
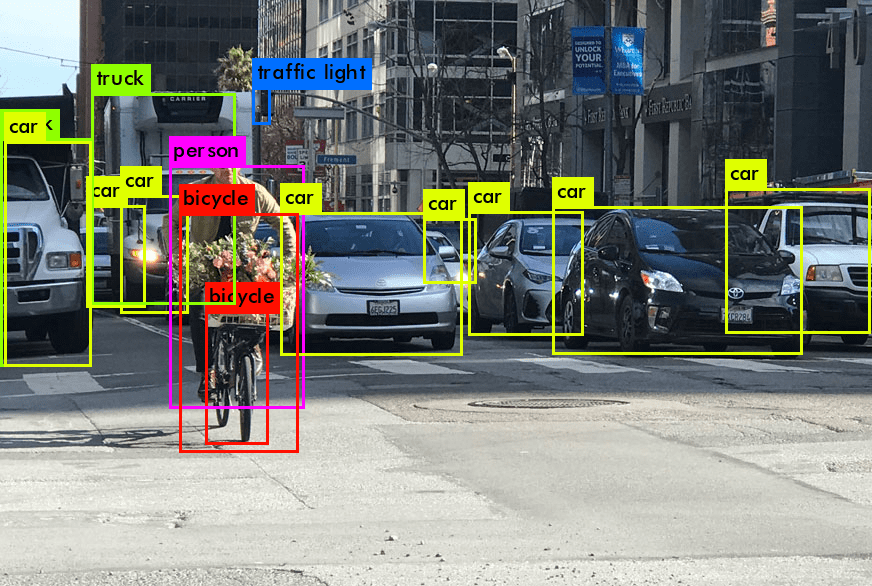
Introduction à la vision par ordinateur (computer vision) et au modèle YOLO
La vision par ordinateur (computer vision), un domaine de l’intelligence artificielle, vise à donner aux machines la capacité d’interpréter et de comprendre le monde visuel. Elle implique la capture, le traitement et l’analyse d’images ou de vidéos pour automatiser des tâches que le système visuel humain peut effectuer. Ce domaine en rapide évolution englobe diverses applications, de la reconnaissance faciale et le suivi d’objets à des activités plus avancées comme la conduite autonome. Le développement de la vision par ordinateur (computer vision) repose fortement sur de grands ensembles de données, des algorithmes sophistiqués et des ressources informatiques puissantes.
Une percée dans ce domaine est survenue avec le développement du modèle YOLO (You Only Look Once). Conçu comme un modèle de détection d’objets à la pointe de la technologie, YOLO a révolutionné l’approche de la détection d’objets dans les images. Les modèles de détection traditionnels impliquaient souvent un processus en deux étapes : d’abord identifier les régions d’intérêt, puis classifier ces régions. En contraste, YOLO a innové en prédisant à la fois les classifications et les boîtes englobantes en une seule passe à travers le réseau neuronal, accélérant considérablement le processus et améliorant les capacités de détection en temps réel.
Ce modèle de détection d’objets a subi plusieurs itérations, chaque version introduisant de nouvelles fonctionnalités et améliorations. YOLOv8, la dernière version d’Ultralytics, s’appuie sur le succès de ses prédécesseurs comme YOLOv5. Il intègre des techniques avancées d’apprentissage automatique pour améliorer la précision et la vitesse, ce qui en fait un choix populaire pour les tâches de vision par ordinateur (computer vision). La nature open-source des modèles YOLO, comme le dépôt YOLOv8 sur GitHub, a en outre contribué à leur adoption généralisée et à leur développement continu.
L’efficacité de YOLO dans la détection d’objets, la segmentation d’instances et les tâches de classification en a fait un élément de base dans les projets de vision par ordinateur (computer vision). En simplifiant le processus d’identification et de catégorisation des objets dans les images, les modèles YOLO comme YOLOv8 aident les machines à comprendre le monde visuel de manière plus précise et efficace.
YOLOv8 : Le nouvel état de l’art en vision par ordinateur (computer vision)
YOLOv8 représente le sommet du progrès dans le domaine de la vision par ordinateur (computer vision), se positionnant comme le nouveau modèle de référence en matière de détection d’objets. Développé par Ultralytics, cette version de la série de modèles YOLO apporte des avancées significatives par rapport à son prédécesseur, YOLOv5, et aux versions antérieures de YOLO. YOLOv8 est équipé d’une gamme de nouvelles fonctionnalités qui améliorent ses capacités de détection, le rendant plus précis et efficace que jamais.
Une des avancées notables de YOLOv8 est son adoption de la détection sans ancre (anchor-free detection). Cette nouvelle approche se détourne de la dépendance traditionnelle aux boîtes d’ancrage, qui étaient un élément de base dans les modèles YOLO précédents. La détection sans ancre simplifie l’architecture du modèle et améliore sa capacité à prédire plus précisément les emplacements des objets. Cette amélioration est particulièrement bénéfique dans les scénarios où l’ensemble de données comprend des objets de formes et de tailles variées.
Le modèle YOLOv8 excelle également dans les tâches de segmentation, un aspect crucial de la vision par ordinateur (computer vision). Que ce soit pour la détection d’objets, la segmentation d’instances ou des modèles de segmentation plus généraux, YOLOv8, en particulier le modèle YOLOv8 Nano, démontre une compétence remarquable. Sa capacité à segmenter et classifier précisément différentes parties d’une image le rend très efficace dans des applications variées, de l’imagerie médicale à la navigation des véhicules autonomes.
Un autre aspect clé de YOLOv8 est son package Python, qui facilite l’intégration et l’utilisation dans des projets basés sur Python. Cette accessibilité est cruciale, surtout compte tenu de la popularité de Python dans les communautés de science des données et d’apprentissage automatique. Les développeurs peuvent entraîner un modèle YOLOv8 sur un ensemble de données personnalisé en utilisant PyTorch, un cadre de pointe pour l’apprentissage profond. Cette flexibilité permet des solutions sur mesure pour des défis spécifiques de vision par ordinateur (computer vision).
La performance de YOLOv8 est encore renforcée par ses métriques de performance de modèle de pointe. Ces métriques mettent en évidence la capacité du modèle à détecter des objets avec une grande précision et rapidité, des facteurs cruciaux dans les applications en temps réel. De plus, en tant que modèle open-source disponible sur GitHub, YOLOv8 bénéficie d’améliorations continues et de contributions de la communauté mondiale de développeurs.
En conclusion, YOLOv8 établit un nouveau jalon dans le domaine de la vision par ordinateur (computer vision). Ses avancées en détection d’objets, en segmentation et en performance globale du modèle en font un outil inestimable pour les développeurs et les chercheurs cherchant à repousser les limites de ce qui est possible dans l’interprétation visuelle pilotée par l’IA.
Architecture YOLOv8 : Le pilier des nouvelles avancées en vision par ordinateur (computer vision)
L’architecture YOLOv8 représente un bond significatif dans le domaine de la vision par ordinateur (computer vision), établissant un nouveau standard de pointe. En tant que dernière version de YOLO, YOLOv8 introduit plusieurs améliorations par rapport à ses prédécesseurs, comme YOLOv5 et les versions antérieures de YOLO. Comprendre l’architecture YOLOv8 est crucial pour ceux qui cherchent à entraîner le modèle pour des tâches spécialisées de détection d’objets.
Une des caractéristiques essentielles de YOLOv8 est sa tête de détection sans ancre, qui s’éloigne de l’approche traditionnelle des boîtes d’ancrage utilisée dans les versions antérieures de YOLO. Ce changement simplifie le modèle tout en maintenant, et dans de nombreux cas en améliorant, la précision dans la détection d’objets. YOLOv8 prend en charge une gamme variée d’applications, de la détection d’objets en temps réel à la segmentation d’images.
Le modèle YOLOv8 est conçu pour l’efficacité et la performance. Le modèle YOLOv8 open source peut être entraîné sur divers ensembles de données, y compris le dataset COCO largement utilisé. Cette flexibilité permet aux utilisateurs d’adapter le modèle à des besoins spécifiques, que ce soit pour la détection d’objets générale ou des tâches spécialisées comme l’estimation de pose.
L’architecture de YOLOv8 est optimisée pour la vitesse et la précision, un facteur crucial dans les applications en temps réel. La conception du modèle comprend également des améliorations en matière de segmentation d’images, en faisant un modèle complet de détection et de segmentation d’images. La série YOLO d’Ultralytics, en particulier YOLOv8, a toujours été à la pointe de l’avancement des modèles de vision par ordinateur (computer vision), et YOLOv8 continue cette tradition.
Pour ceux qui souhaitent commencer avec YOLOv8, le dépôt Ultralytics fournit de nombreuses ressources. Le dépôt, disponible sur GitHub, offre des instructions détaillées sur la façon d’entraîner le modèle YOLOv8, y compris la configuration de l’environnement d’entraînement et le chargement des poids du modèle.
Modèle de détection d’objets YOLOv8 : Révolutionner la détection et la segmentation
Le modèle de détection d’objets YOLOv8 est la dernière addition à la série YOLO, créée par Joseph Redmon et Ali Farhadi. Il se positionne à l’avant-garde des avancées en vision par ordinateur (computer vision), incarnant le nouvel état de l’art tant en détection d’objets qu’en segmentation d’images. Les capacités de YOLOv8 vont au-delà de la simple détection d’objets ; il excelle également dans des tâches telles que la segmentation d’instances et la détection en temps réel, ce qui en fait un outil polyvalent pour une variété d’applications.
YOLOv8 utilise une approche innovante pour la détection, intégrant des fonctionnalités qui en font un détecteur d’objets très précis. Le modèle intègre une tête de détection sans ancre, qui simplifie le processus de détection et améliore la précision. Cela représente un changement significatif par rapport à la méthode des boîtes d’ancrage utilisée dans les versions précédentes de YOLO.
Le processus de formation du modèle YOLOv8 est simple, surtout avec les ressources fournies dans le dépôt GitHub de YOLOv8. Le dépôt comprend des instructions détaillées sur la façon de former le modèle en utilisant un jeu de données personnalisé, permettant aux utilisateurs d’adapter le modèle à leurs besoins spécifiques. Par exemple, former des modèles sur un jeu de données pendant 100 époques peut entraîner une amélioration significative des performances du modèle, comme en témoignent les évaluations sur l’ensemble de validation.
De plus, l’architecture de YOLOv8 est conçue pour soutenir efficacement les tâches de détection d’objets et de segmentation d’images. Cette polyvalence est évidente dans son application dans divers domaines, de la surveillance à la conduite autonome. YOLOv8 introduit de nouvelles fonctionnalités qui améliorent son efficacité, telles que des améliorations dans les dix dernières époques de formation, qui optimisent l’apprentissage et la précision du modèle.
En résumé, YOLOv8 représente une avancée significative dans la série YOLO et le domaine plus large de la vision par ordinateur (computer vision). Son architecture et ses fonctionnalités de pointe en font un choix idéal pour les développeurs et les chercheurs souhaitant mettre en œuvre des modèles de détection et de segmentation avancés dans leurs projets. Le dépôt Ultralytics est un excellent point de départ pour quiconque souhaite explorer les capacités de YOLOv8 et le déployer dans des scénarios réels.
Format d’annotation YOLOv8 : Préparation des données pour l’entraînement
La préparation des données pour l’entraînement est une étape cruciale dans le développement de tout modèle de vision par ordinateur (computer vision), et YOLOv8 ne fait pas exception. Le format d’annotation YOLOv8 joue un rôle pivot dans ce processus, car il influence directement l’apprentissage et la précision du modèle. Une annotation appropriée garantit que le modèle peut identifier correctement et apprendre à partir des différents éléments d’un ensemble de données, ce qui est crucial pour une détection d’objets efficace et la segmentation d’images.
Le format d’annotation YOLOv8 est unique et se distingue des autres formats utilisés en vision par ordinateur (computer vision). Il nécessite un détail précis des objets dans les images, généralement à travers des boîtes englobantes et des étiquettes. Chaque objet dans une image est marqué avec une boîte englobante, et ces boîtes sont étiquetées avec des classes que le modèle doit identifier. Ce format est crucial pour l’entraînement du modèle YOLOv8, car il aide le modèle à comprendre l’emplacement et la catégorie de chaque objet dans une image.
Préparer un ensemble de données pour YOLOv8 implique d’annoter un grand nombre d’images, ce qui peut être un processus long. Cependant, l’effort est essentiel pour atteindre une haute performance du modèle. La qualité et la précision des annotations ont un impact direct sur la capacité du modèle à apprendre et à faire des prédictions précises.
Pour ceux qui cherchent à entraîner un modèle YOLOv8, comprendre et mettre en œuvre le format d’annotation correct est clé. Ce processus implique généralement l’utilisation d’outils d’annotation spécialisés qui permettent aux utilisateurs de dessiner des boîtes englobantes et de les étiqueter de manière appropriée. L’ensemble de données annoté est ensuite utilisé pour entraîner le modèle, lui apprenant à reconnaître et à catégoriser les objets en fonction des étiquettes fournies et des coordonnées des boîtes englobantes.
Formation YOLOv8 : Un guide étape par étape
La formation YOLOv8 est un processus qui nécessite une préparation et une exécution minutieuses pour obtenir des performances optimales du modèle. Le processus de formation comprend plusieurs étapes, de la configuration de l’environnement à l’ajustement fin du modèle sur un ensemble de données spécifique. Voici un guide étape par étape pour former YOLOv8 :
- Configuration de l’environnement : La première étape consiste à configurer l’environnement de formation. Cela implique d’installer les logiciels et dépendances nécessaires. YOLOv8, étant un modèle basé sur Python, nécessite un environnement Python avec des bibliothèques telles que PyTorch.
- Préparation des données : Ensuite, préparez votre ensemble de données selon le format d’annotation YOLOv8. Cela implique d’annoter les images avec des boîtes englobantes et des étiquettes pour définir les objets que le modèle doit apprendre à détecter.
- Configuration du modèle : Avant de commencer la formation, configurez le modèle YOLOv8 selon vos besoins. Cela pourrait impliquer d’ajuster des paramètres tels que le taux d’apprentissage, la taille du lot et le nombre d’époques.
- Formation du modèle : Avec l’environnement et les données configurés, vous pouvez commencer le processus de formation. Cela implique de nourrir le modèle avec l’ensemble de données annoté et de lui permettre d’apprendre à partir des données. Le modèle ajuste itérativement ses poids et biais pour minimiser les erreurs de détection.
- Évaluation des performances : Après la formation, évaluez les performances du modèle à l’aide de métriques telles que la précision, le rappel et la précision moyenne moyenne (mAP). Cela aide à comprendre à quel point le modèle peut détecter et classer des objets dans des images.
- Ajustement fin : En fonction de l’évaluation, vous pourriez avoir besoin d’ajuster finement le modèle. Cela pourrait impliquer de re-former le modèle avec des paramètres ajustés ou de lui fournir des données d’entraînement supplémentaires.
- Déploiement : Une fois le modèle formé et ajusté, il est prêt pour le déploiement dans des applications du monde réel.
Former un modèle YOLOv8 nécessite une attention aux détails et une compréhension approfondie du fonctionnement du modèle. Cependant, l’effort en vaut la peine avec un modèle de détection d’objets robuste, précis et efficace adapté à diverses applications en vision par ordinateur (computer vision).
Déploiement de YOLOv8 dans des applications réelles
Le déploiement de YOLOv8 dans des applications réelles est une étape cruciale pour exploiter ses capacités avancées de détection d’objets. Un déploiement réussi traduit la compétence théorique du modèle en solutions pratiques et actionnables dans diverses industries. Voici un guide complet pour déployer YOLOv8 :
- Choix de la bonne plateforme : La première étape consiste à décider où le modèle YOLOv8 sera déployé. Cela peut varier des serveurs basés sur le cloud pour des applications à grande échelle aux dispositifs de bord pour un traitement en temps réel sur site, comme la solution de plateforme de vision par ordinateur (computer vision) de visionplatform.ai (https://visionplatform.eu-1.slashinfra.nl/computer-vision-platform/).
- Optimisation du modèle : Selon la plateforme de déploiement, il peut être nécessaire d’optimiser le modèle YOLOv8 pour la performance. Des techniques telles que la quantification du modèle ou l’élagage peuvent être utilisées pour réduire la taille du modèle sans compromettre significativement la précision, le rendant adapté aux dispositifs avec des ressources informatiques limitées.
- Intégration avec les systèmes existants : Dans de nombreux cas, le modèle YOLOv8 devra être intégré dans des systèmes logiciels ou matériels existants. Cela nécessite une compréhension approfondie de ces systèmes et la capacité d’interfacer le modèle YOLOv8 en utilisant des API appropriées ou des cadres logiciels.
- Tests et validation : Avant un déploiement à grande échelle, il est crucial de tester le modèle dans un environnement contrôlé pour s’assurer qu’il fonctionne comme prévu. Cela implique de valider la précision, la vitesse et la fiabilité du modèle dans différentes conditions.
- Déploiement et surveillance : Une fois testé, déployez le modèle sur la plateforme choisie. Une surveillance continue est essentielle pour garantir que le modèle fonctionne correctement et efficacement au fil du temps. Cela aide également à identifier et à rectifier les problèmes qui peuvent survenir après le déploiement.
- Mises à jour et maintenance : Comme tout logiciel, le modèle YOLOv8 déployé pourrait nécessiter des mises à jour périodiques pour des améliorations ou pour répondre à de nouveaux défis. Une maintenance régulière garantit que le modèle reste efficace et sécurisé.
Déployer YOLOv8 efficacement exige une approche stratégique, en tenant compte de facteurs tels que l’environnement opérationnel, les limitations computationnelles, et les défis d’intégration. Lorsqu’il est bien réalisé, YOLOv8 peut considérablement améliorer les capacités des systèmes dans des secteurs tels que la sécurité, la santé, les transports et le commerce de détail.
YOLOv8 vs YOLOv5 : Comparaison des modèles de détection d’objets
Comparer YOLOv8 et YOLOv5 est essentiel pour comprendre les progrès dans les modèles de détection d’objets et pour décider quel modèle est le plus adapté à une application spécifique. Les deux modèles sont à la pointe de la technologie en termes de capacités, mais ils présentent des caractéristiques et des performances distinctes.
- Architecture du modèle : YOLOv8 introduit plusieurs améliorations architecturales par rapport à YOLOv5. Cela inclut des améliorations dans les couches de détection et l’intégration de nouvelles technologies comme la détection sans ancre, qui améliore la précision et l’efficacité du modèle.
- Précision et vitesse : YOLOv8 a montré des améliorations en termes de précision et de vitesse de détection par rapport à YOLOv5. Cela est particulièrement évident dans les scénarios de détection difficiles impliquant des objets petits ou superposés.
- Formation et flexibilité : Les deux modèles offrent une flexibilité dans la formation, permettant aux utilisateurs de s’entraîner sur des ensembles de données personnalisés. Cependant, YOLOv8 offre des fonctionnalités plus avancées pour le réglage fin du modèle, ce qui peut conduire à de meilleures performances sur des tâches spécifiques.
- Adéquation à l’application : Bien que YOLOv5 reste une option puissante pour de nombreuses applications, les avancées de YOLOv8 le rendent mieux adapté aux scénarios où la précision et la vitesse maximales sont cruciales.
- Communauté et support : Les deux modèles bénéficient d’un fort soutien communautaire et sont largement utilisés, assurant une amélioration continue et de vastes ressources pour les développeurs.
En conclusion, bien que YOLOv5 reste un modèle robuste et efficace pour la détection d’objets, YOLOv8 représente les dernières avancées dans le domaine, offrant une précision et des performances améliorées. Le choix entre les deux dépend des exigences spécifiques de l’application, y compris des facteurs tels que les ressources informatiques, la complexité de la tâche de détection et le besoin de traitement en temps réel.
Exploration des variantes des modèles YOLO
La série YOLO (You Only Look Once) comprend une gamme de modèles adaptés à diverses applications dans la détection d’objets, chacun différant par sa taille, sa vitesse et sa précision. Du modèle YOLOv8n léger, conçu pour les appareils de bord, au YOLOv8x très précis, adapté à la recherche approfondie, ces variantes répondent à divers environnements informatiques et exigences d’application. Cette exploration fournit un aperçu des différents types de modèles YOLO, mettant en évidence leurs caractéristiques uniques et les cas d’utilisation optimaux.
| Attribut / Modèle | YOLOv8n (Nano) | YOLOv8s (Petit) | YOLOv8m (Moyen) | YOLOv8l (Grand) | YOLOv8x (Très Grand) | |
|---|---|---|---|---|---|---|
| Taille | Très Petit | Petit | Moyen | Grand | Très Grand | |
| Vitesse | Très Rapide | Rapide | Moderée | Lente | Très Lente | |
| Précision | Inférieure | Moderée | Élevée | Très Élevée | La Plus Élevée | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Résolution | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
La comparaison de Yolo avec les modèles précédents tels que YOLOv5, YOLOv6, YOLOv7 et YOLOv8 montre que YOLOv8 est à la fois meilleur et plus rapide que ses versions précédentes.
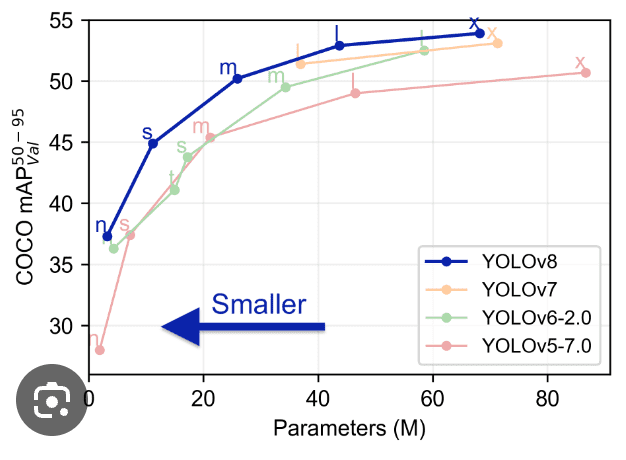
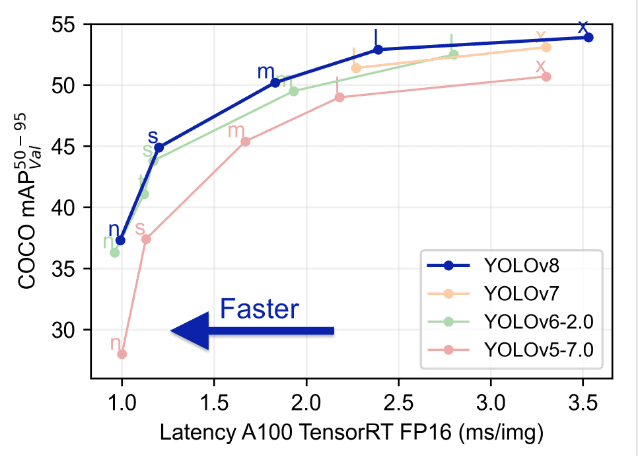
Fonctionnalités avancées dans YOLOv8 : Amélioration de la performance du modèle
La performance du modèle YOLOv8 se distingue dans le domaine de la vision par ordinateur (computer vision), grâce à un ensemble de fonctionnalités avancées qui renforcent ses capacités. Ces fonctionnalités contribuent de manière significative au statut de YOLOv8 en tant que modèle de pointe pour les tâches de détection et de segmentation d’objets. Une analyse approfondie de ces fonctionnalités révèle pourquoi YOLOv8 est un choix privilégié pour les développeurs et les chercheurs :
- Détection sans ancre : YOLOv8 se détourne des boîtes d’ancrage traditionnelles pour un système de détection sans ancre. Cela simplifie l’architecture du modèle, y compris le modèle YOLOv8 Nano, et améliore sa capacité à prédire avec précision les emplacements des objets, en particulier pour les images avec des formes et des tailles d’objets diverses.
- Couches convolutionnelles améliorées : YOLOv8 introduit des modifications dans ses blocs convolutionnels, remplaçant les convolutions
6x6précédentes par des3x3. Ce changement améliore la capacité du modèle à extraire et à apprendre des caractéristiques détaillées des images, améliorant ainsi sa précision de détection globale. - Augmentation des données en mosaïque : Propre à YOLOv8 est l’implémentation de l’augmentation des données en mosaïque pendant l’entraînement. Cette technique assemble quatre images différentes, améliorant la capacité du modèle à détecter des objets dans des contextes et des arrière-plans variés. Cependant, YOLOv8 désactive stratégiquement cette augmentation dans les dix dernières époques de formation pour optimiser les performances.
- Intégration PyTorch : En tant que package Python, YOLOv8 bénéficie d’une intégration transparente avec PyTorch, un cadre de premier plan dans l’apprentissage automatique. Cette intégration simplifie le processus de formation et de déploiement du modèle, en particulier lors du travail avec des ensembles de données personnalisés.
- Détection d’objets multi-échelles : L’architecture de YOLOv8 est conçue pour la détection d’objets multi-échelles. Cette fonctionnalité permet au modèle de détecter avec précision des objets de tailles variées dans une image, le rendant polyvalent dans différents scénarios d’application.
- Capacités de traitement en temps réel : L’un des avantages les plus significatifs de YOLOv8 est sa capacité à effectuer une détection d’objets en temps réel. Cette fonctionnalité est cruciale pour les applications nécessitant une analyse et une réponse immédiates, telles que la conduite autonome et la surveillance en temps réel.
Ces fonctionnalités avancées soulignent la capacité de YOLOv8 en tant qu’outil puissant dans le domaine de la vision par ordinateur (computer vision). Son mélange de précision, de rapidité et de flexibilité en fait un excellent choix pour un large éventail d’applications de détection et de segmentation d’objets.
Commencer avec YOLOv8 : De l’installation à la mise en œuvre
Commencer avec YOLOv8, surtout pour ceux qui sont nouveaux dans le domaine de la vision par ordinateur (computer vision), peut sembler intimidant. Cependant, avec les bonnes directives, configurer et déployer YOLOv8 peut être un processus rationalisé. Voici un guide étape par étape pour commencer avec YOLOv8 :
- Comprendre les bases : Avant de plonger dans YOLOv8, il est crucial d’avoir une compréhension de base des concepts de vision par ordinateur (computer vision) et des principes derrière les modèles de détection d’objets. Cette connaissance de base aidera à comprendre comment fonctionne YOLOv8.
- Configurer l’environnement : La première étape technique implique la configuration de l’environnement de programmation. Cela inclut l’installation de Python, PyTorch et d’autres bibliothèques nécessaires. La documentation de YOLOv8 fournit des orientations détaillées sur le processus de configuration.
- Accéder aux ressources YOLOv8 : Le dépôt GitHub de YOLOv8 est une ressource précieuse. Il contient le code du modèle, les poids pré-entraînés et une documentation extensive. Se familiariser avec ces ressources est crucial pour une mise en œuvre réussie.
- Entraîner le modèle : Pour entraîner YOLOv8, vous avez besoin d’un jeu de données. Pour les débutants, il est conseillé d’utiliser un jeu de données standard comme COCO. Le processus de formation implique de peaufiner le modèle sur votre jeu de données spécifique pour optimiser ses performances pour votre application.
- Évaluer le modèle : Après l’entraînement, évaluez les performances du modèle en utilisant des métriques standard telles que la précision, le rappel et la précision moyenne (mAP). Cette étape est cruciale pour garantir que le modèle détecte précisément les objets.
- Déploiement : Avec un modèle formé et testé, comme le modèle YOLOv8 Nano, l’étape suivante est le déploiement. Cela pourrait être sur un serveur pour des applications basées sur le web ou sur un appareil de bord pour un traitement en temps réel utilisant visionplatform.ai.
- Apprentissage continu : Le domaine de la vision par ordinateur (computer vision) évolue rapidement. Rester à jour avec les dernières avancées et continuer à apprendre est clé pour utiliser efficacement YOLOv8 que vous faites efficacement via une plateforme de vision par ordinateur (computer vision).
Commencer avec YOLOv8 implique un mélange de compréhension théorique et d’application pratique. En suivant ces étapes, on peut mettre en œuvre et utiliser avec succès YOLOv8 dans diverses tâches de vision par ordinateur (computer vision), exploitant tout son potentiel dans la détection d’objets et la segmentation d’images.
L’avenir de la vision par ordinateur (computer vision) : Nouveautés dans YOLOv8 et au-delà
L’avenir de la vision par ordinateur (computer vision) est incroyablement prometteur, avec YOLOv8 en tête de file comme le modèle le plus récent et le plus avancé de la série YOLO. L’introduction de YOLOv8 marque une étape importante dans l’évolution continue des technologies de vision par ordinateur (computer vision), offrant une précision et une efficacité sans précédent dans les tâches de détection d’objets. Voici les nouveautés de YOLOv8 et les implications pour l’avenir de la vision par ordinateur (computer vision) :
- Avancées technologiques : YOLOv8 a introduit plusieurs améliorations technologiques par rapport à ses prédécesseurs. Celles-ci incluent des réseaux convolutionnels plus efficaces, une détection sans ancre et des algorithmes améliorés pour la détection d’objets en temps réel.
- Accessibilité et application accrues : Avec YOLOv8, le domaine de la vision par ordinateur (computer vision) devient plus accessible à un plus large éventail d’utilisateurs, y compris ceux sans compétences de codage étendues. Cette démocratisation de la technologie favorise l’innovation et encourage des applications diverses dans différents secteurs.
- Intégration avec les technologies émergentes : La compatibilité de YOLOv8 avec les cadres d’apprentissage machine avancés et sa capacité à s’intégrer avec d’autres technologies de pointe, comme la réalité augmentée et la robotique, signalent un avenir où les solutions de vision par ordinateur (computer vision) sont de plus en plus polyvalentes et puissantes.
- Amélioration des performances : YOLOv8 a établi de nouveaux repères en termes de performance des modèles, notamment en termes de précision et de vitesse de traitement. Cette amélioration est cruciale pour les applications nécessitant une analyse en temps réel, telles que les véhicules autonomes et les technologies des villes intelligentes.
- Prédictions pour les développements futurs : À l’avenir, nous pouvons anticiper de nouvelles avancées dans les modèles de vision par ordinateur (computer vision), avec encore plus de précision, de vitesse et d’adaptabilité. L’intégration de l’IA avec la vision par ordinateur (computer vision) devrait continuer à évoluer, conduisant à des systèmes plus sophistiqués et autonomes.
Le développement continu de YOLOv8 et de modèles similaires témoigne de la nature dynamique du domaine de la vision par ordinateur (computer vision). À mesure que la technologie progresse, nous pouvons nous attendre à voir plus d’innovations révolutionnaires qui redéfiniront les limites de ce que les systèmes de vision par ordinateur (computer vision) peuvent réaliser.
Conclusion : L’impact de YOLOv8 sur la vision par ordinateur et l’IA
En conclusion, YOLOv8 a eu un impact substantiel sur le domaine de la vision par ordinateur (computer vision) et de l’IA. Ses fonctionnalités avancées et ses capacités représentent un bond significatif en avant dans la technologie de détection d’objets. Les implications des avancées de YOLOv8 vont au-delà du domaine technique, influençant diverses industries et applications :
- Avancées en détection d’objets : YOLOv8 a établi une nouvelle norme en matière de détection d’objets avec sa précision, sa vitesse et son efficacité améliorées. Cela a des implications pour une large gamme d’applications, de la sécurité et la surveillance à la santé, la fabrication, la logistique et la surveillance environnementale.
- Démocratisation de la technologie IA : En rendant la technologie de vision par ordinateur (computer vision) avancée comme le dépôt YOLOv8 plus accessible et conviviale, YOLOv8 a ouvert la porte à un plus large éventail d’utilisateurs et de développeurs pour innover et créer des solutions pilotées par l’IA.
- Applications pratiques améliorées : Les applications pratiques de YOLOv8 dans des scénarios réels sont vastes. Sa capacité à fournir une détection d’objets précise et en temps réel en fait un outil inestimable dans des domaines tels que la conduite autonome, l’automatisation industrielle et les initiatives de villes intelligentes.
- Inspirer les innovations futures : Le succès de YOLOv8 sert d’inspiration pour les développements futurs en vision par ordinateur (computer vision) et en IA. Il prépare le terrain pour de nouvelles recherches et innovations, repoussant les limites de ce que ces technologies peuvent réaliser.
En résumé, YOLOv8 n’a pas seulement fait progresser les aspects techniques de la vision par ordinateur (computer vision), mais a également contribué à l’évolution plus large de l’IA. Son impact se voit dans les capacités améliorées des systèmes IA et les nouvelles possibilités qu’il ouvre pour l’innovation et l’application pratique dans divers domaines. Alors que nous continuons à explorer le potentiel de l’IA et de la vision par ordinateur (computer vision), YOLOv8 sera sans aucun doute considéré comme une étape importante dans ce voyage d’avancement technologique.
Questions Fréquentes sur YOLOv8
Alors que YOLOv8 continue de révolutionner le domaine de la vision par ordinateur (computer vision), de nombreuses questions émergent concernant ses capacités, ses applications et ses aspects techniques. Cette section FAQ vise à fournir des réponses claires et concises à certaines des questions les plus courantes sur YOLOv8. Que vous soyez un développeur expérimenté ou que vous débutiez, ces réponses vous aideront à approfondir votre compréhension de ce modèle de détection d’objets à la pointe de la technologie.
Qu’est-ce que YOLOv8 et en quoi diffère-t-il des versions précédentes de YOLO ?
YOLOv8 est la dernière itération de la série YOLO de détecteurs d’objets en temps réel, offrant des performances de premier ordre en termes de précision et de vitesse. Il s’appuie sur les avancées des versions précédentes comme YOLOv5 avec des améliorations incluant des architectures de base et de cou plus avancées, une tête Ultralytics sans ancre pour une précision accrue, et un équilibre optimal entre précision et vitesse pour la détection d’objets en temps réel. Il propose également une gamme de modèles pré-entraînés pour différentes tâches et exigences de performance.
Comment la détection sans ancre dans YOLOv8 améliore-t-elle la détection d’objets ?
YOLOv8 adopte une approche de détection sans ancre, prédisant directement les centres des objets, ce qui simplifie l’architecture du modèle et améliore la précision. Cette méthode est particulièrement efficace pour détecter des objets de différentes formes et tailles. En réduisant le nombre de prédictions de boîtes, elle accélère le processus de suppression non maximale, crucial pour affiner les résultats de détection, rendant YOLOv8 plus efficace et précis par rapport à ses prédécesseurs qui utilisaient des boîtes d’ancrage.
Quelles sont les innovations clés et les améliorations dans l’architecture de YOLOv8 ?
YOLOv8 introduit plusieurs innovations architecturales significatives, y compris le dos CSPNet pour une extraction efficace des caractéristiques et la tête PANet, améliorant la robustesse contre l’occlusion des objets et les variations d’échelle. Son augmentation de données en mosaïque pendant l’entraînement expose le modèle à un éventail plus large de scénarios, améliorant sa généralisabilité. YOLOv8 combine également l’apprentissage supervisé et non supervisé, contribuant à ses performances de détection améliorées dans les tâches de détection d’objets et de segmentation d’instances.
Pour commencer à utiliser YOLOv8, vous devez d’abord installer le package Python YOLOv8. Ensuite, dans votre script Python, importez le module YOLOv8, créez une instance de la classe YOLOv8 et chargez les poids pré-entraînés. Ensuite, utilisez la méthode detect pour effectuer la détection d’objets sur une image. Les résultats contiendront des informations sur les objets détectés, y compris leurs classes, les scores de confiance et les coordonnées de la boîte englobante.
Quelles sont quelques applications pratiques de YOLOv8 dans différentes industries ?
YOLOv8 a des applications polyvalentes dans diverses industries en raison de sa grande vitesse et précision. Dans les véhicules autonomes, il assiste à l’identification et à la classification des objets en temps réel. Il est utilisé dans les systèmes de surveillance pour la détection et la reconnaissance d’objets en temps réel. Les détaillants utilisent YOLOv8 pour analyser le comportement des clients et gérer les stocks. Dans le domaine de la santé, il aide à l’analyse détaillée des images médicales, améliorant le diagnostic et les soins aux patients.
Comment YOLOv8 se comporte-t-il sur le jeu de données COCO et qu’est-ce que cela signifie pour sa précision ?
YOLOv8 démontre une performance remarquable sur le jeu de données COCO, un standard de référence pour les modèles de détection d’objets. Sa précision moyenne (mAP) varie selon la taille du modèle, avec le plus grand modèle, YOLOv8x, atteignant le mAP le plus élevé. Cela met en évidence des améliorations significatives en termes de précision par rapport aux versions précédentes de YOLO. Le mAP élevé indique une précision supérieure dans la détection d’une large gamme d’objets dans diverses conditions.
Quelles sont les limitations de YOLOv8, et y a-t-il des scénarios où il pourrait ne pas être le meilleur choix ?
Malgré ses performances impressionnantes, YOLOv8 a des limitations, notamment dans la prise en charge des modèles entraînés à haute résolution comme 1280. Pour les applications nécessitant une inférence haute résolution, YOLOv8 peut ne pas être idéal. Cependant, pour la plupart des applications, il surpasse les modèles précédents en termes de précision et de performance. Ses détections sans ancre et son architecture améliorée le rendent adapté à un large éventail de projets de vision par ordinateur (computer vision).
Puis-je entraîner YOLOv8 sur un jeu de données personnalisé, et quels sont quelques conseils pour un entraînement efficace ?
Oui, YOLOv8 peut être entraîné sur des jeux de données personnalisés. Un entraînement efficace implique d’expérimenter avec des techniques d’augmentation de données, notamment l’augmentation en mosaïque, et d’optimiser les hyperparamètres tels que le taux d’apprentissage, la taille du lot et le nombre d’époques. Une évaluation régulière et un ajustement fin sont cruciaux pour maximiser les performances. Choisir le bon jeu de données et le régime d’entraînement est essentiel pour garantir que le modèle se généralise bien aux nouvelles données.
Quelles sont les étapes clés pour déployer YOLOv8 dans un environnement réel ? Déployer
Déployer YOLOv8 implique d’optimiser le modèle pour la plateforme cible, de l’intégrer dans les systèmes existants, et de tester pour l’exactitude et la fiabilité. Une surveillance continue après le déploiement garantit un fonctionnement efficace. Pour les dispositifs de bord, l’optimisation du modèle pourrait inclure la quantification ou l’élagage. Des mises à jour et une maintenance régulières sont essentielles pour garder le modèle efficace et sécurisé dans diverses applications.
À quoi ressemble l’avenir pour YOLOv8 et ses applications en vision par ordinateur (computer vision) ?
L’avenir de YOLOv8 en vision par ordinateur (computer vision) semble prometteur, avec un potentiel pour une précision, une vitesse et une polyvalence encore plus grandes. Sa technologie évolutive, y compris la détection d’objets et la segmentation d’instances, pourrait trouver de nouvelles applications dans des domaines tels que l’imagerie médicale, la conservation de la faune et des systèmes autonomes plus avancés. Des efforts continus de recherche et de développement sont susceptibles de repousser les limites de YOLOv8, consolidant davantage sa position en tant que modèle de détection d’objets de premier plan.