
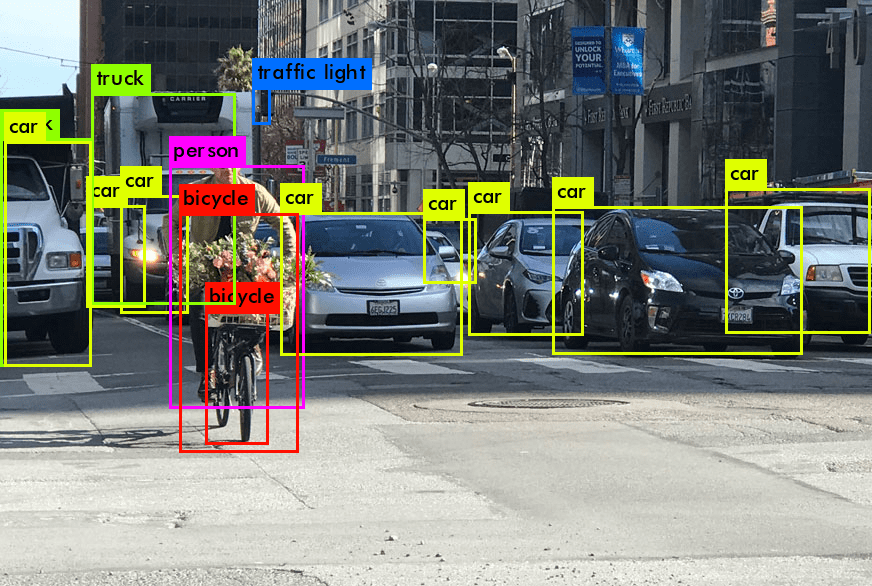
Introdução à Visão Computacional (computer vision) e ao Modelo YOLO
A visão computacional (computer vision), um campo da inteligência artificial, visa dar às máquinas a capacidade de interpretar e entender o mundo visual. Envolve a captura, processamento e análise de imagens ou vídeos para automatizar tarefas que o sistema visual humano pode fazer. Este campo em rápida evolução abrange várias aplicações, desde reconhecimento facial e rastreamento de objetos até atividades mais avançadas como condução autônoma. O desenvolvimento da visão computacional (computer vision) depende fortemente de grandes conjuntos de dados, algoritmos sofisticados e recursos computacionais poderosos.
Um avanço neste campo ocorreu com o desenvolvimento do modelo YOLO (You Only Look Once). Projetado como um modelo de detecção de objetos de última geração, o YOLO revolucionou a abordagem para detectar objetos em imagens. Modelos de detecção tradicionais muitas vezes envolviam um processo de dois passos: primeiro identificar regiões de interesse e depois classificar essas regiões. Em contraste, o YOLO inovou ao prever tanto as classificações quanto as caixas delimitadoras em uma única passagem pela rede neural, acelerando significativamente o processo e melhorando as capacidades de detecção em tempo real.
Este modelo de detecção de objetos passou por várias iterações, com cada versão introduzindo novos recursos e melhorias. O YOLOv8, a versão mais recente da Ultralytics, baseia-se no sucesso de seus predecessores como o YOLOv5. Incorpora técnicas avançadas de aprendizado de máquina para melhorar a precisão e a velocidade, tornando-o uma escolha popular para tarefas de visão computacional (computer vision). A natureza de código aberto dos modelos YOLO, como o repositório YOLOv8 no GitHub, contribuiu ainda mais para sua adoção generalizada e desenvolvimento contínuo.
A eficácia do YOLO na detecção de objetos, segmentação de instâncias e tarefas de classificação tornou-o um elemento básico em projetos de visão computacional (computer vision). Simplificando o processo de identificar e categorizar objetos dentro de imagens, modelos YOLO como o YOLOv8 ajudam as máquinas a entender o mundo visual de forma mais precisa e eficiente.
YOLOv8: O Novo Estado da Arte em Visão Computacional (computer vision)
O YOLOv8 representa o ápice do progresso no domínio da visão computacional (computer vision), estabelecendo-se como o novo estado da arte em modelos de detecção de objetos. Desenvolvido pela Ultralytics, esta versão da série de modelos YOLO apresenta avanços significativos em relação ao seu antecessor, o YOLOv5, e versões anteriores do YOLO. O YOLOv8 vem equipado com uma série de novas funcionalidades que aprimoram suas capacidades de detecção, tornando-o mais preciso e eficiente do que nunca.
Um dos avanços notáveis no YOLOv8 é sua adoção da detecção sem âncoras, que pode ser vista em detalhes aqui anchor-free detection. Esta nova abordagem se afasta da tradicional dependência de caixas âncora, que eram um elemento fundamental nos modelos YOLO anteriores. A detecção sem âncoras simplifica a arquitetura do modelo e melhora sua capacidade de prever locais de objetos com maior precisão. Esse aprimoramento é particularmente benéfico em cenários onde o conjunto de dados inclui objetos de formas e tamanhos variados.
O modelo YOLOv8 também se destaca em tarefas de segmentação, um aspecto crítico da visão computacional (computer vision). Seja para detecção de objetos, segmentação de instâncias ou modelos de segmentação mais gerais, o YOLOv8, especialmente o modelo YOLOv8 Nano, demonstra uma proficiência notável. Sua capacidade de segmentar e classificar precisamente diferentes partes de uma imagem o torna altamente eficaz em diversas aplicações, desde imagens médicas até navegação de veículos autônomos.
Outro aspecto chave do YOLOv8 é seu pacote Python, que facilita a integração e uso em projetos baseados em Python. Essa acessibilidade é crucial, especialmente considerando a popularidade do Python nas comunidades de ciência de dados e aprendizado de máquina. Os desenvolvedores podem treinar um modelo YOLOv8 em um conjunto de dados personalizado usando PyTorch, uma das principais frameworks de aprendizado profundo. Essa flexibilidade permite soluções sob medida para desafios específicos de visão computacional (computer vision).
O desempenho do YOLOv8 é ainda mais reforçado por suas métricas de desempenho de modelo de última geração. Essas métricas demonstram a capacidade do modelo de detectar objetos com alta precisão e velocidade, fatores cruciais em aplicações em tempo real. Além disso, como um modelo de código aberto disponível no GitHub, o YOLOv8 se beneficia de melhorias contínuas e contribuições da comunidade global de desenvolvedores.
Em conclusão, o YOLOv8 estabelece um novo marco no campo da visão computacional (computer vision). Seus avanços em detecção de objetos, segmentação e desempenho geral do modelo o tornam uma ferramenta inestimável para desenvolvedores e pesquisadores que buscam expandir os limites do que é possível na interpretação visual impulsionada por IA.
Arquitetura YOLOv8: A Espinha Dorsal dos Novos Avanços em Visão Computacional (computer vision)
A arquitetura YOLOv8 representa um salto significativo no campo da visão computacional (computer vision), estabelecendo um novo padrão de última geração. Como a versão mais recente do YOLO, o YOLOv8 introduz várias melhorias em relação aos seus predecessores, como o YOLOv5 e versões anteriores do YOLO. Compreender a arquitetura YOLOv8 é crucial para aqueles que procuram treinar o modelo para tarefas especializadas de detecção de objetos.
Uma das características fundamentais do YOLOv8 é sua cabeça de detecção livre de âncoras, uma mudança em relação à abordagem tradicional de caixa de âncora usada nas versões anteriores do YOLO. Essa mudança simplifica o modelo enquanto mantém, e em muitos casos aumenta, a precisão na detecção de objetos. O YOLOv8 suporta uma ampla gama de aplicações, desde detecção de objetos em tempo real até segmentação de imagens.
O modelo YOLOv8 é projetado para eficiência e desempenho. O modelo YOLOv8 de código aberto pode ser treinado em vários conjuntos de dados, incluindo o amplamente utilizado conjunto de dados COCO. Essa flexibilidade permite que os usuários personalizem o modelo para necessidades específicas, seja para detecção de objetos em geral ou tarefas especializadas como estimativa de pose.
A arquitetura do YOLOv8 é otimizada tanto para velocidade quanto para precisão, um fator crucial em aplicações em tempo real. O design do modelo também inclui melhorias na segmentação de imagens, tornando-o um modelo abrangente de detecção e segmentação de imagens. A série Ultralytics YOLO, particularmente o YOLOv8, sempre esteve na vanguarda do avanço dos modelos de visão computacional (computer vision), e o YOLOv8 continua essa tradição.
Para aqueles que desejam começar com o YOLOv8, o repositório da Ultralytics oferece recursos abundantes. O repositório, disponível no GitHub, oferece instruções detalhadas sobre como treinar o modelo YOLOv8, incluindo a configuração do ambiente de treinamento e o carregamento dos pesos do modelo.
Modelo de Detecção de Objetos YOLOv8: Revolucionando a Detecção e Segmentação
O modelo de detecção de objetos YOLOv8 é a mais recente adição à série YOLO, criado por Joseph Redmon e Ali Farhadi. Ele está na vanguarda dos avanços em visão computacional (computer vision), representando o novo estado da arte tanto em detecção de objetos quanto em segmentação de imagens. As capacidades do YOLOv8 vão além da mera detecção de objetos; ele também se destaca em tarefas como segmentação de instâncias e detecção em tempo real, tornando-o uma ferramenta versátil para uma variedade de aplicações.
O YOLOv8 utiliza uma abordagem inovadora para detecção, integrando características que o tornam um detector de objetos altamente preciso. O modelo incorpora uma cabeça de detecção livre de âncoras, que simplifica o processo de detecção e aumenta a precisão. Esta é uma mudança significativa em relação ao método de caixa de âncora usado nas versões anteriores do YOLO.
O treinamento do modelo YOLOv8 é um processo direto, especialmente com os recursos fornecidos no repositório do GitHub do YOLOv8. O repositório inclui instruções detalhadas sobre como treinar o modelo usando um conjunto de dados personalizado, permitindo que os usuários adaptem o modelo às suas necessidades específicas. Por exemplo, treinar modelos em um conjunto de dados por 100 épocas pode resultar em uma melhoria significativa no desempenho do modelo, conforme evidenciado pelas avaliações no conjunto de validação.
Além disso, a arquitetura do YOLOv8 é projetada para suportar efetivamente tarefas de detecção de objetos e segmentação de imagens. Essa versatilidade é evidente em sua aplicação em vários domínios, de vigilância a condução autônoma. O YOLOv8 introduz novos recursos que aumentam sua eficiência, como melhorias nos últimos dez épocas de treinamento, que otimizam o aprendizado e a precisão do modelo.
Em resumo, o YOLOv8 representa um avanço significativo na série YOLO e no campo mais amplo da visão computacional (computer vision). Sua arquitetura e recursos de última geração o tornam uma escolha ideal para desenvolvedores e pesquisadores que procuram implementar modelos avançados de detecção e segmentação em seus projetos. O repositório da Ultralytics é um excelente ponto de partida para quem está interessado em explorar as capacidades do YOLOv8 e implantá-lo em cenários do mundo real.
Formato de Anotação YOLOv8: Preparando Dados para Treinamento
Preparar dados para treinamento é um passo crítico no desenvolvimento de qualquer modelo de visão computacional (computer vision), e o YOLOv8 não é exceção. O formato de anotação YOLOv8 desempenha um papel crucial neste processo, pois influencia diretamente a aprendizagem e a precisão do modelo. Uma anotação adequada garante que o modelo possa identificar e aprender corretamente com os diversos elementos dentro de um conjunto de dados, o que é crucial para a detecção eficaz de objetos e segmentação de imagens.
O formato de anotação do YOLOv8 é único e distinto de outros formatos usados em visão computacional (computer vision). Ele requer detalhamento preciso dos objetos nas imagens, tipicamente através de caixas delimitadoras e rótulos. Cada objeto em uma imagem é marcado com uma caixa delimitadora, e essas caixas são rotuladas com classes que o modelo precisa identificar. Esse formato é crítico para o treinamento do modelo YOLOv8, pois ajuda o modelo a entender a localização e categoria de cada objeto dentro de uma imagem.
Preparar um conjunto de dados para o YOLOv8 envolve anotar um grande número de imagens, o que pode ser um processo demorado. No entanto, o esforço é essencial para alcançar um alto desempenho do modelo. A qualidade e a precisão das anotações impactam diretamente na capacidade do modelo de aprender e fazer previsões precisas.
Para aqueles que procuram treinar um modelo YOLOv8, entender e implementar o formato de anotação correto é chave. Esse processo geralmente envolve o uso de ferramentas de anotação especializadas que permitem aos usuários desenhar caixas delimitadoras e rotulá-las adequadamente. O conjunto de dados anotado é então usado para treinar o modelo, ensinando-o a reconhecer e categorizar objetos com base nos rótulos fornecidos e nas coordenadas das caixas delimitadoras.
Treinamento do YOLOv8: Um Guia Passo a Passo
O treinamento do YOLOv8 é um processo que requer preparação cuidadosa e execução para alcançar o desempenho ótimo do modelo. O processo de treinamento envolve várias etapas, desde a configuração do ambiente até o ajuste fino do modelo em um conjunto de dados específico. Aqui está um guia passo a passo para treinar o YOLOv8:
- Configuração do Ambiente: O primeiro passo é configurar o ambiente de treinamento. Isso envolve instalar o software e as dependências necessárias. O YOLOv8, sendo um modelo baseado em Python, requer um ambiente Python com bibliotecas como PyTorch.
- Preparação dos Dados: Em seguida, prepare seu conjunto de dados de acordo com o formato de anotação do YOLOv8. Isso envolve anotar imagens com caixas delimitadoras e rótulos para definir os objetos que o modelo precisa aprender a detectar.
- Configuração do Modelo: Antes de iniciar o treinamento, configure o modelo YOLOv8 de acordo com suas necessidades. Isso pode envolver ajustar parâmetros como taxa de aprendizado, tamanho do lote e número de épocas.
- Treinamento do Modelo: Com o ambiente e os dados configurados, você pode iniciar o processo de treinamento. Isso envolve alimentar o conjunto de dados anotado ao modelo e permitir que ele aprenda com os dados. O modelo ajusta iterativamente seus pesos e vieses para minimizar erros na detecção.
- Avaliação do Desempenho: Após o treinamento, avalie o desempenho do modelo usando métricas como precisão, recall e Precisão Média Média (mAP). Isso ajuda a entender quão bem o modelo pode detectar e classificar objetos em imagens.
- Ajuste Fino: Com base na avaliação, você pode precisar fazer um ajuste fino no modelo. Isso pode envolver retrair o modelo com parâmetros ajustados ou fornecer a ele dados de treinamento adicionais.
- Implantação: Uma vez que o modelo esteja treinado e ajustado, ele está pronto para ser implantado em aplicações do mundo real.
Treinar um modelo YOLOv8 requer atenção aos detalhes e um entendimento profundo de como o modelo funciona. No entanto, o esforço compensa com um modelo de detecção de objetos robusto, preciso e eficiente, adequado para várias aplicações em visão computacional (computer vision).
Implantando YOLOv8 em Aplicações do Mundo Real
Implantar o YOLOv8 em aplicações do mundo real é um passo crítico para aproveitar suas capacidades avançadas de detecção de objetos. A implantação bem-sucedida traduz a proficiência teórica do modelo em soluções práticas e acionáveis em várias indústrias. Aqui está um guia abrangente para implantar o YOLOv8:
- Escolhendo a Plataforma Certa: O primeiro passo é decidir onde o modelo YOLOv8 será implantado. Isso pode variar desde servidores baseados em nuvem para aplicações em grande escala até dispositivos de borda para processamento em tempo real no local, como a solução de plataforma de visão computacional (computer vision) de visionplatform.ai (https://visionplatform.eu-1.slashinfra.nl/computer-vision-platform/).
- Otimizando o Modelo: Dependendo da plataforma de implantação, pode ser necessário otimizar o modelo YOLOv8 para desempenho. Técnicas como quantização de modelo ou poda podem ser usadas para reduzir o tamanho do modelo sem comprometer significativamente a precisão, tornando-o adequado para dispositivos com recursos computacionais limitados.
- Integração com Sistemas Existentes: Em muitos casos, o modelo YOLOv8 precisará ser integrado a sistemas de software ou hardware existentes. Isso requer um entendimento profundo desses sistemas e a capacidade de interfacear o modelo YOLOv8 usando APIs apropriadas ou frameworks de software.
- Testes e Validação: Antes da implantação em grande escala, é crucial testar o modelo em um ambiente controlado para garantir que ele funcione conforme o esperado. Isso envolve validar a precisão, velocidade e confiabilidade do modelo sob diferentes condições.
- Implantação e Monitoramento: Uma vez testado, implante o modelo na plataforma escolhida. O monitoramento contínuo é essencial para garantir que o modelo opere corretamente e de maneira eficiente ao longo do tempo. Isso também ajuda a identificar e corrigir quaisquer problemas que possam surgir após a implantação.
- Atualizações e Manutenção: Como qualquer software, o modelo YOLOv8 implantado pode requerer atualizações periódicas para melhorias ou para enfrentar novos desafios. A manutenção regular garante que o modelo permaneça eficaz e seguro.
Implantar o YOLOv8 de forma eficaz exige uma abordagem estratégica, considerando fatores como o ambiente operacional, limitações computacionais, e desafios de integração. Quando feito corretamente, o YOLOv8 pode aumentar significativamente as capacidades de sistemas em setores como segurança, saúde, transporte e varejo.
YOLOv8 vs YOLOv5: Comparando Modelos de Detecção de Objetos
Comparar o YOLOv8 e o YOLOv5 é essencial para entender os avanços nos modelos de detecção de objetos e decidir qual modelo é mais adequado para uma aplicação específica. Ambos os modelos são de última geração em suas capacidades, mas possuem características e métricas de desempenho distintas.
- Arquitetura do Modelo: O YOLOv8 introduz várias melhorias arquitetônicas em relação ao YOLOv5. Isso inclui aprimoramentos nas camadas de detecção e a integração de novas tecnologias como detecção sem âncoras, que melhora a precisão e eficiência do modelo.
- Precisão e Velocidade: O YOLOv8 mostrou melhorias na precisão e velocidade de detecção em comparação ao YOLOv5. Isso é particularmente evidente em cenários de detecção desafiadores que envolvem objetos pequenos ou sobrepostos.
- Treinamento e Flexibilidade: Ambos os modelos oferecem flexibilidade no treinamento, permitindo que os usuários treinem em conjuntos de dados personalizados. No entanto, o YOLOv8 fornece recursos mais avançados para ajuste fino do modelo, o que pode levar a um melhor desempenho em tarefas específicas.
- Adequação à Aplicação: Embora o YOLOv5 permaneça uma opção poderosa para muitas aplicações, os avanços do YOLOv8 o tornam mais adequado para cenários onde a máxima precisão e velocidade são cruciais.
- Comunidade e Suporte: Ambos os modelos se beneficiam de um forte suporte comunitário e são amplamente utilizados, garantindo melhorias contínuas e recursos extensivos para desenvolvedores.
Em conclusão, enquanto o YOLOv5 continua sendo um modelo robusto e eficiente para detecção de objetos, o YOLOv8 representa os avanços mais recentes no campo, oferecendo precisão e desempenho melhorados. A escolha entre os dois depende dos requisitos específicos da aplicação, incluindo fatores como recursos computacionais, complexidade da tarefa de detecção e a necessidade de processamento em tempo real.
Explorando as Variantes dos Modelos YOLO
A série YOLO (You Only Look Once) abrange uma variedade de modelos adaptados para várias aplicações em detecção de objetos, cada um diferindo em tamanho, velocidade e precisão. Desde o modelo YOLOv8n leve, projetado para dispositivos de borda, até o YOLOv8x altamente preciso, adequado para pesquisas aprofundadas, essas variantes atendem a ambientes de computação diversos e requisitos de aplicação. Esta exploração fornece uma visão geral dos diferentes tipos de modelos YOLO, destacando suas características únicas e casos de uso ótimos.
| Atributo / Modelo | YOLOv8n (Nano) | YOLOv8s (Pequeno) | YOLOv8m (Médio) | YOLOv8l (Grande) | YOLOv8x (Extra Grande) | |
|---|---|---|---|---|---|---|
| Tamanho | Muito Pequeno | Pequeno | Médio | Grande | Muito Grande | |
| Velocidade | Muito Rápido | Rápido | Moderado | Lento | Muito Lento | |
| Precisão | Inferior | Moderada | Alta | Muito Alta | Máxima | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Resolução | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
Comparando o Yolo com modelos anteriores como YOLOv5, YOLOv6, YOLOv7 e YOLOv8 mostra que o YOLOv8 é tanto melhor quanto mais rápido que suas versões anteriores.
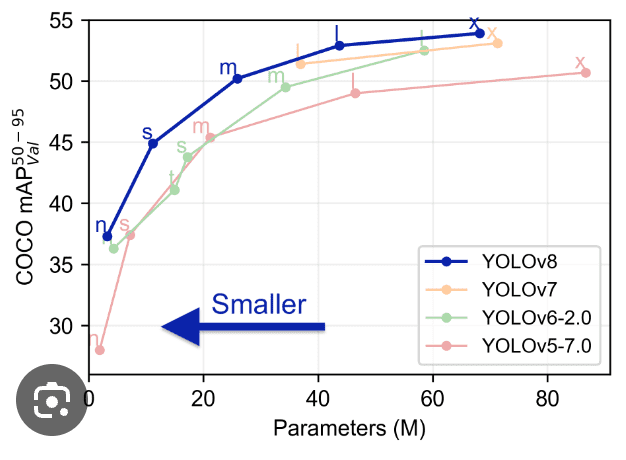
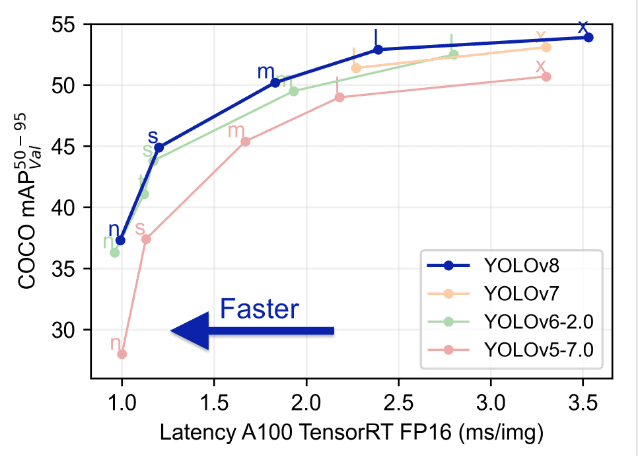
Recursos Avançados no YOLOv8: Aprimorando o Desempenho do Modelo
O desempenho do modelo YOLOv8 se destaca no campo da visão computacional (computer vision), graças a um conjunto de recursos avançados que aprimoram suas capacidades. Esses recursos contribuem significativamente para o status do YOLOv8 como um modelo de última geração para tarefas de detecção e segmentação de objetos. Uma análise detalhada desses recursos revela por que o YOLOv8 é uma escolha principal para desenvolvedores e pesquisadores:
- Detecção Sem Âncoras: O YOLOv8 se afasta das tradicionais caixas de âncora para um sistema de detecção sem âncoras. Isso simplifica a arquitetura do modelo, incluindo o modelo YOLOv8 Nano, e melhora sua capacidade de prever com precisão a localização dos objetos, especialmente para imagens com formas e tamanhos de objetos diversos.
- Camadas Convolutivas Aprimoradas: O YOLOv8 introduz mudanças em seus blocos convolutivos, substituindo as convoluções
6x6por3x3. Essa mudança aprimora a capacidade do modelo de extrair e aprender detalhes das imagens, melhorando sua precisão de detecção geral. - Augmentação de Dados em Mosaico: Exclusivo para o YOLOv8 é a implementação da augmentação de dados em mosaico durante o treinamento. Esta técnica junta quatro imagens diferentes, aprimorando a capacidade do modelo de detectar objetos em contextos e fundos variados. No entanto, o YOLOv8 desativa estrategicamente essa augmentação nas últimas dez épocas de treinamento para otimizar o desempenho.
- Integração com PyTorch: Como um pacote Python, o YOLOv8 beneficia-se da integração perfeita com o PyTorch, uma das principais plataformas em aprendizado de máquina. Essa integração simplifica o processo de treinamento e implantação do modelo, especialmente ao trabalhar com conjuntos de dados personalizados.
- Detecção de Objetos em Múltiplas Escalas: A arquitetura do YOLOv8 é projetada para a detecção de objetos em múltiplas escalas. Esse recurso permite que o modelo detecte objetos de tamanhos variados dentro de uma imagem com precisão, tornando-o versátil em diferentes cenários de aplicação.
- Capacidades de Processamento em Tempo Real: Uma das vantagens mais significativas do YOLOv8 é sua capacidade de realizar detecção de objetos em tempo real. Esse recurso é crucial para aplicações que exigem análise e resposta imediatas, como condução autônoma e vigilância em tempo real.
Esses recursos avançados sublinham a capacidade do YOLOv8 como uma ferramenta poderosa no domínio da visão computacional (computer vision). Sua combinação de precisão, velocidade e flexibilidade o torna uma excelente escolha para um amplo espectro de aplicações de detecção e segmentação de objetos.
Começando com YOLOv8: Da Configuração ao Implantação
Começar com YOLOv8, especialmente para aqueles novos no campo da visão computacional (computer vision), pode parecer assustador. No entanto, com a orientação correta, configurar e implantar YOLOv8 pode ser um processo simplificado. Aqui está um guia passo a passo para começar com YOLOv8:
- Entendendo o Básico: Antes de mergulhar no YOLOv8, é crucial ter um entendimento básico dos conceitos de visão computacional (computer vision) e dos princípios por trás dos modelos de detecção de objetos. Esse conhecimento fundamental ajudará a compreender como o YOLOv8 opera.
- Configurando o Ambiente: O primeiro passo técnico envolve configurar o ambiente de programação. Isso inclui instalar Python, PyTorch e outras bibliotecas necessárias. A documentação do YOLOv8 fornece orientações detalhadas sobre o processo de configuração.
- Acessando os Recursos do YOLOv8: O repositório GitHub do YOLOv8 é um recurso valioso. Ele contém o código do modelo, pesos pré-treinados e documentação extensiva. Familiarizar-se com esses recursos é crucial para uma implementação bem-sucedida.
- Treinando o Modelo: Para treinar o YOLOv8, você precisa de um conjunto de dados. Para iniciantes, é aconselhável usar um conjunto de dados padrão como o COCO. O processo de treinamento envolve ajustar o modelo ao seu conjunto de dados específico para otimizar seu desempenho para sua aplicação.
- Avaliando o Modelo: Após o treinamento, avalie o desempenho do modelo usando métricas padrão como precisão, recall e Precisão Média Média (mAP). Esta etapa é crucial para garantir que o modelo esteja detectando objetos com precisão.
- Implantação: Com um modelo treinado e testado, como o modelo YOLOv8 Nano, o próximo passo é a implantação. Isso pode ser em um servidor para aplicações baseadas na web ou em um dispositivo de borda para processamento em tempo real usando visionplatform.ai.
- Aprendizado Contínuo: O campo da visão computacional (computer vision) está evoluindo rapidamente. Manter-se atualizado com os últimos avanços e aprender continuamente é chave para usar efetivamente o YOLOv8 que você faz efetivamente através de uma plataforma de visão computacional (computer vision platform).
Começar com YOLOv8 envolve uma mistura de entendimento teórico e aplicação prática. Seguindo esses passos, pode-se implementar e utilizar com sucesso o YOLOv8 em várias tarefas de visão computacional (computer vision), aproveitando todo o seu potencial em detecção de objetos e segmentação de imagens.
O Futuro da Visão Computacional: Novidades no YOLOv8 e Além
O futuro da visão computacional (computer vision) é incrivelmente promissor, com o YOLOv8 liderando a frente como o modelo mais recente e avançado da série YOLO. A introdução do YOLOv8 marca um marco significativo na evolução contínua das tecnologias de visão computacional, oferecendo precisão e eficiência sem precedentes em tarefas de detecção de objetos. Aqui estão as novidades no YOLOv8 e as implicações para o futuro da visão computacional:
- Avanços Tecnológicos: O YOLOv8 introduziu várias melhorias tecnológicas em relação aos seus predecessores. Estas incluem redes convolucionais mais eficientes, detecção sem âncoras e algoritmos aprimorados para detecção de objetos em tempo real.
- Aumento da Acessibilidade e Aplicação: Com o YOLOv8, o campo da visão computacional torna-se mais acessível a uma gama mais ampla de usuários, incluindo aqueles sem extensa expertise em codificação. Esta democratização da tecnologia fomenta a inovação e encoraja aplicações diversas em vários setores.
- Integração com Tecnologias Emergentes: A compatibilidade do YOLOv8 com frameworks avançados de aprendizado de máquina e sua capacidade de integração com outras tecnologias de ponta, como realidade aumentada e robótica, sinalizam um futuro onde as soluções de visão computacional são cada vez mais versáteis e poderosas.
- Melhoria das Métricas de Desempenho: O YOLOv8 estabeleceu novos padrões de desempenho do modelo, particularmente em termos de precisão e velocidade de processamento. Esta melhoria é crucial para aplicações que requerem análise em tempo real, como veículos autônomos e tecnologias para cidades inteligentes.
- Previsões para Desenvolvimentos Futuros: Olhando para o futuro, podemos antecipar mais avanços nos modelos de visão computacional, com ainda mais precisão, velocidade e adaptabilidade. A integração da IA com a visão computacional provavelmente continuará a evoluir, levando a sistemas mais sofisticados e autônomos.
O desenvolvimento contínuo do YOLOv8 e modelos similares é um testemunho da natureza dinâmica do campo da visão computacional. À medida que a tecnologia avança, podemos esperar ver mais inovações revolucionárias que redefinirão os limites do que os sistemas de visão computacional podem alcançar.
Conclusão: O Impacto do YOLOv8 na Visão Computacional e IA
Em conclusão, o YOLOv8 teve um impacto substancial no campo da visão computacional (computer vision) e IA. Suas características avançadas e capacidades representam um salto significativo na tecnologia de detecção de objetos. As implicações dos avanços do YOLOv8 vão além do âmbito técnico, influenciando diversas indústrias e aplicações:
- Avanços na Detecção de Objetos: YOLOv8 estabeleceu um novo padrão em detecção de objetos com sua precisão, velocidade e eficiência melhoradas. Isso tem implicações para uma ampla gama de aplicações, desde segurança e vigilância até saúde, manufatura, logística e monitoramento ambiental.
- Democratização da Tecnologia de IA: Ao tornar a tecnologia de visão computacional (computer vision) avançada, como o repositório YOLOv8, mais acessível e fácil de usar, o YOLOv8 abriu a porta para uma gama mais ampla de usuários e desenvolvedores inovarem e criarem soluções baseadas em IA.
- Aplicações Realistas Aprimoradas: As aplicações práticas do YOLOv8 em cenários do mundo real são vastas. Sua capacidade de fornecer detecção de objetos precisa e em tempo real o torna uma ferramenta inestimável em áreas como condução autônoma, automação industrial e iniciativas de cidades inteligentes.
- Inspirando Futuras Inovações: O sucesso do YOLOv8 serve como inspiração para futuros desenvolvimentos em visão computacional (computer vision) e IA. Ele prepara o terreno para mais pesquisas e inovações, expandindo os limites do que essas tecnologias podem alcançar.
Em resumo, o YOLOv8 não apenas avançou os aspectos técnicos da visão computacional (computer vision), mas também contribuiu para a evolução mais ampla da IA. Seu impacto é visto nas capacidades aprimoradas dos sistemas de IA e nas novas possibilidades que ele abre para inovação e aplicação prática em diversos campos. À medida que continuamos a explorar o potencial da IA e da visão computacional (computer vision), o YOLOv8 será, sem dúvida, lembrado como um marco nesta jornada de avanço tecnológico.
Perguntas Frequentes Sobre o YOLOv8
À medida que o YOLOv8 continua a revolucionar o campo da visão computacional (computer vision), surgem numerosas perguntas sobre suas capacidades, aplicações e aspectos técnicos. Esta seção de FAQ visa fornecer respostas claras e concisas para algumas das consultas mais comuns sobre o YOLOv8. Seja você um desenvolvedor experiente ou apenas começando, essas respostas ajudarão a aprofundar seu entendimento deste modelo de detecção de objetos de última geração.
O que é YOLOv8 e como ele difere das versões anteriores do YOLO?
YOLOv8 é a mais recente iteração na série YOLO de detectores de objetos em tempo real, oferecendo desempenho de ponta em termos de precisão e velocidade. Ele se baseia nos avanços de versões anteriores como o YOLOv5 com melhorias que incluem arquiteturas avançadas de backbone e neck, uma cabeça Ultralytics sem âncoras para maior precisão, e um equilíbrio ótimo entre precisão e velocidade para detecção de objetos em tempo real. Ele também oferece uma gama de modelos pré-treinados para diferentes tarefas e requisitos de desempenho.
Como a detecção sem âncoras no YOLOv8 aprimora a detecção de objetos?
YOLOv8 adota uma abordagem de detecção sem âncoras, prevendo diretamente os centros dos objetos, o que simplifica a arquitetura do modelo e melhora a precisão. Este método é particularmente eficaz na detecção de objetos de várias formas e tamanhos. Ao reduzir o número de previsões de caixas, ele acelera o processo de Supressão Não Máxima, crucial para refinar os resultados da detecção, tornando o YOLOv8 mais eficiente e preciso em comparação com seus predecessores que usavam caixas de âncora.
Quais são as principais inovações e melhorias na arquitetura do YOLOv8?
YOLOv8 introduz várias inovações arquitetônicas significativas, incluindo o backbone CSPNet para extração eficiente de características e a cabeça PANet, que aumenta a robustez contra oclusão de objetos e variações de escala. Sua augmentação de dados em mosaico durante o treinamento expõe o modelo a uma ampla gama de cenários, aumentando sua generalização. O YOLOv8 também combina aprendizado supervisionado e não supervisionado, contribuindo para seu desempenho aprimorado em tarefas de detecção de objetos e segmentação de instâncias.Como posso começar a usar o YOLOv8 para minhas tarefas de detecção de objetos?
Para começar a usar o YOLOv8, você deve primeiro instalar o pacote Python do YOLOv8. Em seguida, no seu script Python, importe o módulo YOLOv8, crie uma instância da classe YOLOv8 e carregue os pesos pré-treinados. Depois, use o método detect para realizar a detecção de objetos em uma imagem. Os resultados conterão informações sobre os objetos detectados, incluindo suas classes, pontuações de confiança e coordenadas das caixas delimitadoras.
Quais são algumas aplicações práticas do YOLOv8 em diferentes indústrias?
YOLOv8 tem aplicações versáteis em várias indústrias devido à sua alta velocidade e precisão. Em veículos autônomos, ele auxilia na identificação e classificação de objetos em tempo real. É usado em sistemas de vigilância para detecção e reconhecimento de objetos em tempo real. Varejistas utilizam o YOLOv8 para analisar o comportamento do cliente e gerenciar o inventário. Na saúde, ele auxilia na análise detalhada de imagens médicas, melhorando diagnósticos e cuidados com o paciente.
Como o YOLOv8 se sai no conjunto de dados COCO e o que isso significa para sua precisão?
YOLOv8 demonstra um desempenho notável no conjunto de dados COCO, um padrão de referência para modelos de detecção de objetos. Sua precisão média de precisão (mAP) varia de acordo com o tamanho do modelo, com o modelo maior, YOLOv8x, alcançando o mAP mais alto. Isso destaca melhorias significativas na precisão em comparação com versões anteriores do YOLO. O alto mAP indica uma precisão superior na detecção de uma ampla gama de objetos em várias condições.
Quais são as limitações do YOLOv8 e existem cenários onde ele pode não ser a melhor escolha?
Apesar de seu desempenho impressionante, o YOLOv8 tem limitações, particularmente no suporte a modelos treinados em altas resoluções como 1280. Para aplicações que exigem inferência de alta resolução, o YOLOv8 pode não ser ideal. No entanto, para a maioria das aplicações, ele supera os modelos anteriores em precisão e desempenho. Suas detecções sem âncoras e arquitetura aprimorada o tornam adequado para uma ampla gama de projetos de visão computacional (computer vision).
Posso treinar o YOLOv8 em um conjunto de dados personalizado e quais são algumas dicas para um treinamento eficaz?
Sim, o YOLOv8 pode ser treinado em conjuntos de dados personalizados. O treinamento eficaz envolve experimentar técnicas de augmentação de dados, notavelmente a augmentação em mosaico, e otimizar hiperparâmetros como taxa de aprendizado, tamanho do lote e número de épocas. Avaliação regular e ajuste fino são cruciais para maximizar o desempenho. Escolher o conjunto de dados certo e o regime de treinamento é chave para garantir que o modelo generalize bem para novos dados.
Quais são as etapas chave para implantar o YOLOv8 em um ambiente real? Implantação
Implantar o YOLOv8 envolve otimizar o modelo para a plataforma alvo, integrá-lo aos sistemas existentes e testar sua precisão e confiabilidade. O monitoramento contínuo após a implantação garante uma operação eficiente. Para dispositivos de borda, a otimização do modelo pode incluir quantização ou poda. Atualizações regulares e manutenção são essenciais para manter o modelo eficaz e seguro em várias aplicações.
Como será o futuro do YOLOv8 e suas aplicações em visão computacional (computer vision)?
O futuro do YOLOv8 em visão computacional (computer vision) parece promissor, com potencial para ainda maior precisão, velocidade e versatilidade. Sua tecnologia em evolução, incluindo detecção de objetos e segmentação de instâncias, pode encontrar novas aplicações em áreas como imagens médicas, conservação da vida selvagem e sistemas autônomos mais avançados. Esforços contínuos de pesquisa e desenvolvimento provavelmente expandirão os limites do YOLOv8, consolidando ainda mais sua posição como um modelo líder em detecção de objetos.