
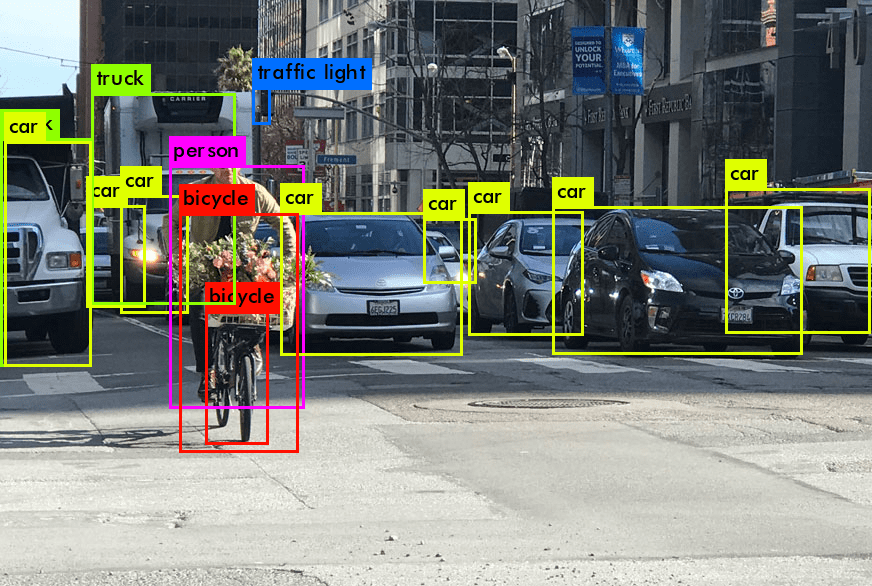
Introdução à Detecção de Objetos em Visão Computacional (computer vision)
Usando a detecção de objetos, uma tarefa fundamental da visão computacional (computer vision), revolucionou a maneira como as máquinas interpretam o mundo visual. Diferente da classificação de imagens, onde o objetivo é classificar uma imagem inteira, a detecção de objetos pode ser usada para identificar e localizar objetos dentro de uma imagem ou quadro de vídeo (que é o mesmo que uma imagem/foto). Esse processo inclui reconhecer o objeto específico, localizar o objeto e determinar sua posição por meio de uma caixa delimitadora. A detecção de objetos preenche a lacuna entre a classificação de imagens e tarefas mais complexas como a segmentação de imagens, onde o objetivo é rotular cada pixel da imagem como pertencente a um único objeto.
O surgimento do aprendizado profundo, particularmente o uso de Redes Neurais Convolucionais (CNNs), avançou significativamente a detecção de objetos. Essas redes neurais processam e analisam dados visuais de forma eficaz, tornando-as ideais para detectar objetos em uma imagem ou vídeo. Desenvolvimentos chave como YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) e redes baseadas em propostas de região como Mask R-CNN melhoraram ainda mais a precisão e eficiência dos sistemas de detecção de objetos. Esses modelos podem realizar detecções em tempo real, um fator crucial para aplicações como condução autônoma ou vigilância em tempo real.
Além disso, a integração de técnicas de aprendizado de máquina permitiu que os sistemas de detecção de objetos classificassem e segmentassem vários objetos em ambientes complexos. Essa habilidade é vital para uma variedade de aplicações, desde a detecção de pedestres em infraestruturas de cidades inteligentes até controle de qualidade na manufatura.
Compreendendo o Conjunto de Dados para Detecção de Objetos
A base de qualquer sistema de detecção de objetos bem-sucedido reside em seu conjunto de dados. Um conjunto de dados para detecção de objetos consiste em imagens ou vídeos anotados para treinar um detector. Essas anotações geralmente incluem caixas delimitadoras ao redor dos objetos e rótulos indicando a classe de cada objeto. A qualidade, diversidade e tamanho do conjunto de dados desempenham um papel crucial no desempenho dos modelos de detecção de objetos. Por exemplo, conjuntos de dados maiores com uma ampla variedade de objetos e cenários permitem que a rede neural aprenda características mais robustas e generalizáveis.
Conjuntos de dados como PASCAL VOC, MS COCO e ImageNet foram fundamentais no avanço da detecção de objetos. Eles fornecem uma vasta gama de imagens anotadas, desde objetos do dia a dia até cenários específicos, auxiliando no desenvolvimento de modelos de detecção versáteis e precisos. Esses conjuntos de dados não apenas facilitam o treinamento de modelos, mas também servem como benchmarks para avaliar e comparar o desempenho de vários algoritmos de detecção de objetos.
Treinar um modelo para detecção de objetos também envolve o uso de técnicas como transferência de aprendizado, onde um modelo pré-treinado em um grande conjunto de dados é ajustado com um conjunto de dados menor e específico. Essa abordagem é particularmente benéfica quando os dados disponíveis para detecção de objetos são limitados ou quando treinar um modelo do zero é computacionalmente caro.
Em resumo, o conjunto de dados é um componente crucial na detecção de objetos, influenciando diretamente a capacidade de um modelo de detectar objetos com precisão em diferentes contextos e ambientes. À medida que as tarefas e tecnologias relacionadas à visão computacional (computer vision) continuam a evoluir, a criação e o refinamento de conjuntos de dados permanecem um foco chave para pesquisadores e profissionais da área.
Explorando Modelos de Detecção de Objetos: Do Tradicional ao Deep Learning
A detecção de objetos é uma tarefa de visão computacional (computer vision) que evoluiu significativamente, especialmente com o avanço das tecnologias de deep learning. Originalmente, a detecção de objetos dependia de técnicas mais simples de visão computacional (computer vision) e algoritmos de aprendizado de máquina, onde os recursos para classificação de objetos eram criados manualmente e os modelos eram treinados para detectar objetos em imagens com base nesses recursos. A introdução do deep learning, particularmente as Redes Neurais Convolucionais profundas (CNNs), revolucionou esse campo. As CNNs aprendem automaticamente hierarquias de recursos a partir dos dados, permitindo uma detecção de objetos mais precisa e segmentação semântica. Essa transição para modelos de deep learning marcou uma melhoria significativa nas capacidades de detecção de objetos.
Os primeiros modelos de detecção de objetos baseados em CNN, como o R-CNN, empregavam um método de proposta de região para identificar locais potenciais de objetos em uma imagem e, em seguida, classificavam cada região. Sucessores como o Fast R-CNN e o Faster R-CNN melhoraram isso, aumentando a precisão da detecção e a velocidade de processamento. Desenvolvimentos posteriores levaram à introdução do Mask R-CNN, que estendeu as capacidades de seus predecessores adicionando um ramo para segmentação em nível de pixel, facilitando a localização e reconhecimento detalhados de objetos.
YOLO: Revolucionando a Detecção de Objetos em Tempo Real
No âmbito da detecção de objetos em tempo real, o modelo YOLO (You Only Look Once) representa um avanço significativo. O YOLO conceitua de forma única a detecção de objetos como um único problema de regressão, prevendo diretamente as coordenadas da caixa delimitadora e as probabilidades de classe a partir dos pixels da imagem em uma avaliação. Essa abordagem permite que o YOLO alcance velocidades de processamento excepcionais, essenciais para aplicações que exigem detecção em tempo real, como detecção de pedestres e rastreamento de veículos em cidades inteligentes.
A arquitetura do YOLO processa a imagem inteira durante o treinamento, permitindo que ele entenda informações contextuais sobre as classes de objetos e sua aparência. Isso contrasta com os métodos baseados em proposta de região, que podem ignorar alguns detalhes contextuais. A capacidade de processamento em tempo real do YOLO o torna indispensável em cenários que exigem detecção de objetos rápida e precisa. A família de modelos YOLO, incluindo versões avançadas como YOLOv3 e YOLOv4, tem ampliado os limites em termos de velocidade e precisão de detecção, estabelecendo o YOLO como um sistema de ponta em detecção de objetos em tempo real, avançando até o YOLOv8.
Análise de vídeo em tempo real para detecção de objetos no drone enquanto voa com visionplatform.ai e nosso computador de borda NVIDIA Jetson montado no drone. Transformamos QUALQUER câmera em uma câmera de IA.
Componentes-chave na Detecção de Objetos: Classificação e Caixa Delimitadora
A introdução à detecção de objetos revela dois aspectos fundamentais: classificação e a caixa delimitadora. Classificação refere-se a identificar a classe do objeto (por exemplo, pedestre, veículo) em uma imagem. É um passo crítico para distinguir entre diferentes categorias de objetos dentro de um sistema de detecção. A caixa delimitadora, por outro lado, envolve localizar o objeto dentro da imagem, geralmente representada por coordenadas que delineiam o objeto. Juntos, esses componentes formam a base da detecção e rastreamento de objetos.
A detecção de objetos pode ajudar modelos, como a família de modelos YOLO e o Detector Multibox de Disparo Único (SSD), a combinação de classificação e caixas delimitadoras garante a precisão da detecção. Esses modelos, frequentemente desenvolvidos e compartilhados em plataformas como o GitHub, utilizam abordagens baseadas em aprendizado profundo. Eles também podem ser usados sem uma linha de código em plataformas de visão (https://visionplatform.ai/computer-vision-platform/) (visão computacional) como visionplatform.ai. Eles são capazes de detectar múltiplos objetos em uma imagem e prever com precisão a localização de cada objeto com uma caixa delimitadora ao redor dele. Essa abordagem dupla é essencial em vários casos de uso de detecção de objetos, desde a detecção de rostos em sistemas de segurança até a detecção de anomalias em ambientes industriais.
O Papel do Aprendizado Profundo na Detecção de Objetos
Os métodos de aprendizado profundo revolucionaram a visão computacional (computer vision) e a detecção de objetos. Esses métodos, principalmente envolvendo redes neurais profundas como as CNNs, possibilitaram uma detecção de objetos mais precisa e segmentação semântica. O TensorFlow, uma biblioteca de código aberto popular para aprendizado de máquina e aprendizado profundo, oferece ferramentas robustas para treinar e implantar modelos de aprendizado profundo para detecção de objetos.
A eficácia do aprendizado profundo na detecção de objetos pode ser observada em sua aplicação a tarefas complexas como detecção de pedestres e detecção de texto. Esses modelos aprendem hierarquias de características para uma detecção de objetos precisa, melhorando significativamente em relação aos algoritmos tradicionais de aprendizado de máquina que requeriam características projetadas manualmente. Os modelos de detecção de objetos baseados em aprendizado profundo são tipicamente avaliados de acordo com sua precisão de detecção e velocidade, tornando-os ideais para aplicações em tempo real.
Com o avanço das técnicas de aprendizado profundo, os sistemas de detecção de objetos tornaram-se mais versáteis, capazes de lidar com uma ampla gama de tarefas de visão computacional (computer vision) incluindo rastreamento de objetos, detecção de pessoas e reconhecimento de imagens. Esse avanço levou ao desenvolvimento de algoritmos robustos de detecção de objetos que podem classificar e localizar objetos de maneira confiável, mesmo em ambientes desafiadores.
Segmentação e Reconhecimento de Objetos: Aprimorando a Detecção com Análise Detalhada
A introdução à detecção de objetos em visão computacional (computer vision) muitas vezes leva à exploração de tarefas relacionadas como segmentação e reconhecimento de objetos. Enquanto a detecção de objetos identifica e localiza objetos dentro de uma imagem, a segmentação avança um passo adiante dividindo a imagem em segmentos para simplificar sua análise ou alterar sua representação. O reconhecimento de objetos, por outro lado, envolve a identificação do objeto específico presente na imagem.
Técnicas baseadas em aprendizado profundo, especialmente redes neurais convolucionais profundas, avançaram significativamente nessas áreas. A segmentação, particularmente a segmentação semântica, é integral para entender o contexto no qual os objetos existem nas imagens. Isso é crucial em casos de uso como imagens médicas, onde a identificação precisa de tecidos ou anomalias é essencial. Algoritmos de detecção de objetos que incluem segmentação, como o Mask R-CNN, fornecem insights detalhados não apenas localizando a “caixa delimitadora ao redor” do objeto, mas também delineando a “forma exata do objeto”.
Processando a Imagem de Entrada: A Jornada pelos Sistemas de Detecção de Objetos
O processo de detecção de objetos começa com uma imagem de entrada, que passa por várias etapas dentro de uma rede de detecção. Inicialmente, a imagem é pré-processada para atender aos requisitos do modelo de detecção de objetos. Isso pode envolver redimensionamento, normalização e aumento. Após isso, a imagem é inserida em um modelo de aprendizado profundo, tipicamente um tipo de modelo como CNNs, para extração de características.
As características extraídas são então usadas para classificar objetos e prever sua localização. A detecção de objetos usada em cenários em tempo real, como detecção de pedestres ou rastreamento de veículos, exige que o modelo analise rapidamente a imagem de entrada e forneça “caixas delimitadoras previstas” precisas para cada “objeto presente”. É aqui que modelos como YOLO se destacam, oferecendo processamento rápido e eficiente adequado para aplicações em tempo real.
Treinar um modelo para tarefas tão complexas envolve uma quantidade substancial de dados para detecção de objetos. Esses dados, geralmente compostos por imagens diversas com objetos anotados, ajudam o modelo a aprender várias categorias de objetos e suas características. Frameworks populares de detecção de objetos como TensorFlow oferecem ferramentas e bibliotecas para construir, treinar e implantar esses modelos de forma eficiente. Todo o processo destaca a sinergia entre técnicas de processamento de imagem e visão computacional (computer vision), algoritmos de aprendizado de máquina e métodos de aprendizado profundo, culminando em um sistema robusto de detecção de objetos.
Casos de Uso da Detecção de Objetos em Diversas Indústrias
A detecção de objetos, impulsionada por modelos baseados em aprendizado profundo, encontrou aplicações em diversas indústrias, cada uma com requisitos e desafios únicos. Esses modelos são tipicamente avaliados de acordo com sua precisão, velocidade e capacidade de detectar múltiplos objetos em condições variadas. No setor de saúde, a detecção de objetos auxilia na identificação de anomalias em imagens médicas, contribuindo significativamente para o diagnóstico precoce e planejamento de tratamento. No varejo, desempenha um papel vital na análise de comportamento do cliente e na gestão de inventário.
Um caso de uso notável da detecção de objetos está na indústria automotiva, onde é crucial para o desenvolvimento de veículos autônomos. Aqui, a capacidade de detectar e diferenciar entre dois objetos, como pedestres e outros veículos, é primordial para a segurança. Sistemas de detecção de objetos, utilizando algoritmos avançados e redes neurais, permitem que esses veículos naveguem com segurança interpretando corretamente seus arredores.
TensorFlow em Detecção de Objetos: Aproveitando Modelos de Aprendizado Profundo
TensorFlow, uma plataforma de código aberto disponível em plataformas como GitHub, tornou-se sinônimo de construção e implantação de modelos de aprendizado profundo, especialmente na área de detecção de objetos. Sua biblioteca abrangente permite que desenvolvedores construam um modelo do zero ou usem modelos pré-treinados para detecção de objetos. A flexibilidade do TensorFlow no tratamento de vários mecanismos de proposta de objetos e seu processamento eficiente de grandes conjuntos de dados o tornam a escolha preferida de muitos desenvolvedores.
Na detecção de objetos, a abordagem de aprendizado é crítica. O TensorFlow facilita a implementação de algoritmos complexos que podem diferenciar tarefas de ‘deteção vs. classificação’, essenciais para cenários de detecção de objetos mais matizados. A plataforma suporta uma ampla gama de modelos, desde aqueles que requerem recursos computacionais intensivos até modelos leves adequados para dispositivos móveis. Essa adaptabilidade garante que os modelos baseados em TensorFlow possam ser implantados em vários ambientes, desde sistemas baseados em servidores até dispositivos de borda como o Jetson Nano Orin, Jetson NX Orin ou Jetson AGX Orin, expandindo o escopo e a acessibilidade da tecnologia de detecção de objetos.
Explorando o Modelo YOLO em Profundidade
O modelo YOLO (You Only Look Once), uma estrutura baseada em aprendizado profundo para detecção de objetos, representa uma mudança significativa na abordagem de aprendizado para detectar objetos. Diferentemente dos modelos tradicionais, onde o sistema primeiro propõe regiões potenciais (proposta de objeto) e depois classifica cada região, o YOLO aplica uma única rede neural à imagem completa, prevendo caixas delimitadoras e probabilidades de classe para vários objetos em uma única avaliação. Esta abordagem, focando na imagem inteira em vez de em propostas separadas, permite que o YOLO detecte objetos em tempo real de forma eficaz.
Os modelos YOLO são tipicamente avaliados de acordo com sua velocidade e precisão na detecção de múltiplos objetos. Em cenários onde dois objetos estão próximos um do outro, a capacidade do YOLO de distinguir entre eles com precisão é crucial. A arquitetura do modelo permite que ele entenda o contexto dentro de uma imagem, tornando-o robusto em ambientes complexos. Essa capacidade é resultado de seu design de rede único, que observa a imagem inteira durante a previsão, capturando assim informações contextuais que podem ser perdidas ao focar em partes da imagem.
Dados para Detecção de Objetos: Coleta e Utilização
O sucesso de qualquer modelo de detecção de objetos, incluindo aqueles baseados em frameworks de aprendizado profundo como o YOLO, depende fortemente da qualidade e quantidade de dados usados para treinamento. O processo para construir um modelo de detecção de objetos começa com a coleta de dados, que envolve reunir um conjunto diversificado de imagens e anotá-las com rótulos e caixas delimitadoras. Essa coleta de dados é um passo crítico no treinamento de um modelo, pois fornece a base para o modelo aprender.
Os dados para detecção de objetos devem abranger uma ampla variedade de cenários e tipos de objetos para garantir que o modelo possa generalizar bem para novas imagens não vistas. Isso inclui levar em conta variações no tamanho dos objetos, condições de iluminação e fundos. Conjuntos de dados anotados disponíveis em plataformas como o GitHub oferecem um recurso valioso para treinamento e avaliação de modelos de detecção de objetos.
Na abordagem de aprendizado para detecção de objetos, o modelo é treinado para detectar ‘objeto versus não objeto’ e classificar os objetos detectados. Esse treinamento envolve não apenas reconhecer a presença de um objeto, mas também determinar precisamente sua localização dentro da imagem. O uso de métodos avançados de aprendizado profundo e grandes conjuntos de dados anotados aumentou substancialmente a precisão e a confiabilidade dos modelos de detecção de objetos, tornando-os ferramentas essenciais em várias aplicações de visão computacional (computer vision).
Detecção vs. Reconhecimento: Entendendo as Diferenças
No campo da visão computacional (computer vision), é crucial diferenciar entre ‘detecção vs. reconhecimento’. Detecção envolve localizar objetos dentro de uma imagem, tipicamente usando caixas delimitadoras, enquanto o reconhecimento aprofunda-se mais, visando identificar a natureza específica ou classe dos objetos detectados. Essa distinção é importante para adaptar sistemas de visão computacional para aplicações específicas. Por exemplo, enquanto um sistema de detecção pode ser suficiente para contar carros em uma estrada, um sistema de reconhecimento seria necessário para diferenciar entre modelos de carros.
A complexidade das tarefas de reconhecimento geralmente exige modelos mais sofisticados em comparação com as tarefas de detecção. O reconhecimento envolve não apenas identificar que um objeto está presente, mas também classificá-lo em uma de várias categorias possíveis. Esse processo requer um entendimento mais matizado das características do objeto e é crucial em cenários onde a identificação detalhada é essencial, como diferenciar entre células benignas e malignas em imagens médicas.
Conclusão e Tendências Futuras em Detecção de Objetos
Ao concluirmos, é evidente que a detecção de objetos é um campo em rápida evolução, com novos avanços surgindo continuamente. As tendências futuras provavelmente se concentrarão em melhorar a precisão, velocidade e capacidade de lidar com cenas mais complexas. A integração da IA com outras tecnologias como realidade aumentada e a Internet das Coisas (IoT) abre novos horizontes para aplicações de detecção de objetos.
Além disso, a demanda por modelos mais eficientes e menos intensivos em dados está impulsionando pesquisas em direção a abordagens de aprendizado com poucos exemplos e aprendizado não supervisionado. Esses métodos visam treinar modelos de forma eficaz com dados limitados, abordando um dos desafios significativos no campo. À medida que a tecnologia avança, podemos antecipar soluções mais inovadoras, aprimorando as capacidades e aplicações da detecção de objetos em vários setores, desde a saúde até veículos autônomos.
O refinamento contínuo de modelos e algoritmos em detecção de objetos certamente contribuirá para sistemas mais sofisticados e precisos, consolidando sua importância no âmbito da visão computacional (computer vision) e além.
FAQ sobre Detecção de Objetos: Entendendo os Conceitos Fundamentais
Mergulhe nos fundamentos da detecção de objetos com nossa seção de perguntas frequentes. Aqui, abordamos questões comuns, esclarecendo como a detecção de objetos funciona, suas aplicações e a tecnologia por trás dela. Se você é novo em visão computacional (computer vision) ou deseja refinar seu conhecimento, essas respostas fornecem insights concisos sobre o mundo empolgante da detecção de objetos.
O que é Detecção de Objetos?
A detecção de objetos é uma solução de visão computacional (computer vision) que identifica e localiza objetos dentro de uma imagem ou vídeo. Ela não apenas reconhece a presença de objetos, mas também indica suas posições com caixas delimitadoras. O sistema atribui níveis de confiança às previsões, indicando a probabilidade de precisão. A detecção de objetos é distinta do reconhecimento de imagens, que atribui um rótulo de classe a uma imagem, e da segmentação de imagens, que identifica objetos no nível de pixel.
Como Funciona a Detecção de Objetos?
A detecção de objetos geralmente envolve duas etapas: detectar regiões de objetos potenciais (Região de Interesse, ou RoI) e depois classificar essas regiões. Abordagens baseadas em aprendizado profundo, especialmente usando redes neurais como Redes Neurais Convolucionais (CNNs), são comuns. Modelos como R-CNN, YOLO e SSD primeiro analisam a imagem para encontrar RoIs e depois classificam cada RoI em categorias de objetos, muitas vezes usando características aprendidas durante o treinamento em conjuntos de dados como COCO ou ImageNet.
Quais são os Tipos de Modelos de Detecção de Objetos?
Modelos populares de detecção de objetos incluem R-CNN e suas variantes (Fast R-CNN, Faster R-CNN e Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) e CenterNet. Esses modelos diferem em sua abordagem para identificar RoIs e classificá-los. Modelos R-CNN usam propostas de região, enquanto YOLO e SSD preveem caixas delimitadoras diretamente da imagem, melhorando a velocidade e eficiência.
Qual é a Diferença Entre Detecção de Objetos e Reconhecimento de Objetos?
Detecção de objetos e reconhecimento de objetos são tarefas distintas. A detecção de objetos envolve localizar objetos dentro de uma imagem e identificar seus limites, tipicamente com caixas delimitadoras. O reconhecimento de objetos vai um passo além, não apenas localizando, mas também classificando os objetos em categorias predefinidas, como distinguir entre diferentes tipos de animais, veículos ou outros itens.
Como são Treinados os Modelos de Detecção de Objetos?
O treinamento de modelos de detecção de objetos envolve alimentar uma rede neural com imagens rotuladas. Essas imagens são anotadas com caixas delimitadoras ao redor dos objetos e seus rótulos de classe correspondentes. A rede neural aprende a reconhecer padrões e características dessas imagens de treinamento. A eficácia do treinamento depende da diversidade e tamanho do conjunto de dados, com conjuntos de dados maiores e variados levando a modelos mais precisos e generalizáveis. Os modelos são frequentemente treinados usando frameworks como TensorFlow ou PyTorch.
Quais são os Usos da Detecção de Objetos?
A detecção de objetos é amplamente utilizada em vários campos. Em segurança e vigilância, auxilia na detecção de rostos e monitoramento de atividades. No varejo, ajuda na análise do comportamento do cliente e na gestão de inventários. Em veículos autônomos, é crucial para identificar obstáculos e navegar com segurança. A detecção de objetos também encontra aplicações na saúde para identificar anormalidades em imagens médicas e na agricultura para monitoramento de culturas e pragas.
O que é YOLO na Detecção de Objetos?
YOLO (You Only Look Once) é um modelo popular de detecção de objetos conhecido por sua velocidade e eficiência. Ao contrário dos modelos tradicionais que processam uma imagem em partes, YOLO examina toda a imagem em uma única passagem, tornando-o significativamente mais rápido. Isso o torna ideal para aplicações de detecção de objetos em tempo real. YOLO tem várias versões, sendo YOLOv5 e YOLOv8 as mais recentes, oferecendo melhorias em precisão e velocidade.
Quão Precisos são os Modelos de Detecção de Objetos?
A precisão dos modelos de detecção de objetos varia dependendo de sua arquitetura e da qualidade dos dados de treinamento. Modelos como YOLOv4 e YOLOv5 demonstram alta precisão, muitas vezes com taxas de precisão acima de 90% em condições ideais. A precisão é medida usando métricas como mAP (Precisão Média Média) e IoU (Interseção sobre União). O mAP para os principais modelos em conjuntos de dados padrão como MS COCO pode ser tão alto quanto 60-70%.
Qual é o Papel das Redes Neurais Convolucionais na Detecção de Objetos?
As Redes Neurais Convolucionais (CNNs) desempenham um papel crítico na detecção de objetos, principalmente na extração de características. Elas processam imagens através de camadas convolucionais para aprender e identificar características chave, que são cruciais para a detecção de objetos. Modelos como R-CNN, Faster R-CNN e SSD utilizam CNNs por sua eficiência no manuseio de dados de imagem, aumentando significativamente a precisão e velocidade da detecção de objetos.
Como Começar a Construir um Modelo de Detecção de Objetos?
Para começar a construir um modelo de detecção de objetos, primeiro defina os objetos que você deseja detectar. Colete e anote um conjunto de dados com imagens contendo esses objetos. Use ferramentas como TensorFlow ou PyTorch para treinar um modelo nesse conjunto de dados. Comece com uma arquitetura simples como SSD ou YOLO para uma implementação mais fácil. Experimente diferentes configurações e hiperparâmetros para otimizar o desempenho do seu modelo.