuro del reconocimiento de imágenes es increíblemente prometedor, con YOLOv8 liderando la carga como el modelo más reciente y avanzado de la serie YOLO. La introducción de YOLOv8 marca un hito significativo en la evolución continua de las tecnologías de reconocimiento de imágenes, ofreciendo una precisión y eficiencia sin precedentes en las tareas de detección de objetos. Aquí están las novedades en YOLOv8 y las implicaciones para el futuro del reconocimiento de imágenes:
- Avances Tecnológicos: YOLOv8 ha introducido varias mejoras tecnológicas sobre sus predecesores. Estas incluyen redes convolucionales más eficientes, detección sin anclajes y algoritmos mejorados para la detección de objetos en tiempo real.
- Mayor Accesibilidad y Aplicación: Con YOLOv8, el campo del reconocimiento de imágenes se vuelve más accesible para una gama más amplia de usuarios, incluidos aquellos sin amplia experiencia en codificación. Esta democratización de la tecnología fomenta la innovación y alienta aplicaciones diversas en varios sectores.
- Integración con Tecnologías Emergentes: La compatibilidad de YOLOv8 con marcos de aprendizaje automático avanzados y su capacidad para integrarse con otras tecnologías de vanguardia, como la realidad aumentada y la robótica, señalan un futuro donde las soluciones de reconocimiento de imágenes son cada vez más versátiles y poderosas.
- Mejora de las Métricas de Rendimiento: YOLOv8 ha establecido nuevos estándares en el rendimiento del modelo, particularmente en términos de precisión y velocidad de procesamiento. Esta mejora es crucial para aplicaciones que requieren análisis en tiempo real, como vehículos autónomos y tecnologías para ciudades inteligentes.
- Predicciones para Desarrollos Futuros: Mirando hacia el futuro, podemos anticipar más avances en los modelos de reconocimiento de imágenes, con aún mayor precisión, velocidad y adaptabilidad. La integración de la IA con el reconocimiento de imágenes probablemente continuará evolucionando, llevando a sistemas más sofisticados y autónomos.
El desarrollo continuo de YOLOv8 y modelos similares es un testimonio de la naturaleza dinámica del campo del reconocimiento de imágenes. A medida que la tecnología avanza, podemos esperar ver más innovaciones revolucionarias que redefinirán los límites de lo que los sistemas de reconocimiento de imágenes pueden lograr.
Conclusión: El impacto de YOLOv8 en el reconocimiento de imágenes y la IA (computer vision)
En conclusión, YOLOv8 ha tenido un impacto sustancial en el campo del reconocimiento de imágenes y la IA (computer vision). Sus características avanzadas y capacidades representan un salto significativo hacia adelante en la tecnología de detección de objetos. Las implicaciones de los avances de YOLOv8 se extienden más allá del ámbito técnico, influyendo en diversas industrias y aplicaciones:
- Avances en la Detección de Objetos: YOLOv8 ha establecido un nuevo estándar en la detección de objetos con su mejora en precisión, velocidad y eficiencia. Esto tiene implicaciones para una amplia gama de aplicaciones, desde seguridad y vigilancia hasta salud, manufactura, logística y monitoreo ambiental.
- Democratización de la Tecnología de IA: Al hacer que la tecnología avanzada de reconocimiento de imágenes como el repositorio YOLOv8 sea más accesible y fácil de usar, YOLOv8 ha abierto la puerta para que una gama más amplia de usuarios y desarrolladores innoven y creen soluciones impulsadas por IA.
- Aplicaciones Mejoradas en el Mundo Real: Las aplicaciones prácticas de YOLOv8 en escenarios del mundo real son vastas. Su capacidad para proporcionar detección de objetos precisa y en tiempo real lo convierte en una herramienta invaluable en áreas como la conducción autónoma, la automatización industrial y las iniciativas de ciudades inteligentes.
- Inspirando Futuras Innovaciones: El éxito de YOLOv8 sirve como inspiración para futuros desarrollos en el reconocimiento de imágenes y la IA (computer vision). Establece las bases para más investigación e innovación, empujando los límites de lo que estas tecnologías pueden lograr.
En resumen, YOLOv8 no solo ha avanzado los aspectos técnicos del reconocimiento de imágenes, sino que también ha contribuido a la evolución más amplia de la IA. Su impacto se ve en las capacidades mejoradas de los sistemas de IA y las nuevas posibilidades que abre para la innovación y la aplicación práctica en diversos campos. A medida que continuamos explorando el potencial de la IA y el reconocimiento de imágenes, YOLOv8 sin duda será recordado como un hito en este viaje de avance tecnológico.
Preguntas Frecuentes Sobre YOLOv8
A medida que YOLOv8 continúa revolucionando el campo del reconocimiento de imágenes (computer vision), surgen numerosas preguntas sobre sus capacidades, aplicaciones y aspectos técnicos. Esta sección de preguntas frecuentes tiene como objetivo proporcionar respuestas claras y concisas a algunas de las consultas más comunes sobre YOLOv8. Ya seas un desarrollador experimentado o estés comenzando, estas respuestas te ayudarán a profundizar tu comprensión de este modelo de detección de objetos de última generación.
¿Qué es YOLOv8 y en qué se diferencia de las versiones anteriores de YOLO?
YOLOv8 es la última iteración en la serie YOLO de detectores de objetos en tiempo real, ofreciendo un rendimiento de primer nivel en términos de precisión y velocidad. Se basa en los avances de versiones anteriores como YOLOv5 con mejoras que incluyen arquitecturas avanzadas de backbone y neck, una cabeza Ultralytics sin anclas para una mayor precisión, y un equilibrio óptimo entre precisión y velocidad para la detección de objetos en tiempo real. También proporciona una gama de modelos preentrenados para diferentes tareas y requisitos de rendimiento.
¿Cómo mejora la detección sin anclas en YOLOv8 la detección de objetos?
YOLOv8 adopta un enfoque de detección sin anclas, prediciendo directamente los centros de los objetos, lo que simplifica la arquitectura del modelo y mejora la precisión. Este método es particularmente efectivo en la detección de objetos de diversas formas y tamaños. Al reducir el número de predicciones de cajas, acelera el proceso de Supresión No Máxima, crucial para refinar los resultados de detección, haciendo que YOLOv8 sea más eficiente y preciso en comparación con sus predecesores que usaban cajas de anclas.
¿Cuáles son las innovaciones clave y mejoras en la arquitectura de YOLOv8?
YOLOv8 introduce varias innovaciones arquitectónicas significativas, incluyendo el backbone CSPNet para una extracción eficiente de características y la cabeza PANet, que mejora la robustez contra la oclusión de objetos y las variaciones de escala. Su aumento de datos en mosaico durante el entrenamiento expone el modelo a una gama más amplia de escenarios, mejorando su generalización. YOLOv8 también combina el aprendizaje supervisado y no supervisado, contribuyendo a su rendimiento mejorado en tareas de detección de objetos y segmentación de instancias.
¿Cómo puedo comenzar a usar YOLOv8 para mis tareas de detección de objetos?
Para comenzar a usar YOLOv8, primero debes instalar el paquete de Python de YOLOv8. Luego, en tu script de Python, importa el módulo YOLOv8, crea una instancia de la clase YOLOv8 y carga los pesos preentrenados. A continuación, utiliza el método detect para realizar la detección de objetos en una imagen. Los resultados contendrán información sobre los objetos detectados, incluyendo sus clases, puntuaciones de confianza y coordenadas de las cajas delimitadoras.
¿Cuáles son algunas aplicaciones prácticas de YOLOv8 en diferentes industrias?
YOLOv8 tiene aplicaciones versátiles en diversas industrias debido a su alta velocidad y precisión. En vehículos autónomos, asiste en la identificación y clasificación de objetos en tiempo real. Se utiliza en sistemas de vigilancia para la detección y reconocimiento de objetos en tiempo real. Los minoristas utilizan YOLOv8 para analizar el comportamiento del cliente y gestionar el inventario. En el cuidado de la salud, ayuda en el análisis detallado de imágenes médicas, mejorando el diagnóstico y la atención al paciente.
¿Cómo se desempeña YOLOv8 en el conjunto de datos COCO y qué significa esto para su precisión?
YOLOv8 demuestra un rendimiento notable en el conjunto de datos COCO, un estándar de referencia para modelos de detección de objetos. Su precisión media promedio (mAP) varía según el tamaño del modelo, siendo el modelo más grande, YOLOv8x, el que alcanza el mAP más alto. Esto destaca mejoras significativas en precisión en comparación con versiones anteriores de YOLO. El alto mAP indica una precisión superior en la detección de una amplia gama de objetos bajo diversas condiciones.
¿Cuáles son las limitaciones de YOLOv8 y hay escenarios donde podría no ser la mejor opción?
A pesar de su impresionante rendimiento, YOLOv8 tiene limitaciones, particularmente en el soporte de modelos entrenados a altas resoluciones como 1280. Para aplicaciones que requieren inferencia de alta resolución, YOLOv8 puede no ser ideal. Sin embargo, para la mayoría de las aplicaciones, supera a los modelos anteriores en precisión y rendimiento. Sus detecciones sin anclas y la arquitectura mejorada lo hacen adecuado para una amplia gama de proyectos de reconocimiento de imágenes (computer vision).
¿Puedo entrenar YOLOv8 en un conjunto de datos personalizado y cuáles son algunos consejos para un entrenamiento efectivo?
Sí, YOLOv8 puede ser entrenado en conjuntos de datos personalizados. Un entrenamiento efectivo implica experimentar con técnicas de aumento de datos, notablemente el aumento en mosaico, y optimizar hiperparámetros como la tasa de aprendizaje, el tamaño del lote y el número de épocas. La evaluación regular y el ajuste fino son cruciales para maximizar el rendimiento. Elegir el conjunto de datos adecuado y el régimen de entrenamiento es clave para asegurar que el modelo se generalice bien a nuevos datos.
¿Cuáles son los pasos clave para desplegar YOLOv8 en un entorno real? Desplegando
Desplegar YOLOv8 implica optimizar el modelo para la plataforma objetivo, integrarlo en los sistemas existentes y probar su precisión y fiabilidad. La monitorización continua después del despliegue asegura una operación eficiente. Para dispositivos de borde, la optimización del modelo podría incluir cuantificación o poda. Las actualizaciones y el mantenimiento regulares son esenciales para mantener el modelo efectivo y seguro en diversas aplicaciones.
¿Cómo se ve el futuro para YOLOv8 y sus aplicaciones en el reconocimiento de imágenes (computer vision)?
El futuro de YOLOv8 en el reconocimiento de imágenes (computer vision) parece prometedor, con potencial para una mayor precisión, velocidad y versatilidad. Su tecnología en evolución, incluyendo la detección de objetos y la segmentación de instancias, podría encontrar nuevas aplicaciones en áreas como la imagenología médica, la conservación de la vida silvestre y sistemas autónomos más avanzados. Los esfuerzos continuos de investigación y desarrollo probablemente empujarán los límites de YOLOv8, consolidando aún más su posición como un modelo líder en detección de objetos.