

Introduction à YOLOv10
YOLOv10 est la dernière innovation de la série YOLO (You Only Look Once), un cadre révolutionnaire dans le domaine de la vision par ordinateur (computer vision). Connu pour ses capacités de détection d’objets en temps réel, YOLOv10 perpétue l’héritage de ses prédécesseurs en fournissant une solution robuste qui combine efficacité et précision. Cette nouvelle version vise à repousser encore plus les limites de performance et d’efficacité des YOLOs, tant du point de vue du post-traitement que de l’architecture du modèle.
La détection d’objets en temps réel vise à prédire avec précision les catégories et les positions des objets dans une image avec un minimum de latence. Au cours des dernières années, les YOLOs se sont imposés comme un choix de premier plan pour la détection d’objets en temps réel en raison de leur équilibre efficace entre performance et efficacité. Le pipeline de détection de YOLO comprend deux composants principaux : le processus d’avancement du modèle et l’étape de post-traitement, impliquant généralement une suppression des maximums non maximaux (NMS).
YOLOv10 introduit plusieurs innovations clés pour pallier les limitations des versions précédentes, telles que la dépendance au NMS pour le post-traitement, qui peut entraîner une augmentation de la latence d’inférence et une redondance computationnelle. En tirant parti des affectations doubles constantes pour une formation sans NMS, YOLOv10 atteint simultanément une performance compétitive et une faible latence d’inférence. Cette approche permet au modèle de contourner le besoin de NMS pendant l’inférence, conduisant à un déploiement de bout en bout plus efficace.
De plus, YOLOv10 présente une stratégie de conception de modèle axée sur l’efficacité et la précision. Cela implique d’optimiser de manière globale divers composants des YOLOs, tels que la tête de classification légère, le sous-échantillonnage découplé spatial-canal et la conception de bloc guidée par le rang. Ces améliorations architecturales réduisent la charge computationnelle et améliorent la capacité du modèle, résultant en une amélioration significative de la performance et de l’efficacité à travers diverses échelles de modèle.
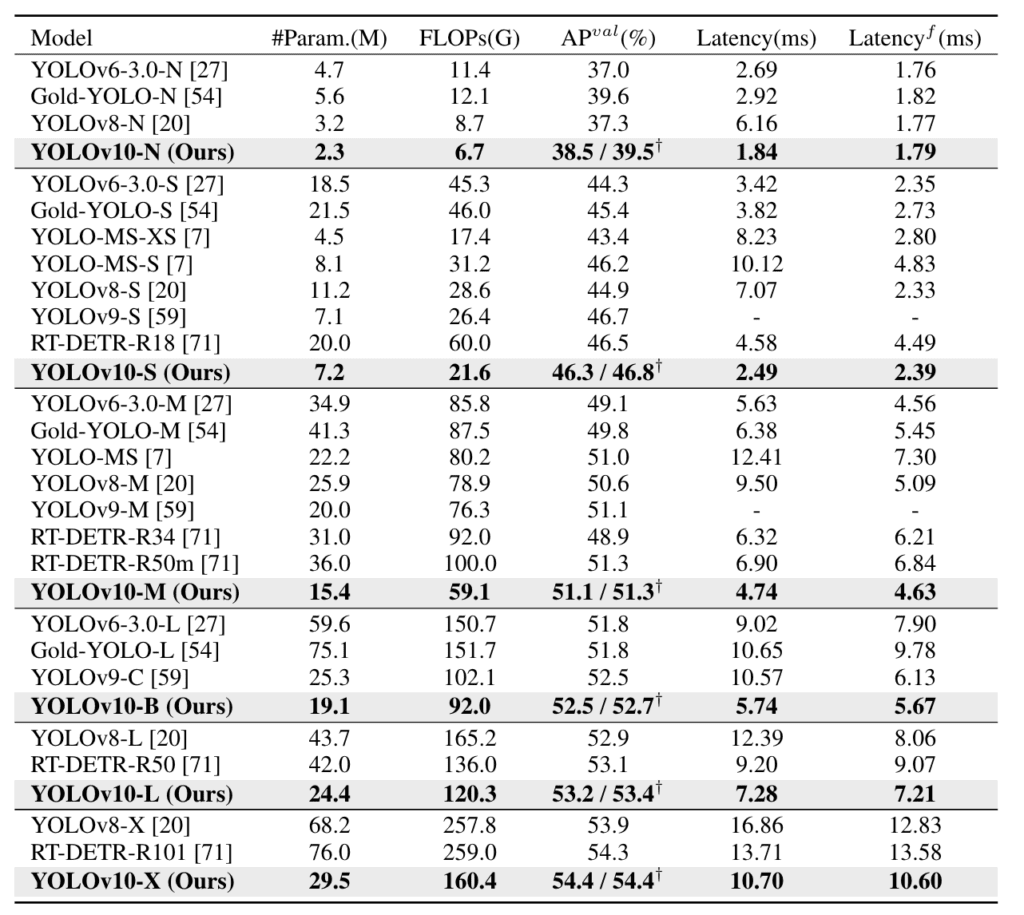
Des expériences approfondies montrent que YOLOv10 atteint une performance de pointe sur le dataset COCO, démontrant des compromis supérieurs entre précision et coût computationnel. Par exemple, YOLOv10-S est 1,8 fois plus rapide que RT-DETR-R18 pour un AP similaire sur COCO, tout en ayant un nombre de paramètres et de FLOPs plus réduit. Comparé à YOLOv9-C, YOLOv10-B a 46 % moins de latence et 25 % moins de paramètres pour la même performance, illustrant ainsi son efficacité et son efficience.
Évolution de YOLO : de YOLOv8 à YOLOv9
La série YOLO a subi une évolution substantielle, chaque nouvelle version s’appuyant sur les succès et abordant les limitations de ses prédécesseurs. YOLOv8 et YOLOv9 ont introduit plusieurs améliorations clés qui ont considérablement avancé les capacités de détection d’objets en temps réel.
YOLOv8 a apporté des innovations telles que le bloc de construction C2f pour une extraction et une fusion de caractéristiques efficaces, ce qui a aidé à améliorer la précision et l’efficacité du modèle. De plus, YOLOv8 a optimisé l’architecture du modèle pour réduire le coût computationnel et améliorer la vitesse d’inférence, le rendant ainsi une option plus viable pour les applications en temps réel, ceci en plus des optimisations habituelles des hyperparamètres de v8.
Cependant, malgré ces avancées, il restait encore des redondances computationnelles notables et des limitations en termes d’efficacité, notamment en raison de la dépendance à NMS pour le post-traitement. Cette dépendance entraînait souvent une efficacité sous-optimale et augmentait la latence d’inférence, empêchant les modèles d’atteindre un déploiement optimal de bout en bout.
YOLOv9 visait à résoudre ces problèmes en introduisant l’architecture GELAN pour améliorer la structure du modèle et l’Information de Gradient Programmable (PGI) pour améliorer le processus de formation. Ces améliorations ont abouti à de meilleures performances et efficacité, mais les défis fondamentaux associés à NMS et à la surcharge computationnelle demeuraient.
YOLOv10 s’appuie sur ces fondations en introduisant des attributions doubles cohérentes pour un entraînement sans NMS et une stratégie de conception de modèle axée sur l’efficacité et la précision. Ces innovations permettent à YOLOv10 d’atteindre des performances compétitives avec une faible latence d’inférence et de réduire la surcharge computationnelle associée aux modèles YOLO précédents.
Comparé à YOLOv9-C, YOLOv10 atteint des performances et une efficacité de pointe à travers différentes échelles de modèle. Par exemple, YOLOv10-S est 1,8 fois plus rapide que RT-DETR-R18 pour un AP similaire sur COCO, tout en ayant moins de paramètres et de FLOPs. Cette amélioration significative des performances et de l’efficacité illustre l’impact des avancées architecturales et des objectifs d’optimisation introduits dans YOLOv10.
Caractéristiques clés de YOLOv10
YOLOv10 introduit plusieurs innovations qui améliorent ses performances et son efficacité. L’une des caractéristiques les plus significatives est la conception de modèle guidée par l’efficacité et la précision globales. Cette stratégie implique une optimisation complète de divers composants au sein du modèle, garantissant son fonctionnement efficace tout en maintenant une haute précision.
Pour réaliser une détection d’objets de bout en bout efficace, YOLOv10 utilise une tête de classification légère qui réduit la charge computationnelle sans sacrifier les performances. Ce choix de conception est crucial pour les applications en temps réel, où la vitesse et la précision sont primordiales. De plus, le modèle intègre un sous-échantillonnage découplé spatial-canal, qui optimise les processus de réduction spatiale et de transformation des canaux. Cette technique minimise la perte d’informations et réduit davantage la charge computationnelle.
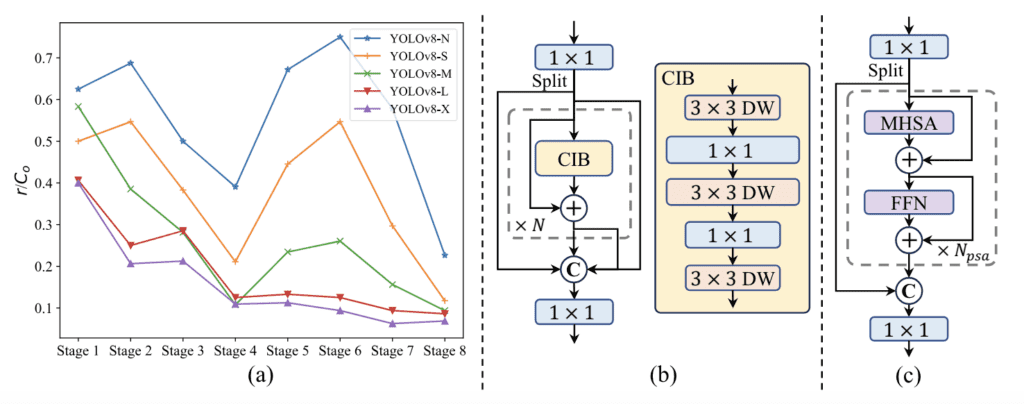
YOLOv10 bénéficie également de la conception de blocs guidée par le rang. Cette approche analyse la redondance intrinsèque de chaque étape du modèle et ajuste la complexité en conséquence. En ciblant les étapes avec une redondance computationnelle notable, le modèle atteint un meilleur équilibre entre efficacité et précision.
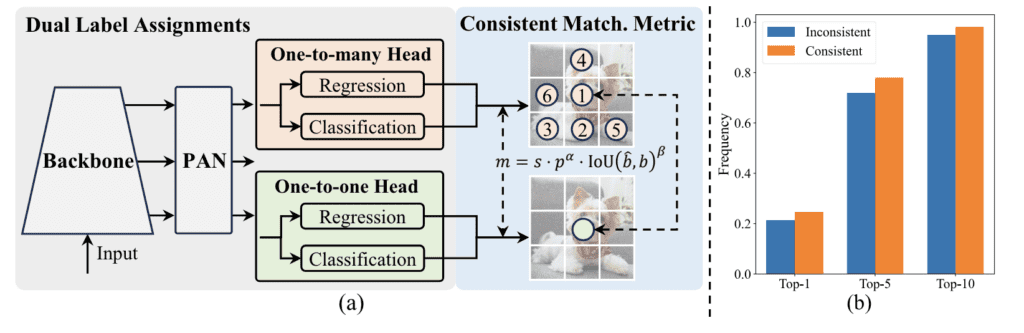
Une autre caractéristique clé est les doubles affectations cohérentes pour l’entraînement sans NMS. Cette méthode remplace la suppression non maximale traditionnelle par une stratégie de marquage plus efficace et précise. En utilisant des affectations de labels doubles, YOLOv10 peut maintenir des performances compétitives et une faible latence d’inférence, le rendant adapté à diverses applications en temps réel.
De plus, YOLOv10 emploie de grandes convolutions à noyau et des modules de semi-attention partiels pour améliorer l’apprentissage de la représentation globale. Ces composants améliorent la capacité du modèle à capturer des motifs complexes dans les données, conduisant à de meilleures performances dans les tâches de détection d’objets.
Comprendre la suppression non maximale (NMS) dans la détection d’objets : Un voyage avec YOLO
Dans le domaine en rapide évolution de la vision par ordinateur (computer vision), l’un des défis critiques est de détecter avec précision les objets dans les images tout en minimisant la redondance. C’est là que la suppression non maximale (NMS) entre en jeu. Plongeons dans ce qu’est la NMS, pourquoi elle est importante, et comment les dernières avancées dans les modèles YOLO (You Only Look Once), spécifiquement YOLOv10, révolutionnent la détection d’objets en minimisant la dépendance à la NMS.
Qu’est-ce que la suppression non maximale (NMS) ?
La suppression non maximale (NMS) est une technique de post-traitement utilisée dans les algorithmes de détection d’objets pour affiner les résultats en éliminant les boîtes englobantes redondantes. L’objectif principal de la NMS est de s’assurer que pour chaque objet détecté, seule la boîte englobante la plus précise est conservée, tandis que celles qui se chevauchent et sont moins précises sont supprimées. Ce processus aide à créer une sortie plus propre et plus précise, ce qui est crucial pour les applications nécessitant une haute précision et efficacité.
Comment fonctionne la NMS ?
Le processus de NMS peut être décomposé en quelques étapes simples :
1. Trier les détections :
D’abord, toutes les boîtes englobantes détectées sont triées en fonction de leurs scores de confiance par ordre décroissant. Le score de confiance indique la probabilité que la boîte englobante représente précisément un objet.
2. Sélectionner la boîte principale :
La boîte englobante avec le score de confiance le plus élevé est sélectionnée en premier. Cette boîte est considérée comme la plus susceptible d’être correcte.
3. Supprimer les chevauchements :
Toutes les autres boîtes englobantes qui se chevauchent de manière significative avec la boîte sélectionnée sont supprimées. Le chevauchement est mesuré en utilisant l’Intersection sur Union (IoU), une métrique qui calcule le rapport entre la zone de chevauchement et la zone totale couverte par les deux boîtes. Typiquement, les boîtes avec un IoU au-dessus d’un certain seuil (par exemple, 0,5) sont supprimées.
4. Répéter :
Le processus est répété avec la boîte de confiance suivante la plus élevée, continuant jusqu’à ce que toutes les boîtes soient traitées.
L’importance de la NMS
La NMS joue un rôle crucial dans la détection d’objets pour plusieurs raisons :
• Réduit la redondance : En éliminant les détections multiples du même objet, la NMS garantit que chaque objet est représenté par une seule boîte englobante la plus précise.
• Améliore la précision : Elle aide à améliorer la précision de la détection en se concentrant sur la prédiction de la plus haute confiance.
• Améliore l’efficacité : Réduire le nombre de boîtes englobantes rend la sortie plus propre et plus interprétable, ce qui est particulièrement important pour les applications en temps réel.
YOLO et NMS
Les modèles YOLO ont été une révolution dans la détection d’objets en temps réel, connus pour leur équilibre entre vitesse et précision. Cependant, les modèles YOLO traditionnels dépendaient fortement de la NMS pour filtrer les détections redondantes après que le réseau ait fait ses prédictions. Cette dépendance à la NMS, bien qu’efficace, ajoutait une étape supplémentaire dans le pipeline de post-traitement, affectant la vitesse d’inférence globale.
La révolution YOLOv10 : Formation sans NMS
Avec l’introduction de YOLOv10, nous voyons un bond significatif en avant pour minimiser la dépendance à la NMS. YOLOv10 introduit une formation sans NMS, une approche révolutionnaire qui améliore l’efficacité et la vitesse du modèle. Voici comment YOLOv10 réalise cela :
1. Affectations doubles cohérentes :
YOLOv10 emploie une stratégie d’affectations doubles cohérentes, qui combine des affectations de labels doubles et une métrique de correspondance cohérente. Cette méthode permet une formation efficace sans nécessiter de NMS pendant l’inférence.
2. Affectations de labels doubles :
En intégrant des affectations de labels un-à-plusieurs et un-à-un, YOLOv10 bénéficie de signaux de supervision riches pendant la formation, menant à une haute efficacité et des performances compétitives sans nécessité de NMS post-traitement.
3. Métrique de correspondance :
Une métrique de correspondance cohérente garantit que la supervision fournie par la tête un-à-plusieurs s’aligne harmonieusement avec la tête un-à-un, optimisant le modèle pour de meilleures performances et une latence réduite.
L’impact de YOLOv10 sans NMS
Les innovations dans YOLOv10 offrent plusieurs avantages :
• Inférence plus rapide : Sans la nécessité de NMS, YOLOv10 réduit considérablement le temps d’inférence, ce qui est idéal pour les applications en temps réel où la vitesse est critique.
• Effi
Repères de performance
Les repères de performance de YOLOv10 soulignent ses avancées par rapport aux modèles précédents de la série YOLO. Des expériences approfondies montrent que YOLOv10 obtient des résultats remarquables en termes de vitesse et de précision. La stratégie de conception du modèle, axée sur l’efficacité et la précision, garantit qu’il peut gérer facilement les tâches de détection d’objets en temps réel.
Comparé à YOLOv9-C, YOLOv10 réalise des améliorations significatives en termes de latence et d’efficacité des paramètres. YOLOv10-B a 46 % de latence en moins et 25 % de paramètres en moins pour la même performance. Cette réduction de la charge de calcul rend YOLOv10 un choix plus pratique pour les applications nécessitant un déploiement rapide et de hautes performances.
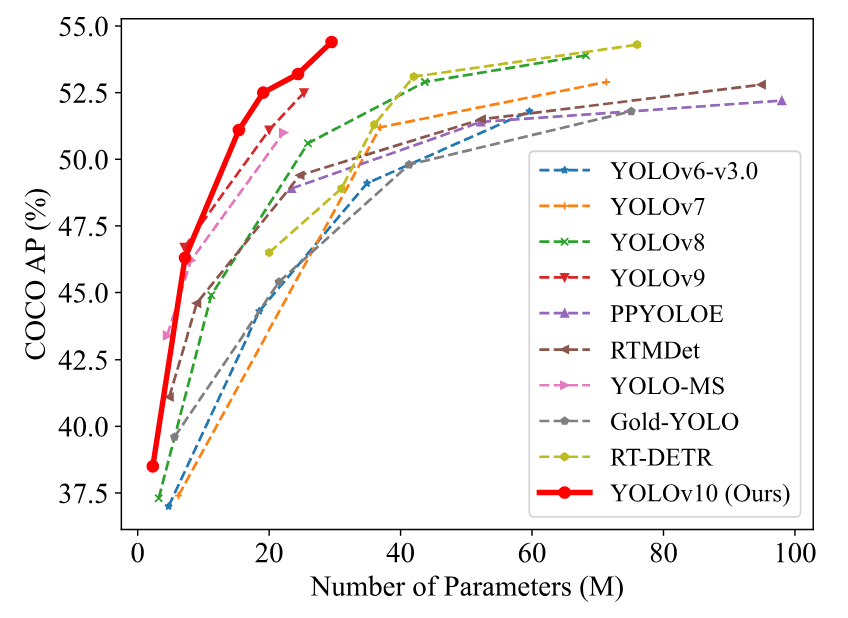

La performance de YOLOv10 sur le jeu de données COCO illustre davantage ses capacités. Le modèle atteint un AP similaire sur COCO à celui de RT-DETR-R18, tout en étant 1,8 fois plus rapide. Cet avantage en termes de vitesse est crucial pour les applications où le traitement en temps réel est essentiel. La capacité du modèle à maintenir une haute précision avec moins de ressources démontre son efficacité et son efficience.
De plus, les innovations de YOLOv10 en matière de suppression non maximale et de conception de modèle holistique contribuent à ses performances supérieures. Les affectations doubles cohérentes pour la formation sans NMS permettent au modèle de contourner les goulets d’étranglement du post-traitement traditionnel, résultant en des détections plus rapides et plus précises.
L’intégration d’une tête de classification légère et d’un sous-échantillonnage découplé spatial-canal joue également un rôle significatif dans l’amélioration des performances de YOLOv10. Ces composants réduisent le coût computationnel tout en préservant la précision de détection du modèle.
YOLOv10 établit un nouveau repère dans le domaine de la détection d’objets en temps réel de bout en bout. Ses caractéristiques innovantes et son optimisation complète lui permettent de fournir des performances et une efficacité de pointe à travers diverses échelles de modèle. En conséquence, YOLOv10 convient bien à une large gamme d’applications, de la conduite autonome à la surveillance de sécurité, où la vitesse et la précision sont critiques.
YOLOv10 et VisionPlatform.ai : un mariage parfait
VisionPlatform.ai se distingue dans le domaine de la vision par ordinateur (computer vision) en offrant une plateforme de vision complète et conviviale sans code vision platform pour transformer N’IMPORTE quelle caméra en caméra IA. L’intégration de YOLOv10 avec VisionPlatform.ai crée une combinaison puissante pour la détection d’objets de bout en bout efficace. YOLOv10 utilise des techniques innovantes qui s’alignent bien avec l’engagement de VisionPlatform.ai envers la haute performance et la facilité de déploiement.
Un des principaux avantages de l’utilisation de YOLOv10 avec VisionPlatform.ai est la capacité à tirer parti du traitement local directement sur la caméra (appelé edge computing) via le NVIDIA Jetson tel que AGX Orin, NX Orin ou Nano Orin, ce qui accélère le déploiement de YOLOv10 pour les tâches de détection d’objets en temps réel et le traitement en temps réel. Cette intégration réduit la surcharge computationnelle et améliore l’efficacité de la plateforme. Pendant ce temps, en profitant des avantages du modèle de conception de YOLOv10 axé sur l’efficacité et la précision, VisionPlatform.ai peut offrir des performances de pointe dans diverses applications, telles que la logistique et la gestion de la chaîne d’approvisionnement.
De plus, VisionPlatform.ai utilise NVIDIA DeepStream, qui optimise davantage le déploiement de YOLOv10 pour la détection d’objets en temps réel. Cette combinaison garantit que la plateforme peut répondre aux exigences exigeantes des applications IA modernes, offrant aux utilisateurs une solution robuste et évolutive. L’architecture efficace de YOLOv10 et l’interface conviviale de VisionPlatform.ai la rendent accessible tant aux utilisateurs novices qu’aux experts.
En outre, VisionPlatform.ai prend en charge divers modèles et configurations, permettant aux utilisateurs de personnaliser leurs installations en fonction de besoins spécifiques. La flexibilité de la plateforme garantit qu’elle peut s’adapter à différentes catégories et positions d’objets, améliorant ainsi sa polyvalence. Des expériences approfondies démontrent que l’intégration de YOLOv10 avec VisionPlatform.ai conduit à des performances et une efficacité supérieures, en faisant un choix idéal pour les entreprises à la recherche de solutions IA avancées.
YOLOv10 et NMS : Aller au-delà du post-traitement traditionnel
YOLOv10 introduit une approche révolutionnaire de la détection d’objets en éliminant le besoin de suppression des maximums non-maximaux (NMS). Le NMS traditionnel, utilisé dans les versions précédentes de YOLO, entraînait souvent une augmentation de la latence d’inférence et une redondance computationnelle notable. Cette nouvelle méthode utilise des attributions doubles cohérentes pour un entraînement sans NMS, améliorant considérablement l’efficacité et la précision du modèle. Cette conception garantit que YOLOv10 peut offrir des performances et une efficacité de pointe dans diverses applications, de la conduite autonome à la surveillance de sécurité / CCTV.
Au cours des dernières années, la dépendance au NMS a posé des défis dans l’optimisation des performances des détecteurs d’objets. YOLOv10 relève ces défis grâce à une stratégie novatrice qui remplace le NMS par des attributions de labels doubles. Cette approche garantit que le modèle peut gérer efficacement les attributions de un-à-plusieurs et de un-à-un, réduisant le coût computationnel et améliorant la vitesse de détection. Des expériences approfondies démontrent que YOLOv10 atteint des performances de pointe sans les goulots d’étranglement du post-traitement traditionnel.
Les attributions doubles pour l’entraînement sans NMS permettent à YOLOv10 de maintenir des performances compétitives et une faible latence d’inférence. Comparé à YOLOv9-C, YOLOv10 obtient une meilleure efficacité et précision, démontrant sa supériorité dans la détection d’objets en temps réel. Par exemple, YOLOv10-B a 46% moins de latence, mettant en avant son optimisation avancée.
Tout en profitant de ces améliorations, YOLOv10 conserve une architecture robuste qui soutient l’apprentissage de représentation globale. Cette capacité permet au modèle de prédire avec précision les catégories et positions des objets, même dans des scénarios complexes. L’élimination du NMS non seulement simplifie le processus de détection, mais améliore également la performance globale et la scalabilité du modèle.
En résumé, l’approche innovante de YOLOv10 pour l’entraînement sans NMS établit une nouvelle référence dans la détection d’objets. En optimisant de manière globale divers composants et en employant des attributions doubles cohérentes, YOLOv10 offre des performances et une efficacité supérieures, faisant de lui un choix privilégié pour les applications en temps réel.
Directions futures et conclusion
YOLOv10 représente un bond significatif en avant dans la détection d’objets en temps réel, mais il reste encore de la place pour des avancées supplémentaires. Les directions futures dans le développement de YOLOv10 se concentreront probablement sur l’amélioration de ses capacités actuelles tout en explorant de nouvelles applications et méthodologies. Un domaine prometteur est l’intégration de stratégies d’augmentation de données plus sophistiquées. Ces stratégies peuvent aider le modèle à mieux généraliser à travers des ensembles de données diversifiés, améliorant sa robustesse et sa précision dans différents scénarios.
Au cours des dernières années, les modèles YOLO ont continuellement évolué pour répondre aux demandes croissantes de la détection d’objets en temps réel. YOLOv10 continue cette tendance en repoussant les limites de la performance et de l’efficacité. Les itérations futures pourraient s’appuyer sur cette base, en incorporant des avancées dans l’accélération matérielle et en tirant parti des technologies émergentes pour réduire davantage la latence d’inférence et augmenter la puissance de traitement.
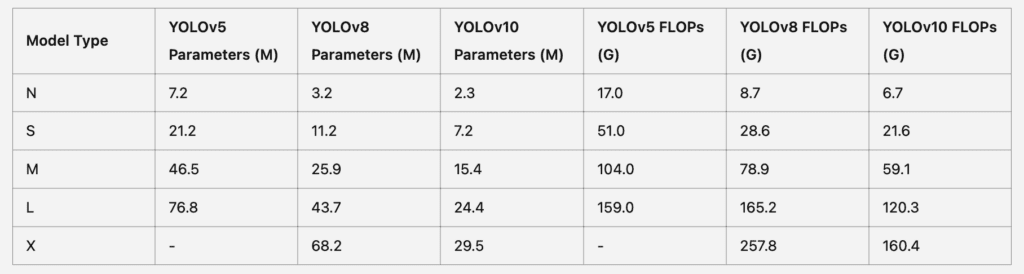
Une autre direction potentielle implique l’optimisation complète de divers composants du modèle pour gérer des tâches de détection plus complexes. Cette optimisation pourrait inclure des améliorations dans la capacité du modèle à détecter et classifier avec précision une gamme plus large de catégories et de positions, le rendant encore plus polyvalent. De plus, des améliorations dans les attributions de labels un-à-plusieurs et un-à-un pourraient affiner davantage la précision de détection du modèle.
La collaboration avec des plateformes comme GitHub et la communauté open-source plus large sera cruciale pour stimuler ces avancées. En partageant des insights et des développements, les chercheurs et les développeurs peuvent pousser collectivement les capacités de YOLOv10 et des modèles futurs.
En conclusion, YOLOv10 établit une nouvelle référence pour les modèles de pointe en termes de performance et d’efficacité. Son architecture innovante et ses méthodologies de formation fournissent un cadre robuste pour la détection d’objets en temps réel. À mesure que le modèle continue d’évoluer, il inspirera sans aucun doute davantage de recherches et de développements, faisant avancer le domaine de la vision par ordinateur (computer vision). En embrassant les avancées futures et en tirant parti de la collaboration communautaire, YOLOv10 maintiendra sa position à l’avant-garde de la technologie de détection d’objets en temps réel.
Questions Fréquentes sur YOLOv10
Alors que YOLOv10 continue de repousser les limites de la détection d’objets en temps réel, de nombreux développeurs et passionnés se posent des questions sur ses capacités, ses applications et ses améliorations par rapport aux versions précédentes. Ci-dessous, nous répondons à certaines des questions les plus courantes sur YOLOv10 pour vous aider à comprendre ses fonctionnalités et ses utilisations potentielles.
Qu’est-ce que YOLOv10 ?
YOLOv10 est la dernière itération de la série YOLO (You Only Look Once), spécialement conçue pour la détection d’objets en temps réel. Il introduit des améliorations significatives en termes d’efficacité et de précision en employant un design de modèle piloté par l’efficacité et la précision. YOLOv10 élimine également le besoin de suppression non maximale (NMS) pendant l’inférence, ce qui résulte en un traitement plus rapide et une réduction de la surcharge computationnelle.
En quoi YOLOv10 est-il meilleur que YOLOv9 ?
YOLOv10 améliore YOLOv9 en incorporant des attributions doubles cohérentes pour une formation sans NMS, ce qui réduit considérablement la latence d’inférence. De plus, YOLOv10 utilise une tête de classification légère et un sous-échantillonnage découplé spatial-canal, qui améliorent ensemble l’efficacité et la précision du modèle. Comparé à YOLOv9-C, YOLOv10-B a 46 % de latence en moins et 25 % de paramètres en moins.
Quelles sont les caractéristiques clés de YOLOv10 ?
Les caractéristiques clés de YOLOv10 incluent son design de modèle piloté par l’efficacité et la précision, qui optimise de manière globale divers composants du modèle. Il utilise une tête de classification légère et un sous-échantillonnage découplé spatial-canal pour réduire la surcharge computationnelle. De plus, YOLOv10 emploie des convolutions à grand noyau et des modules d’auto-attention partiels pour améliorer l’apprentissage de la représentation globale, conduisant à des performances et une efficacité de pointe.
Comment YOLOv10 gère-t-il la suppression non maximale (NMS) ?
YOLOv10 gère la suppression non maximale (NMS) en l’éliminant complètement pendant l’inférence. Au lieu de cela, il utilise des attributions doubles cohérentes pour une formation sans NMS. Cette approche permet au modèle de maintenir une performance compétitive tout en réduisant la latence d’inférence et la redondance computationnelle, améliorant ainsi considérablement l’efficacité et la précision dans les tâches de détection d’objets.
Quels ensembles de données sont utilisés pour évaluer YOLOv10 ?
YOLOv10 est principalement évalué sur l’ensemble de données COCO, qui comprend 80 classes pré-entraînées et est largement utilisé pour évaluer les modèles de détection d’objets. Des expériences approfondies sur l’ensemble de données COCO démontrent que YOLOv10 atteint des performances de pointe, avec des améliorations significatives tant en précision qu’en efficacité par rapport aux versions précédentes de YOLO et à d’autres détecteurs d’objets en temps réel.
Quelles sont les applications réelles de YOLOv10 ?
YOLOv10 est utilisé dans une variété d’applications réelles, y compris la conduite autonome, la surveillance et la logistique. Ses capacités de détection d’objets efficaces et précises le rendent idéal pour des tâches telles que l’identification des piétons et des véhicules en temps réel. De plus, en logistique, il aide à la gestion des inventaires et au suivi des colis, améliorant considérablement l’efficacité opérationnelle et la précision.
Comment YOLOv10 se compare-t-il à d’autres modèles de pointe ?
YOLOv10 se compare favorablement à d’autres modèles de pointe comme RT-DETR-R18 et les versions précédentes de YOLO. Il atteint un AP similaire sur l’ensemble de données COCO tout en étant 1,8 fois plus rapide. Comparé à YOLOv9-C, YOLOv10 offre 46 % de latence en moins et 25 % de paramètres en moins, le rendant très efficace pour les applications en temps réel.
YOLOv10 peut-il être intégré à des plateformes comme VisionPlatform.ai ?
Oui, YOLOv10 peut être intégré à des plateformes comme VisionPlatform.ai. Cette intégration tire parti de NVIDIA Jetson et NVIDIA DeepStream pour améliorer les capacités de traitement en temps réel. L’interface conviviale et l’infrastructure robuste de VisionPlatform.ai soutiennent le déploiement efficace de bout en bout de YOLOv10, le rendant accessible aussi bien aux novices qu’aux experts.
Comment les développeurs peuvent-ils commencer avec YOLOv10 ?
Les développeurs peuvent commencer avec YOLOv10 en accédant à son dépôt GitHub, qui fournit une documentation complète et des exemples de code. Le dépôt comprend un paquet Python téléchargeable qui simplifie le processus de déploiement. De plus, de nombreuses ressources et un soutien communautaire sont disponibles pour aider les développeurs à implémenter et personnaliser YOLOv10 pour diverses applications.
Quelles sont les orientations futures pour le développement de YOLOv10 ?
Les orientations futures pour le développement de YOLOv10 incluent l’amélioration des stratégies d’augmentation des données et l’optimisation du modèle pour de meilleures performances sur des ensembles de données diversifiés. Des recherches supplémentaires pourraient se concentrer sur la réduction des coûts computationnels tout en augmentant la précision. La collaboration au sein de la communauté open-source continuera également à stimuler les avancées, assurant que YOLOv10 reste à la pointe de la technologie de détection d’objets en temps réel (vision par ordinateur).