
Hyperparameter Optimalisatie voor YOLOv8 met Weights & Biases: Een avontuur met object detectie algoritmes
Introductie
Wanneer je werkt met objectdetectie taken, is het essentieel dat je model optimaal presteert. Dit houdt in dat je de juiste hyperparameters selecteert. In deze blogpost zullen we mijn reis door hyperparameter optimalisatie voor het YOLOv8 object detectie model bespreken met behulp van Weights & Biases (W&B) en de Bayesiaanse Optimalisatiemethode.
Door Justas Andriuškevičius – Machine Learning Engineer bij visionplatform.ai
Waarom Hyperparameter Optimalisatie?
Elk machine learning model komt met zijn eigen set knoppen en schakelaars – hyperparameters. Het kiezen van de juiste combinatie kan het verschil maken tussen een gemiddeld model en een topmodel. Maar met ontelbare mogelijke combinaties, hoe maak je dan een keuze? Dat is waar hyperparameter optimalisatie, en specifiek W&B, in beeld komt.
Dataset Selectie
Voordat we diep ingaan op de hyperparameters, laten we het hebben over dataset selectie. Hyperparameter optimalisatie is een bron-intensieve taak. Het uitvoeren ervan op een volledige dataset zou ontzettend lang duren – en laten we eerlijk zijn; niemand heeft daar tijd voor, vooral niet bij omvangrijke datasets.
Om een evenwicht te vinden tussen computationele efficiëntie en een representatieve dataset, heb ik een slimme aanpak gekozen. Gegeven een grote dataset met beelden in chronologische volgorde, heb ik een subset gecureerd door ze te sorteren op tijdstempel, wat slechts 1/4 is van de originele set. Deze methode zorgt ervoor dat het model traint op diverse data, waarbij zowel dag- als nachtscènes worden omvat, essentieel voor een object detectietaak. Tegelijkertijd vermindert deze methode de computationele tijd aanzienlijk in vergelijking met het gebruik van de volledige set. Voor evaluatie heb ik vastgehouden aan de originele validatieset, aangezien deze een uitgebreidere en onpartijdige evaluatie biedt van de prestaties van het model op ongeziene data en het al slechts een fractie is van de originele trainsetgrootte.
Het YOLOv8 Model en Zijn Hyperparameters
Het YOLOv8 (You Only Look Once) model is een favoriet in objectdetectie taken vanwege zijn efficiëntie. Verschillende hyperparameters beïnvloeden de prestaties:
- Batch grootte (batch): Dit bepaalt het aantal voorbeelden dat wordt verwerkt voordat het model zijn gewichten bijwerkt.
- Beeldgrootte (imgsz): Dit beïnvloedt de resolutie van de beelden die in het model worden gevoed.
- Leersnelheid (lr0): Dit bepaalt hoeveel het model wordt aangepast in reactie op de geschatte fout elke keer als de modelgewichten worden bijgewerkt.
- Optimizer: Dit beïnvloedt hoe het model zijn gewichten bijwerkt.
- Augmentatie (augment): Dit geeft aan of er willekeurige wijzigingen in de invoergegevens worden geïntroduceerd, waardoor de robuustheid van het model toeneemt.
- Dropout (dropout): Dit is een regularisatietechniek om overfitting te voorkomen.
Waarom Bayesiaanse Optimalisatie?
Het kiezen van de juiste hyperparameters kan aanvoelen als het zoeken naar een speld in een hooiberg. Bayesiaanse optimalisatie maakt deze zoektocht slimmer. Stel je voor dat je de hoogste score in een spel probeert te halen. In plaats van willekeurig elke mogelijke zet uit te proberen (wat eeuwig kan duren!), kijkt Bayesiaanse optimalisatie naar je vorige zetten, leert ervan, en stelt slim de volgende beste zet voor. Het balanceert tussen het proberen van bewezen zetten (exploitatie) en het experimenteren met nieuwe (verkenning).
Waarom mAP50 maximaliseren?
mAP50 staat voor Mean Average Precision met een IoU van 0,5. Simpel gezegd, het evalueert hoe goed de voorspelde begrenzingsvakken van ons model overlappen met de werkelijke vakken. Het maximaliseren van mAP50 betekent dat ons model niet alleen objecten detecteert, maar hun locaties nauwkeurig aangeeft. Omdat het doel is om voertuigtypes te detecteren tijdens de dag, nacht en in zware weersomstandigheden, wordt het garanderen van een hoge mAP50 nog kritischer. Het gaat niet alleen om het detecteren van voertuigen, maar om ervoor te zorgen dat ze nauwkeurig worden herkend in gevarieerde en uitdagende scenario’s. Nu, waarom kies ik ervoor om mAP50 te maximaliseren over mAP50–95? Toen ik ons model de eerste keer trainde met standaard hyperparameters, merkte ik dat mAP50 zijn optimale waarde bereikte rond het 30-epoch merkteken, terwijl mAP50–95 langer duurde, en zich stabiliseerde rond de 50 epochs. Opmerkelijk is dat een hoge mAP50 vaak indicatief was voor een evenzo hoge mAP50–95. Gezien dit gedrag heb ik voor hyperparameter optimalisatiedoeleinden ervoor gekozen om me te concentreren op het maximaliseren van mAP50. Deze aanpak stelt ons in staat om elke evaluatierun te verkorten, waardoor een efficiëntere verkenning van diverse parametercombinaties mogelijk wordt.
Het gebruik van W&B voor Hyperparameter Optimalisatie
De sweep-functionaliteit van W&B stroomlijnt het optimalisatieproces. Ik heb de sweep opgezet met de Bayesiaanse methode om te zoeken naar de beste hyperparameters. Interessant is dat ik 30 epochs koos voor training omdat, in mijn eerste tests met de volledige dataset, het model tekenen van optimale prestaties begon te vertonen rond dit merkteken.
Resultaten en Inzichten
Duiken in de resultaten van hyperparameteroptimalisatie onthult belangrijke inzichten:
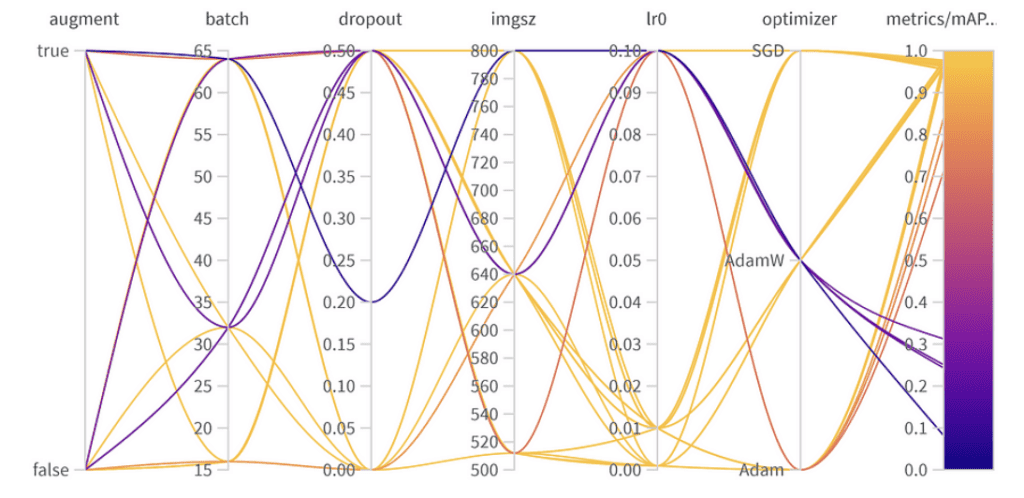
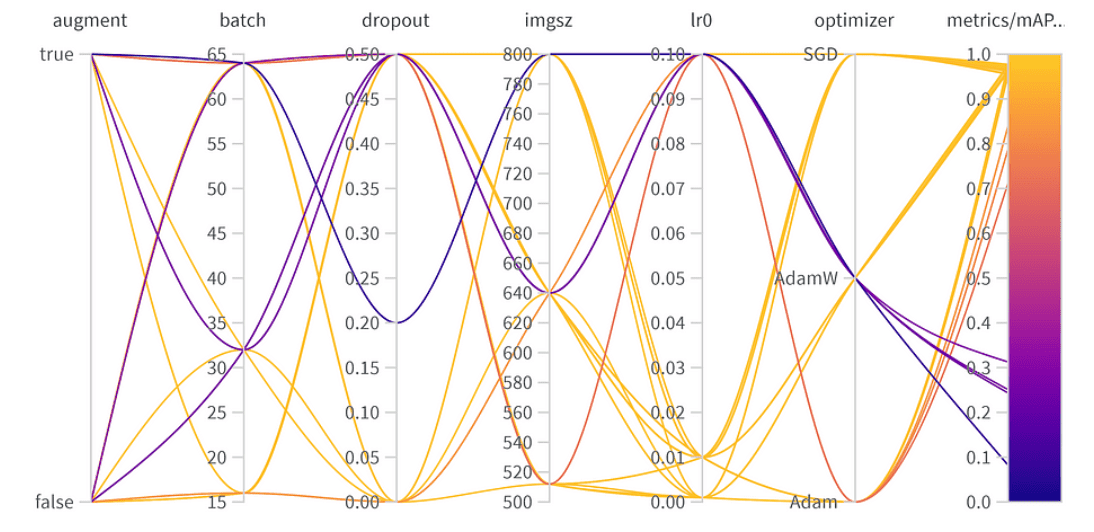
Resultaten van hyperparameteroptimalisatie
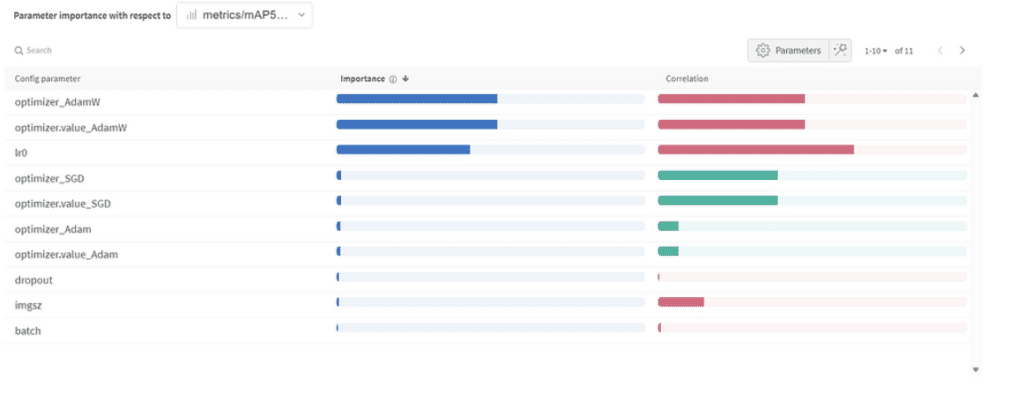
Belang en correlatie van hyperparameters
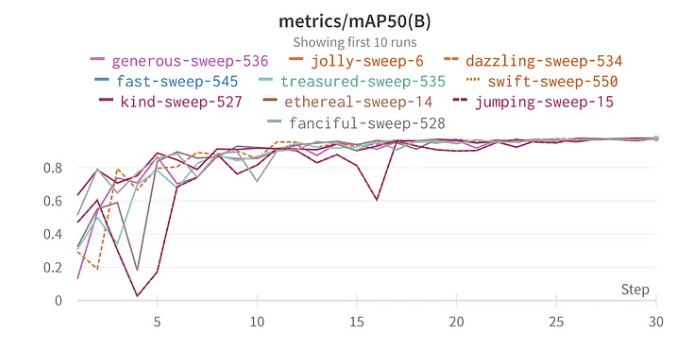
top 10 mAP50 resultaten YoloV8
Parameter Belang:
- Optimizer (AdamW): Met een belang van 0.521 en een negatieve correlatie suggereert dit dat AdamW de prestaties aanzienlijk kan beïnvloeden, maar niet altijd positief.
- Leersnelheid (lr0): Hoog belang (0.433) en een negatieve correlatie (-0.634) geven aan dat een kleinere leersnelheid wellicht beter is voor onze taak.
- Anderen: Optimizers zoals SGD & Adam, en parameters zoals dropout, beeldgrootte, en batchgrootte tonen minimaal belang, wat wijst op hun mindere invloed op de prestaties van ons model.
Eind Hyperparameters:
De beste hyperparametercombinatie is als volgt met de beste mAP50 van 0.9776 op de validatieset:
- Augmentatie: Het beste model sloeg data-augmentatie over, wat wijst op voldoende gegevensdiversiteit.
- Batchgrootte: Koos 64, een balans tussen rekenkundige efficiëntie en modelprestatie.
- Dropout: Een snelheid van 0, wat suggereert dat het model deze regularisatie niet nodig had.
- Beeldgrootte: 640 is het ideale punt voor onze taak.
- Leersnelheid: Koos voor 0.001, in lijn met onze eerdere waarneming dat lagere snelheden gunstig zijn.
- Optimizer: Interessant is dat hoewel AdamW belangrijk leek, Adam werd gekozen in de beste combo. Het is een herinnering dat hyperparameters vaak onderling verbonden effecten hebben.
Een balans vinden: Top prestaties vs. Algemene toepasbaarheid
Hoewel de beste mAP50 behaald op onze validatieset 0.9776 was, was er een andere configuratie met een bijna gelijke mAP50 van 0.9761. Dit “runner-up” model verschilt opvallend omdat het data-augmentatie gebruikte en een dropout-snelheid van 0,5 had. Gezien de lichte daling van de mAP50 (slechts 0.0015) kan het gunstig zijn om dit model te verkiezen in implementatiescenario’s, vooral als we een breed scala aan situaties verwachten waarin het model zal worden gebruikt. Het minimale compromis in directe prestaties kan worden gecompenseerd door het versterkte vermogen van het model om te generaliseren.
Conclusie
Hyperparameteroptimalisatie kan de prestaties van uw model aanzienlijk verbeteren. Met tools zoals W&B en methoden zoals Bayesiaanse optimalisatie wordt dit proces systematisch en inzichtelijk. Terwijl sommige parameters zoals optimizer en leersnelheid cruciaal zijn, hebben anderen een kleine impact. Het benadrukt de noodzaak van taakspecifieke afstemming in plaats van algemene deep learning best practices. Bij het implementeren van een model is het essentieel om de afwegingen tussen piekvalidatieprestaties en robuustheid in gevarieerde real-world situaties te overwegen. In sommige gevallen is een model met een iets lagere validatienauwkeurigheid maar betere algemene toepasbaarheid vanwege regularisatie misschien de betere keuze. Experimenteren, ondersteund door gegevens, is de sleutel!