
Hyperparameter-Optimierung für YOLOv8 mit Weights & Biases: Ein Abenteuer mit Objekterkennungsalgorithmen
Einleitung
Bei der Arbeit mit Objekterkennungsaufgaben ist es entscheidend, dass Ihr Modell optimal funktioniert. Dies beinhaltet die Auswahl der richtigen Hyperparameter. In diesem Blogbeitrag werden wir meinen Weg der Hyperparameter-Optimierung für das YOLOv8 Objekterkennungsmodell mit Weights & Biases (W&B) und der Bayesschen Optimierungsmethode durchgehen.
Von Justas Andriuškevičius– Maschinelles Lernen Ingenieur bei visionplatform.ai
Warum Hyperparameter-Optimierung?
Jedes Maschinenlernmodell kommt mit seinem eigenen Satz von Einstellmöglichkeiten und Knöpfen – den Hyperparametern. Die richtige Kombination kann den Unterschied zwischen einem durchschnittlichen und einem leistungsstarken Modell ausmachen. Aber bei unzähligen möglichen Kombinationen, wie wählen Sie aus? Hier kommt die Hyperparameter-Optimierung und speziell W&B ins Spiel.
Datensatzauswahl
Bevor wir uns intensiv mit den Hyperparametern beschäftigen, sprechen wir über die Datensatzauswahl. Die Hyperparameter-Optimierung ist eine ressourcenintensive Aufgabe. Es auf einem vollständigen Datensatz durchzuführen, würde unglaublich viel Zeit in Anspruch nehmen – und seien wir ehrlich; niemand hat Zeit dafür, besonders wenn man mit umfangreichen Datensätzen arbeitet.
Um ein Gleichgewicht zwischen Recheneffizienz und einem repräsentativen Datensatz zu finden, habe ich einen klugen Ansatz gewählt. Aus einem großen Datensatz mit Bildern in zeitlicher Reihenfolge erstellte ich eine Teilmenge, indem ich sie nach Zeitstempel sortierte, die nur 1/4 des ursprünglichen Satzes ausmacht. Diese Methode stellt sicher, dass das Modell mit vielfältigen Daten trainiert wird, die sowohl Tages- als auch Nachtszenen umfassen, was für eine Objekterkennungsaufgabe von wesentlicher Bedeutung ist. Gleichzeitig verringert diese Methode die Rechenzeit im Vergleich zur Verwendung des gesamten Datensatzes erheblich. Für die Bewertung habe ich mich für das ursprüngliche Validierungsset entschieden, da es eine umfassendere und unvoreingenommene Bewertung der Modellleistung auf unbekannten Daten bietet und bereits nur ein Bruchteil der ursprünglichen Trainingssetgröße ist.
Das YOLOv8-Modell und seine Hyperparameter
Das YOLOv8-Modell (You Only Look Once) ist bei Objekterkennungsaufgaben wegen seiner Effizienz beliebt. Mehrere Hyperparameter beeinflussen seine Leistung:
- Batchgröße (batch): Sie bestimmt die Anzahl der verarbeiteten Proben, bevor das Modell seine Gewichtungen aktualisiert.
- Bildgröße (imgsz): Sie beeinflusst die Auflösung der Bilder, die in das Modell eingespeist werden.
- Lernrate (lr0): Sie steuert, wie stark das Modell in Reaktion auf den geschätzten Fehler bei jedem Gewichtsupdate angepasst wird.
- Optimierer: Er beeinflusst, wie das Modell seine Gewichtungen aktualisiert.
- Augmentation (augment): Gibt an, ob zufällige Änderungen an den Eingabedaten vorgenommen werden, um die Robustheit des Modells zu erhöhen.
- Dropout (dropout): Es handelt sich um eine Regularisierungstechnik zur Vermeidung von Überanpassung.
Warum Bayessche Optimierung?
Die richtigen Hyperparameter zu wählen, kann sich anfühlen, als würde man in einem Heuhaufen nach einer Nadel suchen. Bayessche Optimierung macht diese Suche intelligenter. Stellen Sie sich vor, Sie versuchen, in einem Spiel den höchsten Punktestand zu erzielen. Anstatt jeden möglichen Zug zufällig auszuprobieren (was ewig dauern könnte!), schaut sich die Bayessche Optimierung Ihre bisherigen Züge an, lernt daraus und schlägt klug den nächsten besten Zug vor. Sie balanciert zwischen dem Ausprobieren von bewährten Zügen (Ausnutzung) und dem Experimentieren mit neuen (Entdeckung).
Warum mAP50 maximieren?
mAP50 steht für durchschnittliche Genauigkeit bei einer IoU von 0,5. Einfach ausgedrückt, bewertet es, wie gut die vorhergesagten Begrenzungsrahmen unseres Modells mit den echten Übereinstimmen. Das Maximieren von mAP50 bedeutet, dass unser Modell nicht nur Objekte erkennt, sondern auch ihre Standorte genau bestimmt. Da das Ziel darin besteht, Fahrzeugtypen bei Tag, Nacht und bei extremen Wetterbedingungen zu erkennen, wird das Sicherstellen eines hohen mAP50 noch wichtiger. Es geht nicht nur darum, Fahrzeuge zu erkennen, sondern sicherzustellen, dass sie in unterschiedlichen und herausfordernden Szenarien genau erkannt werden. Warum habe ich mich dafür entschieden, mAP50 anstelle von mAP50–95 zu maximieren? Als ich unser Modell zum ersten Mal mit den Standard-Hyperparametern trainierte, stellte ich fest, dass mAP50 seinen optimalen Wert etwa bei der 30-Epochen-Marke erreichte, während mAP50–95 länger dauerte und sich nur um die 50-Epochen-Marke stabilisierte. Bemerkenswert ist, dass ein hoher mAP50 oft auf einen ebenso hohen mAP50–95 hindeutete. Aufgrund dieses Verhaltens habe ich mich bei der Hyperparameter-Optimierung dafür entschieden, mAP50 zu maximieren. Dieser Ansatz ermöglicht es uns, jeden Evaluierungslauf zu verkürzen und eine effizientere Erkundung verschiedener Parameterkombinationen zu ermöglichen.
Verwendung von W&B für die Hyperparameter-Optimierung
Die Sweep-Funktion von W&B vereinfacht den Optimierungsprozess. Ich habe den Sweep mit der Bayesschen Methode eingerichtet, um die besten Hyperparameter zu suchen. Interessanterweise wählte ich 30 Epochen für das Training, weil in meinen ersten Tests mit dem vollen Datensatz das Modell bereits um diesen Zeitpunkt Anzeichen optimaler Leistung zeigte.
Ergebnisse und Erkenntnisse
Eintauchen in die Ergebnisse der Hyperparameter-Optimierung offenbart wichtige Erkenntnisse:
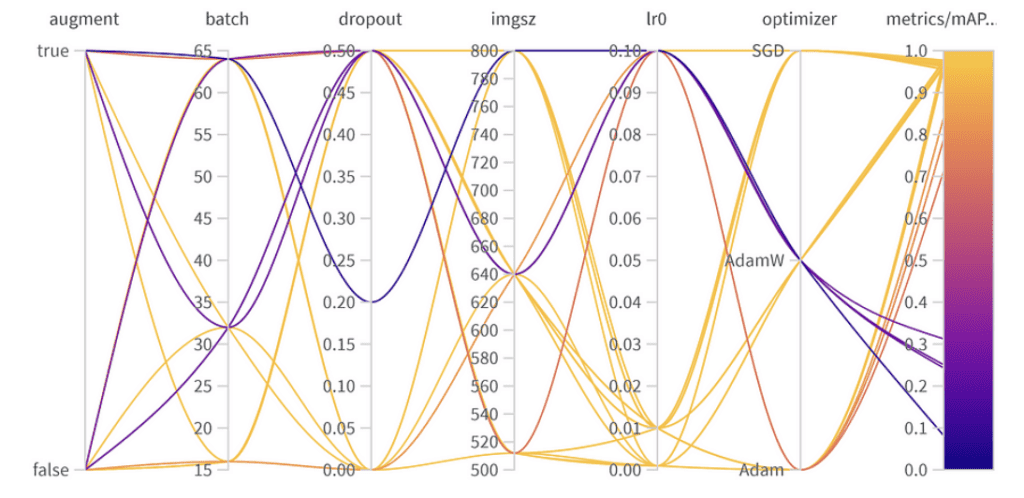
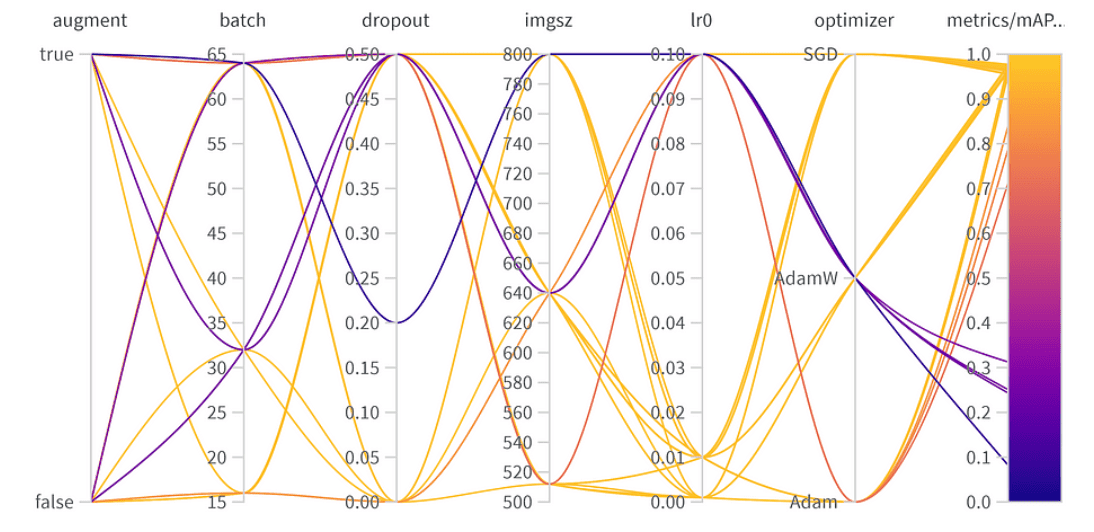
Ergebnisse der Hyperparameter-Optimierung
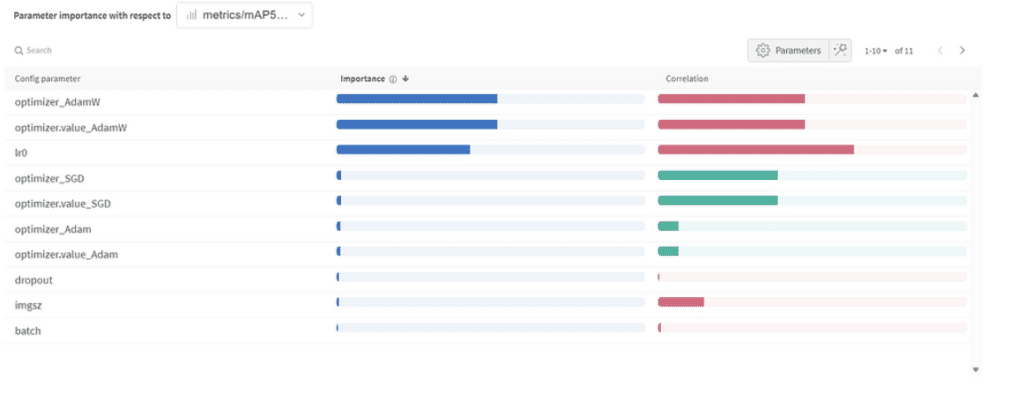
Wichtigkeit und Korrelation der Hyperparameter
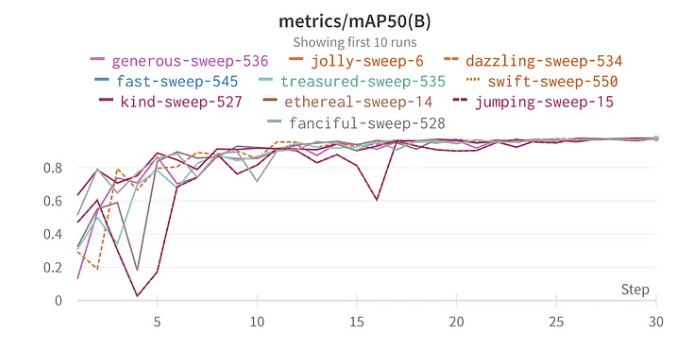
Top 10 mAP50 Ergebnisse YoloV8
Wichtigkeit der Parameter:
- Optimizer (AdamW): Mit einer Wichtigkeit von 0,521 und einer negativen Korrelation deutet dies darauf hin, dass AdamW die Leistung erheblich beeinflussen kann, jedoch nicht immer positiv.
- Lernrate (lr0): Hohe Wichtigkeit (0,433) und eine negative Korrelation (-0,634) deuten darauf hin, dass eine niedrigere Lernrate für unsere Aufgabe besser sein könnte.
- Andere: Optimierer wie SGD & Adam und Parameter wie Dropout, Bildgröße und Batchgröße zeigen eine minimale Wichtigkeit, was auf ihren geringeren Einfluss auf die Leistung unseres Modells hindeutet.
Endgültige Hyperparameter:
Die beste Kombination der Hyperparameter ist wie folgt mit dem besten mAP50 von 0,9776 im Validierungsset:
- Augmentation: Das beste Modell hat die Datenaugmentation übersprungen, was auf ausreichende Datendiversität hinweist.
- Batchgröße: Wählte 64, um Recheneffizienz und Modellleistung auszubalancieren.
- Dropout: Eine Rate von 0 deutet darauf hin, dass das Modell diese Regularisierung nicht benötigte.
- Bildgröße: 640 ist der optimale Wert für unsere Aufgabe.
- Lernrate: Hat sich für 0,001 entschieden, in Übereinstimmung mit unserer früheren Beobachtung, dass niedrigere Raten vorteilhaft sind.
- Optimizer: Interessanterweise wurde, obwohl AdamW wichtig zu sein schien, Adam in der besten Kombination gewählt. Dies erinnert daran, dass Hyperparameter oft miteinander verbundene Effekte haben.
Eine Balance finden: Höchstleistung vs. Allgemeingültigkeit
Während das beste mAP50, das in unserem Validierungsset erzielt wurde, 0,9776 betrug, gab es eine andere Konfiguration mit einem nahezu gleichen mAP50 von 0,9761. Dieses „Zweitplatzierungs“-Modell unterscheidet sich insbesondere dadurch, dass es Datenaugmentation nutzte und eine Dropout-Rate von 0,5 hatte. Angesichts des geringen Rückgangs beim mAP50 (nur 0,0015) könnte es vorteilhaft sein, dieses Modell in Einsatzszenarien zu bevorzugen, insbesondere wenn wir eine Vielzahl von Situationen erwarten, in denen das Modell eingesetzt wird. Die minimale Kompromisse bei der sofortigen Leistung könnten durch die erhöhte Fähigkeit des Modells, zu verallgemeinern, aufgewogen werden.
Schlussfolgerung
Hyperparameter-Optimierung kann die Leistung Ihres Modells erheblich steigern. Mit Werkzeugen wie W&B und Methoden wie der Bayesschen Optimierung wird dieser Prozess systematisch und aufschlussreich. Während einige Parameter wie der Optimierer und die Lernrate entscheidend sind, haben andere einen geringen Einfluss. Dies betont die Notwendigkeit einer aufgabenbezogenen Feinabstimmung statt allgemeiner Best Practices im Deep Learning. Bei der Implementierung eines Modells ist es unerlässlich, die Vor- und Nachteile zwischen Höchstleistung bei der Validierung und Robustheit in unterschiedlichen realen Situationen abzuwägen. In einigen Fällen könnte ein Modell mit etwas geringerer Validierungsgenauigkeit, aber besserer Allgemeingültigkeit aufgrund von Regularisierung die bessere Wahl sein. Experimentieren, unterstützt durch Daten, ist der Schlüssel!