
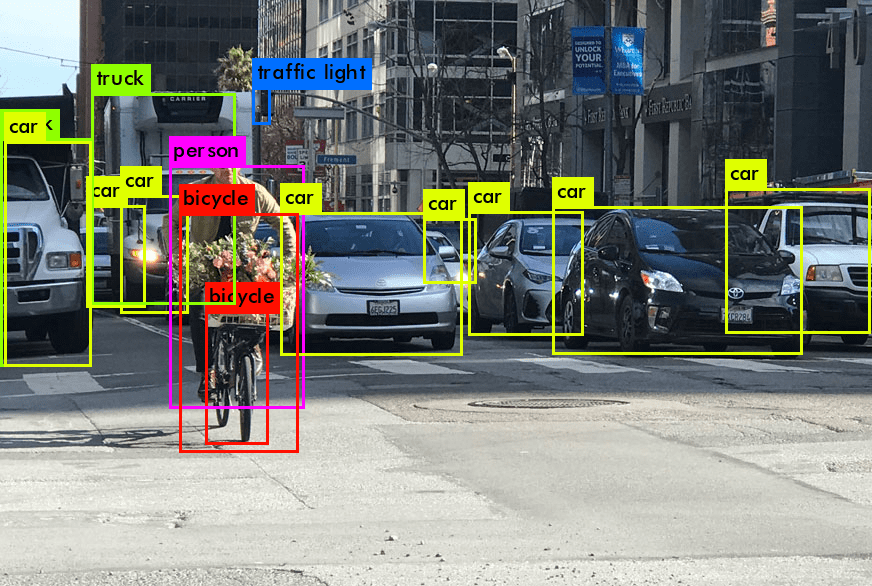
Wprowadzenie do wizji komputerowej (computer vision) i modelu YOLO
Wizja komputerowa, dziedzina sztucznej inteligencji, ma na celu umożliwienie maszynom interpretacji i zrozumienia świata wizualnego. Obejmuje przechwytywanie, przetwarzanie i analizowanie obrazów lub filmów w celu automatyzacji zadań, które może wykonać ludzki system wzrokowy. Ta szybko rozwijająca się dziedzina obejmuje różnorodne zastosowania, od rozpoznawania twarzy i śledzenia obiektów po bardziej zaawansowane działania, takie jak autonomiczna jazda. Rozwój wizji komputerowej w dużej mierze opiera się na dużych zbiorach danych, zaawansowanych algorytmach i potężnych zasobach obliczeniowych.
Przełom w tej dziedzinie nastąpił wraz z opracowaniem modelu YOLO (You Only Look Once). Zaprojektowany jako model detekcji obiektów najnowszej generacji, YOLO zrewolucjonizował podejście do wykrywania obiektów na obrazach. Tradycyjne modele detekcji często obejmowały dwuetapowy proces: najpierw identyfikację regionów zainteresowania, a następnie klasyfikację tych regionów. W przeciwieństwie do tego, YOLO wprowadziło innowację, przewidując zarówno klasyfikacje, jak i ramki ograniczające w jednym przejściu przez sieć neuronową, znacznie przyspieszając proces i poprawiając zdolności detekcji w czasie rzeczywistym.
Ten model detekcji obiektów przeszedł kilka iteracji, z każdą wersją wprowadzając nowe funkcje i ulepszenia. YOLOv8, najnowsza wersja od Ultralytics, buduje na sukcesie swoich poprzedników, takich jak YOLOv5. Wprowadza zaawansowane techniki uczenia maszynowego, aby poprawić dokładność i szybkość, co czyni go popularnym wyborem do zadań wizji komputerowej. Otwartość źródłowa modeli YOLO, takich jak repozytorium YOLOv8 na GitHub, przyczyniła się do ich szerokiego przyjęcia i ciągłego rozwoju.
Skuteczność YOLO w detekcji obiektów, segmentacji instancji i zadaniach klasyfikacyjnych uczyniła go podstawą w projektach wizji komputerowej. Uproszczając proces identyfikacji i kategoryzacji obiektów w obrazach, modele YOLO, takie jak YOLOv8, pomagają maszynom dokładniej i efektywniej rozumieć świat wizualny.
YOLOv8: Nowy standard w wizji komputerowej (computer vision)
YOLOv8 stanowi szczyt postępu w dziedzinie wizji komputerowej (computer vision), ustanawiając nowy standard w modelach wykrywania obiektów. Opracowany przez Ultralytics, ta wersja serii modeli YOLO przynosi znaczące postępy w stosunku do swojego poprzednika, YOLOv5, oraz wcześniejszych wersji YOLO. YOLOv8 jest wyposażony w szereg nowych funkcji, które zwiększają jego zdolności detekcyjne, czyniąc go dokładniejszym i wydajniejszym niż kiedykolwiek wcześniej.
Jednym z istotnych postępów w YOLOv8 jest przyjęcie detekcji bez kotwic (anchor-free detection). To nowe podejście odbiega od tradycyjnego polegania na kotwicach (anchor boxes), które były podstawą we wcześniejszych modelach YOLO. Detekcja bez kotwic upraszcza architekturę modelu i poprawia jego zdolność do dokładniejszego przewidywania lokalizacji obiektów. To ulepszenie jest szczególnie korzystne w scenariuszach, gdzie zbiór danych zawiera obiekty o różnych kształtach i rozmiarach.
Model YOLOv8 również wyróżnia się w zadaniach segmentacji, które są kluczowym aspektem wizji komputerowej (computer vision). Niezależnie od tego, czy chodzi o wykrywanie obiektów, segmentację instancji czy bardziej ogólne modele segmentacji, YOLOv8, a szczególnie model YOLOv8 Nano, wykazuje niezwykłą biegłość. Jego zdolność do precyzyjnego segmentowania i klasyfikowania różnych części obrazu sprawia, że jest wysoce skuteczny w różnorodnych zastosowaniach, od obrazowania medycznego po nawigację pojazdów autonomicznych.
Kolejnym kluczowym aspektem YOLOv8 jest jego pakiet Python, który ułatwia łatwą integrację i użytkowanie w projektach opartych na Pythonie. Ta dostępność jest kluczowa, zwłaszcza biorąc pod uwagę popularność Pythona w społecznościach nauki o danych i uczenia maszynowego. Deweloperzy mogą trenować model YOLOv8 na niestandardowym zbiorze danych za pomocą PyTorch, czołowego frameworka do głębokiego uczenia. Ta elastyczność pozwala na dostosowane rozwiązania do konkretnych wyzwań wizji komputerowej (computer vision).
Wydajność YOLOv8 jest dodatkowo zwiększana przez najnowocześniejsze metryki wydajności modelu. Te metryki pokazują zdolność modelu do wykrywania obiektów z dużą dokładnością i szybkością, co jest kluczowe w aplikacjach w czasie rzeczywistym. Ponadto, jako model open-source dostępny na GitHubie, YOLOv8 korzysta z ciągłych ulepszeń i wkładów od globalnej społeczności programistów.
Podsumowując, YOLOv8 ustanawia nowy punkt odniesienia w dziedzinie wizji komputerowej (computer vision). Jego postępy w wykrywaniu obiektów, segmentacji i ogólnej wydajności modelu czynią go nieocenionym narzędziem dla deweloperów i badaczy dążących do przesuwania granic możliwości w interpretacji wizualnej napędzanej przez AI.
Architektura YOLOv8: Kręgosłup nowych postępów w wizji komputerowej (computer vision)
Architektura YOLOv8 stanowi znaczący skok w dziedzinie wizji komputerowej (computer vision), ustanawiając nowy, najwyższy standard. Jako najnowsza wersja YOLO, YOLOv8 wprowadza kilka ulepszeń w porównaniu do swoich poprzedników, takich jak YOLOv5 i wcześniejsze wersje YOLO. Zrozumienie architektury YOLOv8 jest kluczowe dla osób, które chcą trenować model do specjalistycznych zadań detekcji obiektów.
Jedną z kluczowych cech YOLOv8 jest jego głowica detekcyjna bez kotwic, co stanowi odejście od tradycyjnego podejścia z użyciem pudełek kotwicowych stosowanych w wcześniejszych wersjach YOLO. Zmiana ta upraszcza model, jednocześnie utrzymując, a w wielu przypadkach zwiększając, dokładność wykrywania obiektów. YOLOv8 obsługuje szeroki zakres zastosowań, od detekcji obiektów w czasie rzeczywistym po segmentację obrazu.
Model YOLOv8 jest zaprojektowany z myślą o efektywności i wydajności. Model YOLOv8 open source może być trenowany na różnych zestawach danych, w tym na powszechnie używanym zestawie danych COCO. Ta elastyczność pozwala użytkownikom dostosować model do konkretnych potrzeb, czy to dla ogólnej detekcji obiektów, czy dla specjalistycznych zadań, takich jak estymacja pozy.
Architektura YOLOv8 jest zoptymalizowana zarówno pod kątem szybkości, jak i dokładności, co jest kluczowym czynnikiem w aplikacjach czasu rzeczywistego. Projekt modelu obejmuje również ulepszenia w segmentacji obrazu, czyniąc go kompleksowym modelem detekcji i segmentacji obrazu. Seria Ultralytics YOLO, a szczególnie YOLOv8, zawsze była na czele postępu w modelach wizji komputerowej (computer vision), i YOLOv8 kontynuuje tę tradycję.
Dla tych, którzy chcą zacząć pracę z YOLOv8, repozytorium Ultralytics oferuje bogate zasoby. Repozytorium, dostępne na GitHubie, oferuje szczegółowe instrukcje, jak trenować model YOLOv8, w tym konfigurację środowiska treningowego i ładowanie wag modelu.
Model detekcji obiektów YOLOv8: Rewolucjonizujący detekcję i segmentację
Model detekcji obiektów YOLOv8 to najnowszy dodatek do serii YOLO, stworzony przez Josepha Redmona i Ali Farhadi. Znajduje się na czele postępów w dziedzinie wizji komputerowej (computer vision), uosabiając nowy stan najwyższej klasy zarówno w detekcji obiektów, jak i segmentacji obrazu. Możliwości YOLOv8 wykraczają poza zwykłą detekcję obiektów; model ten doskonale radzi sobie również w zadaniach takich jak segmentacja instancji i detekcja w czasie rzeczywistym, co czyni go wszechstronnym narzędziem dla różnorodnych zastosowań.
YOLOv8 stosuje innowacyjne podejście do detekcji, integrując funkcje, które czynią go wysoce dokładnym detektorem obiektów. Model zawiera głowicę detekcyjną bez kotwic, co usprawnia proces detekcji i zwiększa dokładność. Jest to znacząca zmiana w porównaniu do metody pudełek kotwicowych używanych w poprzednich wersjach YOLO.
Szkolenie modelu YOLOv8 jest prostym procesem, szczególnie z zasobami dostarczonymi w repozytorium GitHub YOLOv8. Repozytorium zawiera szczegółowe instrukcje, jak szkolić model przy użyciu niestandardowego zestawu danych, co umożliwia użytkownikom dostosowanie modelu do ich specyficznych potrzeb. Na przykład, szkolenie modeli na zestawie danych przez 100 epok może znacząco poprawić wydajność modelu, co potwierdzają oceny na zestawie walidacyjnym.
Ponadto, architektura YOLOv8 jest zaprojektowana tak, aby skutecznie wspierać zadania detekcji obiektów i segmentacji obrazu. Ta wszechstronność jest widoczna w jego zastosowaniu w różnych dziedzinach, od monitoringu po autonomiczną jazdę. YOLOv8 wprowadza nowe funkcje, które zwiększają jego efektywność, takie jak ulepszenia w ostatnich dziesięciu epokach szkoleniowych, które optymalizują uczenie się modelu i jego dokładność.
Podsumowując, YOLOv8 stanowi znaczący postęp w serii YOLO i szerszym polu wizji komputerowej (computer vision). Jego najnowocześniejsza architektura i funkcje czynią go idealnym wyborem dla deweloperów i badaczy, którzy chcą wdrażać zaawansowane modele detekcji i segmentacji w swoich projektach. Repozytorium Ultralytics to doskonały punkt wyjścia dla każdego, kto jest zainteresowany eksploracją możliwości YOLOv8 i wdrażaniem go w realnych scenariuszach.
Format adnotacji YOLOv8: Przygotowanie danych do treningu
Przygotowanie danych do treningu to kluczowy etap w rozwoju każdego modelu wizji komputerowej (computer vision), a YOLOv8 nie jest wyjątkiem. Format adnotacji YOLOv8 odgrywa kluczową rolę w tym procesie, ponieważ bezpośrednio wpływa na naukę i dokładność modelu. Prawidłowa adnotacja zapewnia, że model może poprawnie identyfikować i uczyć się na podstawie różnych elementów w zbiorze danych, co jest kluczowe dla skutecznej detekcji obiektów i segmentacji obrazu.
Format adnotacji YOLOv8 jest unikalny i różni się od innych formatów używanych w wizji komputerowej (computer vision). Wymaga dokładnego szczegółowego opisu obiektów na obrazach, zazwyczaj za pomocą prostokątów ograniczających i etykiet. Każdy obiekt na obrazie jest oznaczony prostokątem ograniczającym, a te prostokąty są etykietowane klasami, które model musi zidentyfikować. Ten format jest kluczowy dla treningu modelu YOLOv8, ponieważ pomaga modelowi zrozumieć lokalizację i kategorię każdego obiektu na obrazie.
Przygotowanie zbioru danych dla YOLOv8 obejmuje adnotowanie dużej liczby obrazów, co może być procesem czasochłonnym. Jednak wysiłek ten jest niezbędny do osiągnięcia wysokiej wydajności modelu. Jakość i dokładność adnotacji bezpośrednio wpływają na zdolność modelu do nauki i dokonywania precyzyjnych prognoz.
Dla tych, którzy chcą trenować model YOLOv8, zrozumienie i implementacja odpowiedniego formatu adnotacji jest kluczowe. Proces ten zwykle obejmuje użycie specjalistycznych narzędzi do adnotacji, które pozwalają użytkownikom rysować prostokąty ograniczające i odpowiednio je etykietować. Anotowany zbiór danych jest następnie używany do trenowania modelu, ucząc go rozpoznawania i kategoryzowania obiektów na podstawie dostarczonych etykiet i współrzędnych prostokątów ograniczających.
Szkolenie YOLOv8: Przewodnik krok po kroku
Szkolenie YOLOv8 to proces, który wymaga starannego przygotowania i wykonania, aby osiągnąć optymalną wydajność modelu. Proces szkolenia obejmuje kilka kroków, od konfiguracji środowiska po dostosowywanie modelu do konkretnego zestawu danych. Oto przewodnik krok po kroku, jak przeprowadzić szkolenie YOLOv8:
- Konfiguracja środowiska: Pierwszym krokiem jest przygotowanie środowiska treningowego. Obejmuje to instalację niezbędnego oprogramowania i zależności. YOLOv8, będąc modelem opartym na Pythonie, wymaga środowiska Pythona z bibliotekami takimi jak PyTorch.
- Przygotowanie danych: Następnie przygotuj swój zestaw danych zgodnie z formatem adnotacji YOLOv8. Obejmuje to adnotowanie obrazów za pomocą prostokątów ograniczających i etykiet, aby zdefiniować obiekty, które model musi nauczyć się wykrywać.
- Konfiguracja modelu: Przed rozpoczęciem treningu skonfiguruj model YOLOv8 zgodnie z Twoimi wymaganiami. Może to obejmować dostosowanie parametrów, takich jak szybkość uczenia się, rozmiar partii i liczba epok.
- Trening modelu: Mając przygotowane środowisko i dane, możesz rozpocząć proces treningu. Polega to na dostarczeniu zestawu danych z adnotacjami do modelu i pozwoleniu mu uczyć się na podstawie tych danych. Model iteracyjnie dostosowuje swoje wagi i błędy, aby zminimalizować błędy w wykrywaniu.
- Ocena wydajności: Po treningu oceniaj wydajność modelu za pomocą metryk takich jak precyzja, czułość i średnia precyzja średnia (mAP). Pomaga to zrozumieć, jak dobrze model może wykrywać i klasyfikować obiekty na obrazach.
- Dostrajanie: Na podstawie oceny możesz potrzebować dostrajania modelu. Może to obejmować ponowne szkolenie modelu z dostosowanymi parametrami lub dostarczenie mu dodatkowych danych treningowych.
- Wdrożenie: Gdy model jest przeszkolony i dostrojony, jest gotowy do wdrożenia w rzeczywistych aplikacjach.
Szkolenie modelu YOLOv8 wymaga dbałości o szczegóły i głębokiego zrozumienia działania modelu. Jednak wysiłek się opłaca, dając solidny, dokładny i wydajny model wykrywania obiektów odpowiedni do różnych zastosowań w wizji komputerowej (computer vision).
Wdrażanie YOLOv8 w rzeczywistych zastosowaniach
Wdrażanie YOLOv8 w rzeczywistych zastosowaniach to kluczowy krok w wykorzystaniu jego zaawansowanych możliwości wykrywania obiektów. Skuteczne wdrożenie przekłada teoretyczną biegłość modelu na praktyczne, działające rozwiązania w różnych branżach. Oto kompleksowy przewodnik po wdrażaniu YOLOv8:
- Wybór odpowiedniej platformy: Pierwszym krokiem jest decyzja, gdzie model YOLOv8 zostanie wdrożony. Może to obejmować serwery oparte na chmurze dla aplikacji na dużą skalę lub urządzenia krawędziowe do przetwarzania w czasie rzeczywistym na miejscu, takie jak rozwiązanie platformy wizji komputerowej (computer vision) visionplatform.ai.
- Optymalizacja modelu: W zależności od platformy wdrożeniowej, może być konieczne zoptymalizowanie modelu YOLOv8 pod kątem wydajności. Techniki takie jak kwantyzacja modelu lub przycinanie mogą być użyte do zmniejszenia rozmiaru modelu bez znaczącego wpływu na dokładność, co czyni go odpowiednim dla urządzeń o ograniczonych zasobach obliczeniowych.
- Integracja z istniejącymi systemami: W wielu przypadkach model YOLOv8 będzie musiał zostać zintegrowany z istniejącymi systemami oprogramowania lub sprzętu. Wymaga to dogłębnego zrozumienia tych systemów oraz zdolności do interfejsowania modelu YOLOv8 za pomocą odpowiednich API lub frameworków oprogramowania.
- Testowanie i walidacja: Przed pełnoskalowym wdrożeniem kluczowe jest przetestowanie modelu w kontrolowanym środowisku, aby upewnić się, że działa zgodnie z oczekiwaniami. Obejmuje to walidację dokładności, szybkości i niezawodności modelu w różnych warunkach.
- Wdrożenie i monitorowanie: Po przetestowaniu model należy wdrożyć na wybranej platformie. Ciągłe monitorowanie jest niezbędne, aby zapewnić poprawne i efektywne działanie modelu w czasie. Pomaga to również w identyfikacji i korygowaniu wszelkich problemów, które mogą pojawić się po wdrożeniu.
- Aktualizacje i konserwacja: Podobnie jak każde oprogramowanie, wdrożony model YOLOv8 może wymagać okresowych aktualizacji w celu wprowadzenia ulepszeń lub rozwiązania nowych wyzwań. Regularna konserwacja zapewnia skuteczność i bezpieczeństwo modelu.
Skuteczne wdrożenie YOLOv8 wymaga strategicznego podejścia, uwzględniającego czynniki takie jak środowisko operacyjne, ograniczenia obliczeniowe i wyzwania integracyjne. Kiedy jest wykonane prawidłowo, YOLOv8 może znacząco zwiększyć możliwości systemów w sektorach takich jak bezpieczeństwo, opieka zdrowotna, transport i handel detaliczny.
YOLOv8 vs YOLOv5: Porównanie modeli wykrywania obiektów
Porównanie YOLOv8 i YOLOv5 jest kluczowe, aby zrozumieć postępy w modelach wykrywania obiektów i zdecydować, który model jest bardziej odpowiedni dla konkretnej aplikacji. Oba modele są najnowocześniejsze pod względem swoich możliwości, ale mają różne cechy i wskaźniki wydajności.
- Architektura modelu: YOLOv8 wprowadza kilka ulepszeń architektonicznych w porównaniu do YOLOv5. Obejmują one ulepszenia w warstwach detekcji oraz integrację nowych technologii, takich jak detekcja bez kotwic, co poprawia dokładność i efektywność modelu.
- Dokładność i szybkość: YOLOv8 wykazał poprawę dokładności i szybkości detekcji w porównaniu do YOLOv5. Jest to szczególnie widoczne w trudnych scenariuszach detekcji, obejmujących małe lub nakładające się obiekty.
- Szkolenie i elastyczność: Oba modele oferują elastyczność w szkoleniu, pozwalając użytkownikom na trenowanie na niestandardowych zestawach danych. Jednak YOLOv8 oferuje bardziej zaawansowane funkcje do dostosowywania modelu, co może prowadzić do lepszej wydajności w konkretnych zadaniach.
- Przydatność aplikacji: Chociaż YOLOv5 pozostaje potężną opcją dla wielu aplikacji, zaawansowania YOLOv8 sprawiają, że jest on lepiej dostosowany do scenariuszy, w których kluczowe są maksymalna dokładność i szybkość.
- Wspólnota i wsparcie: Oba modele korzystają z silnego wsparcia społeczności i są szeroko stosowane, co zapewnia ciągłe doskonalenie i obszerne zasoby dla programistów.
Podsumowując, chociaż YOLOv5 pozostaje solidnym i wydajnym modelem do wykrywania obiektów, YOLOv8 reprezentuje najnowsze postępy w tej dziedzinie, oferując poprawioną dokładność i wydajność. Wybór między dwoma zależy od konkretnych wymagań aplikacji, w tym czynników takich jak zasoby obliczeniowe, złożoność zadania detekcji i potrzeba przetwarzania w czasie rzeczywistym.
Eksploracja wariantów modeli YOLO
Seria YOLO (You Only Look Once) obejmuje szereg modeli dostosowanych do różnych zastosowań w detekcji obiektów, różniących się rozmiarem, szybkością i dokładnością. Od lekkiego modelu YOLOv8n, zaprojektowanego dla urządzeń krawędziowych, po bardzo dokładny YOLOv8x, odpowiedni do dogłębnych badań, te warianty są dostosowane do różnorodnych środowisk obliczeniowych i wymagań aplikacji. Ta eksploracja dostarcza przeglądu różnych typów modeli YOLO, podkreślając ich unikalne cechy i optymalne przypadki użycia.
| Atrybut / Model | YOLOv8n (Nano) | YOLOv8s (Mały) | YOLOv8m (Średni) | YOLOv8l (Duży) | YOLOv8x (Bardzo Duży) | |
|---|---|---|---|---|---|---|
| Rozmiar | Bardzo mały | Mały | Średni | Duży | Bardzo duży | |
| Szybkość | Bardzo szybki | Szybki | Umiarkowany | Wolny | Bardzo wolny | |
| Dokładność | Niższa | Umiarkowana | Wysoka | Bardzo wysoka | Najwyższa | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Rozdzielczość | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
Porównanie Yolo z poprzednimi modelami takimi jak YOLOv5, YOLOv6, YOLOv7 i YOLOv8 pokazuje, że YOLOv8 jest zarówno lepszy, jak i szybszy od jego poprzednich wersji.
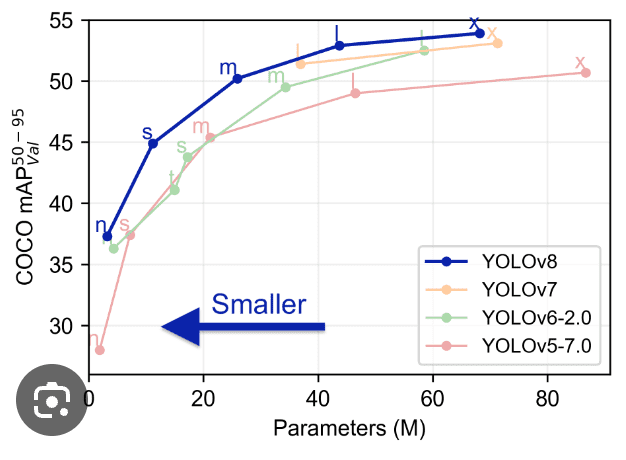
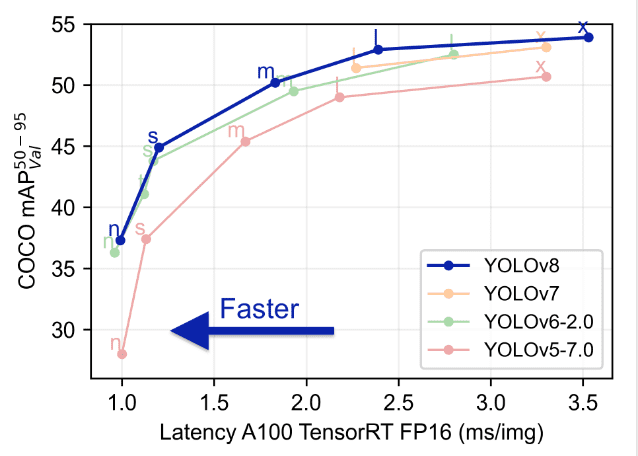
Zaawansowane funkcje w YOLOv8: Poprawa wydajności modelu
Wydajność modelu YOLOv8 wyróżnia się w dziedzinie wizji komputerowej (computer vision), dzięki zestawowi zaawansowanych funkcji, które zwiększają jego możliwości. Te funkcje znacząco przyczyniają się do statusu YOLOv8 jako modelu najnowszej generacji do zadań detekcji i segmentacji obiektów. Dogłębna analiza tych funkcji ujawnia, dlaczego YOLOv8 jest pierwszym wyborem dla deweloperów i badaczy:
- Detekcja bez kotwic: YOLOv8 odchodzi od tradycyjnych pudełek kotwic na rzecz systemu detekcji bez kotwic. Uproszcza to architekturę modelu, w tym model YOLOv8 Nano, i poprawia jego zdolność do dokładnego przewidywania lokalizacji obiektów, szczególnie dla obrazów z różnorodnymi kształtami i rozmiarami obiektów.
- Ulepszone warstwy konwolucyjne: YOLOv8 wprowadza zmiany w swoich blokach konwolucyjnych, zastępując poprzednie konwolucje
6x6na3x3. Ta zmiana zwiększa zdolność modelu do ekstrakcji i nauki szczegółowych cech z obrazów, poprawiając jego ogólną dokładność detekcji. - Mozaikowe powiększanie danych: Charakterystyczną cechą YOLOv8 jest implementacja mozaikowego powiększania danych podczas szkolenia. Ta technika łączy cztery różne obrazy, zwiększając zdolność modelu do wykrywania obiektów w różnych kontekstach i tłach. Jednak YOLOv8 strategicznie wyłącza to powiększanie w ostatnich dziesięciu epokach treningowych, aby zoptymalizować wydajność.
- Integracja z PyTorch: Jako pakiet Pythona, YOLOv8 korzysta z płynnej integracji z PyTorch, czołowym frameworkiem w dziedzinie uczenia maszynowego. Integracja ta upraszcza proces szkolenia i wdrażania modelu, szczególnie przy pracy z niestandardowymi zestawami danych.
- Detekcja obiektów wieloskalowa: Architektura YOLOv8 jest zaprojektowana do detekcji obiektów wieloskalowych. Ta funkcja pozwala modelowi na dokładne wykrywanie obiektów o różnych rozmiarach w obrazie, co czyni go wszechstronnym w różnych scenariuszach zastosowań.
- Możliwości przetwarzania w czasie rzeczywistym: Jedną z najważniejszych zalet YOLOv8 jest jego zdolność do wykrywania obiektów w czasie rzeczywistym. Ta funkcja jest kluczowa dla aplikacji wymagających natychmiastowej analizy i reakcji, takich jak autonomiczna jazda i nadzór w czasie rzeczywistym.
Te zaawansowane funkcje podkreślają zdolności YOLOv8 jako potężnego narzędzia w dziedzinie wizji komputerowej (computer vision). Jego połączenie dokładności, szybkości i elastyczności czyni go doskonałym wyborem dla szerokiego spektrum zastosowań w detekcji i segmentacji obiektów.
Rozpoczęcie pracy z YOLOv8: Od konfiguracji do wdrożenia
Rozpoczęcie pracy z YOLOv8, zwłaszcza dla osób nowych w dziedzinie wizji komputerowej (computer vision), może wydawać się zniechęcające. Jednakże, z odpowiednim przewodnikiem, konfiguracja i wdrożenie YOLOv8 może być prostym procesem. Oto krok po kroku jak zacząć pracę z YOLOv8:
- Zrozumienie podstaw: Zanim zagłębisz się w YOLOv8, kluczowe jest posiadanie podstawowej wiedzy na temat koncepcji wizji komputerowej (computer vision) oraz zasad działania modeli wykrywania obiektów. Ta podstawowa wiedza pomoże w zrozumieniu działania YOLOv8.
- Konfiguracja środowiska: Pierwszym technicznym krokiem jest przygotowanie środowiska programistycznego. Obejmuje to instalację Pythona, PyTorch i innych niezbędnych bibliotek. Dokumentacja YOLOv8 zawiera szczegółowe wskazówki dotyczące procesu konfiguracji.
- Dostęp do zasobów YOLOv8: Repozytorium YOLOv8 na GitHubie jest cennym zasobem. Zawiera kod modelu, wstępnie wytrenowane wagi oraz obszerną dokumentację. Zapoznanie się z tymi zasobami jest kluczowe dla pomyślnego wdrożenia.
- Trening modelu: Aby przeszkolić YOLOv8, potrzebujesz zestawu danych. Dla początkujących zaleca się użycie standardowego zestawu danych, takiego jak COCO. Proces szkolenia obejmuje dostosowanie modelu do konkretnego zestawu danych, aby zoptymalizować jego wydajność dla twojej aplikacji.
- Ocena modelu: Po przeszkoleniu należy ocenić wydajność modelu, używając standardowych metryk takich jak precyzja, czułość i średnia precyzja średnia (mAP). Ten krok jest kluczowy, aby upewnić się, że model dokładnie wykrywa obiekty.
- Wdrożenie: Posiadając przeszkolony i przetestowany model, tak jak model YOLOv8 Nano, następnym krokiem jest wdrożenie. Może to być na serwerze dla aplikacji internetowych lub na urządzeniu krawędziowym do przetwarzania w czasie rzeczywistym za pomocą visionplatform.ai.
- Ciągła nauka: Dziedzina wizji komputerowej (computer vision) szybko się rozwija. Utrzymywanie się na bieżąco z najnowszymi osiągnięciami i ciągła nauka są kluczowe do skutecznego wykorzystania YOLOv8, co można efektywnie robić za pomocą platformy wizji komputerowej (computer vision platform).
Rozpoczęcie pracy z YOLOv8 wiąże się z połączeniem teoretycznego zrozumienia i praktycznego zastosowania. Postępując zgodnie z tymi krokami, można skutecznie wdrożyć i wykorzystać YOLOv8 w różnych zadaniach wizji komputerowej (computer vision), wykorzystując jego pełny potencjał w wykrywaniu obiektów i segmentacji obrazu.
Przyszłość wizji komputerowej (computer vision): Co nowego w YOLOv8 i później
Przyszłość wizji komputerowej (computer vision) jest niezwykle obiecująca, a YOLOv8 prowadzi jako najnowszy i najbardziej zaawansowany model w serii YOLO. Wprowadzenie YOLOv8 stanowi znaczący kamień milowy w ciągłej ewolucji technologii wizji komputerowej (computer vision), oferując bezprecedensową dokładność i wydajność w zadaniach detekcji obiektów. Oto co nowego w YOLOv8 i implikacje dla przyszłości wizji komputerowej (computer vision):
- Postępy technologiczne: YOLOv8 wprowadził kilka ulepszeń technologicznych w porównaniu do swoich poprzedników. Obejmują one bardziej wydajne sieci konwolucyjne, detekcję bez kotwic oraz ulepszone algorytmy do detekcji obiektów w czasie rzeczywistym.
- Zwiększona dostępność i zastosowanie: Dzięki YOLOv8 dziedzina wizji komputerowej (computer vision) staje się bardziej dostępna dla szerszego grona użytkowników, w tym tych bez rozległej wiedzy programistycznej. Demokratyzacja technologii sprzyja innowacjom i zachęca do różnorodnych zastosowań w różnych sektorach.
- Integracja z nowymi technologiami: Kompatybilność YOLOv8 z zaawansowanymi ramami uczenia maszynowego oraz jego zdolność do integracji z innymi nowoczesnymi technologiami, takimi jak rzeczywistość rozszerzona i robotyka, sygnalizuje przyszłość, w której rozwiązania wizji komputerowej (computer vision) są coraz bardziej wszechstronne i potężne.
- Ulepszone metryki wydajności: YOLOv8 ustawił nowe standardy wydajności modelu, szczególnie pod względem dokładności i szybkości przetwarzania. Ta poprawa jest kluczowa dla aplikacji wymagających analizy w czasie rzeczywistym, takich jak autonomiczne pojazdy i technologie inteligentnych miast.
- Prognozy na przyszłe rozwój: Patrząc w przyszłość, możemy spodziewać się dalszych postępów w modelach wizji komputerowej (computer vision), z jeszcze większą dokładnością, szybkością i adaptacyjnością. Integracja AI z wizją komputerową (computer vision) prawdopodobnie będzie nadal ewoluować, prowadząc do bardziej zaawansowanych i autonomicznych systemów.
Ciągły rozwój YOLOv8 i podobnych modeli jest świadectwem dynamicznej natury dziedziny wizji komputerowej (computer vision). W miarę postępu technologicznego możemy spodziewać się coraz to nowszych przełomowych innowacji, które zdefiniują granice możliwości systemów wizji komputerowej (computer vision).
Podsumowanie: Wpływ YOLOv8 na wizję komputerową (computer vision) i AI
Podsumowując, YOLOv8 miało znaczący wpływ na dziedzinę wizji komputerowej (computer vision) i AI. Jego zaawansowane funkcje i możliwości stanowią znaczący skok naprzód w technologii wykrywania obiektów. Implikacje zaawansowań YOLOv8 wykraczają poza sferę techniczną, wpływając na różne branże i zastosowania:
- Postępy w wykrywaniu obiektów: YOLOv8 ustawiło nowy standard w wykrywaniu obiektów dzięki poprawionej dokładności, szybkości i efektywności. Ma to implikacje dla szerokiego zakresu zastosowań, od bezpieczeństwa i nadzoru po opiekę zdrowotną, produkcję, logistykę i monitoring środowiskowy.
- Demokratyzacja technologii AI: Poprzez uczynienie zaawansowanej technologii wizji komputerowej (computer vision) takiej jak repozytorium YOLOv8 bardziej dostępną i przyjazną dla użytkownika, YOLOv8 otworzyło drzwi dla szerszego grona użytkowników i programistów do innowacji i tworzenia rozwiązań opartych na AI.
- Ulepszone zastosowania w rzeczywistym świecie: Praktyczne zastosowania YOLOv8 w scenariuszach rzeczywistych są ogromne. Jego zdolność do dostarczania dokładnych, w czasie rzeczywistym danych o wykrywaniu obiektów czyni go nieocenionym narzędziem w takich obszarach jak autonomiczna jazda, automatyzacja przemysłowa i inicjatywy inteligentnych miast.
- Inspiracja dla przyszłych innowacji: Sukces YOLOv8 służy jako inspiracja dla przyszłych rozwojów w dziedzinie wizji komputerowej (computer vision) i AI. Przygotowuje grunt pod dalsze badania i innowacje, przesuwając granice tego, co te technologie mogą osiągnąć.
Podsumowując, YOLOv8 nie tylko posunęło do przodu aspekty techniczne wizji komputerowej (computer vision), ale także przyczyniło się do szerszej ewolucji AI. Jego wpływ jest widoczny w zwiększonych możliwościach systemów AI oraz nowych możliwościach, które otwiera dla innowacji i praktycznego zastosowania w różnych dziedzinach. W miarę kontynuowania eksploracji potencjału AI i wizji komputerowej (computer vision), YOLOv8 z pewnością zostanie zapamiętane jako kamień milowy na tej drodze technologicznego postępu.
Najczęściej zadawane pytania o YOLOv8
W miarę jak YOLOv8 kontynuuje rewolucjonizowanie dziedziny wizji komputerowej (computer vision), pojawia się wiele pytań dotyczących jego możliwości, zastosowań i aspektów technicznych. Ta sekcja FAQ ma na celu dostarczenie jasnych, zwięzłych odpowiedzi na niektóre z najczęściej zadawane pytania dotyczące YOLOv8. Niezależnie od tego, czy jesteś doświadczonym programistą, czy dopiero zaczynasz, te odpowiedzi pomogą pogłębić Twoje zrozumienie tego najnowocześniejszego modelu wykrywania obiektów.
Czym jest YOLOv8 i czym różni się od poprzednich wersji YOLO?
YOLOv8 to najnowsza iteracja w serii YOLO detektorów obiektów w czasie rzeczywistym, oferująca najwyższą wydajność pod względem dokładności i szybkości. Buduje na postępach poprzednich wersji, takich jak YOLOv5, z ulepszeniami obejmującymi zaawansowane architektury kręgosłupa i szyi, bezankorową rozdzieloną głowicę Ultralytics dla zwiększonej dokładności oraz optymalne równowagi między dokładnością a szybkością dla wykrywania obiektów w czasie rzeczywistym. Zapewnia również szereg wstępnie wytrenowanych modeli dla różnych zadań i wymagań dotyczących wydajności.
Jak detekcja bez kotwic w YOLOv8 poprawia wykrywanie obiektów?
YOLOv8 przyjmuje podejście do detekcji bez kotwic, bezpośrednio przewidując centra obiektów, co upraszcza architekturę modelu i poprawia dokładność. Metoda ta jest szczególnie skuteczna w wykrywaniu obiektów o różnych kształtach i rozmiarach. Poprzez zmniejszenie liczby przewidywanych pudełek, przyspiesza proces tłumienia maksymalnego, który jest kluczowy dla udoskonalenia wyników wykrywania, czyniąc YOLOv8 bardziej wydajnym i dokładnym w porównaniu do jego poprzedników, którzy używali pudełek kotwicowych.
Jakie są kluczowe innowacje i ulepszenia w architekturze YOLOv8?
YOLOv8 wprowadza kilka znaczących innowacji architektonicznych, w tym kręgosłup CSPNet dla efektywnego wydobywania cech oraz głowicę PANet, zwiększającą odporność na zasłonięcie obiektów i zmiany skali. Jego mozaikowe augmentacje danych podczas treningu eksponują model na szerszą gamę scenariuszy, zwiększając jego uogólnienie. YOLOv8 łączy również uczenie nadzorowane i nienadzorowane, przyczyniając się do jego zwiększonej wydajności wykrywania w zadaniach wykrywania obiektów i segmentacji instancji.
Aby rozpocząć korzystanie z YOLOv8, należy najpierw zainstalować pakiet Pythona YOLOv8. Następnie, w swoim skrypcie Pythona, zaimportuj moduł YOLOv8, utwórz instancję klasy YOLOv8 i załaduj wstępnie wytrenowane wagi. Następnie użyj metody detect, aby przeprowadzić wykrywanie obiektów na obrazie. Wyniki będą zawierać informacje o wykrytych obiektach, w tym ich klasy, wyniki ufności i współrzędne ramki ograniczającej.
Jakie są praktyczne zastosowania YOLOv8 w różnych branżach?
YOLOv8 ma wszechstronne zastosowania w różnych branżach dzięki swojej wysokiej szybkości i dokładności. W pojazdach autonomicznych pomaga w identyfikacji i klasyfikacji obiektów w czasie rzeczywistym. Jest używany w systemach monitoringu do wykrywania i rozpoznawania obiektów w czasie rzeczywistym. Detaliści wykorzystują YOLOv8 do analizy zachowań klientów i zarządzania zapasami. W opiece zdrowotnej pomaga w szczegółowej analizie obrazów medycznych, poprawiając diagnostykę i opiekę nad pacjentami.
Jak YOLOv8 radzi sobie na zestawie danych COCO i co to oznacza dla jego dokładności?
YOLOv8 wykazuje znakomitą wydajność na zestawie danych COCO, standardowym punkcie odniesienia dla modeli wykrywania obiektów. Jego średnia precyzja (mAP) różni się w zależności od rozmiaru modelu, przy czym największy model, YOLOv8x, osiąga najwyższy mAP. Podkreśla to znaczące ulepszenia w dokładności w porównaniu do poprzednich wersji YOLO. Wysoki mAP wskazuje na wyższą dokładność w wykrywaniu szerokiej gamy obiektów w różnych warunkach.
Jakie są ograniczenia YOLOv8 i czy są scenariusze, w których może nie być najlepszym wyborem?
Pomimo imponującej wydajności, YOLOv8 ma ograniczenia, szczególnie w obsłudze modeli trenowanych przy wysokich rozdzielczościach, takich jak 1280. Dla aplikacji wymagających wnioskowania o wysokiej rozdzielczości, YOLOv8 może nie być idealny. Jednak dla większości aplikacji przewyższa poprzednie modele pod względem dokładności i wydajności. Jego detekcje bez kotwic i ulepszona architektura sprawiają, że nadaje się do szerokiej gamy projektów wizji komputerowej (computer vision).
Czy mogę trenować YOLOv8 na niestandardowym zestawie danych i jakie są wskazówki do skutecznego treningu?
Tak, YOLOv8 można trenować na niestandardowych zestawach danych. Skuteczny trening obejmuje eksperymentowanie z technikami augmentacji danych, szczególnie mozaikową augmentacją, oraz optymalizację hiperparametrów, takich jak szybkość uczenia się, rozmiar wsadu i liczba epok. Regularna ocena i dostrojenie są kluczowe dla maksymalizacji wydajności. Wybór odpowiedniego zestawu danych i reżimu treningowego jest kluczowy, aby zapewnić, że model dobrze uogólnia się na nowe dane.
Jakie są kluczowe kroki do wdrożenia YOLOv8 w rzeczywistym środowisku? Wdrażanie
Wdrażanie YOLOv8 obejmuje optymalizację modelu dla docelowej platformy, integrację go z istniejącymi systemami i testowanie pod kątem dokładności i niezawodności. Ciągłe monitorowanie po wdrożeniu zapewnia efektywną pracę. Dla urządzeń krawędziowych optymalizacja modelu może obejmować kwantyzację lub przycinanie. Regularne aktualizacje i konserwacja są niezbędne, aby model był skuteczny i bezpieczny w różnych zastosowaniach.
Jak wygląda przyszłość YOLOv8 i jego zastosowań w wizji komputerowej (computer vision)?
Przyszłość YOLOv8 w wizji komputerowej (computer vision) wygląda obiecująco, z potencjałem na jeszcze większą dokładność, szybkość i wszechstronność. Jego ewoluująca technologia, w tym wykrywanie obiektów i segmentacja instancji, może znaleźć nowe zastosowania w obszarach takich jak obrazowanie medyczne, ochrona dzikiej przyrody i bardziej zaawansowane systemy autonomiczne. Ciągłe badania i wysiłki rozwojowe prawdopodobnie przesuną granice YOLOv8, jeszcze bardziej umacniając jego pozycję jako wiodącego modelu wykrywania obiektów.