
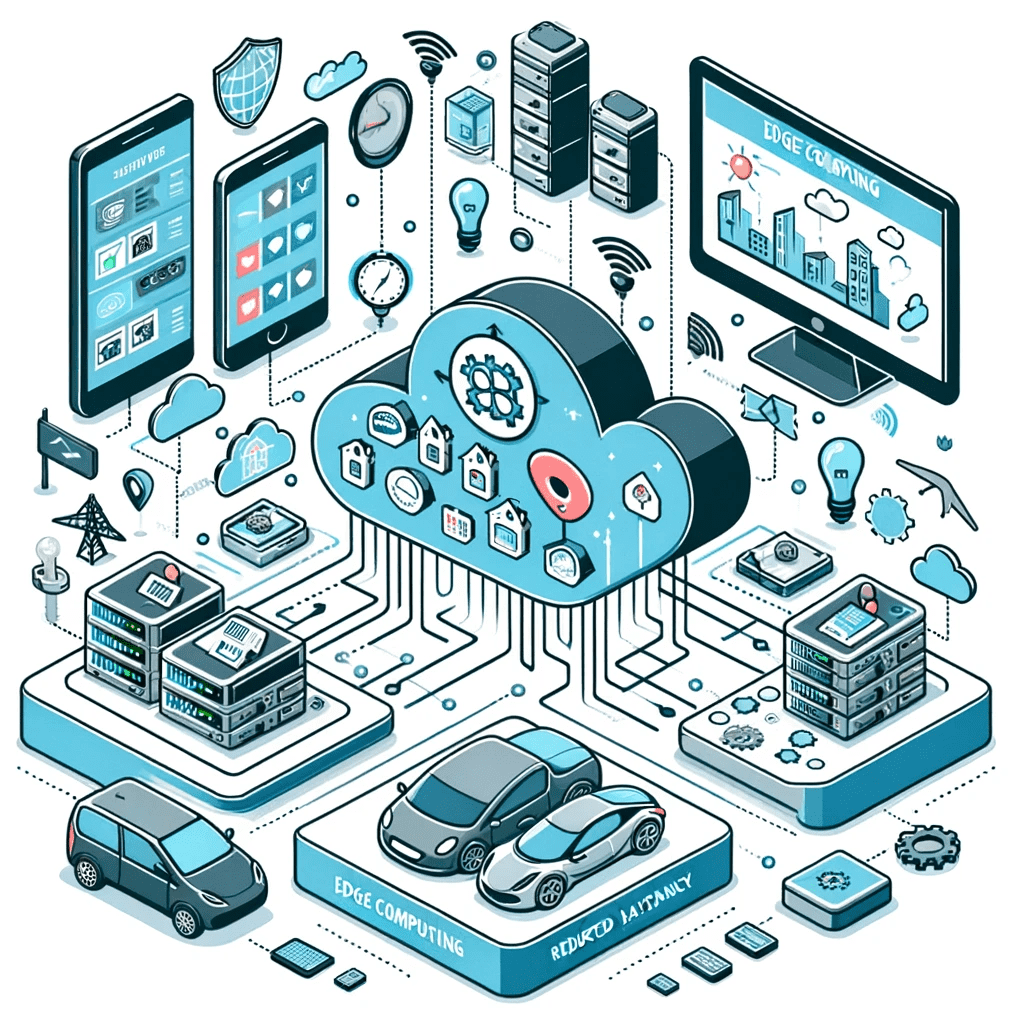
Introduction à l’informatique en périphérie et au réseau Edge 5G
Introduction à l’informatique en périphérie et au réseau Edge 5G
Dans le monde de la technologie en rapide évolution, l’informatique en périphérie a émergé comme une force transformatrice, particulièrement lorsqu’elle est intégrée à la puissance des milliers de réseaux 5G. Au cœur de l’informatique en périphérie, il s’agit de traiter les données plus près de la source de génération des données, plutôt que de dépendre d’un entrepôt centralisé de traitement des données. Ce changement dans la méthodologie de traitement des données apporte une multitude d’avantages, notamment en améliorant les capacités des technologies de réseau en périphérie.
L’intégration de l’informatique en périphérie avec la technologie 5G marque un bond en avant significatif. Les réseaux 5G, connus pour leur haute vitesse et leur faible latence, complètent parfaitement l’informatique en périphérie. Cette combinaison est essentielle pour réaliser le plein potentiel des appareils Internet des objets (IoT) et des applications intelligentes. En traitant les données plus près de leur lieu de génération, l’informatique en périphérie réduit considérablement la latence souvent rencontrée dans les modèles traditionnels de cloud computing. L’informatique en périphérie est une exigence de réseau cruciale dans les applications nécessitant un traitement en temps réel et des temps de réponse rapides, tels que les véhicules autonomes ou l’analyse en temps réel.
De plus, la synergie entre l’informatique en périphérie et la 5G ouvre de nouveaux horizons dans divers secteurs. Des industries telles que la santé, la fabrication et le développement urbain sont témoins d’une transformation, car l’informatique en périphérie permet de gérer efficacement et efficacement d’énormes quantités de données générées par de nombreux appareils IoT. Par exemple, dans les villes intelligentes, l’informatique en périphérie peut traiter les données des capteurs en temps réel dans un environnement d’informatique en périphérie, améliorant la gestion du trafic et l’efficacité énergétique.
De plus, l’informatique en périphérie améliore la sécurité et la confidentialité, car les données sensibles peuvent être traitées localement, réduisant les risques associés au transfert de données sur de longues distances. Cet aspect est particulièrement vital dans des scénarios où la confidentialité des données est primordiale, comme dans les services de santé et financiers, et où l’informatique en périphérie est une nécessité de réseau.
Les avantages du calcul en périphérie dans les réseaux modernes
L’environnement de calcul en périphérie apporte une multitude d’avantages qui redéfinissent les architectures de réseau modernes. Premièrement, il réduit considérablement la latence dans le traitement des données. En rapprochant le calcul de la source de données, le calcul en périphérie minimise le délai entre l’acquisition des données et leur traitement, un facteur critique pour les applications qui dépendent de la prise de décision en temps réel.
Cette réduction de la latence n’est pas seulement bénéfique pour la vitesse ; elle améliore également l’efficacité globale des réseaux. Dans les modèles traditionnels de calcul et de calcul en nuage, les données doivent être envoyées vers et depuis un centre de données centralisé, ce qui peut être à la fois chronophage et consommateur de bande passante. Le calcul en périphérie, en revanche, soulage cette contrainte sur les ressources réseau en traitant les données localement, réduisant ainsi le besoin de transmission de données à longue distance.
Un autre avantage clé du calcul en périphérie, expliqué en termes d’impact sur la sécurité des données et la confidentialité dans un environnement de calcul en périphérie. Avec les données traitées plus près de leur source, l’exposition aux violations de sécurité potentielles pendant le transit est minimisée. Ce traitement local signifie que les informations sensibles n’ont pas à traverser plusieurs réseaux, réduisant ainsi la vulnérabilité aux cyberattaques et aux fuites de données.
De plus, le calcul en périphérie offre une évolutivité et une flexibilité accrues dans la gestion de l’afflux croissant de données provenant des appareils IoT, un exemple de calcul en périphérie, peut traiter et stocker des données à la périphérie, réduisant considérablement la latence. Il permet de gérer efficacement les données à grande échelle sans compromettre les performances, un aspect crucial pour les entreprises qui traitent d’énormes quantités de données quotidiennement.
En outre, le calcul en périphérie permet de réaliser des économies pour les entreprises. En réduisant le besoin pour les données de voyager aller-retour vers le cloud, il y a une diminution significative de la quantité de données qui doivent être envoyées sur le réseau, conduisant à une utilisation moindre de la bande passante et, par conséquent, à une réduction des coûts opérationnels.
Enfin, le calcul en périphérie a le potentiel de jouer un rôle vital dans l’assurance de la continuité des affaires et de la robustesse de l’infrastructure réseau. Dans un environnement de calcul en périphérie où la connectivité réseau est intermittente ou peu fiable, le calcul en périphérie peut traiter les données critiques localement, garantissant que les opérations ne sont pas interrompues en raison de problèmes de connectivité. Cela est particulièrement important dans les environnements éloignés ou industriels où une connectivité cloud constante ne peut être garantie.
En résumé, l’avènement du calcul en périphérie, notamment en conjonction avec la technologie 5G, annonce une nouvelle ère dans le domaine de la transformation numérique. Sa capacité à traiter les données rapidement et en toute sécurité à la périphérie du réseau, couplée à la réduction de la latence et de l’utilisation de la bande passante, positionne le calcul en périphérie comme une technologie pivot dans les architectures de réseau modernes. À mesure que nous avançons, l’intégration du calcul en périphérie avec la 5G est prête à débloquer des niveaux sans précédent d’efficacité et d’innovation dans de multiples industries.
Cas d’utilisation de l’informatique en périphérie dans diverses industries
L’informatique en périphérie transforme les industries en offrant des solutions adaptées à divers scénarios. Dans le secteur de la santé, l’informatique en périphérie permet une surveillance des patients en temps réel et une analyse rapide des données, essentielles pour les environnements de soins critiques. Le secteur manufacturier bénéficie d’une efficacité accrue des lignes de production, où les dispositifs en périphérie surveillent et ajustent instantanément les processus, réduisant les temps d’arrêt et améliorant la qualité des produits. Le secteur du commerce de détail connaît une transformation grâce à la gestion intelligente des stocks et à la personnalisation de l’expérience client, grâce aux capacités de traitement rapide des données de l’informatique en périphérie.
L’industrie automobile, notamment dans le domaine des véhicules autonomes, se présente comme un exemple frappant de l’impact de l’informatique en périphérie. L’informatique en périphérie pour les véhicules autonomes implique le traitement de vastes quantités de données de capteurs en déplacement pour prendre des décisions en une fraction de seconde, une tâche que l’informatique en nuage traditionnelle ne peut pas effectuer aussi efficacement. Ici, l’informatique en périphérie garantit la sécurité et améliore les systèmes de navigation.
De plus, les initiatives de ville intelligente mettent en œuvre des milliers d’applications en périphérie, utilisant l’informatique en périphérie pour gérer tout, du flux de circulation aux niveaux de pollution. Les capteurs et les dispositifs IoT à travers la ville collectent des données, traitées localement, permettant des réponses en temps réel à divers défis urbains. Cette approche améliore non seulement la gestion de la ville, mais aussi la qualité de vie des résidents.
Informatique en périphérie et IoT : une relation synergique
La synergie entre l’informatique en périphérie et l’IoT représente un bond significatif dans l’application technologique. Les dispositifs IoT génèrent d’énormes quantités de données. L’informatique en périphérie permet de traiter ces données à la limite du réseau, plus près de leur source, ce qui réduit la latence et l’utilisation de la bande passante. Cette capacité est essentielle pour les dispositifs IoT nécessitant un traitement en temps réel, comme ceux utilisés dans l’automatisation industrielle, où une réponse immédiate aux données des capteurs peut prévenir les pannes d’équipement et les accidents.
L’informatique mobile en périphérie, un sous-ensemble de l’informatique en périphérie, améliore encore les applications IoT dans les scénarios mobiles. Par exemple, lors de grands événements tels que des sports ou des concerts, l’informatique mobile en périphérie peut traiter les données de milliers de dispositifs, offrant un streaming et une connectivité sans interruption.
En agriculture, l’informatique en périphérie et l’IoT se combinent pour optimiser les pratiques agricoles. Les capteurs collectent des données sur les conditions du sol, la météo et la santé des cultures, que les dispositifs d’informatique en périphérie traitent localement. Cette analyse en temps réel aide à prendre des décisions éclairées concernant l’irrigation, la fertilisation et la récolte, conduisant à une augmentation des rendements des cultures et à une réduction du gaspillage des ressources.
Le modèle de calcul distribué de l’informatique en périphérie garantit que ces industries ne dépendent pas uniquement de serveurs cloud distants. Au lieu de cela, elles bénéficient d’une puissance de traitement localisée, rapprochant l’informatique de là où elle est le plus nécessaire. En conséquence, l’informatique en périphérie offre un paradigme de calcul plus efficace, particulièrement bénéfique pour les secteurs où la prise de décision en une fraction de seconde est cruciale.
En résumé, la capacité de l’informatique en périphérie à travailler à la limite, couplée à l’IoT, introduit une approche révolutionnaire dans le traitement des données. L’application de l’informatique en périphérie à travers les industries démontre sa flexibilité et sa capacité à relever des défis uniques, faisant de l’informatique en périphérie un composant essentiel dans le paysage informatique moderne.
Travail de l’informatique en périphérie : Amélioration des opérations commerciales
Travail de l’informatique en périphérie : Amélioration des opérations commerciales
L’avènement de l’informatique en périphérie marque un tournant décisif dans la manière dont les entreprises abordent le traitement des données et l’efficacité opérationnelle. Ce paradigme informatique permet aux entreprises de traiter les données plus près de leur source, entraînant des améliorations significatives des temps de réponse et des économies de bande passante. En tirant parti de la technologie de l’informatique en périphérie, les entreprises peuvent gérer les volumes croissants de données produites par des milliards d’appareils de manière plus efficace.
L’un des principaux avantages de l’informatique en périphérie est sa capacité à améliorer le traitement des données en temps réel. Par exemple, dans le secteur du commerce de détail, l’informatique en périphérie peut traiter les données des clients sur site, permettant des mises à jour instantanées des stocks et des expériences client personnalisées. Cette immédiateté aide les entreprises à prendre des décisions plus éclairées rapidement, augmentant ainsi l’efficacité opérationnelle et la satisfaction des clients.
De plus, l’informatique en périphérie aide à réduire la latence associée à l’informatique en nuage. Cette réduction est particulièrement cruciale dans les industries où les millisecondes comptent, comme le trading financier ou les jeux en ligne. En traitant les données à la périphérie locale, ces industries peuvent exécuter des transactions et répondre aux actions des utilisateurs beaucoup plus rapidement que les configurations traditionnelles en nuage.
Un autre aspect significatif du travail en informatique en périphérie se trouve dans le domaine de la maintenance prédictive. Ici, les capteurs sur les équipements industriels peuvent envoyer des alertes immédiates aux serveurs de périphérie locaux pour analyse, prédisant les pannes potentielles avant qu’elles ne surviennent. Cette approche proactive minimise les temps d’arrêt et économise les coûts liés à la maintenance et aux réparations.
De plus, le modèle distribué de l’informatique en périphérie offre une résilience contre les problèmes de réseau. Dans un environnement d’informatique en périphérie, en traitant les données localement, les entreprises peuvent continuer leurs opérations même lorsque la connectivité au nuage est perdue ou peu fiable, assurant la continuité des affaires là où se déroule le traitement informatique.
Utiliser les services de calcul en périphérie : Élargir les horizons du cloud et de la périphérie
Les services de calcul en périphérie révolutionnent l’interaction entre les technologies du cloud et de la périphérie, créant une infrastructure informatique plus intégrée et efficace. Ces services permettent aux entreprises de déployer des solutions de calcul en périphérie qui fonctionnent de manière transparente avec les services cloud existants, offrant un modèle hybride qui exploite les forces du calcul en périphérie et du cloud.
Un domaine significatif où les services de calcul en périphérie excellent est dans la gestion de l’énorme quantité de données générées par les dispositifs IoT. En traitant ces données à la périphérie du réseau, seules les informations pertinentes doivent être envoyées au cloud, réduisant ainsi l’utilisation de la bande passante et les coûts. Cela est particulièrement bénéfique pour des industries comme l’agriculture, où les capteurs génèrent de grands volumes de données sur les conditions des cultures.
De plus, les services de calcul en périphérie mobile améliorent les capacités des réseaux mobiles, notamment avec le déploiement des réseaux 5G. Ces services rapprochent la puissance de calcul des utilisateurs mobiles, améliorant considérablement la vitesse et la fiabilité des applications et services mobiles.
Le calcul en périphérie cloud, un autre exemple de calcul en périphérie, connaît une croissance rapide. Cet aspect du calcul en périphérie rapproche la flexibilité et l’évolutivité du cloud computing là où les données sont générées. Il est particulièrement utile dans des scénarios comme les opérations minières à distance ou les activités maritimes, où la connectivité à un cloud central peut être limitée ou inexistante.
En outre, les services de calcul en périphérie ne sont pas limités aux grandes entreprises. Les petites et moyennes entreprises peuvent également tirer parti de ces services pour obtenir un avantage concurrentiel. En installant des dispositifs de calcul en périphérie et en utilisant des services de périphérie, ces entreprises peuvent traiter les données localement, améliorant leur efficacité opérationnelle et leur réactivité aux changements du marché.
En essence, l’utilisation des services de calcul en périphérie permet aux entreprises de créer des infrastructures informatiques plus résilientes, efficaces et adaptatives. Cette intégration du calcul en périphérie et du cloud n’est pas seulement une mise à niveau des systèmes existants, mais une réimagination complète de la manière dont le traitement des données et les services informatiques peuvent être livrés et utilisés dans un paysage numérique en rapide évolution.

Déploiement de l’informatique en périphérie : Approches et méthodologies
Déployer l’informatique en périphérie nécessite une approche stratégique pour garantir une intégration réussie dans les systèmes existants. Ce processus commence souvent par l’identification des cas d’utilisation spécifiques de l’informatique en périphérie au sein d’une organisation. Par exemple, une entreprise de fabrication pourrait déployer l’informatique en périphérie pour la surveillance en temps réel des machines, tandis qu’une entreprise de vente au détail pourrait l’utiliser pour améliorer l’expérience client en magasin. Chaque cas dicte un ensemble unique d’exigences pour le déploiement en périphérie.
La sélection des bonnes ressources informatiques constitue une partie cruciale de ce déploiement, surtout lorsque l’informatique en périphérie est souvent au centre des préoccupations. Selon les besoins, cela pourrait inclure des serveurs en périphérie capables de gérer les charges de travail d’IA, ou des nœuds en périphérie plus légers pour des tâches de traitement de données plus simples. Il est important d’équilibrer la puissance informatique avec l’efficacité énergétique, surtout dans les endroits éloignés où la disponibilité de l’énergie pourrait être une contrainte.
L’architecture réseau joue également un rôle clé dans le déploiement de l’informatique en périphérie, en définissant où se déroule le calcul. Cela implique la mise en place d’un réseau local en périphérie qui peut gérer efficacement le trafic de données généré par les dispositifs en périphérie. Dans les cas où la prise de décision en temps réel est critique, comme dans les véhicules autonomes, le réseau en périphérie doit offrir une latence ultra-faible, souvent facilitée par les réseaux 5G.
De plus, l’intégration de l’informatique en périphérie avec l’informatique en nuage permet une infrastructure plus flexible et évolutive. Ce modèle hybride permet de distribuer les tâches de données et de calcul entre la périphérie et le nuage, en fonction des exigences de bande passante et de latence.
L’importance du Edge Computing : Comprendre ses aspects fondamentaux
Comprendre les aspects fondamentaux du edge computing est essentiel pour exploiter pleinement son potentiel. Au cœur de celui-ci, le edge computing est un modèle de calcul distribué qui rapproche le traitement informatique de la source des données. Ce passage d’un calcul centralisé à un calcul distribué apporte de nombreux avantages, notamment dans les environnements comportant un grand nombre de dispositifs IoT.
L’une des caractéristiques clés du edge computing est sa capacité à traiter et analyser les données localement, à la périphérie du réseau. Cela réduit considérablement la quantité de données devant être envoyées au cloud, minimisant ainsi la latence et l’utilisation de la bande passante. Cela améliore également la confidentialité et la sécurité des données, car les données sensibles peuvent être traitées sur site sans être transmises sur de longues distances.
La technologie du edge computing évolue continuellement, avec de nouveaux développements dans l’intelligence artificielle dans un environnement de edge computing et le cloud computing mobile. Ces avancées augmentent la puissance de calcul disponible à la périphérie, permettant de réaliser des traitements et des analyses de données plus complexes.
De plus, la scalabilité du edge computing est un facteur crucial pour les entreprises. Elle leur permet de commencer avec un déploiement petit et d’augmenter la taille selon leurs besoins. Cette scalabilité est soutenue par la nature modulaire des systèmes de edge computing, qui peuvent être étendus avec des nœuds périphériques supplémentaires au besoin.
En résumé, le edge computing offre un moyen flexible, efficace et sécurisé de traiter les données, ce qui en fait une partie importante de l’infrastructure informatique moderne. Sa capacité à rapprocher la puissance de calcul de l’endroit où les données sont générées en fait une solution idéale pour une large gamme d’applications, des IoT industriels aux villes intelligentes et au-delà. Comprendre ces aspects fondamentaux est vital pour toute organisation cherchant à mettre en œuvre des stratégies de edge computing réussies.
Comparaison entre le Fog Computing et le Edge Computing : Une étude comparative
Le fog computing et le edge computing sont des technologies étroitement liées mais distinctes au sein du paradigme du calcul distribué. Les deux visent à rapprocher le calcul de la source des données, mais ils fonctionnent de manière légèrement différente et répondent à différents cas d’utilisation.
Le fog computing est souvent décrit comme une extension du cloud computing, fournissant des services de stockage et de calcul entre les dispositifs finaux et les serveurs cloud traditionnels. Il crée une infrastructure de calcul décentralisée, ce qui peut entraîner un traitement, un stockage et une analyse des données plus efficaces. Cela est particulièrement bénéfique dans les scénarios avec des dispositifs IoT répartis sur une vaste zone géographique. La couche de brouillard offre un terrain d’entente pour le traitement des données, ce qui peut réduire le besoin de transmission de données à longue distance vers le cloud, améliorant ainsi l’efficacité globale et réduisant la latence.
Le edge computing, en revanche, pousse la frontière des services de calcul jusqu’au bord même du réseau, plus près des sources de données comme les dispositifs IoT. Le edge computing permet le traitement des données, se produisant à la limite, immédiatement à ou près de la source de génération des données. Cela est crucial dans les situations où le traitement des données en temps réel est critique, comme dans les véhicules autonomes, l’automatisation industrielle ou l’infrastructure des villes intelligentes.
Alors que le fog computing offre un contrôle plus centralisé et peut gérer des tâches plus intensives en données que le edge computing, le edge computing excelle dans le traitement des données en temps réel et réduit la dépendance à une connexion Internet constante. Les deux technologies se complètent et peuvent être utilisées simultanément dans un cadre de calcul distribué pour optimiser les réseaux et les applications IoT.
Informatique en nuage et informatique en périphérie : Technologies complémentaires
La relation entre l’informatique en nuage et l’informatique en périphérie est une pierre angulaire du paysage informatique moderne. L’informatique en nuage a été le modèle informatique principal pour les entreprises, offrant des serveurs centralisés puissants et d’énormes capacités de stockage. Cependant, avec l’avènement de l’IoT et la prolifération de milliards d’appareils générant des données, les limitations de l’informatique en nuage en termes de latence et de bande passante sont devenues évidentes, bien que l’informatique en périphérie ait le potentiel de surmonter de telles limitations.
L’informatique en périphérie émerge comme une solution à ces défis en traitant les données à la périphérie du réseau, plus près de là où elles sont générées. Cette approche, fournie par les moyens de l’informatique en périphérie, réduit la quantité de données qui doivent être envoyées au nuage pour traitement, minimisant ainsi la latence et l’utilisation de la bande passante. L’informatique en périphérie est particulièrement efficace dans les cas d’utilisation qui nécessitent une analyse et une prise de décision en temps réel, où l’envoi de données à un serveur nuage distant et leur retour serait trop long.
Cependant, l’informatique en périphérie ne remplace pas l’informatique en nuage ; elle la complète plutôt. Alors que l’informatique en périphérie gère le traitement des données en temps réel et l’analyse immédiate, l’informatique en nuage reste essentielle pour le stockage des données à long terme, l’analyse complète et la référence des données historiques. En tirant parti à la fois de l’informatique en nuage et de l’informatique en périphérie, les entreprises peuvent profiter des avantages des deux : la puissance de traitement en temps réel de l’informatique en périphérie et les capacités de stockage étendues et d’analyse avancée du nuage.
Ensemble, l’informatique en nuage et l’informatique en périphérie créent une infrastructure informatique plus robuste, flexible et efficace, permettant aux entreprises d’optimiser leurs opérations pour l’ère numérique. Cette approche hybride est particulièrement pertinente dans les scénarios de périphérie d’entreprise, où les entreprises opèrent sur plusieurs sites et nécessitent à la fois des capacités de traitement et de stockage de données locales et centralisées.
L’avenir de la technologie de l’informatique en périphérie
L’avenir de la technologie de l’informatique en périphérie est prêt pour une croissance significative et une transformation, stimulée par la demande croissante pour le traitement des données en temps réel et la prolifération des appareils IoT. Alors que des milliards d’appareils continuent de se connecter à Internet, générant d’énormes quantités de données, le besoin d’informatique en périphérie devient de plus en plus important. Cette croissance est soutenue par les avancées dans les dispositifs d’informatique en périphérie, l’intelligence artificielle en périphérie et l’informatique en nuage mobile, améliorant la puissance de calcul disponible à la périphérie du réseau.
Dans le domaine des systèmes autonomes, l’informatique en périphérie est particulièrement cruciale. Par exemple, l’informatique en périphérie permet le traitement des données dans les véhicules autonomes, où les données des capteurs sont traitées à la volée pour prendre des décisions instantanées, une nécessité pour un fonctionnement sûr et efficace. Cela illustre un exemple parfait du potentiel de l’informatique en périphérie dans la gestion des tâches critiques en temps réel.
De plus, l’intégration de l’informatique en périphérie avec les réseaux 5G est prête à débloquer de nouvelles possibilités. Les capacités de large bande et de faible latence du 5G complètent le modèle d’informatique en périphérie, permettant un traitement des données et des temps de réponse encore plus rapides. Cette synergie est vitale dans des industries telles que la télémédecine, la fabrication intelligente et la réalité augmentée, où le traitement immédiat des données est critique.
En outre, le paysage en évolution de l’informatique en périphérie verra émerger des cas d’utilisation plus sophistiqués, notamment à mesure que les applications en périphérie deviennent plus avancées. L’informatique en périphérie devrait jouer un rôle significatif dans les initiatives de villes intelligentes, l’IoT industriel et l’informatique en périphérie pour les soins de santé, où la capacité de traiter les données localement peut conduire à des services plus réactifs et efficaces.
Conclusion : Le rôle intégral des stratégies de périphérie
En conclusion, l’informatique en périphérie n’est pas juste une tendance éphémère ; c’est un changement fondamental dans l’infrastructure informatique qui répond aux limitations des modèles basés sur le cloud traditionnels. Les caractéristiques de l’informatique en périphérie – sa capacité à traiter les données plus près de la source, à réduire la latence et à gérer la charge croissante des appareils IoT – en font une technologie indispensable pour l’avenir.
Les stratégies réussies en informatique en périphérie dépendront de la compréhension des besoins spécifiques de différents cas d’utilisation et du déploiement des solutions de périphérie appropriées. Alors que les entreprises continuent d’adopter la transformation numérique, le rôle de l’informatique en périphérie deviendra plus intégral. Les entreprises doivent rester informées des derniers développements en technologie de périphérie et être prêtes à intégrer des solutions de périphérie dans leur infrastructure informatique existante.
Le voyage vers un cadre informatique plus distribué est bien en cours, et l’informatique en périphérie est à l’avant-garde. En regardant vers l’avenir, le potentiel de l’informatique en périphérie pour révolutionner les industries et améliorer notre quotidien devient de plus en plus évident. Par conséquent, apprendre sur l’informatique en périphérie et rester à jour sur ses avancées est crucial pour toute entreprise cherchant à exploiter la puissance de la technologie moderne.
FAQ : Lever du voile sur les mystères du calcul en périphérie
Dans le monde de la technologie en rapide évolution, le calcul en périphérie émerge comme une pierre angulaire, révolutionnant la manière dont les données sont traitées et gérées. Cette section FAQ vise à démystifier le calcul en périphérie, en fournissant des réponses claires et concises aux questions courantes et en éclairant sur la manière dont il transforme les industries. Plongez dans les fondamentaux du calcul en périphérie et découvrez son impact sur le paysage numérique.
Qu’est-ce que le calcul en périphérie ?
Le calcul en périphérie est une architecture informatique où le traitement des données est effectué à l’emplacement périphérique du réseau, plus proche de la source des données. Cette approche réduit considérablement la latence et l’utilisation de la bande passante par rapport au calcul en nuage centralisé traditionnel. En traitant les données en périphérie près de leur origine, le calcul en périphérie peut aider à la prise de décision en temps réel et à la gestion efficace des données.
Comment fonctionne le calcul en périphérie ?
Dans le calcul en périphérie, le calcul et le stockage se produisent à ou près de l’endroit où les données sont générées, plutôt que d’être envoyés vers des serveurs cloud distants. Cette proximité avec la source de données permet des temps de réponse plus rapides et moins de contraintes sur les ressources réseau. En décentralisant l’architecture informatique, le calcul en périphérie rapproche la charge de travail de l’utilisateur final dans un environnement de calcul en périphérie, améliorant l’efficacité et réduisant la latence.
Quels sont les principaux avantages du calcul en périphérie ?
Les principaux avantages du calcul en périphérie incluent la réduction de la latence, la minimisation des coûts de bande passante, l’amélioration de la confidentialité et de la sécurité, et une meilleure gestion des données. En traitant les données localement, le calcul en périphérie peut aider à réduire le temps nécessaire pour que les données voyagent, accélérant ainsi les temps de réponse. De plus, le calcul en périphérie aide à gérer de manière plus efficace les grandes charges de données, ce qui le rend idéal pour les environnements IoT et les applications qui exigent un traitement rapide des données.
Quels sont quelques cas d’utilisation courants pour le calcul en périphérie ?
Les cas d’utilisation courants du calcul en périphérie impliquent des scénarios où un traitement rapide des données est crucial. Cela inclut les applications IoT, les villes intelligentes, la surveillance de la santé et l’automatisation industrielle. Dans l’IoT, par exemple, le calcul en périphérie permet une analyse en temps réel des données des capteurs. Dans le domaine de la santé, il prend en charge le traitement immédiat des données des patients, et dans la fabrication, le calcul en périphérie aide à la maintenance prédictive et à l’efficacité opérationnelle. Le besoin que le calcul en périphérie adresse est le plus évident dans les applications nécessitant une analyse et une réponse instantanées aux données.
Comment le calcul en périphérie interagit-il avec les appareils IoT ?
L’architecture de calcul en périphérie améliore les appareils IoT en traitant les données localement, réduisant la latence et améliorant les temps de réponse. Pour les appareils IoT, qui devraient atteindre 75 milliards d’ici 2025, le calcul en périphérie est crucial pour gérer efficacement les données qu’ils génèrent. Ce traitement local à l’emplacement périphérique signifie que les appareils IoT peuvent fonctionner de manière plus autonome, réduisant le besoin de connectivité cloud constante et permettant une prise de décision et une action plus rapides.
Quel rôle joue la 5G dans le calcul en périphérie ?
Les réseaux 5G jouent un rôle transformateur dans le calcul en périphérie en fournissant une connectivité à haute vitesse et à faible latence qui complète l’architecture en périphérie. Avec la capacité de la 5G atteignant des vitesses allant jusqu’à 10 Gbps, le calcul en périphérie peut aider à traiter et analyser les données en temps réel. Cette synergie est particulièrement cruciale dans des applications comme les véhicules autonomes et les villes intelligentes, où un traitement et une action immédiats des données sont essentiels.
Quelle est la différence entre le calcul dans le brouillard et le calcul en périphérie ?
Le calcul dans le brouillard est un modèle de calcul distribué qui étend le calcul en nuage jusqu’à la périphérie du réseau. Bien que le calcul dans le brouillard et le calcul en périphérie impliquent tous deux un traitement des données plus proche de leur source, le calcul dans le brouillard opère à un niveau de réseau plus élevé, offrant un traitement et un contrôle plus centralisés. En revanche, le calcul en périphérie déplace le traitement directement sur les appareils à la périphérie du réseau, permettant une prise de décision et des temps de réponse encore plus rapides.
Comment les entreprises mettent-elles en œuvre des stratégies de calcul en périphérie ?
Les entreprises mettent en œuvre des stratégies de calcul en périphérie en identifiant les applications où un traitement des données en temps réel est critique. Cela implique le déploiement de systèmes de calcul en périphérie à des emplacements pertinents, leur intégration avec l’infrastructure informatique existante, et l’assurance d’un flux de données transparent entre les dispositifs en périphérie et les serveurs centraux. Une mise en œuvre réussie comprend souvent la mise à niveau des capacités réseau pour gérer la puissance de calcul accrue et le trafic de données que le calcul en périphérie apporte.
Quelles sont les implications en matière de sécurité du calcul en périphérie ?
Le calcul en périphérie améliore la sécurité en traitant les données localement, réduisant l’exposition des informations sensibles pendant la transmission. Le traitement local des données signifie moins de données transférées sur Internet, réduisant ainsi le risque de violations de données. Cependant, l’augmentation du nombre d’appareils en périphérie élargit également la surface d’attaque potentielle. Par conséquent, la mise en place de protocoles de sécurité robustes à chaque emplacement périphérique est cruciale pour se protéger contre les menaces cybernétiques potentielles.
Quel avenir pour le calcul en périphérie ?
L’avenir du calcul en périphérie est marqué par une croissance continue et une intégration avec des technologies émergentes comme l’IA et la 5G. L’augmentation de la puissance de calcul en périphérie permettra des applications plus sophistiquées, notamment dans l’analytique pilotée par l’IA et l’IoT. De plus, la convergence du calcul et du calcul en nuage conduira à des infrastructures informatiques plus flexibles, efficaces et évolutives entre le nuage et la périphérie. Le développement continu des technologies en périphérie suggère une tendance vers des systèmes de traitement des données plus autonomes et en temps réel dans diverses industries.