
Optymalizacja hiperparametrów dla YOLOv8 z Weights & Biases: Przygoda z algorytmami detekcji obiektów
Wprowadzenie
Pracując nad zadaniem detekcji obiektów, optymalna wydajność Twojego modelu jest kluczowa. Wiąże się to z wyborem odpowiednich hiperparametrów. W tym wpisie na blogu opowiem o mojej przygodzie z optymalizacją hiperparametrów dla modelu detekcji obiektów YOLOv8, korzystając z Weights & Biases (W&B) oraz metody Optymalizacji Bayesowskiej.
Autor: Justas Andriuškevičius – Inżynier uczenia maszynowego w visionplatform.ai
Dlaczego Optymalizacja Hiperparametrów?
Każdy model uczenia maszynowego ma swój zestaw pokręteł i przycisków – hiperparametry. Wybór odpowiedniej kombinacji może stanowić różnicę między przeciętnym modelem a modelem o najlepszej wydajności. Ale przy niezliczonej liczbie możliwych kombinacji, jak dokonać wyboru? Tutaj z pomocą przychodzi optymalizacja hiperparametrów, a konkretnie W&B.
Wybór zestawu danych
Zanim zagłębimy się w hiperparametry, omówmy wybór zestawu danych. Optymalizacja hiperparametrów to zadanie intensywnie korzystające z zasobów. Przeprowadzenie jej na pełnym zestawie danych zajęłoby niesamowicie dużo czasu – a bądźmy szczerzy; nikt na to nie ma czasu, zwłaszcza przy ogromnych zestawach danych.
Aby znaleźć równowagę między wydajnością obliczeniową a reprezentatywnym zestawem danych, przyjąłem sprytną strategię. Mając duży zestaw danych z obrazami w kolejności czasowej, wybrałem podzbiór, sortując je według znacznika czasu, co stanowiło tylko 1/4 oryginalnego zestawu. Ta metoda zapewnia, że model jest szkolony na różnorodnych danych, obejmujących zarówno sceny dzienne, jak i nocne, co jest kluczowe dla zadania detekcji obiektów. Tymczasem ta metoda znacząco skraca czas obliczeń w porównaniu z użyciem pełnego zestawu. Do oceny postanowiłem trzymać się oryginalnego zestawu walidacyjnego, ponieważ zapewnia on bardziej kompleksową i bezstronną ocenę wydajności modelu na niewidzianych danych, a jest już tylko ułamkiem rozmiaru oryginalnego zestawu treningowego.
Model YOLOv8 i jego hiperparametry
Model YOLOv8 (You Only Look Once) jest ulubieńcem w zadaniach detekcji obiektów ze względu na jego wydajność. Kilka hiperparametrów wpływa na jego wydajność:
- Rozmiar wsadu (batch): Określa liczbę próbek przetwarzanych przed aktualizacją wag modelu.
- Rozmiar obrazu (imgsz): Wpływa na rozdzielczość obrazów wprowadzanych do modelu.
- Współczynnik uczenia (lr0): Kontroluje, jak bardzo dostosować model w odpowiedzi na szacowany błąd za każdym razem, gdy wagi modelu są aktualizowane.
- Optymalizator: Wpływa na to, jak model aktualizuje swoje wagi.
- Augmentacja (augment): Oznacza, czy wprowadzać losowe zmiany do danych wejściowych, zwiększając odporność modelu.
- Dropout (dropout): Jest to technika regularyzacji, która zapobiega przeuczeniu.
Dlaczego Optymalizacja Bayesowska?
Wybór odpowiednich hiperparametrów może wydawać się jak szukanie igły w stogu siana. Optymalizacja bayesowska czyni to poszukiwanie bardziej inteligentnym. Wyobraź sobie, że próbujesz uzyskać najwyższy wynik w grze. Zamiast losowo próbować każdego możliwego ruchu (co mogłoby trwać wiecznie!), optymalizacja bayesowska analizuje twoje poprzednie ruchy, uczy się z nich i mądrze sugeruje następny najlepszy ruch. Balansuje między próbowaniem sprawdzonych ruchów (eksploatacją) a eksperymentowaniem z nowymi (eksploracją).
Dlaczego maksymalizować mAP50?
mAP50 oznacza średnią precyzję przy IoU wynoszącym 0,5. W prostych słowach ocenia, jak dobrze przewidziane przez nasz model ramki graniczne pokrywają się z rzeczywistymi ramkami. Maksymalizacja mAP50 oznacza, że nasz model nie tylko wykrywa obiekty, ale również dokładnie wskazuje ich lokalizacje. Ponieważ celem jest wykrywanie rodzajów pojazdów w ciągu dnia, nocy i w trudnych warunkach pogodowych, zapewnienie wysokiego mAP50 staje się jeszcze bardziej kluczowe. Chodzi nie tylko o wykrywanie pojazdów, ale także o to, aby były one dokładnie rozpoznawane w zróżnicowanych i trudnych scenariuszach. Dlaczego więc wybrałem maksymalizację mAP50 nad mAP50-95? Trenując nasz model po raz pierwszy z domyślnymi hiperparametrami, zauważyłem, że mAP50 osiągnęło swoją optymalną wartość około 30. epoki, podczas gdy mAP50-95 trwało dłużej, stabilizując się dopiero około 50 epok. Co ważne, wysokie mAP50 często wskazywało na podobnie wysokie mAP50-95. Mając na uwadze to zachowanie, do celów optymalizacji hiperparametrów postanowiłem skupić się na maksymalizacji mAP50. Podejście to pozwala nam skrócić każdy przebieg oceny, umożliwiając bardziej wydajne badanie różnorodnych kombinacji parametrów.
Korzystanie z W&B do optymalizacji hiperparametrów
Funkcja “sweep” w W&B upraszcza proces optymalizacji. Ustawiłem “sweep” używając metody bayesowskiej, aby szukać najlepszych hiperparametrów. Co ciekawe, wybrałem 30 epok do szkolenia, ponieważ w moich początkowych testach z pełnym zestawem danych model zaczął wykazywać oznaki optymalnej wydajności w okolicach tego momentu.
Wyniki i wnioski
Zanurzenie się w wynikach optymalizacji hiperparametrów ujawnia ważne wnioski:
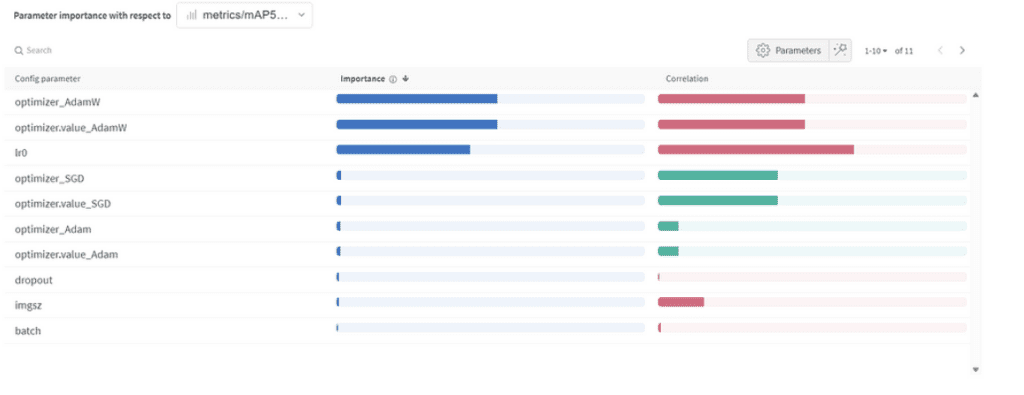
Znaczenie i korelacja hiperparametrów
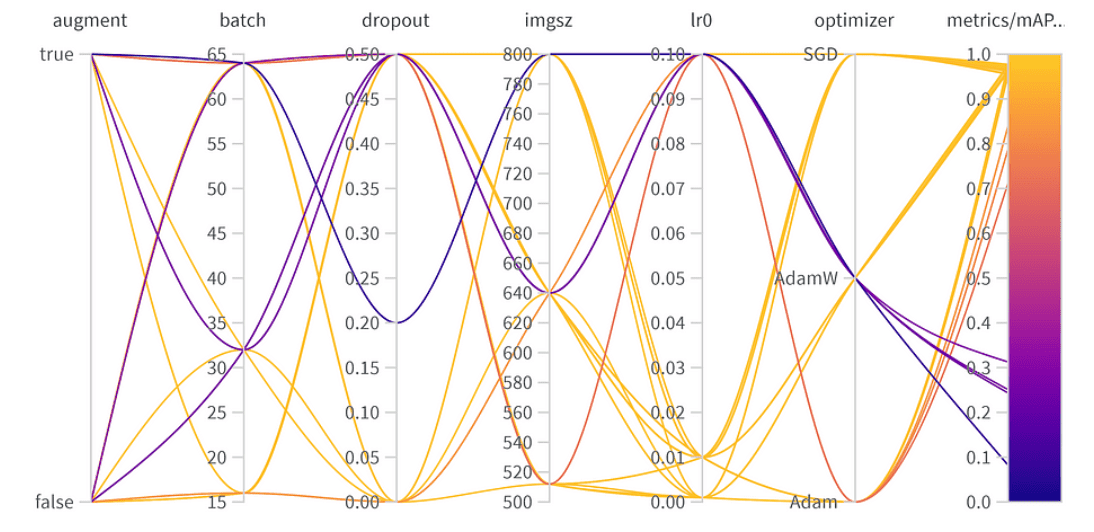
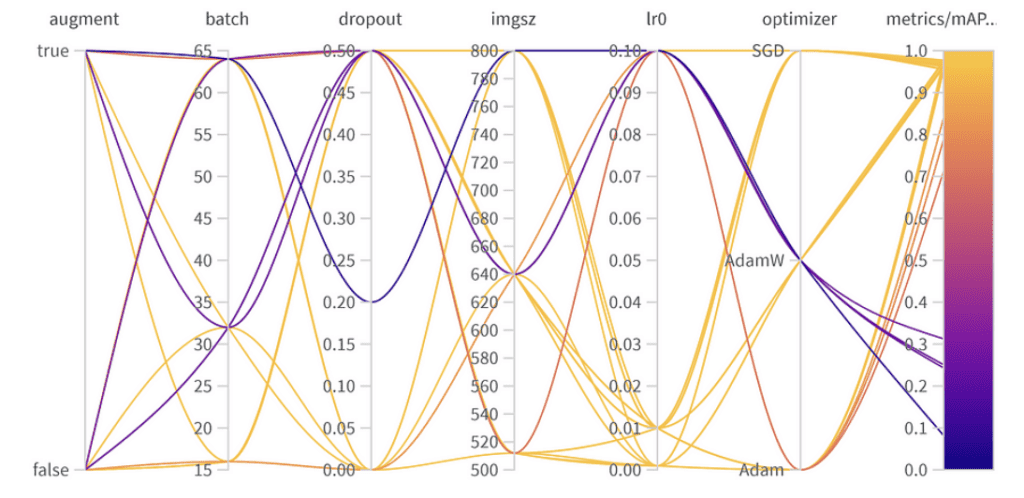
Wyniki optymalizacji hiperparametrów
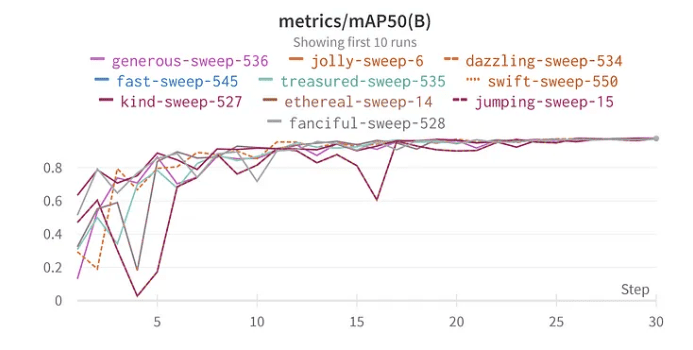
10 najlepszych wyników mAP50 YoloV8
Znaczenie parametru:
- Optymalizator (AdamW): Z ważnością 0.521 i negatywną korelacją sugeruje, że AdamW może znacząco wpłynąć na wydajność, ale nie zawsze pozytywnie.
- Współczynnik uczenia (lr0): Wysoka ważność (0.433) i negatywna korelacja (-0.634) sugerują, że niższy współczynnik uczenia może być lepszy dla naszego zadania.
- Inne: Optymalizatory takie jak SGD & Adam oraz parametry takie jak dropout, rozmiar obrazu i rozmiar wsadu wykazują minimalne znaczenie, co wskazuje na ich mniejszy wpływ na wydajność naszego modelu. Końcowe hiperparametry:
Najlepsza kombinacja hiperparametrów jest następująca z najlepszym wynikiem mAP50 0.9776 w zestawie walidacyjnym:
- Augmentacja: Najlepszy model pominął augmentację danych, wskazując na wystarczającą różnorodność danych.
- Rozmiar wsadu: Wybrano 64, równoważąc wydajność obliczeniową i wydajność modelu.
- Dropout: Wskaźnik 0, sugerujący, że model nie potrzebował tej regularyzacji.
- Rozmiar obrazu: 640 to optymalny punkt dla naszego zadania.
- Współczynnik uczenia: Wybrano 0.001, co jest zgodne z naszymi wcześniejszymi obserwacjami, że niższe współczynniki są korzystne.
- Optymalizator: Co ciekawe, chociaż AdamW wydawał się ważny, w najlepszej kombinacji wybrano Adama. To przypomnienie, że hiperparametry często mają ze sobą powiązane efekty.
Znalezienie równowagi: Najlepsza wydajność vs. Uogólnienie
Chociaż najlepszy wynik mAP50 osiągnięty w naszym zestawie walidacyjnym wynosił 0.9776, istniała inna konfiguracja z bliskim wynikiem mAP50 0.9761. Ten “drugoplanowy” model różni się znacząco tym, że używał augmentacji danych i miał współczynnik dropoutu 0.5. Biorąc pod uwagę niewielki spadek w mAP50 (zaledwie 0.0015), może być korzystne faworyzowanie tego modelu w scenariuszach wdrażania, zwłaszcza jeśli przewidujemy szeroki zakres sytuacji, z którymi model będzie miał do czynienia. Niewielki kompromis w bezpośredniej wydajności może być zrekompensowany lepszą zdolnością modelu do uogólniania.
Podsumowanie
Optymalizacja hiperparametrów może znacząco zwiększyć wydajność Twojego modelu. Dzięki narzędziom takim jak W&B i metodom takim jak optymalizacja bayesowska, ten proces staje się systematyczny i pełen wglądów. Podczas gdy niektóre parametry, takie jak optymalizator i współczynnik uczenia, są kluczowe, inne mają mniejszy wpływ. Podkreśla to potrzebę dostosowywania do konkretnego zadania, a nie ogólnych najlepszych praktyk głębokiego uczenia. Przy wdrażaniu modelu ważne jest, aby rozważyć kompromisy między szczytową wydajnością walidacji a odpornością w różnorodnych rzeczywistych sytuacjach. W niektórych przypadkach model o nieco niższej dokładności walidacji, ale lepszej zdolności do uogólniania dzięki regularyzacji, może być lepszym wyborem. Eksperymentowanie, poparte danymi, jest kluczem!