

Wprowadzenie do YOLOv10
YOLOv10 to najnowszy wynalazek w serii YOLO (You Only Look Once), przełomowej ramie w dziedzinie wizji komputerowej (computer vision). Znany z możliwości wykrywania obiektów w czasie rzeczywistym, YOLOv10 kontynuuje dziedzictwo swoich poprzedników, dostarczając solidne rozwiązanie, które łączy efektywność i dokładność. Ta nowa wersja ma na celu dalsze przesuwanie granic wydajności YOLO zarówno z perspektywy post-processingu, jak i architektury modelu.
Wykrywanie obiektów w czasie rzeczywistym ma na celu dokładne przewidywanie kategorii i pozycji obiektów w obrazie z minimalnym opóźnieniem. Na przestrzeni ostatnich lat, YOLOs wyłoniły się jako wiodący wybór dla wykrywania obiektów w czasie rzeczywistym dzięki ich skutecznemu balansowi między wydajnością a efektywnością. Proces wykrywania w YOLO składa się z dwóch głównych komponentów: procesu przekazywania modelu i kroku post-processingu, który zwykle obejmuje tłumienie maksymalnych wartości (NMS).
YOLOv10 wprowadza kilka kluczowych innowacji, aby sprostać ograniczeniom poprzednich wersji, takim jak poleganie na NMS w post-processingu, co może skutkować zwiększonym opóźnieniem wnioskowania i redundancją obliczeniową. Wykorzystując spójne podwójne przypisania dla szkolenia bez NMS, YOLOv10 osiąga konkurencyjne wyniki i niskie opóźnienie wnioskowania jednocześnie. To podejście pozwala modelowi ominąć potrzebę NMS podczas wnioskowania, prowadząc do bardziej efektywnego wdrożenia end-to-end.
Ponadto, YOLOv10 cechuje się całościową strategią projektowania modelu napędzaną efektywnością i dokładnością. Obejmuje to kompleksową optymalizację różnych komponentów YOLOs, takich jak lekka głowica klasyfikacyjna, przestrzennie-kanałowe oddzielone próbkowanie w dół oraz projekt bloku kierowanego rangą. Te ulepszenia architektoniczne zmniejszają obciążenie obliczeniowe i zwiększają możliwości modelu, co skutkuje znaczącą poprawą wydajności i efektywności na różnych skalach modelu.
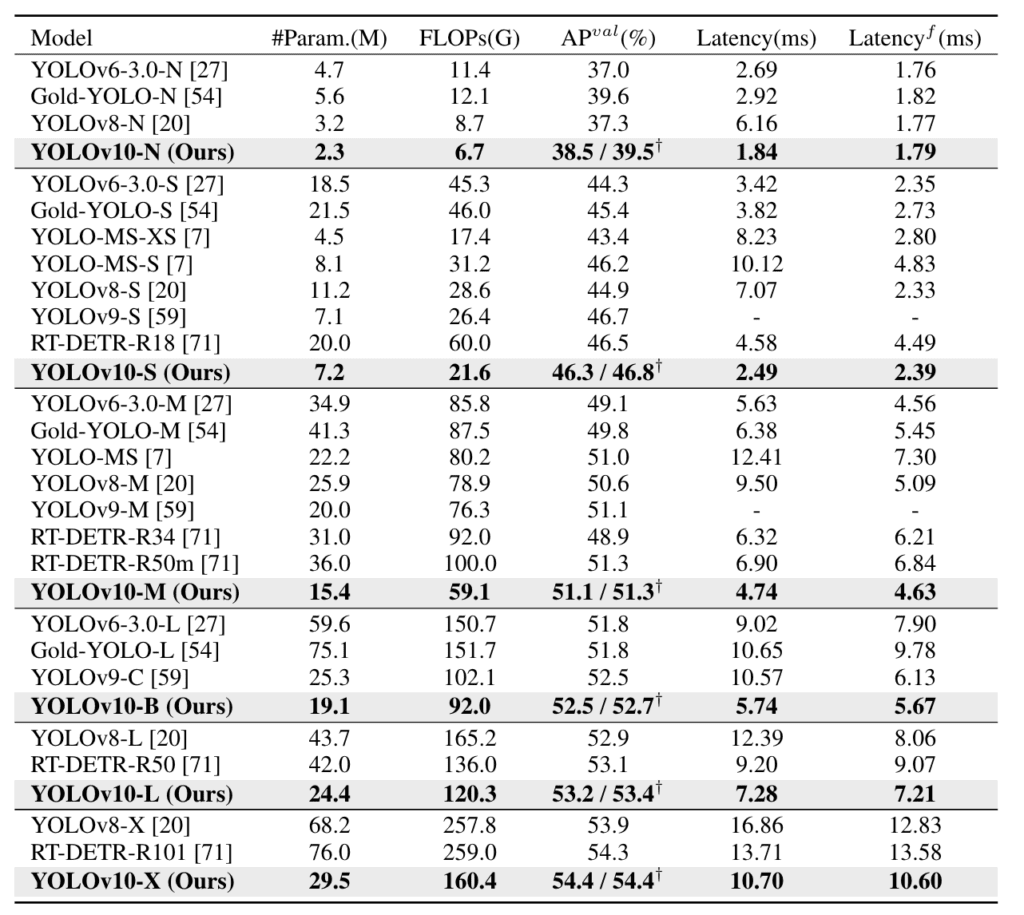
Rozległe eksperymenty pokazują, że YOLOv10 osiąga najnowocześniejsze wyniki na zestawie danych COCO, demonstrując wyższe kompromisy między dokładnością a kosztem obliczeniowym. Na przykład, YOLOv10-S jest 1,8× szybszy niż RT-DETR-R18 przy podobnym AP na COCO, ciesząc się mniejszą liczbą parametrów i FLOPs. W porównaniu z YOLOv9-C, YOLOv10-B ma o 46% mniejsze opóźnienie i o 25% mniej parametrów przy tej samej wydajności, ilustrując jego efektywność i skuteczność.
Ewolucja YOLO: Od YOLOv8 do YOLOv9
Seria YOLO przeszła znaczącą ewolucję, przy czym każda nowa wersja opierała się na sukcesach i rozwiązywała ograniczenia swoich poprzedników. YOLOv8 oraz YOLOv9 wprowadziły kilka kluczowych ulepszeń, które znacząco posunęły do przodu możliwości detekcji obiektów w czasie rzeczywistym.
YOLOv8 wprowadziło innowacje takie jak blok budowlany C2f do skutecznej ekstrakcji i fuzji cech, co pomogło zwiększyć dokładność i efektywność modelu. Dodatkowo, YOLOv8 zoptymalizowało architekturę modelu, aby zmniejszyć koszty obliczeniowe i poprawić szybkość wnioskowania, czyniąc go bardziej wykonalnym rozwiązaniem dla aplikacji w czasie rzeczywistym, to oprócz normalnych optymalizacji hiperparametrów v8.
Jednakże, pomimo tych postępów, nadal zauważalne były nadmiarowe obciążenia obliczeniowe i ograniczenia w efektywności, szczególnie ze względu na zależność od NMS do post-processingu. Ta zależność często prowadziła do suboptymalnej efektywności i zwiększonego opóźnienia wnioskowania, uniemożliwiając modelom osiągnięcie optymalnego wdrożenia od początku do końca.
YOLOv9 miało na celu rozwiązanie tych problemów, wprowadzając architekturę GELAN w celu poprawy struktury modelu oraz Programowalne Informacje Gradientowe (PGI) w celu ulepszenia procesu szkolenia. Te ulepszenia przyniosły lepszą wydajność i efektywność, ale podstawowe wyzwania związane z NMS i obciążeniem obliczeniowym pozostały.
YOLOv10 buduje na tych fundamentach, wprowadzając stałe podwójne przypisania dla szkolenia bez NMS oraz holistyczną strategię projektowania modelu napędzaną efektywnością i dokładnością. Te innowacje pozwalają YOLOv10 osiągnąć konkurencyjną wydajność przy niskim opóźnieniu wnioskowania i zmniejszyć obciążenie obliczeniowe związane z poprzednimi modelami YOLO.
W porównaniu z YOLOv9-C, YOLOv10 osiąga najnowocześniejszą wydajność i efektywność na różnych skalach modelu. Na przykład, YOLOv10-S jest 1,8× szybsze niż RT-DETR-R18 przy podobnym AP na COCO, jednocześnie mając mniej parametrów i FLOPów. Ta znacząca poprawa wydajności i efektywności ilustruje wpływ postępów architektonicznych i wprowadzonych celów optymalizacyjnych w YOLOv10.
Kluczowe funkcje YOLOv10
YOLOv10 wprowadza kilka innowacji, które zwiększają jego wydajność i efektywność. Jedną z najważniejszych cech jest holistyczne podejście do projektowania modelu napędzanego efektywnością i dokładnością. Strategia ta polega na kompleksowej optymalizacji różnych komponentów wewnątrz modelu, zapewniając jego efektywną pracę przy jednoczesnym utrzymaniu wysokiej dokładności.
Aby osiągnąć efektywną detekcję obiektów od początku do końca, YOLOv10 wykorzystuje lekką głowicę klasyfikacyjną, która redukuje obciążenie obliczeniowe bez poświęcania wydajności. Wybór tego rozwiązania jest kluczowy dla aplikacji w czasie rzeczywistym, gdzie równie ważne są szybkość i dokładność. Dodatkowo, model zawiera oddzielone przestrzennie i kanałowo próbkowanie w dół, które optymalizuje procesy redukcji przestrzeni i transformacji kanałów. Ta technika minimalizuje utratę informacji i dodatkowo redukuje obciążenie obliczeniowe.
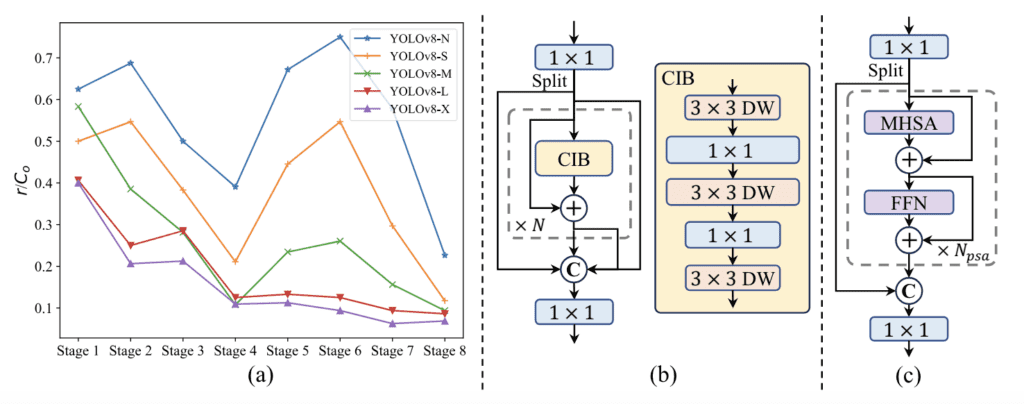
YOLOv10 korzysta również z projektu bloków kierowanych rangą. To podejście analizuje wewnętrzną redundancję każdego etapu modelu i odpowiednio dostosowuje złożoność. Poprzez ukierunkowanie na etapy z zauważalną redundancją obliczeniową, model osiąga lepszą równowagę między efektywnością a dokładnością.
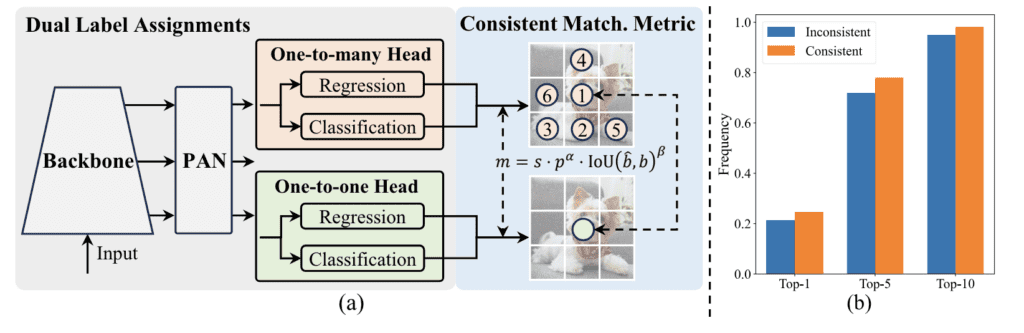
Kolejną kluczową cechą jest spójne podwójne przypisania dla szkolenia bez NMS. Ta metoda zastępuje tradycyjne tłumienie maksymalnych wartości bardziej efektywną i dokładną strategią etykietowania. Dzięki wykorzystaniu podwójnych przypisań etykiet, YOLOv10 utrzymuje konkurencyjną wydajność i niską latencję wnioskowania, co czyni go odpowiednim dla różnych aplikacji w czasie rzeczywistym.
Ponadto, YOLOv10 stosuje duże konwolucje jądrowe i częściowe moduły samo-uwagi, aby poprawić globalne uczenie się reprezentacji. Te komponenty poprawiają zdolność modelu do uchwycenia skomplikowanych wzorców w danych, co prowadzi do lepszej wydajności w zadaniach detekcji obiektów.
Rozumienie tłumienia maksymalnego (NMS) w detekcji obiektów: Podróż z YOLO
W szybko rozwijającej się dziedzinie wizji komputerowej (computer vision), jednym z kluczowych wyzwań jest dokładne wykrywanie obiektów na obrazach przy jednoczesnym minimalizowaniu redundancji. Tutaj właśnie pojawia się tłumienie maksymalne (NMS). Przyjrzyjmy się, czym jest NMS, dlaczego jest ważne i jak najnowsze osiągnięcia w modelach YOLO (You Only Look Once), a konkretnie YOLOv10, rewolucjonizują wykrywanie obiektów, minimalizując zależność od NMS.
Czym jest tłumienie maksymalne (NMS)?
Tłumienie maksymalne (NMS) to technika post-processingu używana w algorytmach detekcji obiektów do udoskonalania wyników poprzez eliminację zbędnych ramek ograniczających. Głównym celem NMS jest zapewnienie, że dla każdego wykrytego obiektu zachowana zostaje tylko najdokładniejsza ramka ograniczająca, podczas gdy nakładające się i mniej dokładne są tłumione. Proces ten pomaga w stworzeniu czystszego i bardziej precyzyjnego wyniku, co jest kluczowe dla aplikacji wymagających wysokiej dokładności i efektywności.
Jak działa NMS?
Proces NMS można podzielić na kilka prostych kroków:
1. Sortowanie wykryć:
Pierwsze, wszystkie wykryte ramki ograniczające są sortowane na podstawie ich wyników ufności w porządku malejącym. Wynik ufności wskazuje prawdopodobieństwo, że ramka ograniczająca dokładnie reprezentuje obiekt.
2. Wybór najlepszej ramki:
Ramka z najwyższym wynikiem ufności jest wybierana jako pierwsza. Ta ramka jest uważana za najbardziej prawdopodobną do poprawności.
3. Tłumienie nakładania się:
Wszystkie inne ramki ograniczające, które znacząco nakładają się na wybraną ramkę, są tłumione. Nakładanie się mierzy za pomocą Intersection over Union (IoU), metryki, która oblicza stosunek obszaru nakładania się do całkowitego obszaru pokrywanego przez obie ramki. Zazwyczaj ramki z IoU powyżej pewnego progu (np. 0,5) są tłumione.
4. Powtórzenie:
Proces jest powtarzany z kolejną ramką o najwyższym wyniku ufności, kontynuowany do momentu przetworzenia wszystkich ramek.
Znaczenie NMS
NMS odgrywa kluczową rolę w detekcji obiektów z kilku powodów:
• Zmniejsza redundancję: Eliminując wielokrotne wykrycia tego samego obiektu, NMS zapewnia, że każdy obiekt jest reprezentowany przez pojedynczą, najdokładniejszą ramkę ograniczającą.
• Poprawia dokładność: Pomaga poprawić precyzję wykrywania, koncentrując się na przewidywaniach o najwyższym poziomie ufności.
• Zwiększa efektywność: Redukując liczbę ramek ograniczających, wynik staje się czystszy i bardziej zrozumiały, co jest szczególnie ważne w aplikacjach czasu rzeczywistego.
YOLO i NMS
Modele YOLO były przełomem w detekcji obiektów w czasie rzeczywistym, znane z równowagi między szybkością a dokładnością. Jednak tradycyjne modele YOLO mocno polegały na NMS, aby odfiltrować zbędne wykrycia po przewidywaniach sieci. Ta zależność od NMS, choć skuteczna, dodawała dodatkowy krok w potoku post-processingu, wpływając na ogólną szybkość wnioskowania.
Revolucja YOLOv10: Szkolenie bez NMS
Z wprowadzeniem YOLOv10 widzimy znaczący postęp w minimalizacji zależności od NMS. YOLOv10 wprowadza szkolenie bez NMS, przełomowe podejście, które zwiększa efektywność i szybkość modelu. Oto jak YOLOv10 osiąga to:
1. Stałe podwójne przypisania:
YOLOv10 stosuje strategię stałych podwójnych przypisań, która łączy podwójne przypisania etykiet i spójną metrykę dopasowania. Ta metoda pozwala na skuteczne szkolenie bez potrzeby stosowania NMS podczas wnioskowania.
2. Podwójne przypisania etykiet:
Integrując przypisania etykiet jeden-do-wielu i jeden-do-jednego, YOLOv10 korzysta z bogatych sygnałów nadzorujących podczas szkolenia, prowadząc do wysokiej efektywności i konkurencyjnej wydajności bez potrzeby post-processingu NMS.
3. Metryka dopasowania:
Spójna metryka dopasowania zapewnia, że nadzór zapewniany przez głowicę jeden-do-wielu harmonijnie współgra z głowicą jeden-do-jednego, optymalizując model pod kątem lepszej wydajności i zmniejszonego opóźnienia.
Wpływ YOLOv10 bez NMS
Innowacje w YOLOv10 oferują kilka zalet:
• Szybsze wnioskowanie: Bez potrzeby stosowania NMS, YOLOv10 znacznie skraca czas wnioskowania, co czyni go idealnym dla aplikacji czasu rzeczywistego, gdzie szybkość jest kluczowa.
• Zwiększona efektywność: Architektura modelu jest zoptymalizowana do wydajnej pracy, zmniejszając obciążenie obliczeniowe i poprawiając wdrażanie na urządzeniach brzegowych o ograniczonych zasobach.
• Poprawiona dokładność: Pomimo większej efektywności, YOLOv10 nie idzie na kompromis w kwestii dokładności, utrzymując wysoką wydajność w różnych zadaniach detekcji obiektów.
Wskaźniki wydajności
Wskaźniki wydajności YOLOv10 podkreślają jego postępy w porównaniu do poprzednich modeli z serii YOLO. Obszerne eksperymenty pokazują, że YOLOv10 osiąga znakomite wyniki pod względem szybkości i dokładności. Strategia projektowania modelu oparta na efektywności i dokładności zapewnia, że może on łatwo radzić sobie z zadaniem detekcji obiektów w czasie rzeczywistym.
W porównaniu z YOLOv9-C, YOLOv10 osiąga znaczące ulepszenia w zakresie opóźnień i efektywności parametrów. YOLOv10-B ma o 46% mniejsze opóźnienia i o 25% mniej parametrów przy tej samej wydajności. Redukcja obciążenia obliczeniowego sprawia, że YOLOv10 jest bardziej praktycznym wyborem dla aplikacji wymagających szybkiego wdrożenia i wysokiej wydajności.
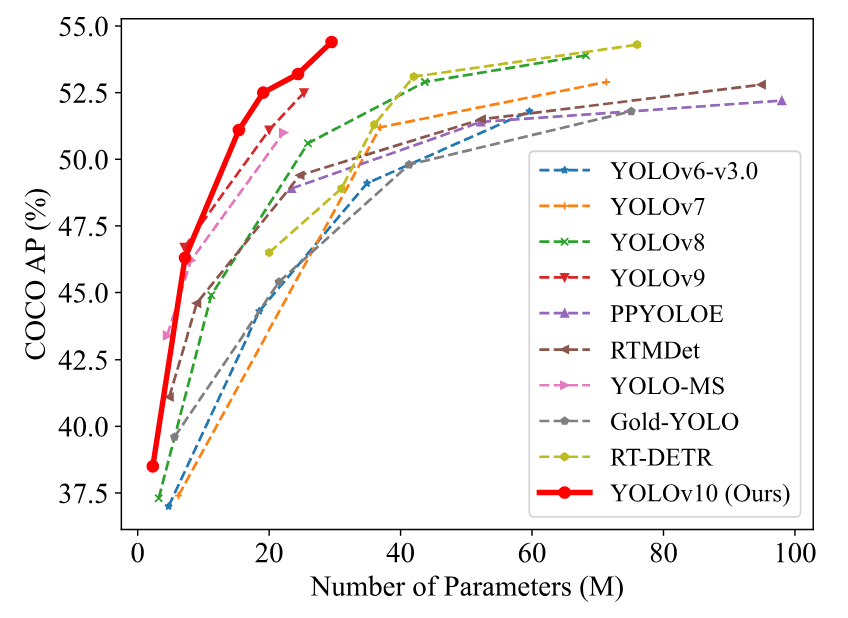

Wydajność YOLOv10 na zestawie danych COCO dodatkowo ilustruje jego możliwości. Model osiąga podobny AP na COCO jak RT-DETR-R18, będąc przy tym 1,8× szybszym. Ta przewaga szybkości jest kluczowa dla aplikacji, gdzie istotne jest przetwarzanie w czasie rzeczywistym. Zdolność modelu do utrzymania wysokiej dokładności przy mniejszym zużyciu zasobów świadczy o jego efektywności i skuteczności.
Dodatkowo, innowacje YOLOv10 w zakresie tłumienia maksymalnego i holistycznego projektowania modelu przyczyniają się do jego wyższej wydajności. Stałe podwójne przypisania dla szkolenia bez NMS pozwalają modelowi ominąć tradycyjne wąskie gardła w post-processingu, co skutkuje szybszymi i bardziej dokładnymi wykryciami.
Integracja lekkiej głowicy klasyfikacyjnej oraz przestrzennie-kanałowego oddzielonego próbkowania w dół również odgrywa znaczącą rolę w zwiększeniu wydajności YOLOv10. Te komponenty redukują koszt obliczeniowy, jednocześnie zachowując dokładność detekcji modelu.
YOLOv10 ustanawia nowy standard w dziedzinie detekcji obiektów w czasie rzeczywistym od początku do końca. Jego innowacyjne funkcje i kompleksowa optymalizacja pozwalają mu dostarczać najnowocześniejszą wydajność i efektywność na różnych skalach modelu. W rezultacie, YOLOv10 jest odpowiedni dla szerokiego zakresu aplikacji, od autonomicznej jazdy po nadzór bezpieczeństwa, gdzie zarówno szybkość, jak i dokładność są kluczowe.
YOLOv10 i VisionPlatform.ai: Idealne Połączenie
VisionPlatform.ai wyróżnia się w dziedzinie wizji komputerowej (computer vision) oferując kompleksową i przyjazną dla użytkownika platformę wizyjną bez kodowania vision platform, która przekształca KAŻDĄ kamerę w kamerę AI. Integracja YOLOv10 z VisionPlatform.ai tworzy potężne połączenie dla efektywnej detekcji obiektów od początku do końca. YOLOv10 wykorzystuje innowacyjne techniki, które dobrze współgrają z zaangażowaniem VisionPlatform.ai w wysoką wydajność i łatwość wdrożenia.
Jedną z głównych zalet używania YOLOv10 z VisionPlatform.ai jest możliwość wykorzystania lokalnego przetwarzania bezpośrednio w kamerze (nazywane edge computing) za pomocą NVIDIA Jetson, takich jak AGX Orin, NX Orin lub Nano Orin, co przyspiesza wdrożenie YOLOv10 do zadań detekcji obiektów w czasie rzeczywistym i przetwarzania w czasie rzeczywistym. Integracja ta redukuje obciążenie obliczeniowe i zwiększa wydajność platformy. Tymczasem, korzystając z zalet holistycznego modelu YOLOv10, który jest napędzany efektywnością i dokładnością, VisionPlatform.ai może dostarczać najnowocześniejszą wydajność w różnych zastosowaniach, takich jak logistyka i zarządzanie łańcuchem dostaw.
Dodatkowo, VisionPlatform.ai wykorzystuje NVIDIA DeepStream, co dodatkowo optymalizuje wdrożenie YOLOv10 do detekcji obiektów w czasie rzeczywistym. To połączenie zapewnia, że platforma może sprostać wymagającym wymaganiom nowoczesnych aplikacji AI, dostarczając użytkownikom solidne i skalowalne rozwiązanie. Efektywna architektura YOLOv10 i przyjazny dla użytkownika interfejs VisionPlatform.ai sprawiają, że jest on dostępny zarówno dla początkujących, jak i zaawansowanych użytkowników.
Ponadto, VisionPlatform.ai obsługuje różne modele i konfiguracje, pozwalając użytkownikom dostosować swoje ustawienia do konkretnych potrzeb. Elastyczność platformy zapewnia, że może ona pomieścić różne kategorie i pozycje obiektów, zwiększając jej wszechstronność. Obszerne eksperymenty pokazują, że integracja YOLOv10 z VisionPlatform.ai prowadzi do lepszej wydajności i efektywności, czyniąc ją idealnym wyborem dla firm poszukujących zaawansowanych rozwiązań AI.
YOLOv10 i NMS: Postęp w zakresie przetwarzania końcowego
YOLOv10 wprowadza przełomowe podejście do wykrywania obiektów, eliminując potrzebę stosowania tłumienia maksymalnych wartości (NMS). Tradycyjne NMS, używane w wcześniejszych wersjach YOLO, często prowadziło do zwiększenia opóźnień wnioskowania i zauważalnej nadmiarowości obliczeniowej. Ta nowa metoda wykorzystuje stałe podwójne przypisania dla szkolenia bez NMS, znacząco zwiększając efektywność i dokładność modelu. Ta konstrukcja zapewnia, że YOLOv10 może dostarczać najnowocześniejszą wydajność i efektywność w różnych zastosowaniach, od autonomicznej jazdy po monitoring bezpieczeństwa / CCTV.
W ostatnich latach, zależność od NMS stanowiła wyzwanie w optymalizacji wydajności detektorów obiektów. YOLOv10 adresuje te wyzwania poprzez nową strategię, która zastępuje NMS podwójnymi przypisaniami etykiet. To podejście zapewnia, że model może efektywnie obsługiwać przypisania jeden-do-wielu i jeden-do-jednego, redukując koszty obliczeniowe i poprawiając szybkość wykrywania. Obszerne eksperymenty pokazują, że YOLOv10 osiąga najnowocześniejszą wydajność bez tradycyjnych wąskich gardeł w post-processingu.
Podwójne przypisania dla szkolenia bez NMS pozwalają YOLOv10 utrzymać konkurencyjną wydajność i niskie opóźnienia wnioskowania. W porównaniu do YOLOv9-C, YOLOv10 osiąga lepszą efektywność i dokładność, demonstrując swoją wyższość w wykrywaniu obiektów w czasie rzeczywistym. Na przykład, YOLOv10-B ma o 46% mniejsze opóźnienia, prezentując swoją zaawansowaną optymalizację.
Podczas cieszenia się tymi ulepszeniami, YOLOv10 utrzymuje solidną architekturę, która wspiera globalne uczenie się reprezentacji. Ta zdolność pozwala modelowi dokładnie przewidywać kategorie i pozycje obiektów, nawet w skomplikowanych scenariuszach. Eliminacja NMS nie tylko usprawnia proces wykrywania, ale także zwiększa ogólną wydajność i skalowalność modelu.
Podsumowując, innowacyjne podejście YOLOv10 do szkolenia bez NMS stanowi nowy punkt odniesienia w wykrywaniu obiektów. Poprzez kompleksową optymalizację różnych komponentów i stosowanie stałych podwójnych przypisań, YOLOv10 dostarcza wyższą wydajność i efektywność, czyniąc go preferowanym wyborem dla aplikacji w czasie rzeczywistym.
Kierunki rozwoju i podsumowanie
YOLOv10 stanowi znaczący krok naprzód w dziedzinie detekcji obiektów w czasie rzeczywistym, jednak nadal istnieje miejsce na dalsze postępy. Przyszłe kierunki rozwoju YOLOv10 prawdopodobnie skoncentrują się na zwiększeniu obecnych możliwości, jednocześnie badając nowe zastosowania i metodyki. Jednym z obiecujących obszarów jest integracja bardziej zaawansowanych strategii augmentacji danych. Te strategie mogą pomóc modelowi lepiej uogólniać na różnorodnych zestawach danych, poprawiając jego odporność i dokładność w różnych scenariuszach.
W ciągu ostatnich lat modele YOLO nieustannie ewoluowały, aby sprostać rosnącym wymaganiom detekcji obiektów w czasie rzeczywistym. YOLOv10 kontynuuje ten trend, przesuwając granice wydajności i efektywności. Przyszłe iteracje mogą budować na tym fundamencie, włączając postępy w przyspieszeniu sprzętowym i wykorzystując nowe technologie, aby jeszcze bardziej zmniejszyć opóźnienia w wnioskowaniu i zwiększyć moc przetwarzania.
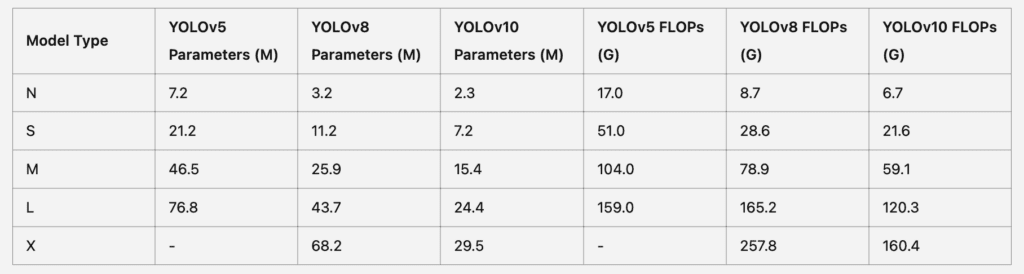
Kolejny potencjalny kierunek to kompleksowa optymalizacja różnych komponentów modelu, aby radzić sobie z bardziej złożonymi zadaniami detekcji. Ta optymalizacja może obejmować ulepszenia w zdolności modelu do dokładnego wykrywania i klasyfikowania szerszego zakresu kategorii i pozycji, czyniąc go jeszcze bardziej wszechstronnym. Ponadto, ulepszenia w przypisaniach etykiet jeden-do-wielu i jeden-do-jednego mogą dodatkowo udoskonalić dokładność detekcji modelu.
Współpraca z platformami takimi jak GitHub oraz szersza społeczność open-source będzie kluczowa w napędzaniu tych postępów. Dzięki dzieleniu się wglądami i rozwojem, badacze i programiści mogą wspólnie posuwać do przodu możliwości YOLOv10 i przyszłych modeli.
Podsumowując, YOLOv10 ustanawia nowy standard dla modeli najnowszej generacji pod względem wydajności i efektywności. Jego innowacyjna architektura i metodyki szkoleniowe zapewniają solidną ramę dla detekcji obiektów w czasie rzeczywistym. W miarę ewolucji modelu, niewątpliwie zainspiruje on do dalszych badań i rozwoju, napędzając dziedzinę wizji komputerowej (computer vision) do przodu. Przyjmując przyszłe postępy i wykorzystując współpracę społeczności, YOLOv10 utrzyma swoją pozycję na czele technologii detekcji obiektów w czasie rzeczywistym.
Najczęściej zadawane pytania o YOLOv10
YOLOv10 nadal przesuwa granice detekcji obiektów w czasie rzeczywistym, dlatego wielu deweloperów i entuzjastów ma pytania dotyczące jego możliwości, zastosowań i ulepszeń w porównaniu do poprzednich wersji. Poniżej odpowiadamy na niektóre z najczęściej zadawanych pytań dotyczących YOLOv10, aby pomóc Ci zrozumieć jego funkcje i potencjalne zastosowania.
Czym jest YOLOv10?
YOLOv10 to najnowsza iteracja w serii YOLO (You Only Look Once), zaprojektowana specjalnie do detekcji obiektów w czasie rzeczywistym. Wprowadza znaczące ulepszenia w zakresie efektywności i dokładności, wykorzystując holistyczny model napędzany efektywnością i dokładnością. YOLOv10 eliminuje również potrzebę stosowania tłumienia maksymalnego (NMS) podczas wnioskowania, co skutkuje szybszym przetwarzaniem i zmniejszeniem obciążenia obliczeniowego.
Jak YOLOv10 poprawia się w porównaniu do YOLOv9?
YOLOv10 poprawia się w porównaniu do YOLOv9, wprowadzając stałe podwójne przypisania dla szkolenia bez NMS, co znacznie redukuje opóźnienia wnioskowania. Dodatkowo, YOLOv10 używa lekkiej głowicy klasyfikacyjnej i przestrzennie-kanałowego oddzielonego próbkowania w dół, co razem zwiększa efektywność i dokładność modelu. W porównaniu z YOLOv9-C, YOLOv10-B ma o 46% mniejsze opóźnienie i o 25% mniej parametrów.
Jakie są kluczowe cechy YOLOv10?
Kluczowe cechy YOLOv10 to holistyczny model napędzany efektywnością i dokładnością, który kompleksowo optymalizuje różne komponenty modelu. Wykorzystuje lekką głowicę klasyfikacyjną i przestrzennie-kanałowe oddzielone próbkowanie w dół, aby zmniejszyć obciążenie obliczeniowe. Dodatkowo, YOLOv10 stosuje duże konwolucje jądrowe i częściowe moduły samo-uwagi, aby zwiększyć globalne uczenie reprezentacji, prowadząc do najnowocześniejszej wydajności i efektywności.
Jak YOLOv10 radzi sobie z tłumieniem maksymalnym (NMS)?
YOLOv10 radzi sobie z tłumieniem maksymalnym (NMS) poprzez całkowite jego eliminowanie podczas wnioskowania. Zamiast tego używa stałych podwójnych przypisań do szkolenia bez NMS. To podejście pozwala modelowi utrzymać konkurencyjną wydajność, jednocześnie redukując opóźnienia wnioskowania i nadmiar obliczeniowy, znacząco zwiększając ogólną efektywność i dokładność w zadaniach detekcji obiektów.
Jakie zbiory danych są używane do oceny YOLOv10?
YOLOv10 jest oceniany głównie na zbiorze danych COCO, który obejmuje 80 wstępnie wytrenowanych klas i jest szeroko używany do oceny modeli detekcji obiektów. Obszerne eksperymenty na zbiorze danych COCO pokazują, że YOLOv10 osiąga najnowocześniejszą wydajność, z znaczącymi ulepszeniami zarówno w dokładności, jak i efektywności w porównaniu do poprzednich wersji YOLO i innych detektorów obiektów w czasie rzeczywistym.
Jakie są rzeczywiste zastosowania YOLOv10?
YOLOv10 jest używany w różnych rzeczywistych zastosowaniach, w tym w autonomicznej jeździe, monitoringu i logistyce. Jego efektywna i dokładna detekcja obiektów czyni go idealnym do zadań takich jak identyfikacja pieszych i pojazdów w czasie rzeczywistym. Dodatkowo, w logistyce pomaga w zarządzaniu zapasami i śledzeniu paczek, znacząco zwiększając efektywność operacyjną i dokładność.
Jak YOLOv10 porównuje się z innymi najnowocześniejszymi modelami?
YOLOv10 porównuje się korzystnie z innymi najnowocześniejszymi modelami, takimi jak RT-DETR-R18 i poprzednie wersje YOLO. Osiąga podobne AP na zbiorze danych COCO, będąc jednocześnie 1,8× szybszym. W porównaniu do YOLOv9-C, YOLOv10 oferuje o 46% mniejsze opóźnienie i o 25% mniej parametrów, co czyni go wysoce efektywnym dla aplikacji w czasie rzeczywistym.
Czy YOLOv10 można zintegrować z platformami takimi jak VisionPlatform.ai?
Tak, YOLOv10 można zintegrować z platformami takimi jak VisionPlatform.ai. Integracja wykorzystuje NVIDIA Jetson i NVIDIA DeepStream, aby zwiększyć możliwości przetwarzania w czasie rzeczywistym. Przyjazny dla użytkownika interfejs VisionPlatform.ai oraz solidna infrastruktura wspierają efektywne wdrożenie YOLOv10 od początku do końca, czyniąc go dostępnym zarówno dla początkujących, jak i ekspertów.
Jak deweloperzy mogą zacząć pracować z YOLOv10?
Deweloperzy mogą zacząć pracować z YOLOv10, uzyskując dostęp do jego repozytorium na GitHubie, które zapewnia kompleksową dokumentację i przykłady kodów. Repozytorium zawiera pakiet Pythona do pobrania, który upraszcza proces wdrażania. Dodatkowo, dostępne są obszerne zasoby i wsparcie społeczności, które pomagają deweloperom w implementacji i dostosowywaniu YOLOv10 do różnych zastosowań.
Jakie są przyszłe kierunki rozwoju YOLOv10?
Przyszłe kierunki rozwoju YOLOv10 obejmują zwiększenie strategii augmentacji danych i optymalizację modelu dla lepszej wydajności na różnorodnych zbiorach danych. Dalsze badania mogą skupić się na zmniejszeniu kosztów obliczeniowych przy jednoczesnym zwiększeniu dokładności. Współpraca w ramach społeczności open-source również będzie napędzać postępy, zapewniając, że YOLOv10 pozostanie na czele technologii detekcji obiektów w czasie rzeczywistym.