
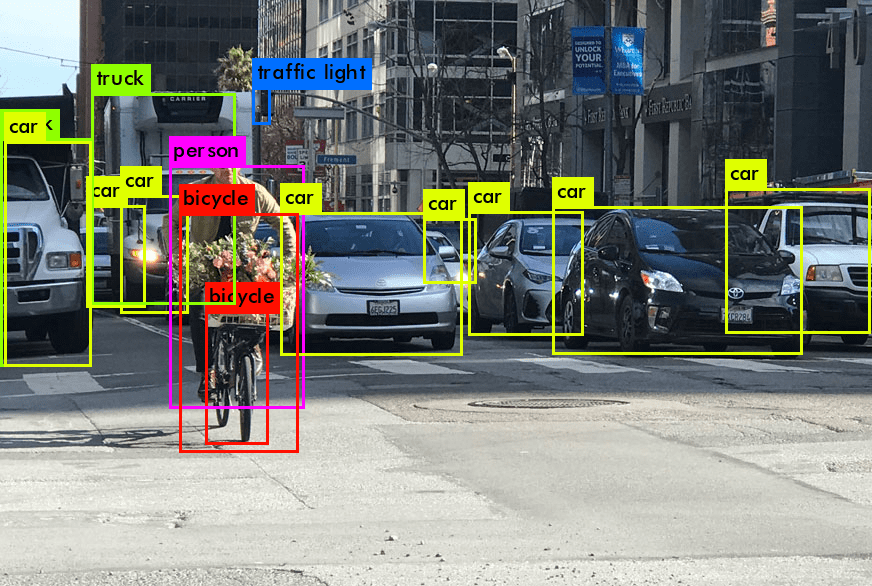
Introduzione al rilevamento degli oggetti nella visone artificale (computer vision)
Utilizzando il rilevamento degli oggetti, un compito fondamentale della visone artificale (computer vision), ha rivoluzionato il modo in cui le macchine interpretano il mondo visivo. A differenza della classificazione delle immagini, dove l’obiettivo è classificare un’intera immagine, il rilevamento degli oggetti può essere utilizzato per identificare e localizzare oggetti all’interno di un’immagine o di un fotogramma video (che è lo stesso di un’immagine / foto). Questo processo include il riconoscimento dell’oggetto specifico, la localizzazione dell’oggetto e la determinazione della sua posizione tramite un riquadro di delimitazione. Il rilevamento degli oggetti colma il divario tra la classificazione delle immagini e compiti più complessi come la segmentazione delle immagini, dove l’obiettivo è etichettare ogni pixel dell’immagine come appartenente a un singolo oggetto specifico.
L’emergere dell’apprendimento profondo, in particolare l’uso delle Reti Neurali Convoluzionali (CNN), ha notevolmente avanzato il rilevamento degli oggetti. Queste reti neurali elaborano ed analizzano efficacemente i dati visivi, rendendoli ideali per il rilevamento di oggetti in un’immagine o video. Sviluppi chiave come YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) e reti basate su proposte di regione come Mask R-CNN hanno ulteriormente migliorato l’accuratezza e l’efficienza dei sistemi di rilevamento degli oggetti. Questi modelli possono eseguire il rilevamento in tempo reale, un fattore cruciale per applicazioni come la guida autonoma o la sorveglianza in tempo reale.
Inoltre, l’integrazione delle tecniche di apprendimento automatico ha permesso ai sistemi di rilevamento degli oggetti di classificare e segmentare vari oggetti in ambienti complessi. Questa capacità è vitale per una gamma di applicazioni, dalla rilevazione dei pedoni nelle infrastrutture delle città intelligenti al controllo di qualità nella produzione.
Comprendere il Dataset per il Rilevamento degli Oggetti
La base di qualsiasi sistema di rilevamento oggetti di successo risiede nel suo dataset. Un dataset per il rilevamento degli oggetti consiste in immagini o video annotati per addestrare un rilevatore. Queste annotazioni includono tipicamente riquadri di delimitazione attorno agli oggetti ed etichette che indicano la classe di ciascun oggetto. La qualità, la diversità e la dimensione del dataset giocano un ruolo cruciale nelle prestazioni dei modelli di rilevamento oggetti. Ad esempio, dataset più grandi con una vasta varietà di oggetti e scenari permettono alla rete neurale di apprendere caratteristiche più robuste e generalizzabili.
Dataset come PASCAL VOC, MS COCO e ImageNet sono stati fondamentali per il progresso del rilevamento oggetti. Forniscono un vasto range di immagini annotate, da oggetti quotidiani a scenari specifici, aiutando nello sviluppo di modelli di rilevamento versatili e accurati. Questi dataset non solo facilitano l’addestramento dei modelli, ma servono anche come benchmark per valutare e confrontare le prestazioni di vari algoritmi di rilevamento oggetti.
L’addestramento di un modello per il rilevamento oggetti implica anche l’uso di tecniche come il transfer learning, dove un modello pre-addestrato su un grande dataset viene perfezionato con un dataset più piccolo e specifico. Questo approccio è particolarmente vantaggioso quando i dati disponibili per il rilevamento oggetti sono limitati o quando addestrare un modello da zero è computazionalmente costoso.
In sintesi, il dataset è un componente cruciale nel rilevamento oggetti, influenzando direttamente la capacità di un modello di rilevare oggetti accuratamente in diversi contesti e ambienti. Man mano che i compiti e la tecnologia relativi alla visone artificale (computer vision) continuano a evolversi, la creazione e il perfezionamento dei dataset rimangono un focus chiave per ricercatori e professionisti nel campo.
Esplorazione dei modelli di rilevamento oggetti: dalla tradizione all’apprendimento profondo
Il rilevamento oggetti è un compito di visone artificiale (computer vision) che si è evoluto significativamente, soprattutto con il progresso delle tecnologie di apprendimento profondo. Inizialmente, il rilevamento oggetti si basava su tecniche di visone artificiale più semplici e algoritmi di apprendimento automatico, dove le caratteristiche per la classificazione degli oggetti venivano create manualmente e i modelli venivano addestrati per rilevare oggetti nelle immagini basandosi su queste caratteristiche. L’introduzione dell’apprendimento profondo, in particolare delle reti neurali convoluzionali profonde (CNN), ha rivoluzionato questo campo. Le CNN imparano automaticamente gerarchie di caratteristiche dai dati, consentendo un rilevamento oggetti più accurato e una segmentazione semantica. Questa transizione ai modelli di apprendimento profondo ha segnato un miglioramento significativo nelle capacità di rilevamento oggetti.
I primi modelli di rilevamento oggetti basati su CNN, come R-CNN, utilizzavano un metodo di proposta di regioni per identificare le potenziali posizioni degli oggetti in un’immagine e poi classificavano ogni regione. Successori come Fast R-CNN e Faster R-CNN hanno migliorato questo approccio aumentando l’accuratezza del rilevamento e la velocità di elaborazione. Ulteriori sviluppi hanno portato all’introduzione di Mask R-CNN, che ha esteso le capacità dei suoi predecessori aggiungendo un ramo per la segmentazione a livello di pixel, facilitando la localizzazione e il riconoscimento dettagliato degli oggetti.
YOLO: Rivoluzionare il rilevamento degli oggetti in tempo reale
Nel campo del rilevamento degli oggetti in tempo reale, il modello YOLO (You Only Look Once) rappresenta un significativo passo avanti. YOLO concettualizza in modo unico il rilevamento degli oggetti come un singolo problema di regressione, prevedendo direttamente le coordinate del riquadro di delimitazione e le probabilità delle classi dai pixel dell’immagine in una sola valutazione. Questo approccio permette a YOLO di raggiungere velocità di elaborazione eccezionali, essenziali per applicazioni che richiedono rilevamento in tempo reale come la rilevazione dei pedoni e il tracciamento dei veicoli nelle città intelligenti.
L’architettura di YOLO elabora l’intera immagine durante l’addestramento, permettendogli di comprendere le informazioni contestuali sulle classi di oggetti e il loro aspetto. Questo si contrappone ai metodi basati su proposte di regione, che potrebbero trascurare alcuni dettagli contestuali. La capacità di elaborazione in tempo reale di YOLO lo rende indispensabile in scenari che richiedono un rilevamento degli oggetti veloce e accurato. La famiglia di modelli YOLO, inclusi versioni avanzate come YOLOv3 e YOLOv4, ha spostato i confini in termini di velocità e accuratezza di rilevamento, stabilendo YOLO come un sistema all’avanguardia nel rilevamento degli oggetti in tempo reale fino ad arrivare a YOLOv8.
Analisi video in tempo reale per il rilevamento degli oggetti sul drone mentre vola con visionplatform.ai e il nostro computer NVIDIA Jetson Edge montato sul drone. Trasformiamo QUALSIASI telecamera in una telecamera AI.
Componenti chiave nel rilevamento degli oggetti: Classificazione e Bounding Box
L’introduzione al rilevamento degli oggetti rivela due aspetti fondamentali: la classificazione e il bounding box. La classificazione si riferisce all’identificazione della classe dell’oggetto (ad esempio, pedone, veicolo) in un’immagine. È un passo critico per distinguere tra diverse categorie di oggetti all’interno di un sistema di rilevamento. Il bounding box, d’altra parte, implica la localizzazione dell’oggetto all’interno dell’immagine, di solito rappresentata da coordinate che delimitano l’oggetto. Insieme, questi componenti formano la base del rilevamento e del tracciamento degli oggetti.
Il rilevamento degli oggetti può aiutare i modelli, come la famiglia di modelli YOLO e il Single Shot Multibox Detector (SSD), la combinazione di classificazione e bounding box garantisce l’accuratezza del rilevamento. Questi modelli, spesso sviluppati e condivisi su piattaforme come GitHub, utilizzano approcci basati sull’apprendimento profondo. Possono anche essere utilizzati senza una riga di codice su piattaforme di visone artificale (https://visionplatform.eu-1.slashinfra.nl/computer-vision-platform/) (computer vision) come visionplatform.ai. Sono capaci di rilevare più oggetti in un’immagine e prevedere accuratamente la posizione di ciascun oggetto con un bounding box intorno ad esso. Questo approccio duale è essenziale in vari casi d’uso del rilevamento degli oggetti, che vanno dal rilevamento dei volti nei sistemi di sicurezza alla rilevazione di anomalie in ambienti industriali.
Il ruolo del Deep Learning nel rilevamento degli oggetti
I metodi di deep learning hanno rivoluzionato la visone artificale (computer vision) e il rilevamento degli oggetti. Questi metodi, che coinvolgono principalmente reti neurali profonde come le CNN, hanno permesso un rilevamento degli oggetti più accurato e una segmentazione semantica più efficace. TensorFlow, una popolare libreria open-source per il machine learning e il deep learning, offre strumenti robusti per addestrare e implementare modelli di deep learning per il rilevamento degli oggetti.
L’efficacia del deep learning nel rilevamento degli oggetti può essere osservata nella sua applicazione a compiti complessi come il rilevamento dei pedoni e il rilevamento del testo. Questi modelli apprendono gerarchie di caratteristiche per un rilevamento degli oggetti accurato, migliorando significativamente rispetto agli algoritmi tradizionali di machine learning che richiedevano caratteristiche progettate manualmente. I modelli di rilevamento degli oggetti basati su deep learning sono tipicamente valutati in base alla loro accuratezza di rilevamento e velocità, rendendoli ideali per applicazioni in tempo reale.
Con il progresso delle tecniche di deep learning, i sistemi di rilevamento degli oggetti sono diventati più versatili, capaci di gestire una vasta gamma di compiti di visone artificale (computer vision) inclusi il tracciamento degli oggetti, il rilevamento delle persone e il riconoscimento delle immagini. Questo avanzamento ha portato allo sviluppo di algoritmi di rilevamento degli oggetti robusti che possono classificare e localizzare affidabilmente gli oggetti, anche in ambienti difficili.
Segmentazione e Riconoscimento degli Oggetti: Migliorare il Rilevamento con un’Analisi Dettagliata
L’introduzione al rilevamento degli oggetti nella visone artificiale (computer vision) spesso porta all’esplorazione di compiti correlati come la segmentazione e il riconoscimento degli oggetti. Mentre il rilevamento degli oggetti identifica e localizza gli oggetti all’interno di un’immagine, la segmentazione va oltre dividendo l’immagine in segmenti per semplificarne l’analisi o cambiarne la rappresentazione. Il riconoscimento degli oggetti, d’altra parte, implica l’identificazione dell’oggetto specifico presente nell’immagine.
Le tecniche basate sull’apprendimento profondo, in particolare le reti neurali convoluzionali profonde, hanno notevolmente avanzato queste aree. La segmentazione, in particolare la segmentazione semantica, è fondamentale per comprendere il contesto in cui gli oggetti esistono nelle immagini. Questo è cruciale in casi d’uso come l’imaging medico, dove l’identificazione precisa dei tessuti o delle anomalie è essenziale. Gli algoritmi di rilevamento degli oggetti che includono la segmentazione, come Mask R-CNN, forniscono approfondimenti dettagliati non solo localizzando il “contenitore intorno” all’oggetto, ma anche delineando l’esatta “forma dell’oggetto”.
Elaborazione dell’immagine di input: Il percorso attraverso i sistemi di rilevamento degli oggetti
Il processo di rilevamento degli oggetti inizia con un’immagine di input, che attraversa diverse fasi all’interno di una rete di rilevamento. Inizialmente, l’immagine viene preelaborata per adattarsi ai requisiti del modello di rilevamento degli oggetti. Questo può comportare ridimensionamento, normalizzazione e aumento. Successivamente, l’immagine viene inserita in un modello di apprendimento profondo, tipicamente un tipo di modello come le CNN, per l’estrazione delle caratteristiche.
Le caratteristiche estratte vengono poi utilizzate per classificare gli oggetti e prevedere la loro posizione. Il rilevamento degli oggetti utilizzato in scenari in tempo reale, come il rilevamento dei pedoni o il tracciamento dei veicoli, richiede che il modello analizzi rapidamente l’immagine di input e fornisca accurati “riquadri di delimitazione previsti” per ogni “oggetto presente”. Qui modelli come YOLO eccellono, offrendo un’elaborazione rapida ed efficiente adatta per applicazioni in tempo reale.
Allenare un modello per compiti così complessi comporta una notevole quantità di dati per il rilevamento degli oggetti. Questi dati, solitamente composti da immagini diverse con oggetti annotati, aiutano il modello a imparare varie categorie di oggetti e le loro caratteristiche. Framework popolari di rilevamento degli oggetti come TensorFlow offrono strumenti e librerie per costruire, allenare e distribuire questi modelli in modo efficiente. L’intero processo evidenzia la sinergia tra tecniche di visone artificale (computer vision) e di elaborazione delle immagini, algoritmi di machine learning e metodi di apprendimento profondo, culminando in un robusto sistema di rilevamento degli oggetti.
Casi d’uso del rilevamento oggetti in varie industrie
Il rilevamento oggetti, alimentato da modelli basati sull’apprendimento profondo, ha trovato applicazioni in diverse industrie, ognuna con requisiti e sfide unici. Questi modelli sono tipicamente valutati in base alla loro accuratezza, velocità e capacità di rilevare più oggetti in condizioni variabili. Nel settore sanitario, il rilevamento oggetti aiuta nell’identificazione di anomalie nell’imaging medico, contribuendo significativamente alla diagnosi precoce e alla pianificazione del trattamento. Nel retail, gioca un ruolo vitale nell’analisi del comportamento dei clienti e nella gestione dell’inventario.
Un caso d’uso notevole del rilevamento oggetti è nell’industria automobilistica, dove è cruciale per lo sviluppo di veicoli autonomi. Qui, la capacità di rilevare e differenziare tra due oggetti, come pedoni e altri veicoli, è fondamentale per la sicurezza. I sistemi di rilevamento oggetti, utilizzando algoritmi avanzati e reti neurali, permettono a questi veicoli di navigare in sicurezza interpretando accuratamente l’ambiente circostante.
TensorFlow nella rilevazione di oggetti: sfruttare i modelli di apprendimento profondo
TensorFlow, un framework open-source disponibile su piattaforme come GitHub, è diventato sinonimo di costruzione e distribuzione di modelli di apprendimento profondo, specialmente nel campo della rilevazione di oggetti. La sua libreria completa consente agli sviluppatori di costruire un modello da zero o utilizzare modelli pre-addestrati per la rilevazione di oggetti. La flessibilità di TensorFlow nel gestire vari meccanismi di proposta di oggetti e la sua efficiente elaborazione di grandi dataset lo rendono la scelta preferita di molti sviluppatori.
Nella rilevazione di oggetti, l’approccio di apprendimento è critico. TensorFlow facilita l’implementazione di algoritmi complessi che possono differenziare i compiti di ‘rilevazione vs. classificazione’, essenziali per scenari di rilevazione di oggetti sfumati. La piattaforma supporta una vasta gamma di modelli, da quelli che richiedono risorse computazionali intensive a modelli leggeri adatti per dispositivi mobili. Questa adattabilità garantisce che i modelli basati su TensorFlow possano essere distribuiti in vari ambienti, dai sistemi basati su server ai dispositivi edge come il Jetson Nano Orin, Jetson NX Orin o Jetson AGX Orin, ampliando l’ambito e l’accessibilità della tecnologia di rilevazione di oggetti.
Esplorazione approfondita del modello YOLO
Il modello YOLO (You Only Look Once), un framework basato sull’apprendimento profondo per la rilevazione di oggetti, rappresenta un cambiamento significativo nell’approccio di apprendimento per la rilevazione di oggetti. A differenza dei modelli tradizionali in cui il sistema propone prima regioni potenziali (proposta di oggetto) e poi classifica ogni regione, YOLO applica una singola rete neurale all’intera immagine, prevedendo box di delimitazione e probabilità di classe per più oggetti in una sola valutazione. Questo approccio, che si concentra sull’intera immagine piuttosto che su proposte separate, permette a YOLO di rilevare oggetti in tempo reale in modo efficace.
I modelli YOLO sono tipicamente valutati in base alla loro velocità e precisione nel rilevare più oggetti. In scenari in cui due oggetti sono vicini tra loro, la capacità di YOLO di distinguerli accuratamente è fondamentale. L’architettura del modello gli consente di comprendere il contesto all’interno di un’immagine, rendendolo robusto in ambienti complessi. Questa capacità è il risultato del suo design di rete unico, che considera l’intera immagine durante la previsione, catturando così informazioni contestuali che potrebbero essere perse concentrandosi su parti dell’immagine.
Dati per il rilevamento degli oggetti: Raccolta e Utilizzo
Il successo di qualsiasi modello di rilevamento degli oggetti, inclusi quelli basati su framework di deep learning come YOLO, dipende fortemente dalla qualità e dalla quantità dei dati utilizzati per l’addestramento. Il processo per costruire un modello di rilevamento degli oggetti inizia con la raccolta dei dati, che implica la raccolta di un insieme diversificato di immagini e la loro annotazione con etichette e riquadri di delimitazione. Questa raccolta di dati è un passo critico nell’addestramento di un modello, in quanto fornisce la base per l’apprendimento del modello.
I dati per il rilevamento degli oggetti devono comprendere una vasta gamma di scenari e tipi di oggetti per garantire che il modello possa generalizzare bene su nuove immagini mai viste prima. Questo include la considerazione delle variazioni nelle dimensioni degli oggetti, nelle condizioni di illuminazione e negli sfondi. I dataset annotati disponibili su piattaforme come GitHub offrono una risorsa preziosa per l’addestramento e il benchmarking dei modelli di rilevamento degli oggetti.
Nell’approccio di apprendimento per il rilevamento degli oggetti, il modello viene addestrato a rilevare ‘oggetto vs. nessun oggetto’ e a classificare gli oggetti rilevati. Questo addestramento implica non solo il riconoscimento della presenza di un oggetto, ma anche la determinazione precisa della sua posizione all’interno dell’immagine. L’uso di metodi avanzati di deep learning e di dataset ampi e annotati ha notevolmente aumentato l’accuratezza e l’affidabilità dei modelli di rilevamento degli oggetti, rendendoli strumenti essenziali in varie applicazioni di visone artificiale (computer vision).
Rilevamento vs. Riconoscimento: Comprendere le Differenze
Nel campo della visone artificale (computer vision), è fondamentale differenziare tra ‘rilevamento vs. riconoscimento’. Il rilevamento implica la localizzazione di oggetti all’interno di un’immagine, tipicamente utilizzando riquadri di delimitazione, mentre il riconoscimento approfondisce, mirando a identificare la natura specifica o la classe degli oggetti rilevati. Questa distinzione è importante per adattare i sistemi di visone artificale (computer vision) a specifiche applicazioni. Ad esempio, mentre un sistema di rilevamento potrebbe essere sufficiente per contare le auto su una strada, un sistema di riconoscimento sarebbe necessario per differenziare tra i modelli di auto.
La complessità dei compiti di riconoscimento di solito richiede modelli più sofisticati rispetto ai compiti di rilevamento. Il riconoscimento spesso implica non solo identificare che un oggetto è presente, ma anche classificarlo in una delle diverse categorie possibili. Questo processo richiede una comprensione più sfumata delle caratteristiche dell’oggetto ed è cruciale in scenari in cui l’identificazione dettagliata è essenziale, come nel differenziare tra cellule benigne e maligne nell’imaging medico.
Conclusione e Tendenze Future nella Rilevazione degli Oggetti
Mentre concludiamo, è evidente che la rilevazione degli oggetti è un campo in rapida evoluzione, con nuovi avanzamenti che emergono continuamente. Le tendenze future probabilmente si concentreranno sul miglioramento dell’accuratezza, della velocità e della capacità di gestire scene più complesse. L’integrazione dell’IA con altre tecnologie come la realtà aumentata e l’Internet delle Cose (IoT) apre nuovi orizzonti per le applicazioni di rilevazione degli oggetti.
Inoltre, la domanda di modelli più efficienti e meno intensivi in termini di dati sta spingendo la ricerca verso approcci di apprendimento con pochi esempi e apprendimento non supervisionato. Questi metodi mirano a formare modelli in modo efficace con dati limitati, affrontando una delle sfide significative nel campo. Con il progresso della tecnologia, possiamo anticipare soluzioni più innovative, migliorando le capacità e le applicazioni della rilevazione degli oggetti in vari settori, dalla sanità ai veicoli autonomi.
Il continuo perfezionamento di modelli e algoritmi nella rilevazione degli oggetti contribuirà senza dubbio a sistemi più sofisticati e accurati, consolidando la sua importanza nel regno della visone artificiale (computer vision) e oltre.
FAQ sulla rilevazione degli oggetti: comprendere i concetti fondamentali
Immergiti nei concetti essenziali della rilevazione degli oggetti con la nostra sezione FAQ. Qui, affrontiamo domande comuni, chiarendo come funziona la rilevazione degli oggetti, le sue applicazioni e la tecnologia dietro di essa. Che tu sia nuovo alla visone artificale (computer vision) o che tu stia cercando di affinare la tua conoscenza, queste risposte forniscono intuizioni concise nel mondo emozionante della rilevazione degli oggetti.
Cos’è la rilevazione degli oggetti?
La rilevazione degli oggetti è una soluzione di visone artificale (computer vision) che identifica e localizza oggetti all’interno di un’immagine o di un video. Non solo riconosce la presenza di oggetti, ma ne individua anche le posizioni con i riquadri di delimitazione. Il sistema assegna livelli di fiducia alle previsioni, indicando la probabilità di accuratezza. La rilevazione degli oggetti è distinta dal riconoscimento delle immagini, che assegna un’etichetta di classe a un’immagine, e dalla segmentazione delle immagini, che identifica gli oggetti a livello di pixel.
Come funziona la rilevazione degli oggetti?
La rilevazione degli oggetti generalmente coinvolge due fasi: rilevare le potenziali regioni degli oggetti (Region of Interest, o RoI) e poi classificare queste regioni. Gli approcci basati sull’apprendimento profondo, specialmente utilizzando reti neurali come le Reti Neurali Convoluzionali (CNNs), sono comuni. Modelli come R-CNN, YOLO e SSD analizzano prima l’immagine per trovare le RoI e poi classificano ogni RoI in categorie di oggetti, spesso utilizzando caratteristiche apprese durante l’addestramento su dataset come COCO o ImageNet.
Quali sono i tipi di modelli di rilevazione degli oggetti?
I modelli di rilevazione degli oggetti popolari includono R-CNN e le sue varianti (Fast R-CNN, Faster R-CNN e Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) e CenterNet. Questi modelli differiscono nel loro approccio all’identificazione delle RoI e alla loro classificazione. I modelli R-CNN utilizzano proposte di regione, mentre YOLO e SSD prevedono direttamente i riquadri di delimitazione dall’immagine, migliorando velocità ed efficienza.
Qual è la differenza tra rilevazione degli oggetti e riconoscimento degli oggetti?
La rilevazione degli oggetti e il riconoscimento degli oggetti sono compiti distinti. La rilevazione degli oggetti coinvolge la localizzazione degli oggetti all’interno di un’immagine e l’identificazione dei loro confini, tipicamente con riquadri di delimitazione. Il riconoscimento degli oggetti va un passo oltre, non solo localizzando ma anche classificando gli oggetti in categorie predefinite, come distinguere tra diversi tipi di animali, veicoli o altri oggetti.
Come vengono addestrati i modelli di rilevazione degli oggetti?
L’addestramento dei modelli di rilevazione degli oggetti coinvolge l’alimentazione di una rete neurale con immagini etichettate. Queste immagini sono annotate con riquadri di delimitazione attorno agli oggetti e le loro corrispondenti etichette di classe. La rete neurale impara a riconoscere schemi e caratteristiche da queste immagini di addestramento. L’efficacia dell’addestramento dipende dalla diversità e dalla dimensione del dataset, con dataset più grandi e variati che portano a modelli più accurati e generalizzabili. I modelli sono spesso addestrati utilizzando framework come TensorFlow o PyTorch.
Quali sono gli usi della rilevazione degli oggetti?
La rilevazione degli oggetti è ampiamente utilizzata in vari campi. In sicurezza e sorveglianza, aiuta nella rilevazione dei volti e nel monitoraggio delle attività. Nel retail, aiuta nell’analisi del comportamento dei clienti e nella gestione delle scorte. Nei veicoli autonomi, è cruciale per identificare ostacoli e navigare in sicurezza. La rilevazione degli oggetti trova anche applicazioni in sanità per identificare anomalie nelle immagini mediche e in agricoltura per il monitoraggio delle colture e dei parassiti.
Cos’è YOLO nella rilevazione degli oggetti?
YOLO (You Only Look Once) è un modello di rilevazione degli oggetti popolare noto per la sua velocità ed efficienza. A differenza dei modelli tradizionali che elaborano un’immagine in parti, YOLO esamina l’intera immagine in un solo passaggio, rendendolo significativamente più veloce. Questo lo rende ideale per applicazioni di rilevazione degli oggetti in tempo reale. YOLO ha diverse versioni, con YOLOv5 e YOLOv8 essendo le più recenti, offrendo miglioramenti in termini di accuratezza e velocità.
Quanto sono accurati i modelli di rilevazione degli oggetti?
L’accuratezza dei modelli di rilevazione degli oggetti varia a seconda della loro architettura e della qualità dei dati di addestramento. Modelli come YOLOv4 e YOLOv5 dimostrano un’alta accuratezza, spesso con tassi di precisione superiori al 90% in condizioni ideali. L’accuratezza è misurata utilizzando metriche come mAP (mean Average Precision) e IoU (Intersection over Union). Il mAP per i migliori modelli su dataset standard come MS COCO può essere alto come 60-70%.
Qual è il ruolo delle Reti Neurali Convoluzionali nella rilevazione degli oggetti?
Le Reti Neurali Convoluzionali (CNNs) giocano un ruolo critico nella rilevazione degli oggetti, principalmente nell’estrazione delle caratteristiche. Elaborano le immagini attraverso strati convoluzionali per apprendere e identificare le caratteristiche chiave, che sono cruciali per la rilevazione degli oggetti. Modelli come R-CNN, Faster R-CNN e SSD utilizzano CNN per la loro efficienza nel gestire i dati delle immagini, migliorando significativamente l’accuratezza e la velocità della rilevazione degli oggetti.
Come iniziare a costruire un modello di rilevazione degli oggetti?
Per iniziare a costruire un modello di rilevazione degli oggetti, definisci prima gli oggetti che vuoi rilevare. Raccogli e annota un dataset con immagini contenenti questi oggetti. Utilizza strumenti come TensorFlow o PyTorch per addestrare un modello su questo dataset. Inizia con un’architettura semplice come SSD o YOLO per una più facile implementazione. Sperimenta con diverse configurazioni e iperparametri per ottimizzare le prestazioni del tuo modello.