
Co to jest Wykrywanie Obiektów
Wykrywanie obiektów w wizji komputerowej odnosi się do zadania identyfikowania i lokalizowania obiektów w obrazie lub klatce wideo. Celem jest nie tylko klasyfikacja obecnych obiektów, ale również dostarczenie precyzyjnej lokalizacji każdego obiektu w obrazie. Zwykle obejmuje to rysowanie ramion ograniczających wokół wykrytych obiektów i etykietowanie ich odpowiadającymi im etykietami klas.
- Wykrywanie obiektów jest fundamentalnym zadaniem w wielu aplikacjach wizji komputerowej, w tym:
- Jazda autonomiczna: Wykrywanie pieszych, pojazdów, znaków drogowych oraz innych obiektów na drodze.
- Nadzór i bezpieczeństwo: Identyfikacja osób, pojazdów i podejrzanych działań w strumieniach wideo.
- Obrazowanie medyczne: Lokalizacja i klasyfikacja anomalii w obrazach medycznych takich jak rentgeny, rezonanse magnetyczne czy tomografie komputerowe.
- Handel detaliczny: Liczenie i śledzenie produktów na półkach sklepowych lub wykrywanie zachowań związanych z kradzieżą sklepową.
- Automatyzacja przemysłowa: Inspekcja wyprodukowanych produktów pod kątem defektów czy anomalii na liniach produkcyjnych.
- Rzeczywistość rozszerzona: Rozpoznawanie obiektów w środowisku w celu nałożenia cyfrowych informacji.
- Robotyka: Umożliwienie robotom postrzeganie i interakcję z obiektami w ich otoczeniu.
Algorytmy wykrywania obiektów zazwyczaj obejmują kilka kroków:
- Ekstrakcja cech: Analiza obrazu wejściowego w celu zidentyfikowania cech istotnych dla wykrywania obiektów. Może to obejmować techniki takie jak konwolucyjne sieci neuronowe (CNN) do ekstrakcji hierarchicznych reprezentacji obrazu.
- Lokalizacja: Ten krok obejmuje przewidywanie lokalizacji obiektów w obrazie. Często jest to realizowane przez regresję współrzędnych ramion ograniczających względem ramki obrazu.
- Klasyfikacja: Każdemu wykrytemu obiektowi przypisywana jest etykieta klasy (np. osoba, samochód, pies) na podstawie jego cech wizualnych. Zazwyczaj jest to realizowane przy użyciu modelu klasyfikacyjnego, często wraz z modelem lokalizacji.
- Post-processing: Na koniec wyniki detekcji mogą zostać poddane krokom post-processingu, takim jak tłumienie maksymalne (NMS), aby doprecyzować ramiona ograniczające i eliminować duplikaty detekcji.
Zazwyczaj kroki od ekstrakcji cech do post-processingu są obsługiwane przez Głęboką Konwolucyjną Sieć Neuronową.
Popularne podejścia do wykrywania obiektów obejmują:
- Detektory dwuetapowe: Te metody najpierw proponują regiony zainteresowania (RoIs) za pomocą technik takich jak selektywne wyszukiwanie lub sieci proponujące regiony (RPNs), a następnie klasyfikują i udoskonalają te propozycje. Przykłady to Faster R-CNN, R-FCN i Mask R-CNN.
- Detektory jednoetapowe: Te metody bezpośrednio przewidują ramiona ograniczające obiektów i prawdopodobieństwa klas w jednym przejściu przez sieć, bez osobnego etapu propozycji. Przykłady to YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) i RetinaNet.
Chociaż detektory dwuetapowe mogą pochwalić się lepszą dokładnością, często są one bardziej kosztowne obliczeniowo i nie mogą być używane w wielu aplikacjach czasu rzeczywistego. Detektory jednoetapowe poświęcają nieco dokładności dla szybkości. Jak to zwykle bywa w przypadku sieci neuronowych, należy określić priorytety między szybkością a dokładnością przy wyborze modelu do użycia.
Wykrywanie obiektów osiągnęło znaczące postępy w ostatnich latach, napędzane przez ulepszenia w technikach uczenia głębokiego, rozmiarach zbiorów danych i zasobach obliczeniowych.
Co to jest YOLO
YOLO (You Only Look Once) to rodzina modeli wykrywania obiektów w czasie rzeczywistym, które są wysoce efektywne i zdolne do wykrywania obiektów w obrazach lub klatkach wideo z zadziwiającą prędkością. Kluczową cechą modeli YOLO jest ich zdolność do wykonywania wykrywania obiektów w jednym przejściu przez sieć neuronową, stąd nazwa „You Only Look Once”.
Było kilka iteracji i wersji modeli YOLO, każda z ulepszeniami w stosunku do poprzednich wersji. Jednak ogólna architektura i zasady pozostają spójne w różnych wersjach. Oto ogólny przegląd działania modeli YOLO:
- Podejście oparte na siatce: YOLO dzieli obraz wejściowy na siatkę komórek. Każda komórka odpowiada za przewidywanie ramion ograniczających i prawdopodobieństw klas dla obiektów, których centra mieszczą się w tej komórce.
- Przewidywanie: Dla każdej komórki siatki, YOLO przewiduje ramiona ograniczające (zazwyczaj 2 lub więcej na komórkę) wraz z wynikami ufności reprezentującymi prawdopodobieństwo, że ramiona ograniczające zawierają obiekt, oraz prawdopodobieństwa klas dla każdej klasy.
- Przewidywanie jednoetapowe: YOLO przetwarza cały obraz przez konwolucyjną sieć neuronową (CNN) w jednym przejściu do przodu, aby dokonać tych przewidywań. W przeciwieństwie do niektórych innych metod wykrywania obiektów, które wymagają wielu przejść lub propozycji regionów.
- Format wyjścia: Wynikiem modelu YOLO jest zestaw ramion ograniczających, wyników ufności i prawdopodobieństw klas. Te ramiona ograniczające są bezpośrednio przewidywane przez sieć i nie polegają na żadnych krokach post-processingu, takich jak tłumienie maksymalne (NMS), aby je doprecyzować.
- Funkcja straty: YOLO używa kombinacji straty lokalizacyjnej (mierzącej dokładność przewidywań ramion ograniczających) i straty klasyfikacyjnej (mierzącej dokładność przewidywań klas) do trenowania modelu. Funkcja straty jest zaprojektowana, aby karać niedokładne przewidywania, jednocześnie zachęcając model do dokonywania pewnych przewidywań dotyczących obiektów.
Wprowadzenie do YOLOv9
YOLOv9, najnowsza iteracja popularnej serii You Only Look Once (YOLO), stanowi przełomowy postęp w systemach detekcji obiektów w czasie rzeczywistym. Budując na sukcesach swoich poprzedników, YOLOv9 wprowadza innowacyjne koncepcje, takie jak Programowalna Informacja Gradientowa (PGI) i Generalized Efficient Layer Aggregation Network (GELAN), aby zwiększyć efektywność i dokładność zadań detekcji obiektów. Poprzez wykorzystanie PGI, YOLOv9 rozwiązuje wyzwanie utraty danych w głębokich sieciach poprzez zapewnienie zachowania kluczowych cech i niezawodnej generacji gradientów dla optymalnych wyników treningowych. Dodatkowo, integracja GELAN oferuje lekką architekturę sieci, która optymalizuje wykorzystanie parametrów i efektywność obliczeniową, czyniąc YOLOv9 wszechstronnym i wysokowydajnym rozwiązaniem dla szerokiego zakresu zastosowań.
Z koncentracją na detekcji obiektów w czasie rzeczywistym, YOLOv9 rozwija najnowocześniejsze metodyki, takie jak CSPNet, ELAN, i ulepszone techniki integracji cech, aby dostarczyć wyższą wydajność w różnych zadaniach wizji komputerowej. Poprzez wprowadzenie mocy PGI do programowania informacji gradientowych i GELAN do efektywnej agregacji warstw, YOLOv9 ustanawia nowy standard dla systemów detekcji obiektów, przewyższając istniejące detektory w czasie rzeczywistym pod względem dokładności, prędkości i wykorzystania parametrów. Ten model YOLO nowej generacji obiecuje rewolucję w dziedzinie wizji komputerowej dzięki swoim zaawansowanym możliwościom i wyjątkowej wydajności na zbiorach danych, takich jak MS COCO, ustanawiając się jako czołowy konkurent w dziedzinie detekcji obiektów w czasie rzeczywistym.
Problemy rozwiązane przez YOLOv9
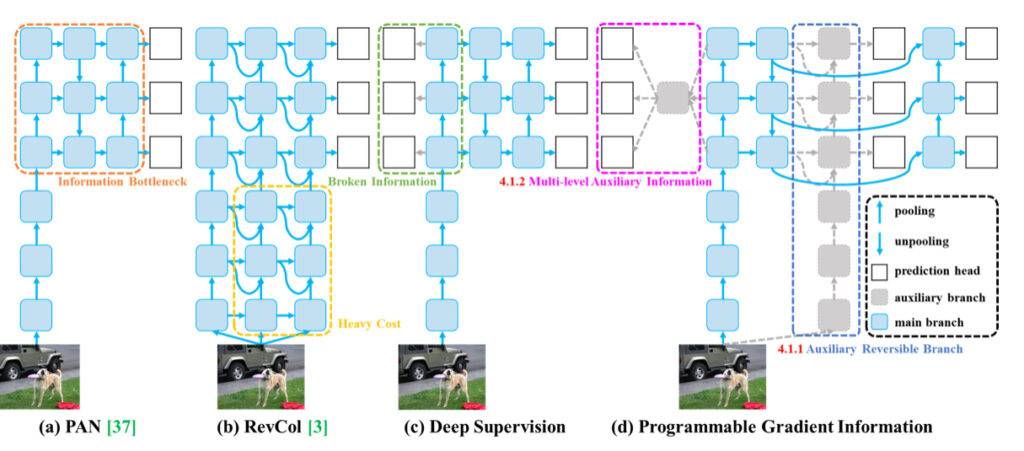
YOLOv9 osiągnął wyższą wydajność dzięki rozwiązaniu kilku problemów występujących podczas szkolenia głębokich sieci neuronowych.Problem butelki informacyjnej w głębokich sieciach neuronowych odnosi się do zjawiska, w którym dane wejściowe przechodzą ekstrakcję cech warstwami i transformację przestrzenną, co prowadzi do utraty istotnych informacji. Dane płynące przez kolejne warstwy głębokiej sieci mogą stopniowo tracić swoje charakterystyczne cechy i istotne szczegóły, prowadząc do powstania butelki informacyjnej. Butelka ta ogranicza zdolność sieci do zachowania pełnej informacji o celu predykcji, co może prowadzić do niepewnych gradientów podczas treningu i słabego zbieżności modelu.

Aby rozwiązać problem butelki informacyjnej, badacze eksplorowali różne metody, takie jak architektury odwracalne, modelowanie maskowane i głęboka nadzorowana nauka. Architektury odwracalne mają na celu utrzymanie informacji o danych wejściowych poprzez wielokrotne wykorzystanie danych wejściowych. Modelowanie maskowane koncentruje się na maksymalizacji ekstrahowanych cech w sposób niejawny, aby zachować informacje wejściowe. Głęboka nadzorowana nauka polega na wcześniejszym ustaleniu mapowania z płytkich cech na cele, aby zapewnić przekazanie ważnych informacji do głębszych warstw. Jednak te metody mają ograniczenia i wady, takie jak wzrost kosztów wnioskowania, konflikty między stratą rekonstrukcji a stratą celu, akumulacja błędów i trudność w modelowaniu informacji semantycznych wysokiego rzędu.
Poprzez wprowadzenie Programowalnej Informacji Gradientowej (PGI) w swoich badaniach, autorzy YOLOv9 zapewniają nowatorskie rozwiązanie problemu butelki informacyjnej. PGI generuje niezawodne gradienty poprzez pomocniczą odwracalną gałąź, umożliwiając głębokim cechom zachowanie kluczowych cech niezbędnych do wykonywania zadań docelowych. Ten sposób zapewnia zachowanie ważnych informacji i uzyskanie dokładnych gradientów do skutecznego aktualizowania wag sieci, poprawiając zbieżność i wyniki treningowe głębokich sieci neuronowych.
Problemy związane z wykorzystaniem parametrów
Drugim problemem rozwiązanym przez autorów YOLOv9 są nieefektywności związane z wykorzystaniem parametrów. Generalized Efficient Layer Aggregation Network (GELAN) wprowadzony przez autorów zwiększa wykorzystanie parametrów i efektywność obliczeniową w głębokich sieciach neuronowych poprzez stworzenie nowatorskiej lekkiej architektury, która optymalizuje wykorzystanie parametrów i zasobów obliczeniowych. Oto kilka kluczowych sposobów, w jakie GELAN osiąga to:
- Elastyczność bloków obliczeniowych: GELAN pozwala na użycie różnych bloków obliczeniowych, takich jak bloki Res, bloki Dark i bloki CSP. Przeprowadzając badania ablacyjne na tych blokach obliczeniowych, GELAN demonstruje zdolność do utrzymania dobrej wydajności przy jednoczesnej możliwości wyboru i wymianie bloków obliczeniowych na podstawie konkretnych wymagań użytkowników. Ta elastyczność nie tylko redukuje liczbę parametrów, ale także poprawia ogólną efektywność obliczeniową sieci.
- Wydajność parametrów: GELAN został zaprojektowany w taki sposób, aby osiągnąć lepsze wykorzystanie parametrów w porównaniu do metod opartych na konwolucji względem głębokości. Wykorzystując efektywnie konwolucje klasyczne, GELAN maksymalizuje wykorzystanie parametrów, zachowując jednocześnie wysoką wydajność w zadaniach detekcji obiektów. To efektywne wykorzystanie parametrów przyczynia się do ogólnej skuteczności i skalowalności sieci.
- Wrażliwość na głębokość: Wydajność GELAN nie jest nadmiernie wrażliwa na głębokość sieci. Eksperymenty pokazują, że zwiększenie głębokości GELAN nie prowadzi do malejących zysków pod względem wykorzystania parametrów i efektywności obliczeniowej. Ta cecha pozwala GELAN zachować stały poziom wydajności przy różnych głębokościach, zapewniając, że sieć pozostaje wydajna i skuteczna bez względu na jej złożoność.
- Adaptowalność urządzeń wydajnościowych: Architektura GELAN została zaprojektowana tak, aby była adaptowalna do różnych urządzeń wydajnościowych, pozwalając użytkownikom wybierać bloki obliczeniowe odpowiednie dla ich określonych wymagań sprzętowych. Ta adaptowalność zapewnia, że GELAN może być efektywnie wdrażany na szeroką gamę urządzeń, niezależnie od wydajności ani efektywności obliczeniowej.
Poprzez połączenie tych czynników GELAN zwiększa wykorzystanie parametrów i efektywność obliczeniową w głębokich sieciach neuronowych, czyniąc go wszechstronnym i wysokowydajnym rozwiązaniem dla różnych zastosowań, w tym zadań detekcji obiektów w czasie rzeczywistym.
Porównanie wydajności
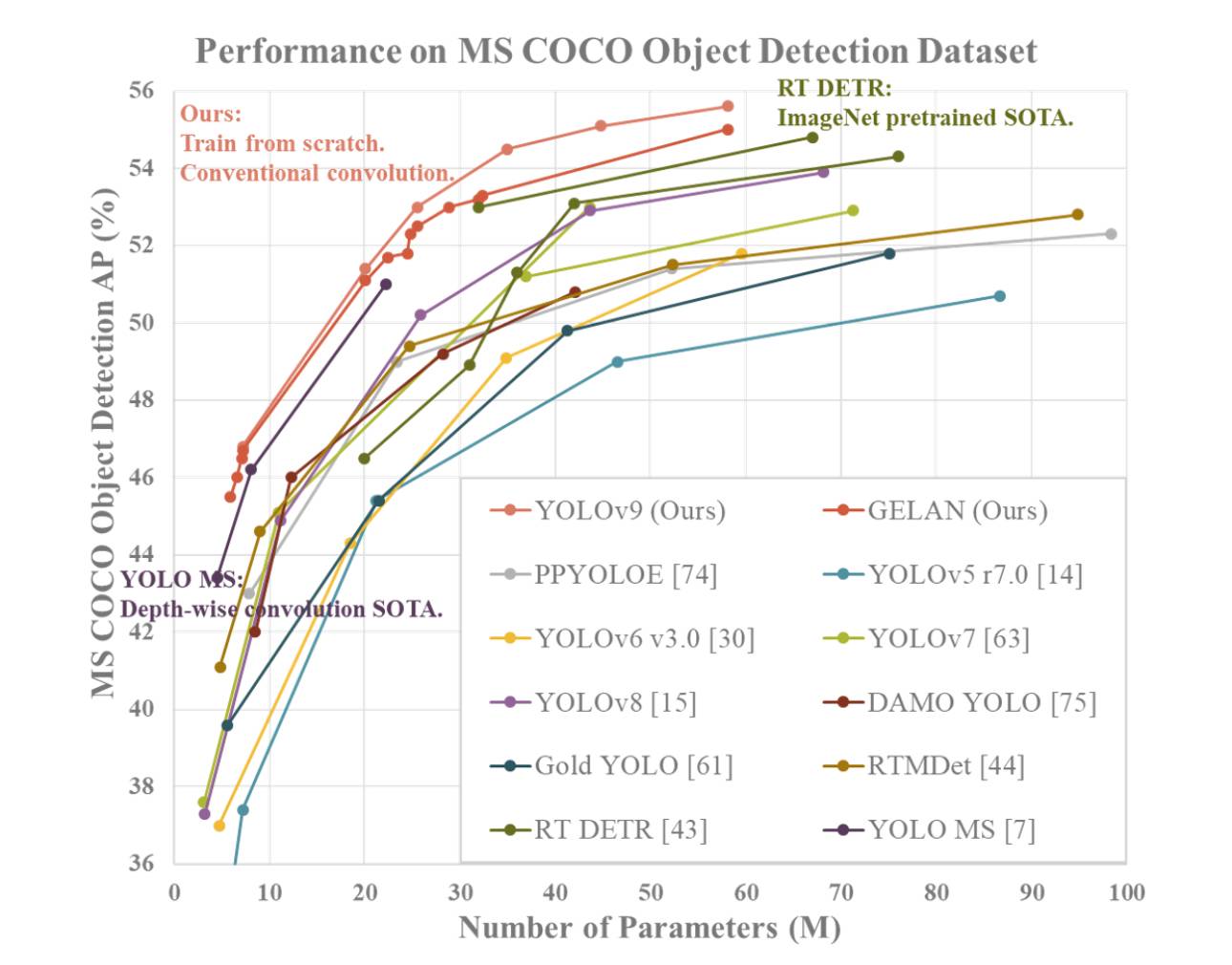
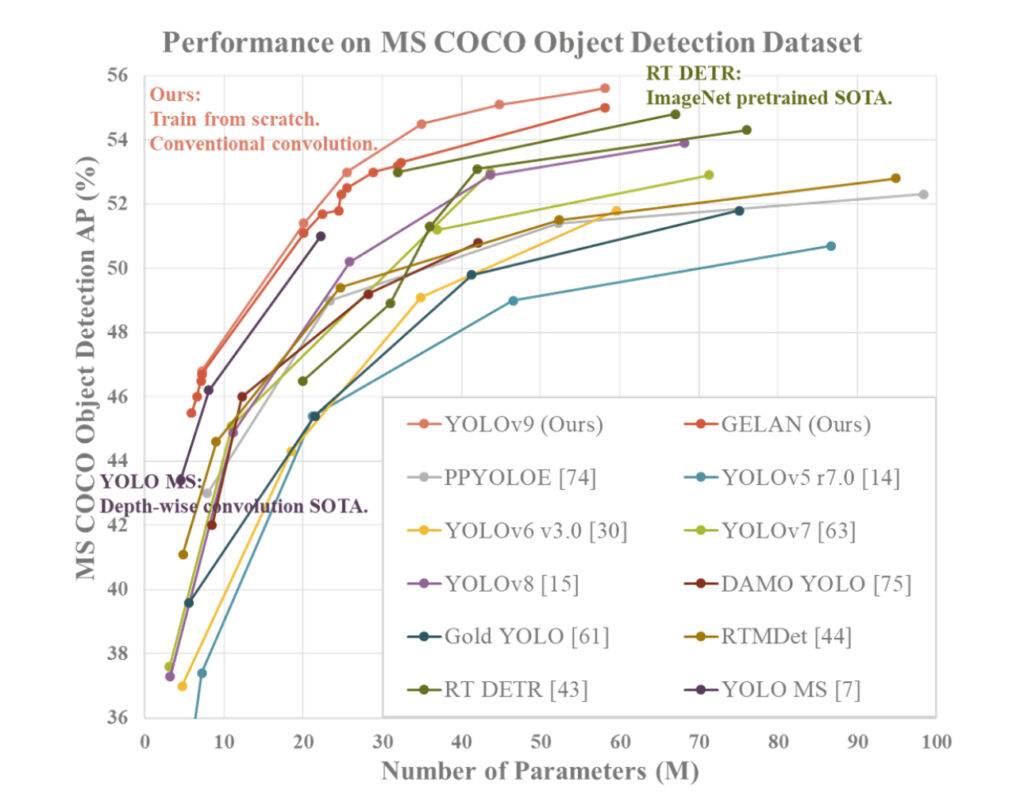
YOLOv9 wykazuje wyższą wydajność w porównaniu do wcześniejszych najlepszych detektorów obiektów w czasie rzeczywistym pod względem różnych metryk. Oto podsumowanie porównania na podstawie dostarczonych informacji:
- Redukcja parametrów: YOLOv9 osiąga znaczną redukcję liczby parametrów w porównaniu z poprzednimi detektorami, takimi jak YOLOv8. Ta redukcja parametrów przyczynia się do poprawy efektywności obliczeniowej i szybszych prędkości wnioskowania.
- Efektywność obliczeniowa: YOLOv9 redukuje także ilość obliczeń wymaganych do zadań detekcji obiektów, co prowadzi do zwiększenia efektywności w przetwarzaniu i analizie danych wizualnych.
- Poprawa dokładności: Pomimo redukcji parametrów i obliczeń, YOLOv9 udaje się poprawić metrykę Średniej Precyzji (AP) znacząco na zbiorze danych MS COCO. Ta poprawa dokładności pokazuje skuteczność proponowanych mechanizmów PGI i GELAN w poprawie wydajności detekcji modelu.
- Konkurencyjność: YOLOv9 wykazuje silną konkurencyjność w porównaniu z innymi detektorami obiektów w czasie rzeczywistym szkolonymi za pomocą różnych metod, w tym trenowanych od podstaw, wstępnie nauczonych przez ImageNet, uczenia na odległość i złożonych procesów szkoleniowych. Model przewyższa te metody pod względem dokładności, efektywności parametrów i prędkości obliczeniowej.
- Wszechstronność: Połączenie PGI i GELAN w YOLOv9 umożliwia skuteczną integrację lekkich architektur z głębokimi modelami, umożliwiając szeroki zakres zastosowań w detekcji obiektów w czasie rzeczywistym na różnych urządzeniach do wnioskowania.
Podsumowując, YOLOv9 wyróżnia się jako system detekcji obiektów, który wyróżnia się pod względem dokładności, efektywności i wykorzystania parametrów, co czyni go przekonującym wyborem do zadań wizji komputerowej w czasie rzeczywistym.
| Model | APval (%) | AP50_val (%) | AP75_val (%) | Parametry (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Wnioski
YOLOv9 prezentuje znaczące postępy w detekcji obiektów w czasie rzeczywistym poprzez wdrożenie i wykorzystanie innowacyjnych technik, takich jak Generalized Efficient Layer Aggregation Network (GELAN) i Programmable Gradient Information (PGI). Poprzez rozwiązanie kluczowych problemów, takich jak problem butelki informacyjnej oraz optymalizacja wykorzystania parametrów i efektywności obliczeniowej, YOLOv9 wyłania się jako czołowy gracz w dziedzinie detekcji obiektów.
Analiza porównawcza pokazuje, że YOLOv9 przewyższa istniejące metody pod względem dokładności, efektywności parametrów i prędkości obliczeniowej. Jego zdolność do redukcji parametrów przy jednoczesnym poprawieniu Średniej Precyzji (AP) na zbiorach danych takich jak MS COCO podkreśla skuteczność proponowanych udoskonaleń. Ponadto, możliwość dostosowania YOLOv9 do różnych urządzeń wydajnościowych podkreśla jego wszechstronność i zastosowanie w różnych scenariuszach detekcji obiektów w czasie rzeczywistym.
Ogólnie rzecz biorąc, badania nie tylko posuwają do przodu stan wiedzy w dziedzinie detekcji obiektów w czasie rzeczywistym, ale także ustalają nowy standard wydajności, efektywności i wykorzystania parametrów w głębokich sieciach neuronowych. Sukces YOLOv9 w pokonywaniu kluczowych wyzwań i dostarczaniu wyższych wyników podkreśla jego potencjał do dalszych innowacji w dziedzinie wizji komputerowej i zastosowań uczenia maszynowego.
FAQ o YOLOv9
W szybko rozwijającej się dziedzinie wizji komputerowej, YOLOv9 wyróżnia się jako znaczący skok naprzód, łącząc efektywność z przełomową dokładnością. Wraz ze wzrostem zainteresowania tym zaawansowanym modelem wykrywania obiektów, pojawiają się również pytania o jego zastosowanie, wydajność i dostępność. Poniżej odpowiadamy na najczęstsze zapytania, aby pomóc zarówno nowicjuszom, jak i doświadczonym profesjonalistom uzyskać jaśniejszy obraz tego, co YOLOv9 oferuje i jak może przekształcić ich projekty oparte na wizji.
Co to jest YOLOv9 i czym różni się od poprzednich wersji?
YOLOv9 to najnowsza iteracja w serii YOLO (You Only Look Once), znanej z możliwości wykrywania obiektów. Wprowadza on nową lekką architekturę sieci, zwiększającą szybkość i dokładność detekcji. W porównaniu do swojego poprzednika, YOLOv9 oferuje ulepszoną średnią precyzję (AP) na zbiorze danych MS COCO, dzięki postępom w programowalnych informacjach gradientowych i integracji technologii transformatorów, co czyni go bardziej efektywnym w zastosowaniach rzeczywistych.
Jak zacząć z YOLOv9 do wykrywania obiektów?
Aby rozpocząć pracę z YOLOv9, najpierw zainstaluj wymagane zależności, w tym Python, PyTorch i CUDA do przyspieszenia GPU. Pobierz kod źródłowy YOLOv9 z oficjalnego repozytorium. Wytrenuj model z własnym zestawem danych lub użyj dostępnych online wstępnie wytrenowanych wag, aby wykrywać obiekty. Uruchomienie skryptu detekcji na obrazie lub wideo da w wyniku wykrywanie obiektów w czasie rzeczywistym, prezentując możliwości YOLOv9.
Jakie są kluczowe ulepszenia w wydajności YOLOv9?
YOLOv9 wprowadza kluczowe ulepszenia w wydajności wykrywania obiektów, zwłaszcza wzrost średniej precyzji (AP) oraz redukcję czasu wnioskowania. Na zbiorze danych MS COCO, YOLOv9 demonstruje znaczący wzrost AP, osiągając do 55,6% dla niektórych modeli, wraz z szybszymi prędkościami detekcji, co czyni go bardzo odpowiednim dla aplikacji w czasie rzeczywistym. Te wzmocnienia są przypisywane jego nowej architekturze i technikom optymalizacji.
Czy YOLOv9 może być zintegrowany z urządzeniami edge computing?
Tak, YOLOv9 może być zintegrowany z urządzeniami edge computing, takimi jak NVIDIA Jetson, dzięki jego zoptymalizowanej architekturze, która wspiera efektywną operację na sprzęcie z ograniczonymi zasobami obliczeniowymi. Ta kompatybilność umożliwia YOLOv9 przeprowadzanie wykrywania obiektów w czasie rzeczywistym w scenariuszach edge, takich jak kamery dozoru i autonomiczne pojazdy, gdzie szybkie przetwarzanie jest kluczowe.
Jakie są wyzwania i rozwiązania w treningu YOLOv9?
Trening YOLOv9 stawia wyzwania takie jak różnorodność danych i wymagania sprzętowe. Różnorodny zestaw danych jest kluczowy dla osiągnięcia wysokiej dokładności, podczas gdy potężny sprzęt przyspiesza proces treningu. Rozwiązania obejmują augmentację zestawów danych dla różnorodności oraz wykorzystanie zasobów obliczeniowych w chmurze lub specjalistycznego sprzętu, takiego jak GPU, dla szybszego treningu modelu. Dostrojenie wstępnie wytrenowanych modeli może również znacząco zmniejszyć czas i zużycie zasobów treningu.
Gdzie mogę znaleźć zasoby i wsparcie społeczności dla YOLOv9?
Zasoby i wsparcie społeczności dla YOLOv9 są obfite. Deweloperzy mogą znaleźć dokumentację, wstępnie wytrenowane modele i przykłady kodu w oficjalnym repozytorium GitHub YOLOv9. Dla wsparcia społeczności, fora takie jak Reddit i Stack Overflow hostują aktywne dyskusje, wskazówki i porady dotyczące rozwiązywania problemów. Te platformy zapewniają bogactwo informacji zarówno dla początkujących, jak i ekspertów, którzy chcą ulepszyć swoje projekty YOLOv9.