
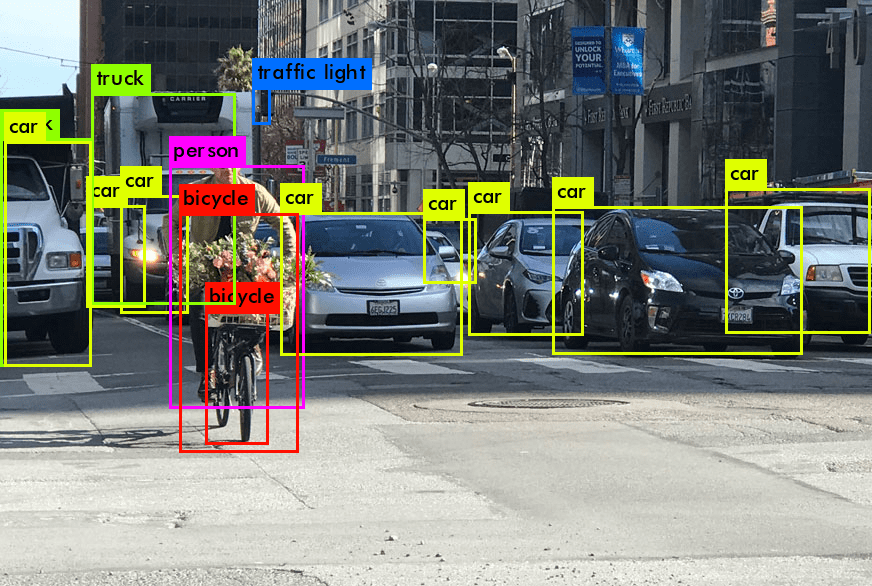
Wprowadzenie do wykrywania obiektów w wizji komputerowej (computer vision)
Wykorzystanie wykrywania obiektów, podstawowego zadania wizji komputerowej (computer vision), zrewolucjonizowało sposób, w jaki maszyny interpretują świat wizualny. W przeciwieństwie do klasyfikacji obrazów, gdzie celem jest klasyfikacja całego obrazu, wykrywanie obiektów może być używane do identyfikacji i lokalizacji obiektów w obrazie lub klatce wideo (która jest taka sama jak obraz / zdjęcie). Proces ten obejmuje rozpoznawanie konkretnego obiektu, lokalizację obiektu i określanie jego pozycji za pomocą ramki ograniczającej. Wykrywanie obiektów łączy klasyfikację obrazów z bardziej złożonymi zadaniami, takimi jak segmentacja obrazu, gdzie celem jest oznaczenie każdego piksela obrazu jako należącego do konkretnego pojedynczego obiektu.
Pojawienie się uczenia głębokiego, szczególnie stosowanie konwolucyjnych sieci neuronowych (CNN), znacząco posunęło naprzód wykrywanie obiektów. Te sieci neuronowe skutecznie przetwarzają i analizują dane wizualne, co czyni je idealnymi do wykrywania obiektów w obrazie lub wideo. Kluczowe rozwinięcia, takie jak YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) i sieci oparte na propozycjach regionów, takie jak Mask R-CNN, dodatkowo zwiększyły dokładność i efektywność systemów wykrywania obiektów. Te modele mogą przeprowadzać wykrywanie w czasie rzeczywistym, co jest kluczowym czynnikiem dla aplikacji takich jak autonomiczna jazda czy monitorowanie w czasie rzeczywistym.
Ponadto integracja technik uczenia maszynowego pozwoliła systemom wykrywania obiektów na klasyfikację i segmentację różnych obiektów w złożonych środowiskach. Ta zdolność jest kluczowa dla szeregu zastosowań, od wykrywania pieszych w infrastrukturach inteligentnych miast po kontrolę jakości w produkcji.
Zrozumienie zbioru danych do wykrywania obiektów
Podstawą każdego skutecznego systemu wykrywania obiektów jest jego zbiór danych. Zbiór danych do wykrywania obiektów składa się z obrazów lub filmów z adnotacjami, które służą do szkolenia detektora. Te adnotacje zazwyczaj obejmują ramki ograniczające wokół obiektów oraz etykiety wskazujące klasę każdego obiektu. Jakość, różnorodność i wielkość zbioru danych odgrywają kluczową rolę w wydajności modeli wykrywania obiektów. Na przykład, większe zbiory danych z szerokim zakresem obiektów i scenariuszy umożliwiają sieci neuronowej naukę bardziej solidnych i uogólnionych cech.
Zbiory danych takie jak PASCAL VOC, MS COCO i ImageNet odegrały kluczową rolę w rozwoju wykrywania obiektów. Zapewniają one szeroki zakres adnotowanych obrazów, od codziennych przedmiotów po specyficzne scenariusze, wspomagając rozwój wszechstronnych i dokładnych modeli wykrywania. Te zbiory danych nie tylko ułatwiają szkolenie modeli, ale także służą jako punkty odniesienia do oceny i porównywania wydajności różnych algorytmów wykrywania obiektów.
Szkolenie modelu do wykrywania obiektów obejmuje również stosowanie technik takich jak transfer learning, gdzie model wstępnie wyszkolony na dużym zbiorze danych jest dostosowywany do mniejszego, specyficznego zbioru danych. To podejście jest szczególnie korzystne, gdy dostępne dane do wykrywania obiektów są ograniczone lub gdy szkolenie modelu od podstaw jest kosztowne obliczeniowo.
Podsumowując, zbiór danych jest kluczowym składnikiem w wykrywaniu obiektów, bezpośrednio wpływającym na zdolność modelu do dokładnego wykrywania obiektów w różnych kontekstach i środowiskach. W miarę jak powiązane zadania wizji komputerowej (wizja komputerowa) i technologia nadal się rozwijają, tworzenie i doskonalenie zbiorów danych pozostaje kluczowym obszarem zainteresowania badaczy i praktyków w tej dziedzinie.
Eksploracja modeli wykrywania obiektów: od tradycyjnych do głębokiego uczenia
Wykrywanie obiektów to zadanie wizji komputerowej (computer vision), które znacznie ewoluowało, szczególnie z rozwojem technologii głębokiego uczenia. Początkowo, wykrywanie obiektów opierało się na prostszych technikach wizji komputerowej (computer vision) i algorytmach uczenia maszynowego, gdzie cechy do klasyfikacji obiektów były ręcznie opracowywane, a modele były trenowane do wykrywania obiektów na obrazach na podstawie tych cech. Wprowadzenie głębokiego uczenia, szczególnie głębokich sieci konwolucyjnych (CNN), zrewolucjonizowało tę dziedzinę. CNN automatycznie uczą się hierarchii cech z danych, co umożliwia dokładniejsze wykrywanie obiektów i segmentację semantyczną. Przejście na modele głębokiego uczenia oznaczało znaczącą poprawę zdolności wykrywania obiektów.
Wczesne modele wykrywania obiektów oparte na CNN, takie jak R-CNN, stosowały metodę propozycji regionów do identyfikacji potencjalnych lokalizacji obiektów na obrazie, a następnie klasyfikowały każdy region. Następcy, tacy jak Fast R-CNN i Faster R-CNN, wprowadzili ulepszenia, zwiększając dokładność wykrywania i szybkość przetwarzania. Dalszy rozwój doprowadził do wprowadzenia Mask R-CNN, który rozszerzył możliwości swoich poprzedników, dodając gałąź do segmentacji na poziomie pikseli, co ułatwia szczegółową lokalizację i rozpoznawanie obiektów.
YOLO: Rewolucja w detekcji obiektów w czasie rzeczywistym
W dziedzinie detekcji obiektów w czasie rzeczywistym, model YOLO (You Only Look Once) stanowi znaczący przełom. YOLO unikalnie postrzega detekcję obiektów jako pojedynczy problem regresji, bezpośrednio przewidując współrzędne ramki ograniczającej i prawdopodobieństwa klas z pikseli obrazu w jednej ocenie. To podejście pozwala YOLO osiągnąć wyjątkowe prędkości przetwarzania, niezbędne dla aplikacji wymagających detekcji w czasie rzeczywistym, takich jak wykrywanie pieszych i śledzenie pojazdów w inteligentnych miastach.
Architektura YOLO przetwarza cały obraz podczas treningu, co pozwala mu zrozumieć kontekstowe informacje o klasach obiektów i ich wyglądzie. Kontrastuje to z metodami opartymi na propozycjach regionów, które mogą przeoczyć niektóre szczegóły kontekstowe. Zdolność przetwarzania w czasie rzeczywistym YOLO czyni go niezastąpionym w scenariuszach wymagających szybkiej i dokładnej detekcji obiektów. Rodzina modeli YOLO, w tym zaawansowane wersje takie jak YOLOv3 i YOLOv4, przesunęła granice pod względem prędkości i dokładności detekcji, ustanawiając YOLO jako system najnowocześniejszy w detekcji obiektów w czasie rzeczywistym, aż do YOLOv8.
Analiza wideo w czasie rzeczywistym detekcji obiektów na dronie podczas lotu z visionplatform.ai i naszym komputerem NVIDIA Jetson Edge zamontowanym na dronie. Zamieniamy KAŻDĄ kamerę w kamerę AI.
Kluczowe komponenty w wykrywaniu obiektów: klasyfikacja i ramka ograniczająca
Wprowadzenie do wykrywania obiektów ujawnia dwa podstawowe aspekty: klasyfikację i ramkę ograniczającą. Klasyfikacja odnosi się do identyfikacji klasy obiektu (np. pieszy, pojazd) na obrazie. Jest to kluczowy krok w rozróżnianiu różnych kategorii obiektów w systemie wykrywania. Ramka ograniczająca z kolei polega na lokalizowaniu obiektu w obrazie, zazwyczaj reprezentowanym przez współrzędne obrysowujące obiekt. Razem te komponenty stanowią podstawę wykrywania i śledzenia obiektów.
Wykrywanie obiektów może pomóc modelom, takim jak rodzina modeli YOLO i detektor Single Shot Multibox (SSD), gdzie połączenie klasyfikacji i ramek ograniczających zapewnia dokładność wykrywania. Te modele, często rozwijane i udostępniane na platformach takich jak GitHub, wykorzystują podejścia oparte na głębokim uczeniu. Mogą być również używane bez pisania linijki kodu na platformach wizyjnych (wizja komputerowa) takich jak visionplatform.ai. Są zdolne do wykrywania wielu obiektów na obrazie i dokładnego przewidywania lokalizacji każdego obiektu z ramką ograniczającą wokół niego. To podwójne podejście jest niezbędne w różnych przypadkach użycia wykrywania obiektów, od wykrywania twarzy w systemach bezpieczeństwa po wykrywanie anomalii w ustawieniach przemysłowych.
Rola uczenia głębokiego w wykrywaniu obiektów
Metody uczenia głębokiego zrewolucjonizowały wizję komputerową (computer vision) i wykrywanie obiektów. Te metody, głównie opierające się na głębokich sieciach neuronowych takich jak CNN, umożliwiły dokładniejsze wykrywanie obiektów i segmentację semantyczną. TensorFlow, popularna otwartoźródłowa biblioteka do uczenia maszynowego i uczenia głębokiego, oferuje solidne narzędzia do trenowania i wdrażania modeli uczenia głębokiego do wykrywania obiektów.
Skuteczność uczenia głębokiego w wykrywaniu obiektów można zaobserwować w jego zastosowaniu do skomplikowanych zadań, takich jak wykrywanie pieszych i wykrywanie tekstu. Te modele uczą się hierarchii cech dla dokładnego wykrywania obiektów, znacznie poprawiając w stosunku do tradycyjnych algorytmów uczenia maszynowego, które wymagały ręcznie opracowywanych cech. Modele wykrywania obiektów oparte na uczeniu głębokim są zwykle oceniane według ich dokładności wykrywania i szybkości, co czyni je idealnymi do zastosowań w czasie rzeczywistym.
Z postępem technik uczenia głębokiego, systemy wykrywania obiektów stały się bardziej wszechstronne, zdolne do obsługi szerokiego zakresu zadań wizji komputerowej (computer vision), w tym śledzenia obiektów, wykrywania osób i rozpoznawania obrazów. Ten postęp doprowadził do rozwoju solidnych algorytmów wykrywania obiektów, które mogą niezawodnie klasyfikować i lokalizować obiekty, nawet w trudnych warunkach.
Segmentacja i rozpoznawanie obiektów: Zwiększenie wykrywania dzięki szczegółowej analizie
Wprowadzenie do wykrywania obiektów w wizji komputerowej (computer vision) często prowadzi do eksploracji powiązanych zadań, takich jak segmentacja i rozpoznawanie obiektów. Podczas gdy wykrywanie obiektów identyfikuje i lokalizuje obiekty w obrazie, segmentacja idzie o krok dalej, dzieląc obraz na segmenty, aby uprościć jego analizę lub zmienić jego reprezentację. Rozpoznawanie obiektów z kolei polega na identyfikacji konkretnego obiektu obecnego na obrazie.
Techniki oparte na głębokim uczeniu, szczególnie głębokie sieci neuronowe konwolucyjne, znacząco posunęły te obszary do przodu. Segmentacja, zwłaszcza semantyczna segmentacja, jest integralną częścią zrozumienia kontekstu, w którym obiekty istnieją na obrazach. Jest to kluczowe w przypadkach użycia, takich jak obrazowanie medyczne, gdzie precyzyjna identyfikacja tkanek lub anomalii jest niezbędna. Algorytmy wykrywania obiektów, które obejmują segmentację, takie jak Mask R-CNN, dostarczają szczegółowych wglądów, nie tylko lokalizując „ograniczną ramkę wokół” obiektu, ale także precyzyjnie określając „kształt obiektu”.
Przetwarzanie obrazu wejściowego: Podróż przez systemy wykrywania obiektów
Proces wykrywania obiektów rozpoczyna się od obrazu wejściowego, który przechodzi przez kilka etapów w sieci detekcyjnej. Początkowo obraz jest przetwarzany wstępnie, aby dostosować go do wymagań modelu wykrywania obiektów. Może to obejmować zmianę rozmiaru, normalizację i augmentację. Następnie obraz jest wprowadzany do modelu głębokiego uczenia, zwykle typu modelu jak CNN, w celu ekstrakcji cech.
Wyekstrahowane cechy są następnie używane do klasyfikacji obiektów i przewidywania ich lokalizacji. Wykrywanie obiektów używane w scenariuszach czasu rzeczywistego, takich jak wykrywanie pieszych czy śledzenie pojazdów, wymaga od modelu szybkiej analizy obrazu wejściowego i dostarczenia dokładnych „przewidywanych ramek ograniczających” dla każdego „obiektu obecnego”. Tutaj modele takie jak YOLO wyróżniają się, oferując szybkie i efektywne przetwarzanie odpowiednie dla aplikacji w czasie rzeczywistym.
Szkolenie modelu do takich złożonych zadań wymaga znacznej ilości danych do wykrywania obiektów. Dane te, zwykle zawierające różnorodne obrazy z adnotowanymi obiektami, pomagają modelowi uczyć się różnych kategorii obiektów i ich cech. Popularne ramy wykrywania obiektów, takie jak TensorFlow, oferują narzędzia i biblioteki do budowania, szkolenia i wdrażania tych modeli w sposób efektywny. Cały proces podkreśla synergia między technikami wizji komputerowej (computer vision) i przetwarzaniem obrazów, algorytmami uczenia maszynowego i metodami uczenia głębokiego, co skutkuje solidnym systemem wykrywania obiektów.
Zastosowania wykrywania obiektów w różnych branżach
Wykrywanie obiektów, wspierane przez modele oparte na głębokim uczeniu, znalazło zastosowanie w różnorodnych branżach, każda z nich ma unikalne wymagania i wyzwania. Modele te są zwykle oceniane według ich dokładności, szybkości i zdolności do wykrywania wielu obiektów w różnych warunkach. W sektorze opieki zdrowotnej, wykrywanie obiektów pomaga w identyfikacji anomalii w obrazowaniu medycznym, znacząco przyczyniając się do wczesnej diagnozy i planowania leczenia. W handlu detalicznym odgrywa kluczową rolę w analizie zachowań klientów i zarządzaniu zapasami.
Jednym z godnych uwagi przypadków użycia wykrywania obiektów jest przemysł motoryzacyjny, gdzie jest to kluczowe dla rozwoju pojazdów autonomicznych. Tutaj zdolność do wykrywania i rozróżniania między dwoma obiektami, takimi jak piesi i inne pojazdy, jest niezbędna dla bezpieczeństwa. Systemy wykrywania obiektów, wykorzystujące zaawansowane algorytmy i sieci neuronowe, umożliwiają tym pojazdom bezpieczną nawigację poprzez dokładne interpretowanie otoczenia.
TensorFlow w wykrywaniu obiektów: Wykorzystanie modeli głębokiego uczenia
TensorFlow, otwarta platforma dostępna na platformach takich jak GitHub, stała się synonimem budowania i wdrażania modeli głębokiego uczenia, szczególnie w dziedzinie wykrywania obiektów. Jego obszerna biblioteka pozwala programistom budować model od podstaw lub używać wcześniej wytrenowanych modeli do wykrywania obiektów. Elastyczność TensorFlow w obsłudze różnych mechanizmów propozycji obiektów oraz jego efektywne przetwarzanie dużych zbiorów danych sprawiają, że jest to preferowany wybór wielu programistów.
W wykrywaniu obiektów kluczowe jest podejście uczenia się. TensorFlow ułatwia implementację skomplikowanych algorytmów, które mogą różnicować zadania 'wykrywanie vs. klasyfikacja’, co jest niezbędne w subtelnych scenariuszach wykrywania obiektów. Platforma obsługuje szeroki zakres modeli, od tych wymagających intensywnych zasobów obliczeniowych po lekkie modele odpowiednie dla urządzeń mobilnych. Ta adaptacyjność zapewnia, że modele oparte na TensorFlow mogą być wdrażane w różnych środowiskach, od systemów opartych na serwerach po urządzenia krawędziowe takie jak Jetson Nano Orin, Jetson NX Orin lub Jetson AGX Orin, rozszerzając zakres i dostępność technologii wykrywania obiektów.
Dogłębne badanie modelu YOLO
Model YOLO (You Only Look Once), oparty na głębokim uczeniu framework do wykrywania obiektów, stanowi znaczący przełom w podejściu do nauki wykrywania obiektów. W przeciwieństwie do tradycyjnych modeli, gdzie system najpierw proponuje potencjalne regiony (propozycja obiektu), a następnie klasyfikuje każdy region, YOLO stosuje pojedynczą sieć neuronową do całego obrazu, przewidując ramki ograniczające i prawdopodobieństwa klas dla wielu obiektów w jednej ocenie. To podejście, skupiające się na całym obrazie, a nie na oddzielnych propozycjach, pozwala YOLO skutecznie wykrywać obiekty w czasie rzeczywistym.
Modele YOLO są zwykle oceniane pod kątem ich szybkości i dokładności w wykrywaniu wielu obiektów. W scenariuszach, gdzie dwa obiekty znajdują się blisko siebie, zdolność YOLO do dokładnego ich rozróżnienia jest kluczowa. Architektura modelu umożliwia mu zrozumienie kontekstu w obrazie, co czyni go odpornym w złożonych środowiskach. Ta zdolność jest wynikiem jego unikalnego projektu sieci, który podczas przewidywania analizuje cały obraz, co pozwala uchwycić informacje kontekstowe, które mogłyby zostać pominięte, gdy skupiono by się na częściach obrazu.
Dane do wykrywania obiektów: Zbieranie i wykorzystanie
Sukces każdego modelu wykrywania obiektów, w tym tych opartych na frameworkach do głębokiego uczenia się, takich jak YOLO, w dużej mierze zależy od jakości i ilości danych użytych do szkolenia. Proces budowania modelu do wykrywania obiektów zaczyna się od zbierania danych, które obejmuje gromadzenie różnorodnego zestawu obrazów i ich adnotowanie etykietami oraz ramkami ograniczającymi. Zbieranie danych to kluczowy krok w szkoleniu modelu, ponieważ dostarcza on podstawy, na których model może się uczyć.
Dane do wykrywania obiektów muszą obejmować szeroki zakres scenariuszy i typów obiektów, aby zapewnić, że model będzie dobrze generalizował na nowe, niewidziane wcześniej obrazy. Obejmuje to uwzględnienie różnic w rozmiarze obiektów, warunkach oświetleniowych i tłach. Anotowane zbiory danych dostępne na platformach takich jak GitHub oferują cenne zasoby do szkolenia i benchmarkingu modeli wykrywania obiektów.
W podejściu do nauki wykrywania obiektów, model jest szkolony do wykrywania 'obiektu vs. brak obiektu’ oraz do klasyfikacji wykrytych obiektów. Szkolenie to obejmuje nie tylko rozpoznawanie obecności obiektu, ale także dokładne określenie jego lokalizacji w obrazie. Użycie zaawansowanych metod głębokiego uczenia się i dużych, anotowanych zbiorów danych znacznie zwiększyło dokładność i niezawodność modeli wykrywania obiektów, czyniąc je niezbędnymi narzędziami w różnych zastosowaniach wizji komputerowej (computer vision).
Wykrywanie a rozpoznawanie: Zrozumienie różnic
W dziedzinie wizji komputerowej (computer vision) kluczowe jest rozróżnienie między 'wykrywaniem a rozpoznawaniem’. Wykrywanie polega na lokalizowaniu obiektów w obrazie, zwykle za pomocą prostokątów ograniczających, podczas gdy rozpoznawanie zagłębia się głębiej, starając się zidentyfikować konkretną naturę lub klasę wykrytych obiektów. To rozróżnienie jest ważne przy dostosowywaniu systemów wizji komputerowej do konkretnych zastosowań. Na przykład, podczas gdy system wykrywania może być wystarczający do liczenia samochodów na drodze, system rozpoznawania byłby niezbędny do odróżnienia modeli samochodów.
Złożoność zadań rozpoznawania zwykle wymaga bardziej zaawansowanych modeli w porównaniu do zadań wykrywania. Rozpoznawanie często wiąże się nie tylko z identyfikacją obecności obiektu, ale także z klasyfikacją go do jednej z kilku możliwych kategorii. Ten proces wymaga bardziej subtelnej znajomości cech obiektu i jest kluczowy w scenariuszach, gdzie szczegółowa identyfikacja jest niezbędna, na przykład przy rozróżnianiu komórek łagodnych i złośliwych w obrazowaniu medycznym.
Podsumowanie i przyszłe trendy w wykrywaniu obiektów
Jak wynika z podsumowania, wykrywanie obiektów to szybko rozwijająca się dziedzina, w której ciągle pojawiają się nowe osiągnięcia. Przyszłe trendy prawdopodobnie będą skupiać się na poprawie dokładności, szybkości oraz zdolności do radzenia sobie z bardziej złożonymi scenami. Integracja sztucznej inteligencji z innymi technologiami, takimi jak rzeczywistość rozszerzona oraz Internet rzeczy (IoT), otwiera nowe horyzonty dla zastosowań wykrywania obiektów.
Ponadto, zapotrzebowanie na bardziej efektywne i mniej intensywne pod względem danych modele napędza badania nad metodami uczenia się z kilkoma przykładami oraz podejściami do uczenia nienadzorowanego. Te metody mają na celu skuteczne szkolenie modeli przy ograniczonej ilości danych, co stanowi jedno z głównych wyzwań w tej dziedzinie. W miarę postępu technologii możemy spodziewać się coraz bardziej innowacyjnych rozwiązań, które zwiększą możliwości i zastosowania wykrywania obiektów w różnych sektorach, od opieki zdrowotnej po samochody autonomiczne.
Ciągłe doskonalenie modeli i algorytmów w wykrywaniu obiektów niewątpliwie przyczyni się do stworzenia bardziej zaawansowanych i dokładnych systemów, umacniając jego znaczenie w dziedzinie wizji komputerowej (computer vision) i poza nią.
FAQ dotyczące wykrywania obiektów: Zrozumienie podstawowych pojęć
Zapoznaj się z podstawami wykrywania obiektów w naszej sekcji FAQ. Tutaj odpowiadamy na często zadawane pytania, wyjaśniając, jak działa wykrywanie obiektów, jego zastosowania oraz technologia, która za tym stoi. Niezależnie od tego, czy jesteś nowy w dziedzinie wizji komputerowej (computer vision) czy chcesz udoskonalić swoją wiedzę, te odpowiedzi dostarczają zwięzłych wglądów w ekscytujący świat wykrywania obiektów.
Czym jest wykrywanie obiektów?
Wykrywanie obiektów to rozwiązanie z zakresu wizji komputerowej (computer vision), które identyfikuje i lokalizuje obiekty w obrazie lub wideo. Nie tylko rozpoznaje obecność obiektów, ale także wskazuje ich pozycje za pomocą ram ograniczających. System przypisuje poziomy pewności do przewidywań, wskazując prawdopodobieństwo dokładności. Wykrywanie obiektów różni się od rozpoznawania obrazów, które przypisuje etykietę klasy do obrazu, oraz od segmentacji obrazu, która identyfikuje obiekty na poziomie pikseli.
Jak działa wykrywanie obiektów?
Wykrywanie obiektów zazwyczaj obejmuje dwa etapy: wykrywanie potencjalnych regionów obiektów (Region of Interest, czyli RoI) a następnie klasyfikowanie tych regionów. Podejścia oparte na uczeniu głębokim, szczególnie przy użyciu sieci neuronowych takich jak konwolucyjne sieci neuronowe (CNNs), są powszechne. Modele takie jak R-CNN, YOLO i SSD najpierw analizują obraz w celu znalezienia RoI, a następnie klasyfikują każdy RoI do kategorii obiektów, często wykorzystując cechy nauczone podczas treningu na zestawach danych takich jak COCO czy ImageNet.
Jakie są rodzaje modeli wykrywania obiektów?
Popularne modele wykrywania obiektów obejmują R-CNN i jego warianty (Fast R-CNN, Faster R-CNN i Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) i CenterNet. Modele te różnią się podejściem do identyfikowania RoI i ich klasyfikacji. Modele R-CNN używają propozycji regionów, podczas gdy YOLO i SSD przewidują ramki ograniczające bezpośrednio z obrazu, co poprawia szybkość i wydajność.
Jaka jest różnica między wykrywaniem obiektów a rozpoznawaniem obiektów?
Wykrywanie obiektów i rozpoznawanie obiektów to różne zadania. Wykrywanie obiektów polega na lokalizowaniu obiektów w obrazie i identyfikowaniu ich granic, zwykle za pomocą ram ograniczających. Rozpoznawanie obiektów idzie o krok dalej, nie tylko lokalizując, ale także klasyfikując obiekty do predefiniowanych kategorii, takich jak rozróżnianie między różnymi rodzajami zwierząt, pojazdów czy innych przedmiotów.
Jak szkolone są modele wykrywania obiektów?
Szkolenie modeli wykrywania obiektów polega na karmieniu sieci neuronowej oznaczonymi obrazami. Te obrazy są anotowane ramami ograniczającymi wokół obiektów oraz ich odpowiednimi etykietami klas. Sieć neuronowa uczy się rozpoznawać wzorce i cechy z tych obrazów treningowych. Skuteczność szkolenia zależy od różnorodności i wielkości zestawu danych, przy czym większe, bardziej zróżnicowane zestawy danych prowadzą do bardziej dokładnych i uogólnionych modeli. Modele często są szkolone przy użyciu frameworków takich jak TensorFlow czy PyTorch.
Jakie są zastosowania wykrywania obiektów?
Wykrywanie obiektów jest szeroko stosowane w różnych dziedzinach. W bezpieczeństwie i nadzorze pomaga w wykrywaniu twarzy i monitorowaniu działań. W handlu detalicznym pomaga w analizie zachowań klientów i zarządzaniu zapasami. W pojazdach autonomicznych jest kluczowe do identyfikacji przeszkód i bezpiecznej nawigacji. Wykrywanie obiektów znajduje także zastosowanie w opiece zdrowotnej do identyfikacji nieprawidłowości w obrazach medycznych oraz w rolnictwie do monitorowania upraw i szkodników.
Czym jest YOLO w wykrywaniu obiektów?
YOLO (You Only Look Once) to popularny model wykrywania obiektów znany ze swojej szybkości i wydajności. W przeciwieństwie do tradycyjnych modeli, które przetwarzają obraz na części, YOLO bada cały obraz za jednym razem, co czyni go znacznie szybszym. Sprawia to, że jest idealny do zastosowań w wykrywaniu obiektów w czasie rzeczywistym. YOLO ma kilka wersji, z YOLOv5 i YOLOv8 będącymi najnowszymi, oferującymi ulepszenia w dokładności i szybkości.
Jak dokładne są modele wykrywania obiektów?
Dokładność modeli wykrywania obiektów różni się w zależności od ich architektury i jakości danych treningowych. Modele takie jak YOLOv4 i YOLOv5 wykazują wysoką dokładność, często z wskaźnikami precyzji powyżej 90% w idealnych warunkach. Dokładność jest mierzona za pomocą metryk takich jak mAP (średnia średnia precyzja) i IoU (Intersection over Union). mAP dla najlepszych modeli na standardowych zestawach danych, takich jak MS COCO, może wynosić nawet 60-70%.
Jaka jest rola konwolucyjnych sieci neuronowych w wykrywaniu obiektów?
Konwolucyjne sieci neuronowe (CNNs) odgrywają kluczową rolę w wykrywaniu obiektów, głównie w ekstrakcji cech. Przetwarzają obrazy przez warstwy konwolucyjne, ucząc się i identyfikując kluczowe cechy, które są niezbędne do wykrywania obiektów. Modele takie jak R-CNN, Faster R-CNN i SSD wykorzystują CNNs ze względu na ich efektywność w obsłudze danych obrazowych, znacznie zwiększając dokładność i szybkość wykrywania obiektów.
Jak zacząć budować model wykrywania obiektów?
Aby zacząć budować model wykrywania obiektów, najpierw zdefiniuj obiekty, które chcesz wykryć. Zbierz i oznacz zestaw danych z obrazami zawierającymi te obiekty. Użyj narzędzi takich jak TensorFlow czy PyTorch do szkolenia modelu na tym zestawie danych. Zacznij od prostszej architektury, takiej jak SSD lub YOLO, dla łatwiejszej implementacji. Eksperymentuj z różnymi konfiguracjami i hiperparametrami, aby zoptymalizować wydajność swojego modelu.