
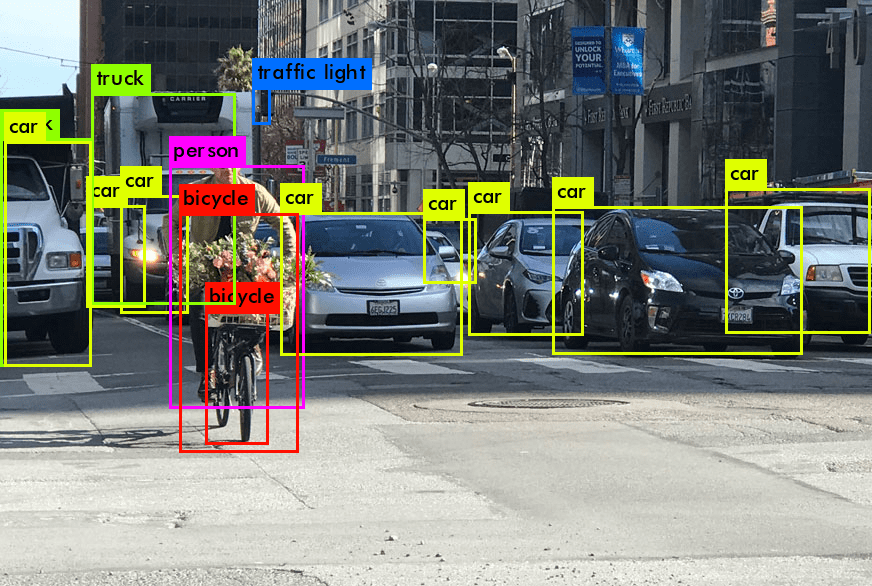
Einführung in die Objekterkennung in der Bilderkennung (computer vision)
Die Verwendung von Objekterkennung, einer grundlegenden Aufgabe der Bilderkennung (computer vision), hat revolutioniert, wie Maschinen die visuelle Welt interpretieren. Im Gegensatz zur Bildklassifizierung, bei der das Ziel darin besteht, ein gesamtes Bild zu klassifizieren, kann die Objekterkennung dazu verwendet werden, Objekte innerhalb eines Bildes oder Videobildes (was dasselbe wie ein Bild / Foto ist) zu identifizieren und zu lokalisieren. Dieser Prozess umfasst das Erkennen des spezifischen Objekts, die Objektlokalisierung und die Bestimmung seiner Position durch ein Begrenzungsrahmen. Die Objekterkennung schließt die Lücke zwischen Bildklassifizierung und komplexeren Aufgaben wie der Bildsegmentierung, bei der das Ziel darin besteht, jedes Pixel des Bildes einem bestimmten einzelnen Objekt zuzuordnen.
Das Aufkommen des Deep Learning, insbesondere der Einsatz von Convolutional Neural Networks (CNNs), hat die Objekterkennung erheblich vorangetrieben. Diese neuronalen Netzwerke verarbeiten und analysieren visuelle Daten effektiv, was sie ideal für die Erkennung von Objekten in einem Bild oder Video macht. Wichtige Entwicklungen wie YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) und auf Regionsvorschlägen basierende Netzwerke wie Mask R-CNN haben die Genauigkeit und Effizienz von Objekterkennungssystemen weiter verbessert. Diese Modelle können die Erkennung in Echtzeit durchführen, ein entscheidender Faktor für Anwendungen wie autonomes Fahren oder Echtzeitüberwachung.
Darüber hinaus hat die Integration von maschinellem Lernen es Objekterkennungssystemen ermöglicht, verschiedene Objekte in komplexen Umgebungen zu klassifizieren und zu segmentieren. Diese Fähigkeit ist entscheidend für eine Reihe von Anwendungen, von der Fußgängererkennung in der Infrastruktur intelligenter Städte bis zur Qualitätskontrolle in der Fertigung.
Verständnis des Datensatzes für die Objekterkennung
Die Grundlage jedes erfolgreichen Systems zur Objekterkennung liegt in seinem Datensatz. Ein Datensatz für die Objekterkennung besteht aus Bildern oder Videos, die annotiert sind, um einen Detektor zu trainieren. Diese Annotationen umfassen typischerweise Begrenzungsrahmen um Objekte und Beschriftungen, die die Klasse jedes Objekts angeben. Die Qualität, Vielfalt und Größe des Datensatzes spielen eine entscheidende Rolle für die Leistung von Modellen zur Objekterkennung. Beispielsweise ermöglichen größere Datensätze mit einer Vielzahl von Objekten und Szenarien, dass das neuronale Netzwerk robustere und generalisierbare Merkmale lernt.
Datensätze wie PASCAL VOC, MS COCO und ImageNet waren maßgeblich für den Fortschritt der Objekterkennung. Sie bieten eine breite Palette von annotierten Bildern, von alltäglichen Objekten bis hin zu spezifischen Szenarien, und unterstützen die Entwicklung vielseitiger und genauer Erkennungsmodelle. Diese Datensätze erleichtern nicht nur das Training von Modellen, sondern dienen auch als Benchmarks, um die Leistung verschiedener Algorithmen zur Objekterkennung zu bewerten und zu vergleichen.
Das Training eines Modells für die Objekterkennung beinhaltet auch den Einsatz von Techniken wie Transferlernen, bei dem ein auf einem großen Datensatz vortrainiertes Modell mit einem kleineren, spezifischen Datensatz feinabgestimmt wird. Dieser Ansatz ist besonders vorteilhaft, wenn die verfügbaren Daten für die Objekterkennung begrenzt sind oder wenn das Training eines Modells von Grund auf rechenintensiv ist.
Zusammenfassend ist der Datensatz eine entscheidende Komponente in der Objekterkennung, die direkt die Fähigkeit eines Modells beeinflusst, Objekte in verschiedenen Kontexten und Umgebungen genau zu erkennen. Da sich die zugehörigen Aufgaben und Technologien der Bilderkennung (computer vision) weiterentwickeln, bleibt die Erstellung und Verfeinerung von Datensätzen ein zentraler Schwerpunkt für Forscher und Praktiker in diesem Bereich.
Erkundung von Objekterkennungsmodellen: Von traditionellen zu Deep-Learning-Methoden
Die Objekterkennung ist eine Aufgabe der Bilderkennung (computer vision), die sich besonders mit dem Fortschritt der Deep-Learning-Technologien erheblich weiterentwickelt hat. Ursprünglich basierte die Objekterkennung auf einfacheren Bilderkennungstechniken und maschinellen Lernalgorithmen, bei denen Merkmale zur Objektklassifizierung manuell erstellt wurden und die Modelle darauf trainiert wurden, Objekte in Bildern anhand dieser Merkmale zu erkennen. Die Einführung von Deep Learning, insbesondere tiefen Convolutional Neural Networks (CNNs), revolutionierte dieses Feld. CNNs lernen automatisch Merkmalshierarchien aus den Daten, was eine genauere Objekterkennung und semantische Segmentierung ermöglicht. Dieser Übergang zu Deep-Learning-Modellen markierte eine signifikante Verbesserung der Fähigkeiten zur Objekterkennung.
Frühe auf CNN basierende Objekterkennungsmodelle, wie R-CNN, verwendeten eine Methode zur Vorschlagserstellung von Bereichen, um potenzielle Standorte von Objekten in einem Bild zu identifizieren und dann jeden Bereich zu klassifizieren. Nachfolger wie Fast R-CNN und Faster R-CNN verbesserten dies, indem sie die Erkennungsgenauigkeit und die Verarbeitungsgeschwindigkeit erhöhten. Weitere Entwicklungen führten zur Einführung von Mask R-CNN, das die Fähigkeiten seiner Vorgänger erweiterte, indem es einen Zweig für die pixelgenaue Segmentierung hinzufügte, was eine detaillierte Objektlokalisierung und -erkennung erleichterte.
YOLO: Revolutionierung der Echtzeit-Objekterkennung
Im Bereich der Echtzeit-Objekterkennung stellt das YOLO-Modell (You Only Look Once) einen bedeutenden Durchbruch dar. YOLO konzeptualisiert die Objekterkennung einzigartig als ein einzelnes Regressionsproblem, indem es direkt die Koordinaten der Begrenzungsrahmen und die Klassenwahrscheinlichkeiten aus den Bildpixeln in einer Auswertung vorhersagt. Dieser Ansatz ermöglicht es YOLO, außergewöhnliche Verarbeitungsgeschwindigkeiten zu erreichen, die für Anwendungen erforderlich sind, die eine Echtzeit-Erkennung benötigen, wie die Fußgängererkennung und die Fahrzeugverfolgung in intelligenten Städten.
Die Architektur von YOLO verarbeitet während des Trainings das gesamte Bild, wodurch es kontextuelle Informationen über Objektklassen und ihr Aussehen verstehen kann. Dies steht im Gegensatz zu den auf Regionsvorschlägen basierenden Methoden, die einige kontextuelle Details übersehen könnten. Die Echtzeit-Verarbeitungsfähigkeit von YOLO macht es unverzichtbar in Szenarien, die eine schnelle und genaue Objekterkennung erfordern. Die YOLO-Modellfamilie, einschließlich fortgeschrittener Versionen wie YOLOv3 und YOLOv4, hat die Grenzen in Bezug auf Erkennungsgeschwindigkeit und Genauigkeit verschoben und YOLO als ein hochmodernes System in der Echtzeit-Objekterkennung etabliert, das bis zu YOLOv8 reicht.
Echtzeit-Videoanalytik zur Objekterkennung auf der Drohne während des Fluges mit visionplatform.ai und unserem auf der Drohne montierten NVIDIA Jetson Edge-Computer. Wir verwandeln JEDE Kamera in eine KI-Kamera.
Schlüsselkomponenten in der Objekterkennung: Klassifizierung und Begrenzungsrahmen
Die Einführung in die Objekterkennung enthüllt zwei grundlegende Aspekte: Klassifizierung und der Begrenzungsrahmen. Klassifizierung bezieht sich darauf, die Objektklasse (z.B. Fußgänger, Fahrzeug) in einem Bild zu identifizieren. Dies ist ein entscheidender Schritt, um zwischen verschiedenen Objektkategorien innerhalb eines Erkennungssystems zu unterscheiden. Der Begrenzungsrahmen andererseits beinhaltet das Lokalisieren des Objekts innerhalb des Bildes, normalerweise dargestellt durch Koordinaten, die das Objekt umreißen. Zusammen bilden diese Komponenten die Grundlage der Objekterkennung und -verfolgung.
Objekterkennung kann Modellen wie der YOLO-Modellfamilie und dem Single Shot Multibox Detector (SSD) helfen, die Kombination aus Klassifizierung und Begrenzungsrahmen gewährleistet die Erkennungsgenauigkeit. Diese Modelle, die oft auf Plattformen wie GitHub entwickelt und geteilt werden, nutzen Ansätze, die auf tiefem Lernen basieren. Sie können auch ohne eine Zeile Code auf Bilderkennungsplattformen (computer vision) wie visionplatform.ai verwendet werden. Sie sind in der Lage, mehrere Objekte in einem Bild zu erkennen und die Lage jedes Objekts genau mit einem Begrenzungsrahmen um es herum vorherzusagen. Dieser doppelte Ansatz ist in verschiedenen Anwendungsfällen der Objekterkennung unerlässlich, von der Gesichtserkennung in Sicherheitssystemen bis zur Anomalieerkennung in industriellen Umgebungen.
Die Rolle des Deep Learning bei der Objekterkennung
Methoden des Deep Learning haben die Bilderkennung (computer vision) und Objekterkennung revolutioniert. Diese Methoden, die hauptsächlich tiefe neuronale Netzwerke wie CNNs einbeziehen, haben eine genauere Objekterkennung und semantische Segmentierung ermöglicht. TensorFlow, eine beliebte Open-Source-Bibliothek für maschinelles Lernen und Deep Learning, bietet robuste Werkzeuge zum Trainieren und Bereitstellen von Deep-Learning-Modellen für die Objekterkennung.
Die Wirksamkeit von Deep Learning bei der Objekterkennung lässt sich an seiner Anwendung bei komplexen Aufgaben wie der Fußgängererkennung und Texterkennung beobachten. Diese Modelle lernen Hierarchien von Merkmalen für eine genaue Objekterkennung, was eine erhebliche Verbesserung gegenüber traditionellen maschinellen Lernalgorithmen darstellt, die handgefertigte Merkmale benötigten. Objekterkennungsmodelle, die auf Deep Learning basieren, werden in der Regel nach ihrer Erkennungsgenauigkeit und Geschwindigkeit bewertet, was sie ideal für Echtzeitanwendungen macht.
Mit dem Fortschritt der Deep-Learning-Techniken sind Objekterkennungssysteme vielseitiger geworden und können eine breite Palette von Bilderkennungsaufgaben (computer vision) bewältigen, einschließlich Objektverfolgung, Personenerkennung und Bilderkennung. Dieser Fortschritt hat zur Entwicklung robuster Objekterkennungsalgorithmen geführt, die Objekte auch in herausfordernden Umgebungen zuverlässig klassifizieren und lokalisieren können.
Segmentierung und Objekterkennung: Verbesserung der Erkennung durch detaillierte Analyse
Die Einführung in die Objekterkennung in der Bilderkennung (computer vision) führt oft zur Erforschung verwandter Aufgaben wie Segmentierung und Objekterkennung. Während die Objekterkennung Objekte innerhalb eines Bildes identifiziert und lokalisiert, geht die Segmentierung einen Schritt weiter, indem sie das Bild in Segmente unterteilt, um dessen Analyse zu vereinfachen oder seine Darstellung zu ändern. Die Objekterkennung hingegen befasst sich mit der Identifizierung des spezifischen Objekts im Bild.
Techniken, die auf tiefem Lernen basieren, insbesondere tiefe Faltungsneuronale Netzwerke, haben diese Bereiche erheblich vorangetrieben. Die Segmentierung, insbesondere die semantische Segmentierung, ist integral für das Verständnis des Kontexts, in dem Objekte in Bildern existieren. Dies ist entscheidend in Anwendungsfällen wie der medizinischen Bildgebung, wo eine präzise Identifikation von Geweben oder Anomalien wesentlich ist. Algorithmen zur Objekterkennung, die Segmentierung einschließen, wie Mask R-CNN, bieten detaillierte Einblicke, indem sie nicht nur das „Bounding-Box um“ ein Objekt lokalisieren, sondern auch die genaue „Form des Objekts“ abgrenzen.
Verarbeitung des Eingabebildes: Die Reise durch Objekterkennungssysteme
Der Prozess der Objekterkennung beginnt mit einem Eingabebild, das mehrere Stufen innerhalb eines Erkennungsnetzwerks durchläuft. Zunächst wird das Bild vorverarbeitet, um den Anforderungen des Objekterkennungsmodells zu entsprechen. Dies kann Größenänderung, Normalisierung und Erweiterung umfassen. Anschließend wird das Bild in ein Deep-Learning-Modell, typischerweise eine Art von Modell wie CNNs, zur Merkmalsextraktion eingespeist.
Die extrahierten Merkmale werden dann verwendet, um Objekte zu klassifizieren und ihre Position vorherzusagen. Objekterkennung, die in Echtzeitszenarien verwendet wird, wie Fußgängererkennung oder Fahrzeugverfolgung, erfordert, dass das Modell das Eingabebild schnell analysiert und genaue „vorhergesagte Begrenzungsrahmen“ für jedes „vorhandene Objekt“ liefert. Hier zeichnen sich Modelle wie YOLO aus, die eine schnelle und effiziente Verarbeitung bieten, die für Echtzeitanwendungen geeignet ist.
Das Training eines Modells für solch komplexe Aufgaben erfordert eine erhebliche Menge an Daten für die Objekterkennung. Diese Daten, die normalerweise aus vielfältigen Bildern mit annotierten Objekten bestehen, helfen dem Modell, verschiedene Objektkategorien und ihre Merkmale zu erlernen. Beliebte Objekterkennungs-Frameworks wie TensorFlow bieten Werkzeuge und Bibliotheken, um diese Modelle effizient zu bauen, zu trainieren und zu implementieren. Der gesamte Prozess unterstreicht die Synergie zwischen Bilderkennung (https://en.wikipedia.org/wiki/Computer_vision) (computer vision) und Bildverarbeitungstechniken, maschinellem Lernen und Deep-Learning-Methoden, die in einem robusten Objekterkennungssystem gipfeln.
Anwendungsfälle der Objekterkennung in verschiedenen Branchen
Die Objekterkennung, angetrieben durch Modelle, die auf tiefem Lernen basieren, hat Anwendungen in verschiedenen Branchen gefunden, jede mit einzigartigen Anforderungen und Herausforderungen. Diese Modelle werden typischerweise nach ihrer Genauigkeit, Geschwindigkeit und Fähigkeit bewertet, mehrere Objekte unter verschiedenen Bedingungen zu erkennen. Im Gesundheitswesen hilft die Objekterkennung dabei, Anomalien in der medizinischen Bildgebung zu identifizieren, was erheblich zur Früherkennung und Behandlungsplanung beiträgt. Im Einzelhandel spielt sie eine entscheidende Rolle bei der Analyse des Kundenverhaltens und der Bestandsverwaltung.
Ein bemerkenswerter Anwendungsfall der Objekterkennung ist in der Automobilindustrie, wo sie für die Entwicklung von autonomen Fahrzeugen entscheidend ist. Hier ist die Fähigkeit, zwischen zwei Objekten, wie Fußgängern und anderen Fahrzeugen, zu unterscheiden, von größter Bedeutung für die Sicherheit. Objekterkennungssysteme, die fortschrittliche Algorithmen und neuronale Netzwerke verwenden, ermöglichen es diesen Fahrzeugen, sicher zu navigieren, indem sie ihre Umgebung genau interpretieren.
TensorFlow in der Objekterkennung: Nutzung von Deep-Learning-Modellen
TensorFlow, ein Open-Source-Framework, das auf Plattformen wie GitHub verfügbar ist, ist zum Synonym für das Erstellen und Bereitstellen von Deep-Learning-Modellen geworden, insbesondere im Bereich der Objekterkennung. Seine umfassende Bibliothek ermöglicht es Entwicklern, ein Modell von Grund auf neu zu erstellen oder vortrainierte Modelle für die Objekterkennung zu verwenden. Die Flexibilität von TensorFlow im Umgang mit verschiedenen Mechanismen zur Objektvorschlag und seine effiziente Verarbeitung großer Datensätze machen es zur bevorzugten Wahl vieler Entwickler.
In der Objekterkennung ist der Lernansatz entscheidend. TensorFlow erleichtert die Implementierung komplexer Algorithmen, die zwischen ‚Erkennung vs. Klassifizierung‘ unterscheiden können, was für nuancierte Objekterkennungsszenarien wesentlich ist. Die Plattform unterstützt eine breite Palette von Modellen, von solchen, die intensive Rechenressourcen erfordern, bis hin zu leichten Modellen, die für mobile Geräte geeignet sind. Diese Anpassungsfähigkeit stellt sicher, dass auf TensorFlow basierende Modelle in verschiedenen Umgebungen eingesetzt werden können, von serverbasierten Systemen bis hin zu Edge-Geräten wie dem Jetson Nano Orin, Jetson NX Orin oder Jetson AGX Orin, was den Umfang und die Zugänglichkeit der Objekterkennungstechnologie erweitert.
Erforschung des YOLO-Modells im Detail
Das YOLO (You Only Look Once)-Modell, ein auf tiefem Lernen basierendes Framework für die Objekterkennung, stellt einen signifikanten Wandel im Lernansatz zur Objekterkennung dar. Im Gegensatz zu traditionellen Modellen, bei denen das System zunächst potenzielle Regionen vorschlägt (Objektvorschlag) und dann jede Region klassifiziert, wendet YOLO ein einzelnes neuronales Netzwerk auf das gesamte Bild an, das Begrenzungsrahmen und Wahrscheinlichkeiten für mehrere Objekte in einer einzigen Auswertung vorhersagt. Dieser Ansatz, der sich auf das gesamte Bild und nicht auf separate Vorschläge konzentriert, ermöglicht es YOLO, Objekte in Echtzeit effektiv zu erkennen.
YOLO-Modelle werden typischerweise nach ihrer Geschwindigkeit und Genauigkeit bei der Erkennung mehrerer Objekte bewertet. In Szenarien, in denen zwei Objekte nahe beieinander liegen, ist die Fähigkeit von YOLO, zwischen ihnen genau zu unterscheiden, entscheidend. Die Architektur des Modells ermöglicht es ihm, den Kontext innerhalb eines Bildes zu verstehen, was es in komplexen Umgebungen robust macht. Diese Fähigkeit ist das Ergebnis seines einzigartigen Netzwerkdesigns, das während der Vorhersage das gesamte Bild betrachtet und dadurch Kontextinformationen erfasst, die möglicherweise verloren gehen würden, wenn man sich auf Teile des Bildes konzentriert.
Daten für Objekterkennung: Sammlung und Nutzung
Der Erfolg eines jeden Objekterkennungsmodells, einschließlich derer, die auf Deep-Learning-basierten Frameworks wie YOLO basieren, hängt stark von der Qualität und Quantität der für das Training verwendeten Daten ab. Der Prozess zum Erstellen eines Modells für die Objekterkennung beginnt mit der Datensammlung, die das Sammeln einer vielfältigen Menge von Bildern und das Annotieren dieser mit Labels und Begrenzungsrahmen umfasst. Diese Datensammlung ist ein kritischer Schritt beim Training eines Modells, da sie die Grundlage bietet, von der das Modell lernt.
Die Daten für die Objekterkennung müssen eine breite Vielfalt an Szenarien und Objekttypen umfassen, um sicherzustellen, dass das Modell gut auf neue, unbekannte Bilder verallgemeinern kann. Dies beinhaltet die Berücksichtigung von Variationen in Objektgröße, Lichtverhältnissen und Hintergründen. Annotierte Datensätze, die auf Plattformen wie GitHub verfügbar sind, bieten eine wertvolle Ressource für das Training und das Benchmarking von Objekterkennungsmodellen.
Im Lernansatz für die Objekterkennung wird das Modell trainiert, um ‚Objekt vs. kein Objekt‘ zu erkennen und die erkannten Objekte zu klassifizieren. Dieses Training beinhaltet nicht nur das Erkennen der Anwesenheit eines Objekts, sondern auch das genaue Bestimmen seiner Position innerhalb des Bildes. Der Einsatz von fortgeschrittenen Deep-Learning-Methoden und großen, annotierten Datensätzen hat die Erkennungsgenauigkeit und Zuverlässigkeit von Objekterkennungsmodellen erheblich gesteigert, was sie zu wesentlichen Werkzeugen in verschiedenen Anwendungen der Bilderkennung (computer vision) macht.
Erkennung vs. Identifikation: Die Unterschiede verstehen
Im Bereich der Bilderkennung (computer vision) ist es entscheidend, zwischen ‚Erkennung vs. Identifikation‘ zu unterscheiden. Erkennung beinhaltet das Lokalisieren von Objekten innerhalb eines Bildes, typischerweise unter Verwendung von Begrenzungsrahmen, während die Identifikation tiefer geht und darauf abzielt, die spezifische Natur oder Klasse der erkannten Objekte zu bestimmen. Diese Unterscheidung ist wichtig, um Bilderkennungssysteme (computer vision) für spezifische Anwendungen maßzuschneidern. Beispielsweise könnte ein Erkennungssystem ausreichen, um Autos auf einer Straße zu zählen, während ein Identifikationssystem notwendig wäre, um zwischen Automodellen zu unterscheiden.
Die Komplexität von Identifikationsaufgaben erfordert in der Regel ausgefeiltere Modelle im Vergleich zu Erkennungsaufgaben. Identifikation beinhaltet oft nicht nur die Feststellung, dass ein Objekt vorhanden ist, sondern auch dessen Klassifizierung in eine von mehreren möglichen Kategorien. Dieser Prozess erfordert ein nuancierteres Verständnis der Merkmale des Objekts und ist entscheidend in Szenarien, in denen eine detaillierte Identifikation wesentlich ist, wie zum Beispiel die Unterscheidung zwischen gutartigen und bösartigen Zellen in der medizinischen Bildgebung.
Schlussfolgerung und zukünftige Trends in der Objekterkennung
Wie wir abschließend feststellen können, ist die Objekterkennung ein sich schnell entwickelndes Feld, in dem ständig neue Fortschritte gemacht werden. Zukünftige Trends werden wahrscheinlich darauf abzielen, die Genauigkeit, Geschwindigkeit und die Fähigkeit zur Bewältigung komplexerer Szenen zu verbessern. Die Integration von KI mit anderen Technologien wie erweiterter Realität und dem Internet der Dinge (IoT) eröffnet neue Horizonte für Anwendungen der Objekterkennung.
Darüber hinaus treibt die Nachfrage nach effizienteren und weniger datenintensiven Modellen die Forschung in Richtung Few-Shot-Learning und unüberwachte Lernansätze voran. Diese Methoden zielen darauf ab, Modelle effektiv mit begrenzten Daten zu trainieren und damit eine der großen Herausforderungen im Bereich anzugehen. Mit dem Fortschritt der Technologie können wir innovative Lösungen erwarten, die die Fähigkeiten und Anwendungen der Objekterkennung in verschiedenen Sektoren, von der Gesundheitsversorgung bis zu autonomen Fahrzeugen, verbessern.
Die kontinuierliche Verfeinerung von Modellen und Algorithmen in der Objekterkennung wird zweifellos zu ausgefeilteren und genaueren Systemen beitragen und ihre Bedeutung im Bereich der Bilderkennung (computer vision) und darüber hinaus festigen.
FAQ zur Objekterkennung: Verständnis der Kernkonzepte
Tauchen Sie mit unserem FAQ-Bereich in die Grundlagen der Objekterkennung ein. Hier beantworten wir häufig gestellte Fragen, klären, wie die Objekterkennung funktioniert, ihre Anwendungen und die dahinterstehende Technologie. Ob Sie neu in der Bilderkennung (computer vision) sind oder Ihr Wissen verfeinern möchten, diese Antworten bieten prägnante Einblicke in die spannende Welt der Objekterkennung.
Was ist Objekterkennung?
Die Objekterkennung ist eine Lösung der Bilderkennung (computer vision), die Objekte innerhalb eines Bildes oder Videos identifiziert und lokalisiert. Sie erkennt nicht nur die Anwesenheit von Objekten, sondern markiert auch deren Positionen mit Begrenzungsrahmen. Das System weist Vorhersagen Vertrauensniveaus zu, die die Wahrscheinlichkeit der Genauigkeit angeben. Die Objekterkennung unterscheidet sich von der Bilderkennung, die einem Bild eine Klassenbezeichnung zuweist, und der Bildsegmentierung, die Objekte auf Pixelebene identifiziert.
Wie funktioniert die Objekterkennung?
Die Objekterkennung umfasst im Allgemeinen zwei Phasen: das Erkennen potenzieller Objektbereiche (Region of Interest, oder RoI) und dann das Klassifizieren dieser Bereiche. Ansätze, die auf tiefem Lernen basieren, insbesondere unter Verwendung von neuronalen Netzwerken wie Convolutional Neural Networks (CNNs), sind üblich. Modelle wie R-CNN, YOLO und SSD analysieren zunächst das Bild, um RoIs zu finden, und klassifizieren dann jedes RoI in Objektkategorien, oft unter Verwendung von Merkmalen, die während des Trainings auf Datensätzen wie COCO oder ImageNet gelernt wurden.
Was sind die Arten von Objekterkennungsmodellen?
Beliebte Objekterkennungsmodelle umfassen R-CNN und seine Varianten (Fast R-CNN, Faster R-CNN und Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) und CenterNet. Diese Modelle unterscheiden sich in ihrem Ansatz zur Identifizierung von RoIs und deren Klassifizierung. R-CNN-Modelle verwenden Regionsvorschläge, während YOLO und SSD Begrenzungsrahmen direkt aus dem Bild vorhersagen, was Geschwindigkeit und Effizienz verbessert.
Was ist der Unterschied zwischen Objekterkennung und Objekterkennung?
Objekterkennung und Objekterkennung sind unterschiedliche Aufgaben. Die Objekterkennung beinhaltet das Lokalisieren von Objekten innerhalb eines Bildes und das Identifizieren ihrer Grenzen, typischerweise mit Begrenzungsrahmen. Die Objekterkennung geht einen Schritt weiter, indem sie nicht nur lokalisiert, sondern auch die Objekte in vordefinierte Kategorien klassifiziert, wie das Unterscheiden zwischen verschiedenen Arten von Tieren, Fahrzeugen oder anderen Gegenständen.
Wie werden Objekterkennungsmodelle trainiert?
Das Training von Objekterkennungsmodellen beinhaltet das Füttern eines neuronalen Netzwerks mit beschrifteten Bildern. Diese Bilder sind mit Begrenzungsrahmen um Objekte und deren entsprechenden Klassenbezeichnungen annotiert. Das neuronale Netzwerk lernt, Muster und Merkmale aus diesen Trainingsbildern zu erkennen. Die Wirksamkeit des Trainings hängt von der Vielfalt und Größe des Datensatzes ab, wobei größere, vielfältigere Datensätze zu genaueren und generalisierbaren Modellen führen. Modelle werden oft unter Verwendung von Frameworks wie TensorFlow oder PyTorch trainiert.
Was sind die Anwendungen der Objekterkennung?
Die Objekterkennung wird in verschiedenen Bereichen eingesetzt. In Sicherheit und Überwachung hilft sie bei der Gesichtserkennung und der Überwachung von Aktivitäten. Im Einzelhandel hilft sie bei der Analyse des Kundenverhaltens und der Bestandsverwaltung. In autonomen Fahrzeugen ist sie entscheidend für die Identifizierung von Hindernissen und die sichere Navigation. Die Objekterkennung findet auch Anwendungen im Gesundheitswesen zur Identifizierung von Anomalien in medizinischen Bildern und in der Landwirtschaft zur Überwachung von Kulturen und Schädlingen.
Was ist YOLO in der Objekterkennung?
YOLO (You Only Look Once) ist ein beliebtes Objekterkennungsmodell, das für seine Geschwindigkeit und Effizienz bekannt ist. Im Gegensatz zu traditionellen Modellen, die ein Bild in Teilen verarbeiten, untersucht YOLO das gesamte Bild in einem einzigen Durchgang, was es deutlich schneller macht. Dies macht es ideal für Anwendungen zur Echtzeit-Objekterkennung. YOLO hat mehrere Versionen, wobei YOLOv5 und YOLOv8 die neuesten sind und Verbesserungen in Genauigkeit und Geschwindigkeit bieten.
Wie genau sind Objekterkennungsmodelle?
Die Genauigkeit von Objekterkennungsmodellen variiert je nach ihrer Architektur und der Qualität der Trainingsdaten. Modelle wie YOLOv4 und YOLOv5 zeigen eine hohe Genauigkeit, oft mit Präzisionsraten über 90% unter idealen Bedingungen. Die Genauigkeit wird anhand von Metriken wie mAP (mean Average Precision) und IoU (Intersection over Union) gemessen. Der mAP für Top-Modelle auf Standarddatensätzen wie MS COCO kann bis zu 60-70% betragen.
Welche Rolle spielen Convolutional Neural Networks in der Objekterkennung?
Convolutional Neural Networks (CNNs) spielen eine entscheidende Rolle in der Objekterkennung, hauptsächlich bei der Merkmalsextraktion. Sie verarbeiten Bilder durch konvolutionäre Schichten, um Schlüsselmerkmale zu lernen und zu identifizieren, die für die Erkennung von Objekten entscheidend sind. Modelle wie R-CNN, Faster R-CNN und SSD nutzen CNNs für ihre Effizienz bei der Verarbeitung von Bilddaten, was die Genauigkeit und Geschwindigkeit der Objekterkennung erheblich verbessert.
Wie fängt man an, ein Objekterkennungsmodell zu bauen?
Um mit dem Bau eines Objekterkennungsmodells zu beginnen, definieren Sie zunächst die Objekte, die Sie erkennen möchten. Sammeln und annotieren Sie einen Datensatz mit Bildern, die diese Objekte enthalten. Verwenden Sie Tools wie TensorFlow oder PyTorch, um ein Modell auf diesem Datensatz zu trainieren. Beginnen Sie mit einer einfachen Architektur wie SSD oder YOLO für eine einfachere Implementierung. Experimentieren Sie mit verschiedenen Konfigurationen und Hyperparametern, um die Leistung Ihres Modells zu optimieren.