
Optimización de Hiperparámetros para YOLOv8 con Weights & Biases: Una aventura con algoritmos de detección de objetos.
Introducción
Al trabajar con tareas de detección de objetos, es crucial que tu modelo funcione de manera óptima. Esto implica seleccionar los hiperparámetros adecuados. En esta entrada del blog, te guiaré a través de mi experiencia en la optimización de hiperparámetros para el modelo de detección de objetos YOLOv8 usando Weights & Biases (W&B) y el método de Optimización Bayesiana.
Por Justas Andriuškevičius – Ingeniero de Aprendizaje Automático en visionplatform.ai
¿Por qué Optimizar Hiperparámetros?
Cada modelo de aprendizaje automático viene con su conjunto de ajustes – hiperparámetros. Seleccionar la combinación correcta puede marcar la diferencia entre un modelo promedio y uno de alto rendimiento. Pero, con innumerables combinaciones posibles, ¿cómo elegir? Ahí es donde entra en juego la optimización de hiperparámetros, y específicamente W&B.
Selección del Conjunto de Datos
Antes de adentrarnos en los hiperparámetros, hablemos de la selección del conjunto de datos. La optimización de hiperparámetros es una tarea que consume muchos recursos. Llevarlo a cabo en un conjunto completo de datos llevaría muchísimo tiempo, y seamos realistas, nadie tiene tiempo para eso, especialmente cuando se trata de grandes conjuntos de datos.
Para encontrar un equilibrio entre la eficiencia computacional y un conjunto de datos representativo, adopté un enfoque inteligente. Dado un gran conjunto de datos con imágenes en orden cronológico, seleccioné un subconjunto ordenándolas por marca temporal, que es solo 1/4 del conjunto original. Este método garantiza que el modelo se entrene en datos diversos, abarcando escenas diurnas y nocturnas, esencial para una tarea de detección de objetos. Al mismo tiempo, este método reduce significativamente el tiempo de cómputo en comparación con el uso del conjunto completo. Para la evaluación, me mantuve con el conjunto de validación original, ya que proporciona una evaluación más completa e imparcial del rendimiento del modelo en datos no vistos, y ya es solo una fracción del tamaño del conjunto original de entrenamiento.
El Modelo YOLOv8 y Sus Hiperparámetros
El modelo YOLOv8 (You Only Look Once) es favorito en tareas de detección de objetos debido a su eficiencia. Varios hiperparámetros influyen en su rendimiento:
- Tamaño del lote (batch): Determina la cantidad de muestras procesadas antes de que el modelo actualice sus pesos.
- Tamaño de imagen (imgsz): Afecta la resolución de las imágenes introducidas en el modelo.
- Tasa de aprendizaje (lr0): Controla cuánto ajustar el modelo en respuesta al error estimado cada vez que se actualizan los pesos del modelo.
- Optimizador: Influye en cómo el modelo actualiza sus pesos.
- Aumento (augment): Indica si introducir cambios aleatorios en los datos de entrada, aumentando la robustez del modelo.
- Abandono (dropout): Es una técnica de regularización para prevenir el sobreajuste.
¿Por qué Optimización Bayesiana?
Elegir los hiperparámetros adecuados puede sentirse como buscar una aguja en un pajar. La optimización bayesiana hace esta búsqueda más inteligente. Imagina que intentas obtener la puntuación más alta en un juego. En lugar de probar al azar cada movimiento posible (¡que podría llevar una eternidad!), la optimización bayesiana observa tus movimientos anteriores, aprende de ellos y sugiere inteligentemente el siguiente mejor movimiento. Equilibra entre probar movimientos probados (explotación) y experimentar con nuevos (exploración).
¿Por qué Maximizar mAP50?
mAP50 significa Precisión Media Promedio con un IoU de 0.5. En términos simples, evalúa cuán bien las cajas delimitadoras predichas por nuestro modelo se superponen con las cajas delimitadoras reales. Maximizar mAP50 significa que nuestro modelo no solo está detectando objetos, sino que también está ubicándolos con precisión. Debido a que el objetivo es detectar tipos de vehículos durante el día, la noche y en condiciones climáticas adversas, asegurar un alto mAP50 es aún más crucial. No se trata solo de detectar vehículos, sino de asegurarse de que sean reconocidos con precisión en escenarios variados y desafiantes. ¿Por qué elegí maximizar mAP50 sobre mAP50-95? Al entrenar nuestro modelo por primera vez con hiperparámetros predeterminados, observé que mAP50 alcanzó su valor óptimo alrededor de la marca de 30 épocas, mientras que mAP50-95 tomó más tiempo, estabilizándose solo alrededor de 50 épocas. Notablemente, un alto mAP50 a menudo indicaba un mAP50-95 igualmente alto. Dado este comportamiento, para fines de optimización de hiperparámetros, elegí centrarme en maximizar mAP50. Este enfoque nos permite acortar cada evaluación, permitiendo una exploración más eficiente de diversas combinaciones de parámetros.
Usando W&B para la Optimización de Hiperparámetros
La funcionalidad de barrido de W&B simplifica el proceso de optimización. Configuré el barrido usando el método bayesiano para buscar los mejores hiperparámetros. Curiosamente, elegí 30 épocas para la formación porque, en mis pruebas iniciales con el conjunto completo de datos, el modelo comenzó a mostrar signos de rendimiento óptimo alrededor de esta marca.
Resultados e Implicaciones
Profundizando en los resultados de la optimización de hiperparámetros, se revelan importantes conclusiones:
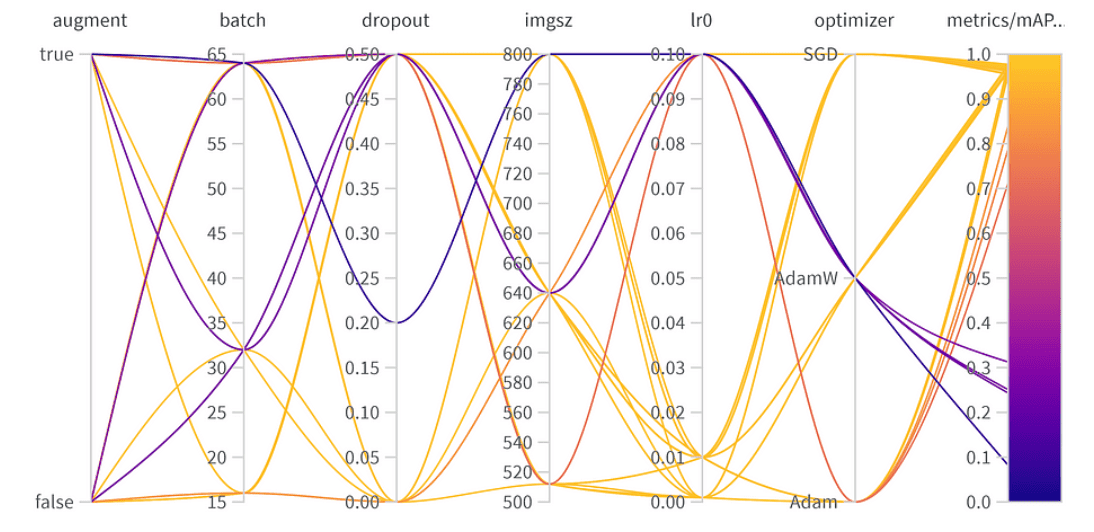
Resultados de optimización de hiperparámetros
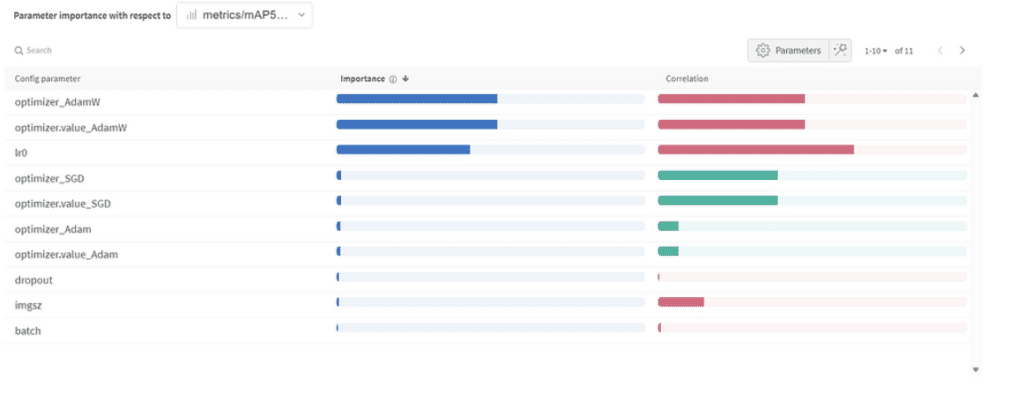
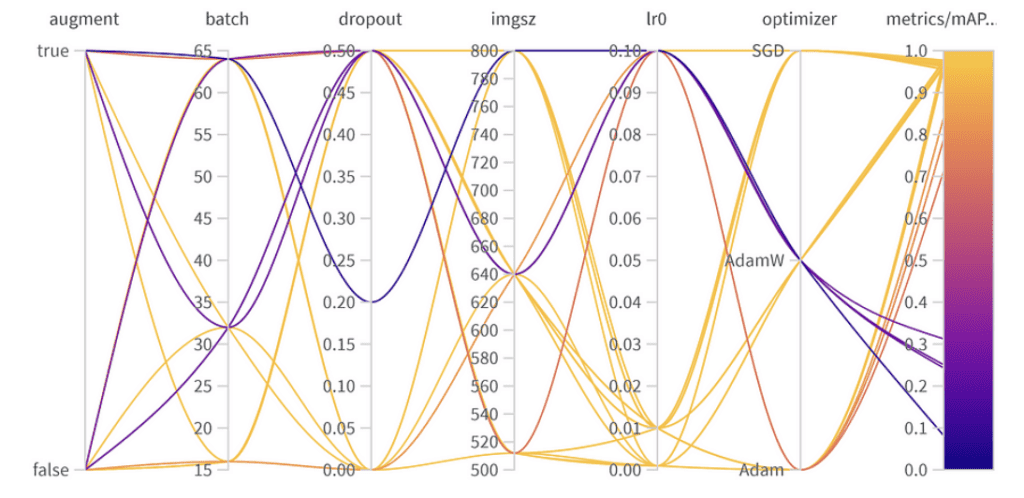
Importancia y correlación de hiperparámetros
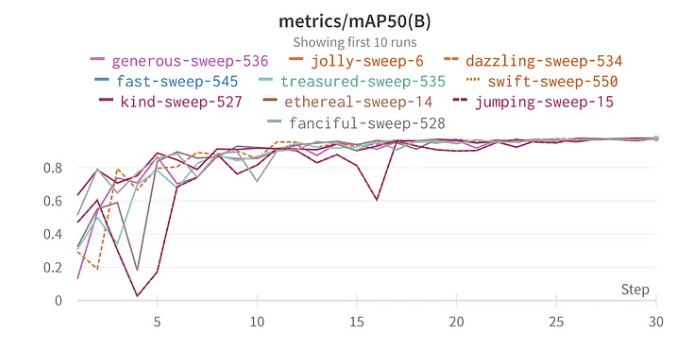
los 10 mejores resultados mAP50 de YoloV8
Importancia de parámetros:
- Optimizador (AdamW): Con una importancia de 0.521 y una correlación negativa, sugiere que AdamW puede impactar significativamente en el rendimiento, pero no siempre de manera positiva.
- Tasa de aprendizaje (lr0): Alta importancia (0.433) y una correlación negativa (-0.634) insinúan que una tasa de aprendizaje más pequeña podría ser mejor para nuestra tarea.
- Otros: Optimizadores como SGD & Adam, y parámetros como abandono (dropout), tamaño de imagen y tamaño del lote muestran una importancia mínima, indicando su menor influencia en el rendimiento de nuestro modelo.
Hiperparámetros finales:
La mejor combinación de hiperparámetros es la siguiente, con el mejor mAP50 de 0.9776 en el conjunto de validación:
- Aumento de datos (Augmentation): El mejor modelo omitió el aumento de datos, indicando suficiente diversidad de datos.
- Tamaño del lote: Eligieron 64, equilibrando la eficiencia computacional y el rendimiento del modelo.
- Abandono (Dropout): Una tasa de 0, sugiriendo que el modelo no necesitaba esta regularización.
- Tamaño de imagen: 640 es el punto óptimo para nuestra tarea.
- Tasa de aprendizaje: Optaron por 0.001, en línea con nuestra observación anterior sobre que las tasas más bajas son beneficiosas.
- Optimizador: Curiosamente, aunque AdamW parecía importante, Adam fue elegido en la mejor combinación. Es un recordatorio de que los hiperparámetros a menudo tienen efectos interconectados.
Encontrando un equilibrio: Máximo rendimiento vs. Generalización
Aunque el mejor mAP50 logrado en nuestro conjunto de validación fue de 0.9776, había otra configuración con un mAP50 cercano de 0.9761. Este modelo «subcampeón» difiere notablemente en que empleó el aumento de datos y utilizó una tasa de abandono de 0.5. Considerando la ligera caída en mAP50 (una mera diferencia de 0.0015), podría ser beneficioso favorecer este modelo en escenarios de despliegue, especialmente si anticipamos una amplia gama de situaciones que el modelo enfrentará. El mínimo compromiso en el rendimiento inmediato podría ser compensado por la mejor capacidad del modelo para generalizar.
Conclusión
La optimización de hiperparámetros puede mejorar significativamente el rendimiento de tu modelo. Con herramientas como W&B y métodos como la optimización bayesiana, este proceso se vuelve sistemático y revelador. Mientras que algunos parámetros como el optimizador y la tasa de aprendizaje son cruciales, otros tienen un impacto menor. Esto enfatiza la necesidad de una sintonización específica para la tarea en lugar de las mejores prácticas generales de aprendizaje profundo. Al desplegar un modelo, es esencial ponderar las compensaciones entre el rendimiento máximo de validación y la robustez en variadas situaciones del mundo real. En algunos casos, un modelo con una precisión de validación ligeramente menor pero mejor generalización debido a la regularización podría ser la mejor opción. ¡Experimentar respaldado por datos es clave!