
Otimização de Hiperparâmetros para YOLOv8 com Weights & Biases: Uma aventura com algoritmos de detecção de objetos
Introdução
Ao trabalhar com tarefas de detecção de objetos, otimizar o desempenho do seu modelo é crucial. Isso envolve selecionar os hiperparâmetros corretos. Neste post, vamos acompanhar minha jornada de otimização de hiperparâmetros para o modelo de detecção de objetos YOLOv8 usando Weights & Biases (W&B) e o método de Otimização Bayesiana.
Por Justas Andriuškevičius – Engenheiro de Machine Learning na visionplatform.ai
Por que Otimizar Hiperparâmetros?
Cada modelo de aprendizado de máquina vem com seu conjunto de ajustes – hiperparâmetros. Selecionar a combinação correta pode fazer a diferença entre um modelo médio e um de alto desempenho. Mas, com inúmeras combinações possíveis, como escolher? É aqui que a otimização de hiperparâmetros, e especificamente W&B, entra em jogo.
Seleção de Conjunto de Dados
Antes de mergulharmos profundamente nos hiperparâmetros, vamos discutir a seleção do conjunto de dados. A otimização de hiperparâmetros é uma tarefa que consome muitos recursos. Realizá-la em um conjunto de dados completo levaria muito tempo – e vamos ser honestos; ninguém tem tempo para isso, especialmente ao lidar com conjuntos de dados volumosos.
Para equilibrar entre eficiência computacional e um conjunto de dados representativo, adotei uma abordagem inteligente. Dado um grande conjunto de dados com imagens em ordem cronológica, selecionei um subconjunto ordenando-as pelo timestamp, que é apenas 1/4 do conjunto original. Esse método garante que o modelo treine com dados diversos, abrangendo cenas diurnas e noturnas, essenciais para uma tarefa de detecção de objetos. Ao mesmo tempo, esse método reduz significativamente o tempo de computação em comparação com o uso do conjunto completo. Para avaliação, mantive o conjunto de validação original, pois ele oferece uma avaliação mais abrangente e imparcial do desempenho do modelo em dados não vistos e é apenas uma fração do tamanho original do conjunto de treinamento.
O Modelo YOLOv8 e Seus Hiperparâmetros
O modelo YOLOv8 (You Only Look Once) é um favorito para tarefas de detecção de objetos devido à sua eficiência. Vários hiperparâmetros influenciam seu desempenho:
- Tamanho do lote (batch): Determina o número de amostras processadas antes de o modelo atualizar seus pesos.
- Tamanho da imagem (imgsz): Afeta a resolução das imagens alimentadas no modelo.
- Taxa de aprendizado (lr0): Controla o quanto ajustar o modelo em resposta ao erro estimado a cada vez que os pesos do modelo são atualizados.
- Otimizador: Influencia como o modelo atualiza seus pesos.
- Aumento (augment): Denota se devem ser introduzidas mudanças aleatórias nos dados de entrada, aumentando a robustez do modelo.
- Dropout (dropout): É uma técnica de regularização para evitar o overfitting.
Por que Otimização Bayesiana?
Escolher os hiperparâmetros certos pode parecer como procurar uma agulha num palheiro. A otimização bayesiana torna essa busca mais inteligente. Imagine que você está tentando obter a maior pontuação em um jogo. Em vez de tentar aleatoriamente cada movimento possível (o que levaria para sempre!), a otimização bayesiana analisa seus movimentos anteriores, aprende com eles e sugere inteligentemente o próximo melhor movimento. Ela equilibra entre testar movimentos comprovados (exploração) e experimentar novos (exploração).
Por que Maximizar mAP50?
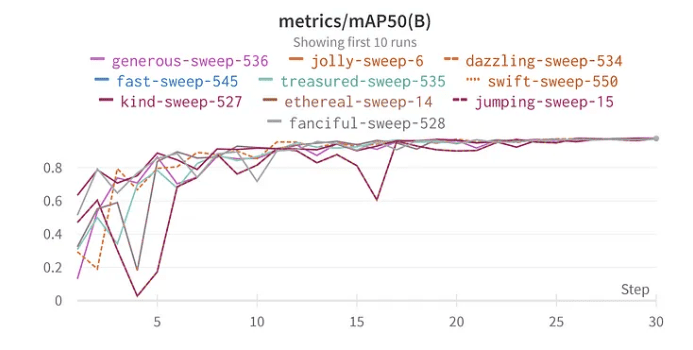
mAP50 significa Mean Average Precision com um IoU de 0,5. Em termos simples, avalia quão bem as caixas delimitadoras previstas pelo nosso modelo se sobrepõem às caixas verdadeiras. Maximizar mAP50 significa que nosso modelo não está apenas detectando objetos, mas identificando com precisão seus locais. Como o objetivo é detectar tipos de veículos durante o dia, a noite e em condições climáticas adversas, garantir um mAP50 alto torna-se ainda mais crucial. Não se trata apenas de detectar veículos, mas de garantir que sejam corretamente reconhecidos em cenários variados e desafiadores. Agora, por que escolhi maximizar mAP50 em vez de mAP50–95? Ao treinar nosso modelo pela primeira vez com hiperparâmetros padrão, observei que mAP50 atingiu seu valor ótimo em torno da marca de 30 épocas, enquanto mAP50–95 demorou mais, estabilizando-se apenas em torno de 50 épocas. Notavelmente, um alto mAP50 era frequentemente indicativo de um mAP50–95 igualmente alto. Dado esse comportamento, para fins de otimização de hiperparâmetros, optei por focar em maximizar mAP50. Esta abordagem nos permite encurtar cada execução de avaliação, possibilitando uma exploração mais eficiente de combinações de parâmetros diversos.
Usando W&B para Otimização de Hiperparâmetros
A funcionalidade de varredura de W&B simplifica o processo de otimização. Configurei a varredura usando o método bayesiano para procurar os melhores hiperparâmetros. Curiosamente, escolhi 30 épocas para treinamento porque, em meus testes iniciais com o conjunto de dados completo, o modelo começou a mostrar sinais de desempenho ótimo por volta dessa marca.
Resultados e Insights
Mergulhando nos resultados da otimização de hiperparâmetros, revelam-se insights importantes:
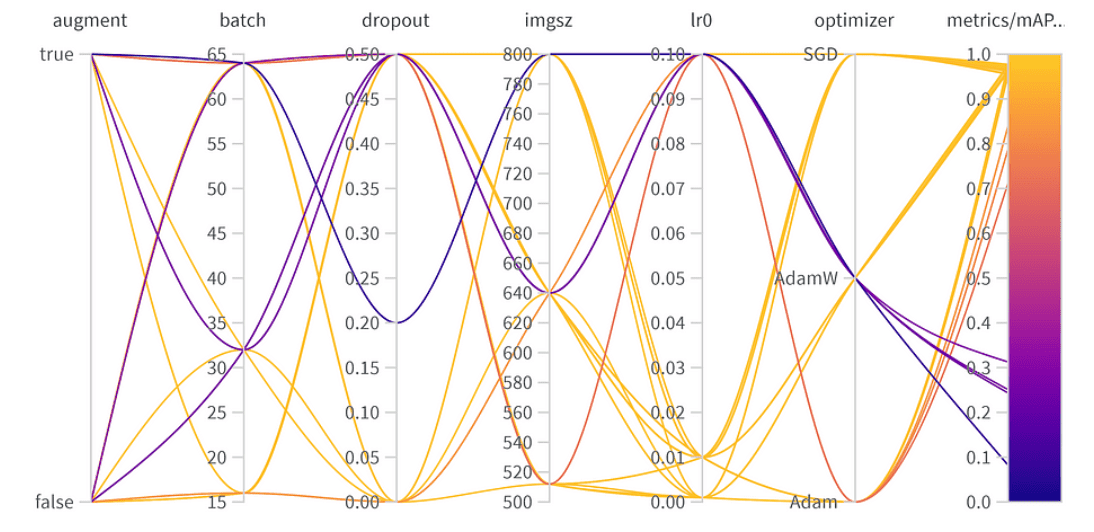
Resultados da otimização de hiperparâmetros
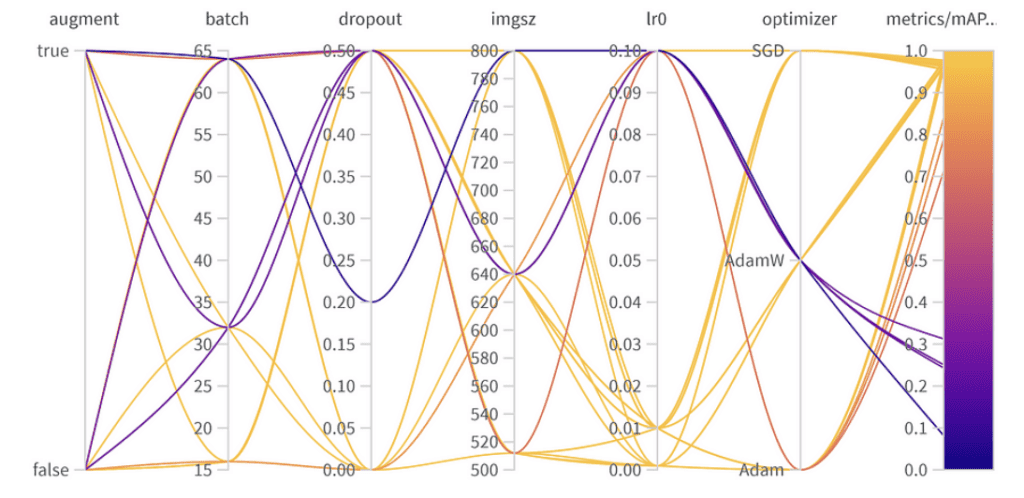
Importância e correlação de hiperparâmetros
top 10 resultados mAP50 YoloV8 top 10 resultados mAP50
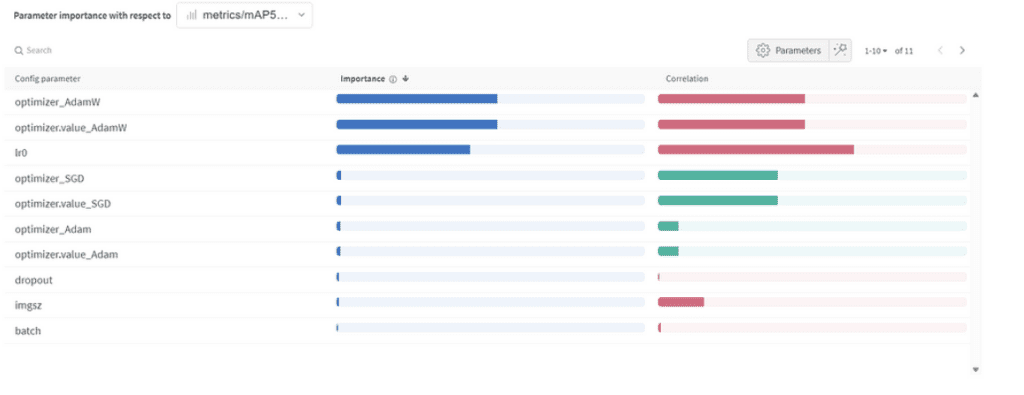
Importância dos Parâmetros:
- Otimizador (AdamW): Com uma importância de 0.521 e uma correlação negativa, sugere que AdamW pode impactar significativamente no desempenho, mas nem sempre de forma positiva.
- Taxa de Aprendizado (lr0): Alta importância (0.433) e uma correlação negativa (-0.634) indicam que uma taxa de aprendizado menor pode ser melhor para nossa tarefa.
- Outros: Otimizadores como SGD & Adam, e parâmetros como dropout, tamanho da imagem e tamanho do lote mostram importância mínima, indicando menor influência no desempenho do nosso modelo.
Hiperparâmetros Finais:
A melhor combinação de hiperparâmetros é a seguinte, com o melhor mAP50 de 0.9776 no conjunto de validação:
- Aumento: O melhor modelo pulou a aumentação de dados, indicando diversidade de dados suficiente.
- Tamanho do Lote: Escolheu 64, equilibrando eficiência computacional e desempenho do modelo.
- Dropout: Uma taxa de 0, sugerindo que o modelo não precisou dessa regularização.
- Tamanho da Imagem: 640 é o ponto ideal para nossa tarefa.
- Taxa de Aprendizado: Optou por 0.001, alinhando-se à nossa observação anterior sobre taxas mais baixas serem benéficas.
- Otimizador: Curiosamente, mesmo que AdamW parecesse importante, Adam foi escolhido na melhor combinação. É um lembrete de que hiperparâmetros frequentemente têm efeitos interconectados.
Encontrando um Equilíbrio: Melhor Desempenho vs. Generalização
Embora o melhor mAP50 alcançado em nosso conjunto de validação tenha sido 0.9776, havia outra configuração com um mAP50 próximo de 0.9761. Esse modelo “vice-campeão” difere notavelmente por ter empregado aumento de dados e usado uma taxa de dropout de 0,5. Considerando a pequena queda no mAP50 (meros 0.0015), pode ser benéfico favorecer esse modelo em cenários de implantação, especialmente se anteciparmos uma ampla variedade de situações que o modelo encontrará. O compromisso mínimo no desempenho imediato pode ser compensado pela habilidade aprimorada do modelo de generalizar.
Conclusão
A otimização de hiperparâmetros pode aumentar significativamente o desempenho do seu modelo. Com ferramentas como W&B e métodos como otimização bayesiana, este processo torna-se sistemático e esclarecedor. Enquanto alguns parâmetros como otimizador e taxa de aprendizado são cruciais, outros têm um impacto menor. Isso destaca a necessidade de ajuste específico para a tarefa, em vez de melhores práticas gerais de aprendizado profundo. Ao implantar um modelo, é essencial ponderar os compromissos entre o desempenho máximo de validação e robustez em diversas situações do mundo real. Em alguns casos, um modelo com precisão de validação ligeiramente inferior, mas melhor generalização devido à regularização, pode ser a melhor escolha. Experimentação, respaldada por dados, é a chave!