
Optimisation des hyperparamètres pour YOLOv8 avec Weights & Biases : Une aventure avec les algorithmes de détection d’objets
Introduction
Lorsqu’on travaille sur des tâches de détection d’objets, il est essentiel d’optimiser la performance de votre modèle. Cela implique de choisir les bons hyperparamètres. Dans cet article, nous allons parcourir mon périple d’optimisation des hyperparamètres pour le modèle de détection d’objets YOLOv8 en utilisant Weights & Biases (W&B) et la méthode d’Optimisation Bayésienne.
Par Justas Andriuškevičius – Ingénieur en Apprentissage Automatique chez visionplatform.ai
Pourquoi l’optimisation des hyperparamètres ?
Chaque modèle d’apprentissage automatique est livré avec son ensemble de boutons et de molettes — les hyperparamètres. Choisir la bonne combinaison peut faire la différence entre un modèle moyen et un modèle haut de gamme. Mais, avec d’innombrables combinaisons possibles, comment choisir ? C’est là qu’interviennent l’optimisation des hyperparamètres et, plus spécifiquement, W&B.
Sélection de l’ensemble de données
Avant de plonger profondément dans les hyperparamètres, discutons de la sélection de l’ensemble de données. L’optimisation des hyperparamètres est une tâche gourmande en ressources. La conduire sur un ensemble de données complet prendrait énormément de temps – soyons réalistes ; personne n’a de temps pour cela, surtout lorsqu’on traite des ensembles de données volumineux.
Pour trouver un équilibre entre l’efficacité computationnelle et un ensemble de données représentatif, j’ai adopté une approche astucieuse. Étant donné un grand ensemble de données avec des images dans l’ordre des timestamps, j’ai créé un sous-ensemble en les triant par timestamp, qui ne représente que 1/4 de l’ensemble original. Cette méthode garantit que le modèle s’entraîne sur des données diversifiées, encapsulant à la fois les scènes de jour et de nuit, essentielles pour une tâche de détection d’objets. Tout en réduisant considérablement le temps de calcul par rapport à l’utilisation de l’ensemble complet. Pour l’évaluation, je me suis tenu à l’ensemble de validation original, car il offre une évaluation plus complète et impartiale des performances du modèle sur des données inconnues, et ce n’est déjà qu’une fraction de la taille d’origine de l’ensemble d’entraînement.
Le modèle YOLOv8 et ses hyperparamètres
Le modèle YOLOv8 (You Only Look Once) est favori pour les tâches de détection d’objets en raison de son efficacité. Plusieurs hyperparamètres influencent ses performances :
- Taille du lot (batch) : Elle détermine le nombre d’échantillons traités avant que le modèle ne mette à jour ses poids.
- Taille de l’image (imgsz) : Elle affecte la résolution des images introduites dans le modèle.
- Taux d’apprentissage (lr0) : Il contrôle la manière d’ajuster le modèle en réponse à l’erreur estimée à chaque mise à jour des poids du modèle.
- Optimiseur : Il influence la manière dont le modèle met à jour ses poids.
- Augmentation (augment) : Elle indique si l’on doit introduire des modifications aléatoires dans les données d’entrée, renforçant ainsi la robustesse du modèle.
- Dropout (dropout) : C’est une technique de régularisation pour éviter le surajustement.
Pourquoi l’optimisation bayésienne ?
Choisir les bons hyperparamètres peut ressembler à chercher une aiguille dans une botte de foin. L’optimisation bayésienne rend cette recherche plus intelligente. Imaginez que vous essayez d’obtenir le meilleur score dans un jeu. Au lieu d’essayer aléatoirement chaque mouvement possible (ce qui pourrait prendre une éternité !), l’optimisation bayésienne examine vos mouvements passés, apprend d’eux, et suggère astucieusement le prochain meilleur mouvement. Elle trouve un équilibre entre l’essai de mouvements éprouvés (exploitation) et l’expérimentation de nouveaux mouvements (exploration).
Pourquoi maximiser mAP50 ?
mAP50 signifie Mean Average Precision avec un IoU de 0,5. En termes simples, il évalue la manière dont les boîtes englobantes prédites par notre modèle chevauchent les boîtes véritables. Maximiser mAP50 signifie que notre modèle ne détecte pas seulement les objets, mais localise précisément leur position. Parce que l’objectif est de détecter les types de véhicules pendant le jour, la nuit, et dans des conditions météorologiques extrêmes, assurer un mAP50 élevé devient encore plus crucial. Il ne s’agit pas seulement de détecter les véhicules, mais de s’assurer qu’ils sont correctement reconnus dans des scénarios variés et difficiles. Pourquoi ai-je choisi de maximiser mAP50 plutôt que mAP50–95 ? Lors de la première formation de notre modèle avec les hyperparamètres par défaut, j’ai observé que mAP50 atteignait sa valeur optimale autour du 30ème epoch, tandis que mAP50–95 prenait plus de temps, se stabilisant seulement autour de 50 epochs. Notamment, un mAP50 élevé était souvent indicatif d’un mAP50–95 également élevé. Étant donné ce comportement, pour des fins d’optimisation des hyperparamètres, j’ai choisi de me concentrer sur la maximisation de mAP50. Cette approche nous permet de raccourcir chaque exécution d’évaluation, facilitant une exploration plus efficace de diverses combinaisons de paramètres.
Utilisation de W&B pour l’optimisation des hyperparamètres
La fonctionnalité de balayage de W&B simplifie le processus d’optimisation. J’ai configuré le balayage en utilisant la méthode bayésienne pour rechercher les meilleurs hyperparamètres. De manière intéressante, j’ai choisi 30 epochs pour l’entraînement car, lors de mes tests initiaux avec l’ensemble de données complet, le modèle a commencé à montrer des signes de performance optimale autour de ce repère.
Résultats et réflexions
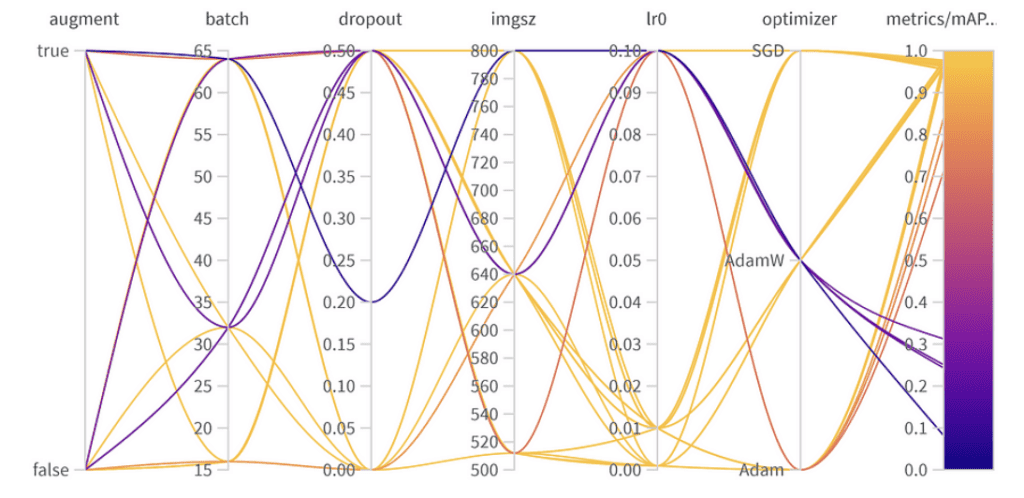
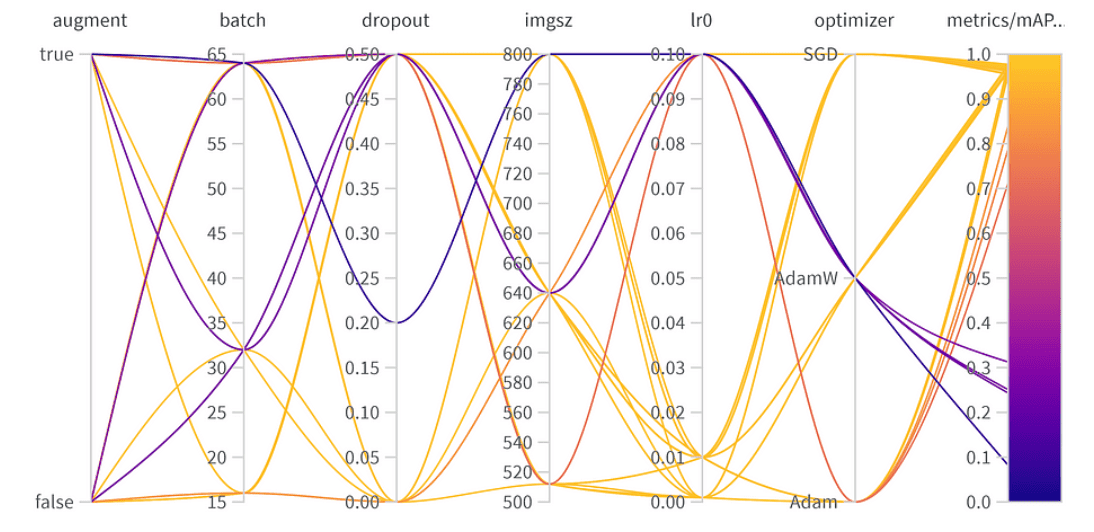
Résultats de l’optimisation des hyperparamètres
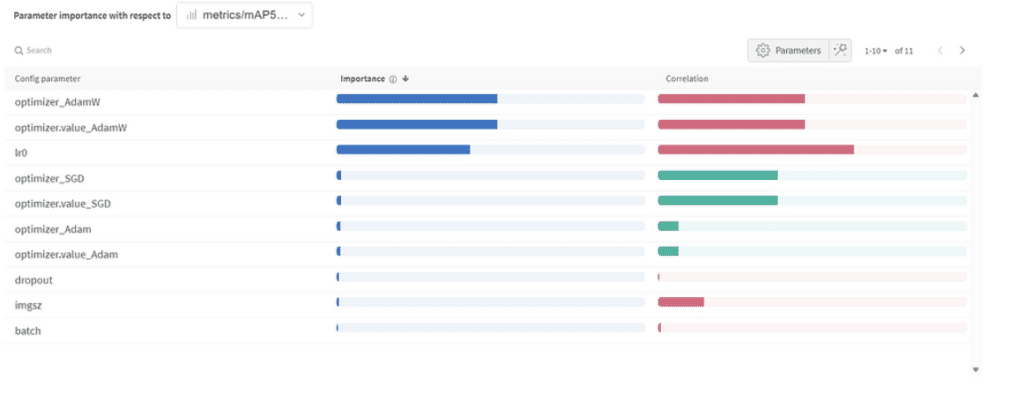
Importance et corrélation des hyperparamètres
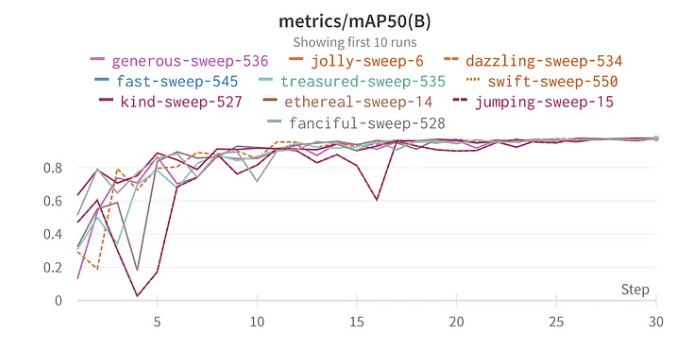
10 meilleurs résultats mAP50 pour YoloV8
Importance des paramètres :
- Optimiseur (AdamW) : Avec une importance de 0.521 et une corrélation négative, cela suggère qu’AdamW peut avoir un impact significatif sur les performances, mais pas toujours de manière positive.
- Taux d’apprentissage (lr0) : Haute importance (0.433) et une corrélation négative (-0.634) laissent supposer qu’un taux d’apprentissage plus faible pourrait être préférable pour notre tâche.
- Autres : Des optimiseurs comme SGD & Adam, et des paramètres tels que le dropout, la taille de l’image, et la taille du lot montrent une importance minimale, indiquant leur moindre influence sur la performance de notre modèle.
Hyperparamètres finaux :
La meilleure combinaison d’hyperparamètres est la suivante avec le meilleur mAP50 de 0.9776 sur l’ensemble de validation :
- Augmentation : Le meilleur modèle a omis l’augmentation des données, indiquant une diversité de données suffisante.
- Taille du lot : Choisi 64, équilibrant l’efficacité computationnelle et la performance du modèle.
- Dropout : Un taux de 0, suggérant que le modèle n’avait pas besoin de cette régularisation.
- Taille de l’image : 640 est le point idéal pour notre tâche.
- Taux d’apprentissage : A opté pour 0.001, en accord avec notre observation précédente selon laquelle des taux plus bas sont bénéfiques.
- Optimiseur : Étonnamment, même si AdamW semblait important, Adam a été choisi dans la meilleure combinaison. C’est un rappel que les hyperparamètres ont souvent des effets interconnectés.
Trouver un équilibre : Performance maximale vs. Généralisation
Bien que le meilleur mAP50 obtenu sur notre ensemble de validation était de 0.9776, il y avait une autre configuration avec un mAP50 proche de 0.9761. Ce modèle « deuxième » se distingue notamment par l’utilisation de l’augmentation des données et un taux de dropout de 0.5. Compte tenu de la légère baisse du mAP50 (une simple différence de 0.0015), il pourrait être bénéfique de privilégier ce modèle dans des scénarios de déploiement, surtout si nous prévoyons une grande variété de situations que le modèle rencontrera. Le léger compromis en performance immédiate pourrait être compensé par la capacité améliorée du modèle à généraliser.
Conclusion
L’optimisation des hyperparamètres peut considérablement améliorer la performance de votre modèle. Avec des outils comme W&B et des méthodes comme l’optimisation bayésienne, ce processus devient systématique et éclairant. Alors que certains paramètres comme l’optimiseur et le taux d’apprentissage sont essentiels, d’autres ont un impact mineur. Cela souligne la nécessité d’un ajustement spécifique à la tâche plutôt que des meilleures pratiques générales en apprentissage profond. Lors du déploiement d’un modèle, il est essentiel de peser les compromis entre la performance maximale en validation et la robustesse dans diverses situations réelles. Dans certains cas, un modèle avec une précision de validation légèrement inférieure mais une meilleure généralisation grâce à la régularisation pourrait être le meilleur choix. Expérimenter, soutenu par des données, est la clé !