
Ottimizzazione degli Iperparametri per YOLOv8 con Weights & Biases: Un’avventura con gli algoritmi di rilevamento degli oggetti
Introduzione
Quando si lavora con compiti di rilevamento degli oggetti, è fondamentale che il tuo modello funzioni in modo ottimale. Questo comporta la selezione dei giusti iperparametri. In questo post, parleremo del mio percorso di ottimizzazione degli iperparametri per il modello di rilevamento degli oggetti YOLOv8 usando Weights & Biases (W&B) e il metodo di Ottimizzazione Bayesiana.
Di Justas Andriuškevičius – Ingegnere di Apprendimento Automatico presso visionplatform.ai
Perché l’Ottimizzazione degli Iperparametri?
Ogni modello di apprendimento automatico ha il suo insieme di manopole e pulsanti: gli iperparametri. Selezionare la combinazione giusta può fare la differenza tra un modello medio e uno di alto livello. Ma, con innumerevoli possibili combinazioni, come si fa a scegliere? Ecco dove entra in gioco l’ottimizzazione degli iperparametri, e in particolare W&B.
Selezione del Dataset
Prima di entrare nei dettagli degli iperparametri, discutiamo della selezione del dataset. L’ottimizzazione degli iperparametri è un compito che richiede molte risorse. Effettuarla su un dataset completo richiederebbe molto tempo, e siamo realistici, nessuno ha tempo per questo, soprattutto quando si tratta di dataset voluminosi.
Per bilanciare l’efficienza computazionale con un dataset rappresentativo, ho adottato un approccio astuto. Dato un grande dataset con immagini in ordine cronologico, ho curato un sottoinsieme ordinandole per timestamp, che rappresenta solo 1/4 del set originale. Questo metodo garantisce che il modello venga addestrato su dati diversificati, comprendendo sia scene diurne che notturne, fondamentali per un compito di rilevamento degli oggetti. Allo stesso tempo, questo metodo riduce significativamente il tempo computazionale rispetto all’uso dell’intero set. Per la valutazione, ho mantenuto il set di convalida originale, poiché fornisce una valutazione più completa e imparziale delle prestazioni del modello su dati non visti e rappresenta già solo una frazione della dimensione del set di addestramento originale.
Il Modello YOLOv8 e i Suoi Iperparametri
Il modello YOLOv8 (You Only Look Once) è preferito nei compiti di rilevamento degli oggetti grazie alla sua efficienza. Diversi iperparametri influenzano le sue prestazioni:
- Dimensione del lotto (batch): determina il numero di campioni elaborati prima che il modello aggiorni i suoi pesi.
- Dimensione dell’immagine (imgsz): influisce sulla risoluzione delle immagini inserite nel modello.
- Velocità di apprendimento (lr0): controlla quanto regolare il modello in risposta all’errore stimato ogni volta che i pesi del modello vengono aggiornati.
- Ottimizzatore: influenza come il modello aggiorna i suoi pesi.
- Augmentazione (augment): indica se introdurre variazioni casuali nei dati di input, aumentando la robustezza del modello.
- Dropout (dropout): è una tecnica di regolarizzazione per prevenire l’overfitting.
Perché l’Ottimizzazione Bayesiana?
Scegliere gli iperparametri giusti può sembrare come cercare un ago in un pagliaio. L’ottimizzazione bayesiana rende questa ricerca più intelligente. Immagina di cercare di ottenere il punteggio più alto in un gioco. Invece di provare casualmente ogni possibile mossa (che potrebbe richiedere molto tempo!), l’ottimizzazione bayesiana osserva le tue mosse precedenti, impara da esse e suggerisce in modo intelligente la prossima mossa migliore. Bilancia tra provare mosse collaudate (sfruttamento) e sperimentare nuove (esplorazione).
Perché Massimizzare mAP50?
mAP50 sta per Precisione Media Media con un IoU di 0,5. In termini semplici, valuta quanto bene le bounding box predette dal nostro modello si sovrappongono con le bounding box reali. Massimizzare mAP50 significa che il nostro modello non sta solo rilevando oggetti ma sta identificando con precisione le loro posizioni. Poiché l’obiettivo è rilevare tipi di veicoli di giorno, di notte e in condizioni meteorologiche avverse, garantire un alto mAP50 diventa ancora più cruciale. Non si tratta solo di rilevare veicoli, ma di garantire che vengano riconosciuti con precisione in scenari diversi e impegnativi. Ora, perché ho scelto di massimizzare mAP50 piuttosto che mAP50-95? Quando ho addestrato il nostro modello per la prima volta con iperparametri predefiniti, ho osservato che mAP50 raggiungeva il suo valore ottimale intorno al marchio di 30 epoche, mentre mAP50-95 richiedeva più tempo, stabilizzandosi solo intorno alle 50 epoche. Nota che un alto mAP50 indicava spesso un mAP50-95 altrettanto elevato. Dato questo comportamento, per scopi di ottimizzazione degli iperparametri, ho scelto di concentrarmi sul massimizzare mAP50. Questo approccio ci permette di abbreviare ogni run di valutazione, consentendo una esplorazione più efficiente di diverse combinazioni di parametri.
Utilizzo di W&B per l’Ottimizzazione degli Iperparametri
La funzionalità di sweep di W&B semplifica il processo di ottimizzazione. Ho impostato lo sweep utilizzando il metodo bayesiano per cercare i migliori iperparametri. Interessantemente, ho scelto 30 epoche per l’addestramento perché, nei miei test iniziali con il dataset completo, il modello ha iniziato a mostrare segni di prestazioni ottimali intorno a questo punto.
Risultati e Intuizioni
Immergendosi nei risultati dell’ottimizzazione degli iperparametri si rivelano importanti intuizioni:
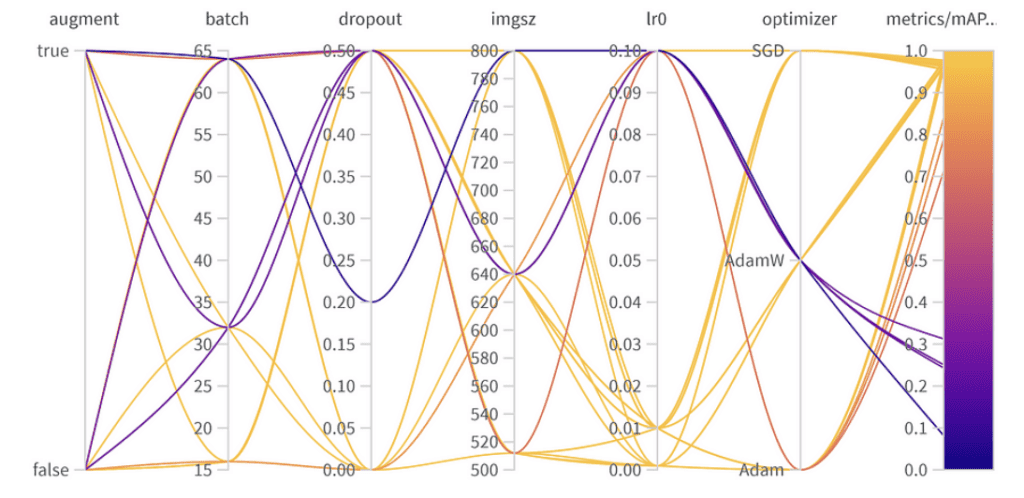
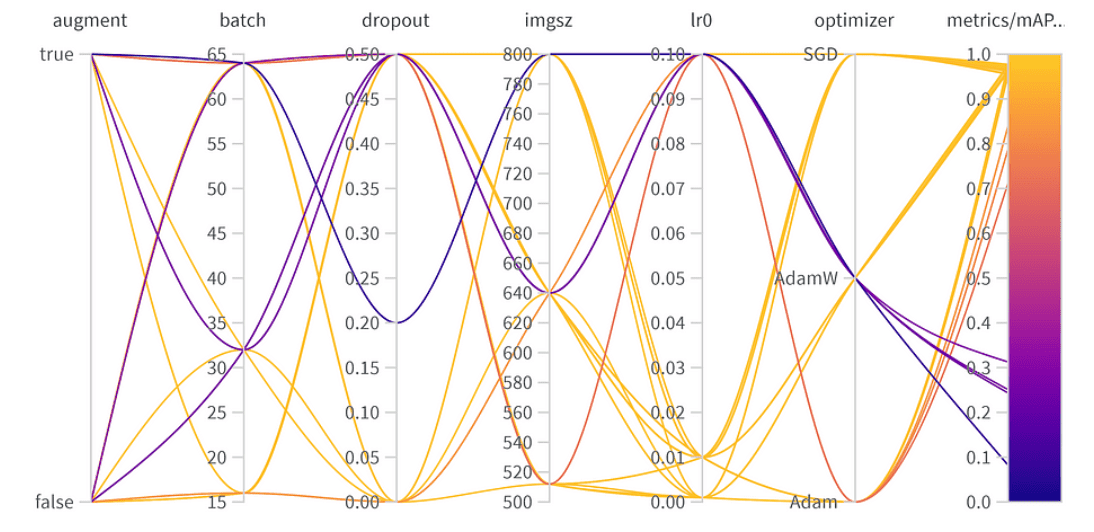
Risultati dell’ottimizzazione degli iperparametri
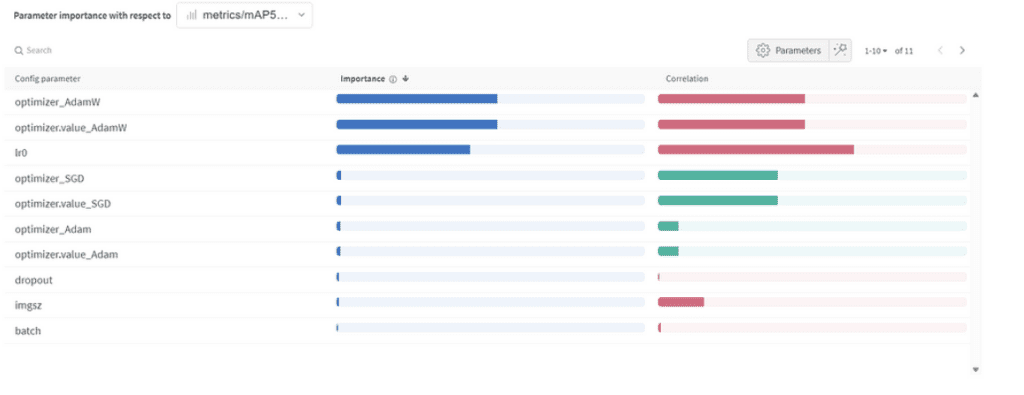
Importanza e correlazione degli iperparametri
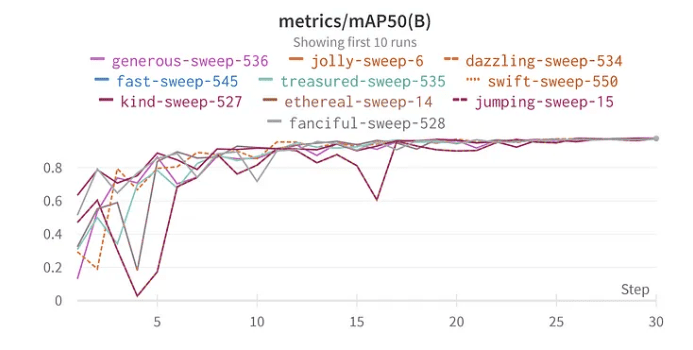
i 10 migliori risultati mAP50
Importanza del parametro:
- Ottimizzatore (AdamW): Con un’importanza di 0.521 e una correlazione negativa, suggerisce che AdamW può influenzare significativamente le prestazioni, ma non sempre in modo positivo.
- Velocità di apprendimento (lr0): Alta importanza (0.433) e una correlazione negativa (-0.634) suggeriscono che una velocità di apprendimento più bassa potrebbe essere migliore per il nostro compito.
- Altri: Ottimizzatori come SGD & Adam, e parametri come dropout, dimensione dell’immagine e dimensione del lotto mostrano un’importanza minima, indicando la loro minore influenza sulle prestazioni del nostro modello. Iperparametri finali:
La migliore combinazione di iperparametri è la seguente con il miglior mAP50 di 0.9776 sul set di convalida:
- Aumento dei dati: Il miglior modello ha saltato l’augmentazione dei dati, indicando una sufficiente diversità di dati.
- Dimensione del lotto: Ha scelto 64, bilanciando l’efficienza computazionale e le prestazioni del modello.
- Dropout: Un tasso di 0, suggerendo che il modello non aveva bisogno di questa regolarizzazione.
- Dimensione dell’immagine: 640 è il punto ideale per il nostro compito.
- Velocità di apprendimento: Ha optato per 0.001, in linea con la nostra precedente osservazione sul fatto che tassi più bassi siano vantaggiosi.
- Ottimizzatore: Curiosamente, anche se AdamW sembrava importante, Adam è stato scelto nella migliore combinazione. È un promemoria che gli iperparametri spesso hanno effetti interconnessi.
Trova un equilibrio: Prestazioni al top vs. Generalizzabilità
Mentre il miglior mAP50 ottenuto sul nostro set di convalida era 0.9776, c’era un’altra configurazione con un mAP50 vicino di 0.9761. Questo modello “secondo classificato” differisce in modo notevole in quanto ha impiegato l’augmentazione dei dati e ha utilizzato un tasso di dropout del 0.5. Considerando la leggera diminuzione di mAP50 (solo 0.0015), potrebbe essere vantaggioso preferire questo modello in scenari di implementazione, specialmente se prevediamo una vasta gamma di situazioni che il modello dovrà affrontare. Il minimo compromesso nelle prestazioni immediate potrebbe essere compensato dalla maggiore capacità del modello di generalizzare.
Conclusione
L’ottimizzazione degli iperparametri può aumentare significativamente le prestazioni del tuo modello. Con strumenti come W&B e metodi come l’ottimizzazione bayesiana, questo processo diventa sistematico e perspicace. Mentre alcuni parametri come l’ottimizzatore e la velocità di apprendimento sono fondamentali, altri hanno un impatto minore. Ciò sottolinea la necessità di una sintonizzazione specifica per il compito piuttosto che delle migliori pratiche generali di apprendimento profondo. Quando si implementa un modello, è essenziale valutare i compromessi tra le prestazioni di convalida al top e la robustezza in varie situazioni reali. In alcuni casi, un modello con una precisione di convalida leggermente inferiore ma una migliore generalizzabilità grazie alla regolarizzazione potrebbe essere la scelta migliore. La sperimentazione, supportata dai dati, è fondamentale!