
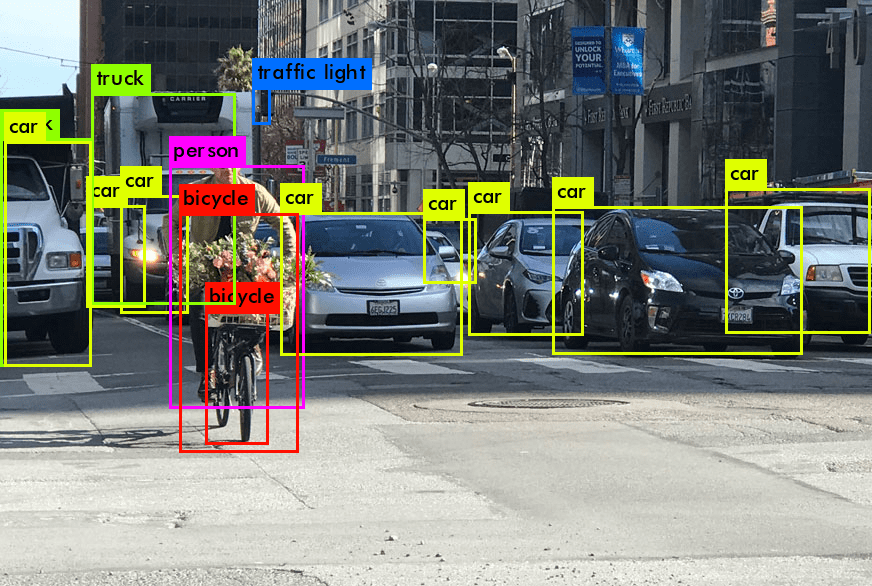
Introduction à la détection d’objets en vision par ordinateur (computer vision)
L’utilisation de la détection d’objets, une tâche fondamentale de la vision par ordinateur (computer vision), a révolutionné la manière dont les machines interprètent le monde visuel. Contrairement à la classification d’images, où l’objectif est de classer une image entière, la détection d’objets permet d’identifier et de localiser des objets dans une image ou une trame vidéo (qui est la même chose qu’une image / photo). Ce processus comprend la reconnaissance de l’objet spécifique, la localisation de l’objet et la détermination de sa position à travers une boîte englobante. La détection d’objets fait le lien entre la classification d’images et des tâches plus complexes comme la segmentation d’images, où l’objectif est d’étiqueter chaque pixel de l’image comme appartenant à un objet particulier.
L’émergence de l’apprentissage profond, en particulier l’utilisation des réseaux de neurones convolutionnels (CNNs), a considérablement avancé la détection d’objets. Ces réseaux neuronaux traitent et analysent efficacement les données visuelles, les rendant idéaux pour détecter des objets dans une image ou une vidéo. Des développements clés tels que YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) et des réseaux basés sur des propositions de régions comme Mask R-CNN ont encore amélioré la précision et l’efficacité des systèmes de détection d’objets. Ces modèles peuvent effectuer la détection en temps réel, un facteur crucial pour des applications telles que la conduite autonome ou la surveillance en temps réel.
De plus, l’intégration de techniques d’apprentissage automatique a permis aux systèmes de détection d’objets de classer et de segmenter divers objets dans des environnements complexes. Cette capacité est essentielle pour une gamme d’applications, de la détection de piétons dans les infrastructures de villes intelligentes à la qualité de contrôle dans la fabrication.
Comprendre le jeu de données pour la détection d’objets
La base de tout système de détection d’objets réussi réside dans son jeu de données. Un jeu de données pour la détection d’objets comprend des images ou des vidéos annotées pour entraîner un détecteur. Ces annotations incluent généralement des boîtes englobantes autour des objets et des étiquettes indiquant la classe de chaque objet. La qualité, la diversité et la taille du jeu de données jouent un rôle crucial dans la performance des modèles de détection d’objets. Par exemple, des jeux de données plus grands avec une grande variété d’objets et de scénarios permettent au réseau de neurones d’apprendre des caractéristiques plus robustes et généralisables.
Des jeux de données comme PASCAL VOC, MS COCO et ImageNet ont été essentiels dans l’avancement de la détection d’objets. Ils fournissent une vaste gamme d’images annotées, allant des objets quotidiens à des scénarios spécifiques, aidant au développement de modèles de détection polyvalents et précis. Ces jeux de données facilitent non seulement la formation de modèles mais servent également de références pour évaluer et comparer la performance de divers algorithmes de détection d’objets.
Former un modèle pour la détection d’objets implique également l’utilisation de techniques telles que l’apprentissage par transfert, où un modèle pré-entraîné sur un grand jeu de données est affiné avec un jeu de données plus petit et spécifique. Cette approche est particulièrement bénéfique lorsque les données disponibles pour la détection d’objets sont limitées ou lorsque la formation d’un modèle à partir de zéro est coûteuse en termes de calcul.
En résumé, le jeu de données est un composant crucial dans la détection d’objets, influençant directement la capacité d’un modèle à détecter des objets avec précision dans différents contextes et environnements. Alors que les tâches et la technologie liées à la vision par ordinateur (computer vision) continuent d’évoluer, la création et le raffinement des jeux de données restent un point central pour les chercheurs et les praticiens dans le domaine.
Exploration des modèles de détection d’objets : des traditionnels à l’apprentissage profond
La détection d’objets est une tâche de vision par ordinateur (computer vision) qui a considérablement évolué, notamment avec le progrès des technologies d’apprentissage profond. À l’origine, la détection d’objets reposait sur des techniques de vision par ordinateur plus simples et des algorithmes d’apprentissage automatique, où les caractéristiques pour la classification des objets étaient élaborées manuellement et les modèles étaient entraînés pour détecter des objets dans des images en fonction de ces caractéristiques. L’introduction de l’apprentissage profond, en particulier des réseaux de neurones convolutionnels profonds (CNN), a révolutionné ce domaine. Les CNN apprennent automatiquement les hiérarchies de caractéristiques à partir des données, permettant une détection d’objets plus précise et une segmentation sémantique. Cette transition vers des modèles d’apprentissage profond a marqué une amélioration significative des capacités de détection d’objets.
Les premiers modèles de détection d’objets basés sur CNN, tels que R-CNN, utilisaient une méthode de proposition de régions pour identifier les emplacements potentiels des objets dans une image, puis classaient chaque région. Des successeurs comme Fast R-CNN et Faster R-CNN ont amélioré cela en augmentant la précision de détection et la vitesse de traitement. Les développements ultérieurs ont conduit à l’introduction de Mask R-CNN, qui a étendu les capacités de ses prédécesseurs en ajoutant une branche pour la segmentation au niveau des pixels, facilitant la localisation et la reconnaissance détaillées des objets.
YOLO : Révolutionner la détection d’objets en temps réel
Dans le domaine de la détection d’objets en temps réel, le modèle YOLO (You Only Look Once) représente une percée significative. YOLO conceptualise de manière unique la détection d’objets comme un seul problème de régression, prédisant directement les coordonnées des boîtes englobantes et les probabilités de classe à partir des pixels de l’image en une seule évaluation. Cette approche permet à YOLO d’atteindre des vitesses de traitement exceptionnelles, essentielles pour les applications nécessitant une détection en temps réel telles que la détection de piétons et le suivi de véhicules dans les villes intelligentes.
L’architecture de YOLO traite l’image entière pendant l’entraînement, lui permettant de comprendre les informations contextuelles sur les classes d’objets et leur apparence. Cela contraste avec les méthodes basées sur la proposition de régions, qui pourraient négliger certains détails contextuels. La capacité de traitement en temps réel de YOLO le rend indispensable dans les scénarios exigeant une détection d’objets rapide et précise. La famille de modèles YOLO, incluant des versions avancées comme YOLOv3 et YOLOv4, a repoussé les limites en termes de vitesse et de précision de détection, établissant YOLO comme un système de pointe dans la détection d’objets en temps réel, allant jusqu’à YOLOv8.
Analyse vidéo en temps réel de la détection d’objets sur le drone en vol avec visionplatform.ai et notre ordinateur de bord NVIDIA Jetson monté sur le drone. Nous transformons N’IMPORTE QUELLE caméra en caméra IA.
Composants clés dans la détection d’objets : Classification et boîte englobante
L’introduction à la détection d’objets révèle deux aspects fondamentaux : la classification et la boîte englobante. La classification fait référence à l’identification de la classe de l’objet (par exemple, piéton, véhicule) dans une image. C’est une étape cruciale pour distinguer différentes catégories d’objets au sein d’un système de détection. La boîte englobante, quant à elle, implique de localiser l’objet dans l’image, généralement représentée par des coordonnées qui délimitent l’objet. Ensemble, ces composants constituent la base de la détection et du suivi d’objets.
La détection d’objets peut aider les modèles, tels que la famille de modèles YOLO et le détecteur Single Shot Multibox (SSD), la combinaison de la classification et des boîtes englobantes assure la précision de la détection. Ces modèles, souvent développés et partagés sur des plateformes comme GitHub, utilisent des approches basées sur l’apprentissage profond. Ils peuvent également être utilisés sans une ligne de code sur des plateformes de vision par ordinateur (https://visionplatform.eu-1.slashinfra.nl/computer-vision-platform/) comme visionplatform.ai. Ils sont capables de détecter plusieurs objets dans une image et de prédire avec précision l’emplacement de chaque objet avec une boîte englobante autour de lui. Cette double approche est essentielle dans divers cas d’utilisation de la détection d’objets, allant de la détection de visages dans les systèmes de sécurité à la détection d’anomalies dans les environnements industriels.
Le rôle de l’apprentissage profond dans la détection d’objets
Les méthodes d’apprentissage profond ont révolutionné la vision par ordinateur (computer vision) et la détection d’objets. Ces méthodes, impliquant principalement des réseaux neuronaux profonds comme les CNN, ont permis une détection d’objets plus précise et une segmentation sémantique. TensorFlow, une bibliothèque open-source populaire pour l’apprentissage automatique et l’apprentissage profond, offre des outils robustes pour former et déployer des modèles d’apprentissage profond pour la détection d’objets.
L’efficacité de l’apprentissage profond dans la détection d’objets peut être observée dans son application à des tâches complexes comme la détection de piétons et la détection de texte. Ces modèles apprennent des hiérarchies de caractéristiques pour une détection d’objets précise, améliorant considérablement les algorithmes traditionnels d’apprentissage automatique qui nécessitaient des caractéristiques conçues manuellement. Les modèles de détection d’objets basés sur l’apprentissage profond sont généralement évalués selon leur précision de détection et leur vitesse, les rendant idéaux pour les applications en temps réel.
Avec l’avancement des techniques d’apprentissage profond, les systèmes de détection d’objets sont devenus plus polyvalents, capables de gérer une large gamme de tâches de vision par ordinateur (computer vision) incluant le suivi d’objets, la détection de personnes et la reconnaissance d’images. Cet avancement a conduit au développement d’algorithmes de détection d’objets robustes capables de classer et de localiser de manière fiable les objets, même dans des environnements difficiles.
Segmentation et reconnaissance d’objets : Amélioration de la détection avec une analyse détaillée
L’introduction à la détection d’objets en vision par ordinateur (computer vision) conduit souvent à l’exploration de tâches connexes comme la segmentation et la reconnaissance d’objets. Alors que la détection d’objets identifie et localise les objets dans une image, la segmentation va plus loin en divisant l’image en segments pour en simplifier l’analyse ou en modifier la représentation. La reconnaissance d’objets, quant à elle, implique l’identification de l’objet spécifique présent dans l’image.
Les techniques basées sur l’apprentissage profond, en particulier les réseaux de neurones convolutionnels profonds, ont considérablement fait avancer ces domaines. La segmentation, en particulier la segmentation sémantique, est essentielle pour comprendre le contexte dans lequel les objets existent dans les images. Cela est crucial dans des cas d’utilisation tels que l’imagerie médicale, où l’identification précise des tissus ou des anomalies est essentielle. Les algorithmes de détection d’objets qui incluent la segmentation, comme Mask R-CNN, fournissent des insights détaillés en localisant non seulement la “boîte englobante autour” de l’objet mais aussi en délimitant la “forme exacte de l’objet”.
Traitement de l’image d’entrée : Le parcours à travers les systèmes de détection d’objets
Le processus de détection d’objets commence avec une image d’entrée, qui subit plusieurs étapes au sein d’un réseau de détection. Initialement, l’image est prétraitée pour répondre aux exigences du modèle de détection d’objets. Cela peut impliquer un redimensionnement, une normalisation et une augmentation. Ensuite, l’image est introduite dans un modèle d’apprentissage profond, typiquement un type de modèle comme les CNN, pour l’extraction de caractéristiques.
Les caractéristiques extraites sont ensuite utilisées pour classer les objets et prédire leur emplacement. La détection d’objets utilisée dans des scénarios en temps réel, tels que la détection de piétons ou le suivi de véhicules, nécessite que le modèle analyse rapidement l’image d’entrée et fournisse des “boîtes englobantes prédites” précises pour chaque “objet présent”. C’est là que des modèles comme YOLO excellent, offrant un traitement rapide et efficace adapté aux applications en temps réel.
Former un modèle pour de telles tâches complexes implique une quantité substantielle de données pour la détection d’objets. Ces données, comprenant généralement des images diverses avec des objets annotés, aident le modèle à apprendre les différentes catégories d’objets et leurs caractéristiques. Des cadres de détection d’objets populaires comme TensorFlow offrent des outils et des bibliothèques pour construire, former et déployer ces modèles efficacement. Tout le processus met en évidence la synergie entre la vision par ordinateur (vision par ordinateur) et les techniques de traitement d’image, les algorithmes d’apprentissage automatique et les méthodes d’apprentissage profond, aboutissant à un système robuste de détection d’objets.
Cas d’utilisation de la détection d’objets dans diverses industries
La détection d’objets, alimentée par des modèles basés sur l’apprentissage profond, a trouvé des applications dans diverses industries, chacune avec des exigences et des défis uniques. Ces modèles sont généralement évalués selon leur précision, leur vitesse et leur capacité à détecter plusieurs objets dans des conditions variées. Dans le secteur de la santé, la détection d’objets aide à identifier les anomalies dans l’imagerie médicale, contribuant ainsi de manière significative au diagnostic précoce et à la planification du traitement. Dans le commerce de détail, elle joue un rôle essentiel dans l’analyse du comportement des clients et la gestion des stocks.
Un cas d’utilisation notable de la détection d’objets se trouve dans l’industrie automobile, où elle est cruciale pour le développement de véhicules autonomes. Ici, la capacité à détecter et différencier deux objets, tels que les piétons et les autres véhicules, est primordiale pour la sécurité. Les systèmes de détection d’objets, utilisant des algorithmes avancés et des réseaux de neurones, permettent à ces véhicules de naviguer en toute sécurité en interprétant avec précision leur environnement.
TensorFlow en détection d’objets : Exploitation des modèles d’apprentissage profond
TensorFlow, un cadre open-source disponible sur des plateformes comme GitHub, est devenu synonyme de construction et de déploiement de modèles d’apprentissage profond, notamment dans le domaine de la détection d’objets. Sa bibliothèque complète permet aux développeurs de construire un modèle à partir de zéro ou d’utiliser des modèles pré-entraînés pour la détection d’objets. La flexibilité de TensorFlow dans la gestion de divers mécanismes de proposition d’objets et son traitement efficace de grands ensembles de données en font un choix privilégié pour de nombreux développeurs.
Dans la détection d’objets, l’approche d’apprentissage est cruciale. TensorFlow facilite la mise en œuvre d’algorithmes complexes qui peuvent différencier les tâches de ‘détection vs. classification’, essentielles pour des scénarios de détection d’objets nuancés. La plateforme prend en charge une large gamme de modèles, des modèles nécessitant des ressources informatiques intensives aux modèles légers adaptés aux appareils mobiles. Cette adaptabilité garantit que les modèles basés sur TensorFlow peuvent être déployés dans divers environnements, des systèmes basés sur serveur aux appareils de bord tels que le Jetson Nano Orin, Jetson NX Orin ou Jetson AGX Orin, élargissant la portée et l’accessibilité de la technologie de détection d’objets.
Exploration approfondie du modèle YOLO
Le modèle YOLO (You Only Look Once), un cadre basé sur l’apprentissage profond pour la détection d’objets, représente un changement significatif dans l’approche d’apprentissage pour la détection d’objets. Contrairement aux modèles traditionnels où le système propose d’abord des régions potentielles (proposition d’objet) puis classe chaque région, YOLO applique un seul réseau neuronal à l’image complète, prédisant des boîtes englobantes et des probabilités de classe pour plusieurs objets en une seule évaluation. Cette approche, qui se concentre sur l’image entière plutôt que sur des propositions séparées, permet à YOLO de détecter des objets en temps réel de manière efficace.
Les modèles YOLO sont généralement évalués selon leur vitesse et leur précision dans la détection de plusieurs objets. Dans les scénarios où deux objets sont proches l’un de l’autre, la capacité de YOLO à les distinguer avec précision est cruciale. L’architecture du modèle lui permet de comprendre le contexte au sein d’une image, le rendant robuste dans des environnements complexes. Cette capacité résulte de sa conception de réseau unique, qui examine l’image entière lors de la prédiction, capturant ainsi des informations contextuelles qui pourraient être manquées lorsqu’on se concentre sur des parties de l’image.
Données pour la détection d’objets : Collecte et utilisation
Le succès de tout modèle de détection d’objets, y compris ceux basés sur des cadres d’apprentissage profond comme YOLO, repose fortement sur la qualité et la quantité des données utilisées pour l’entraînement. Le processus de construction d’un modèle pour la détection d’objets commence par la collecte de données, qui implique de rassembler un ensemble diversifié d’images et de les annoter avec des étiquettes et des boîtes englobantes. Cette collecte de données est une étape cruciale dans la formation d’un modèle, car elle fournit la base sur laquelle le modèle apprendra.
Les données pour la détection d’objets doivent englober une grande variété de scénarios et de types d’objets pour garantir que le modèle puisse bien généraliser sur de nouvelles images inédites. Cela inclut la prise en compte des variations de taille des objets, des conditions d’éclairage et des arrière-plans. Les ensembles de données annotés disponibles sur des plateformes comme GitHub offrent une ressource précieuse pour l’entraînement et l’évaluation des modèles de détection d’objets.
Dans l’approche d’apprentissage pour la détection d’objets, le modèle est entraîné à détecter ‘objet contre non-objet’ et à classifier les objets détectés. Cet entraînement implique non seulement de reconnaître la présence d’un objet, mais aussi de déterminer précisément son emplacement dans l’image. L’utilisation de méthodes d’apprentissage profond avancées et de grands ensembles de données annotés a considérablement augmenté la précision et la fiabilité de la détection des modèles de détection d’objets, les rendant des outils essentiels dans diverses applications de vision par ordinateur (computer vision).
Détection vs. Reconnaissance : Comprendre les différences
Dans le domaine de la vision par ordinateur (computer vision), il est crucial de différencier la ‘détection vs. reconnaissance’. La détection consiste à localiser des objets dans une image, généralement à l’aide de boîtes englobantes, tandis que la reconnaissance va plus loin, visant à identifier la nature spécifique ou la classe des objets détectés. Cette distinction est importante pour adapter les systèmes de vision par ordinateur (computer vision) à des applications spécifiques. Par exemple, alors qu’un système de détection pourrait suffire pour compter les voitures sur une route, un système de reconnaissance serait nécessaire pour différencier les modèles de voitures.
La complexité des tâches de reconnaissance exige généralement des modèles plus sophistiqués par rapport aux tâches de détection. La reconnaissance implique souvent non seulement d’identifier qu’un objet est présent, mais aussi de le classer dans l’une des plusieurs catégories possibles. Ce processus nécessite une compréhension plus nuancée des caractéristiques de l’objet et est crucial dans des scénarios où une identification détaillée est essentielle, comme la différenciation entre des cellules bénignes et malignes dans l’imagerie médicale.
Conclusion et tendances futures en détection d’objets
En conclusion, il est évident que la détection d’objets est un domaine en évolution rapide, avec de nouvelles avancées qui émergent continuellement. Les tendances futures devraient se concentrer sur l’amélioration de la précision, de la vitesse et de la capacité à gérer des scènes plus complexes. L’intégration de l’IA avec d’autres technologies telles que la réalité augmentée et l’Internet des Objets (IoT) ouvre de nouveaux horizons pour les applications de détection d’objets.
De plus, la demande pour des modèles plus efficaces et moins gourmands en données pousse la recherche vers des approches d’apprentissage en quelques coups et d’apprentissage non supervisé. Ces méthodes visent à former efficacement des modèles avec des données limitées, abordant l’un des défis majeurs du domaine. Au fur et à mesure que la technologie progresse, nous pouvons anticiper des solutions plus innovantes, améliorant les capacités et les applications de la détection d’objets dans divers secteurs, de la santé aux véhicules autonomes.
Le raffinement continu des modèles et des algorithmes en détection d’objets contribuera sans aucun doute à des systèmes plus sophistiqués et précis, renforçant son importance dans le domaine de la vision par ordinateur (computer vision) et au-delà.
FAQ sur la détection d’objets : Comprendre les concepts de base
Plongez dans les fondamentaux de la détection d’objets avec notre section FAQ. Ici, nous répondons aux questions courantes, clarifiant le fonctionnement de la détection d’objets, ses applications et la technologie qui la sous-tend. Que vous soyez novice en vision par ordinateur (computer vision) ou que vous cherchiez à affiner vos connaissances, ces réponses fournissent des aperçus concis sur le monde passionnant de la détection d’objets.
Qu’est-ce que la détection d’objets ?
La détection d’objets est une solution de vision par ordinateur (computer vision) qui identifie et localise des objets dans une image ou une vidéo. Elle ne reconnaît pas seulement la présence d’objets, mais indique également leur position avec des boîtes englobantes. Le système attribue des niveaux de confiance aux prédictions, indiquant la probabilité de précision. La détection d’objets est distincte de la reconnaissance d’image, qui attribue une étiquette de classe à une image, et de la segmentation d’image, qui identifie les objets au niveau des pixels.
Comment fonctionne la détection d’objets ?
La détection d’objets implique généralement deux étapes : la détection des régions d’objets potentiels (Région d’Intérêt, ou RoI) et ensuite la classification de ces régions. Les approches basées sur l’apprentissage profond, en particulier en utilisant des réseaux neuronaux comme les Réseaux Neuronaux Convolutifs (CNNs), sont courantes. Des modèles comme R-CNN, YOLO et SSD analysent d’abord l’image pour trouver les RoI, puis classifient chaque RoI dans des catégories d’objets, souvent en utilisant des caractéristiques apprises lors de l’entraînement sur des ensembles de données comme COCO ou ImageNet.
Quels sont les types de modèles de détection d’objets ?
Les modèles de détection d’objets populaires incluent R-CNN et ses variantes (Fast R-CNN, Faster R-CNN et Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector) et CenterNet. Ces modèles diffèrent dans leur approche pour identifier les RoI et les classer. Les modèles R-CNN utilisent des propositions de régions, tandis que YOLO et SSD prédisent directement les boîtes englobantes à partir de l’image, améliorant la vitesse et l’efficacité.
Quelle est la différence entre la détection d’objets et la reconnaissance d’objets ?
La détection d’objets et la reconnaissance d’objets sont des tâches distinctes. La détection d’objets implique de localiser des objets dans une image et d’identifier leurs limites, généralement avec des boîtes englobantes. La reconnaissance d’objets va plus loin en localisant mais aussi en classifiant les objets dans des catégories prédéfinies, comme distinguer différents types d’animaux, de véhicules ou d’autres articles.
Comment les modèles de détection d’objets sont-ils formés ?
La formation des modèles de détection d’objets implique de nourrir un réseau neuronal avec des images étiquetées. Ces images sont annotées avec des boîtes englobantes autour des objets et leurs étiquettes de classe correspondantes. Le réseau neuronal apprend à reconnaître des motifs et des caractéristiques à partir de ces images d’entraînement. L’efficacité de la formation dépend de la diversité et de la taille de l’ensemble de données, avec des ensembles de données plus grands et variés menant à des modèles plus précis et généralisables. Les modèles sont souvent formés en utilisant des cadres comme TensorFlow ou PyTorch.
Quelles sont les utilisations de la détection d’objets ?
La détection d’objets est largement utilisée dans divers domaines. En sécurité et surveillance, elle aide à la détection de visages et au suivi des activités. En commerce de détail, elle aide à analyser le comportement des clients et à gérer les inventaires. Dans les véhicules autonomes, elle est cruciale pour identifier les obstacles et naviguer en toute sécurité. La détection d’objets trouve également des applications en santé pour identifier les anomalies dans les images médicales, et en agriculture pour la surveillance des cultures et des ravageurs.
Qu’est-ce que YOLO en détection d’objets ?
YOLO (You Only Look Once) est un modèle de détection d’objets populaire connu pour sa vitesse et son efficacité. Contrairement aux modèles traditionnels qui traitent une image en parties, YOLO examine toute l’image en une seule passe, ce qui le rend nettement plus rapide. Cela le rend idéal pour les applications de détection d’objets en temps réel. YOLO a plusieurs versions, avec YOLOv5 et YOLOv8 étant les plus récentes, offrant des améliorations en termes de précision et de vitesse.
Quelle est la précision des modèles de détection d’objets ?
La précision des modèles de détection d’objets varie en fonction de leur architecture et de la qualité des données d’entraînement. Des modèles comme YOLOv4 et YOLOv5 démontrent une haute précision, souvent avec des taux de précision supérieurs à 90 % dans des conditions idéales. La précision est mesurée à l’aide de métriques comme mAP (mean Average Precision) et IoU (Intersection over Union). Le mAP pour les meilleurs modèles sur des ensembles de données standard comme MS COCO peut atteindre 60-70 %.
Quel est le rôle des Réseaux Neuronaux Convolutifs dans la détection d’objets ?
Les Réseaux Neuronaux Convolutifs (CNNs) jouent un rôle crucial dans la détection d’objets, principalement dans l’extraction de caractéristiques. Ils traitent les images à travers des couches convolutionnelles pour apprendre et identifier les caractéristiques clés, qui sont cruciales pour détecter des objets. Des modèles comme R-CNN, Faster R-CNN et SSD utilisent les CNNs pour leur efficacité dans le traitement des données d’image, améliorant considérablement la précision et la vitesse de la détection d’objets.
Comment commencer à construire un modèle de détection d’objets ?
Pour commencer à construire un modèle de détection d’objets, définissez d’abord les objets que vous souhaitez détecter. Rassemblez et annotez un ensemble de données avec des images contenant ces objets. Utilisez des outils comme TensorFlow ou PyTorch pour entraîner un modèle sur cet ensemble de données. Commencez avec une architecture simple comme SSD ou YOLO pour une mise en œuvre plus facile. Expérimentez avec différentes configurations et hyperparamètres pour optimiser les performances de votre modèle.