
Cosa è il rilevamento oggetti
Il rilevamento oggetti nella visione artificiale si riferisce al compito di identificare e localizzare gli oggetti all’interno di un’immagine o di un frame video. L’obiettivo è non solo classificare quali oggetti sono presenti, ma anche fornire la posizione precisa di ciascun oggetto all’interno dell’immagine. Ciò comporta tipicamente il disegno di bounding box intorno agli oggetti rilevati ed etichettarli con le rispettive classi.
Il rilevamento oggetti è un compito fondamentale in molte applicazioni di visione artificiale, tra cui:
- Guida autonoma: rilevamento di pedoni, veicoli, segnali stradali e altri oggetti sulla strada.
- Sorveglianza e sicurezza: identificazione di persone, veicoli e attività sospette nei flussi video.
- Imaging medico: individuazione e classificazione di anomalie nelle immagini mediche come raggi X, MRI o tomografie computerizzate.
- Commercio al dettaglio: conteggio e tracciamento dei prodotti sugli scaffali dei negozi o rilevamento di comportamenti di furto.
- Automazione industriale: ispezione dei prodotti manufatti per difetti o anomalie sulle linee di produzione.
- Realtà aumentata: riconoscimento di oggetti nell’ambiente per sovrapporre informazioni digitali.
- Robotica: consentire ai robot di percepire e interagire con gli oggetti nel loro ambiente.
Gli algoritmi di rilevamento oggetti coinvolgono tipicamente diversi passaggi:
- Estrazione delle caratteristiche: l’immagine in input viene analizzata per identificare le caratteristiche rilevanti per il rilevamento degli oggetti. Ciò potrebbe coinvolgere tecniche come le reti neurali convoluzionali (CNN) per estrarre rappresentazioni gerarchiche dell’immagine.
- Localizzazione: questo passaggio prevede la previsione della posizione degli oggetti all’interno dell’immagine. Questo viene spesso fatto tramite regressione delle coordinate del bounding box rispetto al frame dell’immagine.
- Classificazione: a ciascun oggetto rilevato viene assegnata un’etichetta di classe (ad es. persona, auto, cane) basata sulle sue caratteristiche visive. Questo viene tipicamente fatto utilizzando un modello di classificazione, spesso insieme al modello di localizzazione.
- Post-elaborazione: infine, i risultati del rilevamento possono subire passaggi di post-elaborazione come la soppressione del non massimo (NMS) per raffinare i bounding box ed eliminare i rilevamenti duplicati.
Tipicamente i passaggi dall’estrazione delle caratteristiche alla post-elaborazione sono tutti gestiti da una Rete Neurale Convoluzionale Profonda.
Gli approcci popolari per il rilevamento oggetti includono:
- Rilevatori a due fasi: questi metodi propongono prima regioni di interesse (RoI) utilizzando tecniche come la ricerca selettiva o le reti di proposte regionali (RPN), e quindi classificano e raffinano queste proposte. Gli esempi includono Faster R-CNN, R-FCN e Mask R-CNN.
- Rilevatori a una fase: questi metodi prevedono direttamente bounding box degli oggetti e probabilità di classe in un’unica passata attraverso la rete, senza una fase separata di proposta. Gli esempi includono YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) e RetinaNet.
Sebbene i rilevatori a due fasi vantino una precisione superiore, sono spesso computazionalmente più costosi da eseguire e non possono essere utilizzati per molte applicazioni in tempo reale. I rilevatori a una fase sacrificano un po’ di precisione per la velocità. Come avviene tipicamente con le reti neurali, è necessario definire priorità tra velocità e precisione nella selezione di un modello da utilizzare.
Il rilevamento oggetti ha visto significativi progressi negli ultimi anni, guidati dai miglioramenti nelle tecniche di apprendimento profondo, nelle dimensioni dei dataset e nelle risorse computazionali.
Cos’è YOLO
YOLO (You Only Look Once) è una famiglia di modelli di rilevamento oggetti in tempo reale altamente efficienti e in grado di rilevare oggetti in immagini o frame video con una velocità notevole. La caratteristica chiave dei modelli YOLO è la loro capacità di eseguire il rilevamento degli oggetti in una singola passata attraverso la rete neurale, da qui il nome “You Only Look Once”.
Ci sono state diverse iterazioni e versioni dei modelli YOLO, ciascuna con miglioramenti rispetto alle versioni precedenti. Tuttavia, l’architettura generale e i principi rimangono consistenti tra le diverse versioni. Ecco una panoramica generale di come funzionano i modelli YOLO:
- Approccio basato su griglia: YOLO divide l’immagine in input in una griglia di celle. Ogni cella è responsabile della previsione dei bounding box e delle probabilità di classe per gli oggetti il cui centro cade in quella cella.
- Previsione: per ogni cella della griglia, YOLO prevede bounding box (tipicamente 2 o più per cella) insieme a punteggi di confidenza che rappresentano la probabilità che il bounding box contenga un oggetto e probabilità di classe per ciascuna classe.
- Previsione in un’unica passata: YOLO elabora l’intera immagine attraverso una rete neurale convoluzionale (CNN) in un’unica passata per fare queste previsioni. Questo è in contrasto con alcuni altri metodi di rilevamento oggetti che richiedono passaggi multipli o proposte di regione.
- Formato di output: l’output di un modello YOLO è un insieme di bounding box, punteggi di confidenza e probabilità di classe. Questi bounding box sono previsti direttamente dalla rete e non si basano su alcun passaggio di post-elaborazione come la soppressione del non massimo (NMS) per raffinarli.
- Funzione di perdita: YOLO utilizza una combinazione di perdite di localizzazione (misurando l’accuratezza delle previsioni del bounding box) e perdite di classificazione (misurando l’accuratezza delle previsioni di classe) per addestrare il modello. La funzione di perdita è progettata per penalizzare le previsioni inaccurate mentre incoraggia simultaneamente il modello a fare previsioni fiduciose per gli oggetti.
Introduzione a YOLOv9
YOLOv9, l’ultima iterazione della popolare serie You Only Look Once (YOLO), rappresenta un avanzamento all’avanguardia nei sistemi di rilevamento oggetti in tempo reale. Basandosi sul successo dei suoi predecessori, YOLOv9 introduce concetti innovativi come Programmable Gradient Information (PGI) e Generalized Efficient Layer Aggregation Network (GELAN) per migliorare l’efficienza e l’accuratezza dei compiti di rilevamento oggetti. Integrando PGI, YOLOv9 affronta la sfida della perdita di dati nelle reti profonde garantendo la conservazione delle caratteristiche chiave e la generazione affidabile di gradienti per risultati di addestramento ottimali. Inoltre, l’integrazione di GELAN offre un’architettura di rete leggera che ottimizza l’utilizzo dei parametri e l’efficienza computazionale, rendendo YOLOv9 una soluzione versatile e ad alte prestazioni per una vasta gamma di applicazioni.

Con un focus sul rilevamento oggetti in tempo reale, YOLOv9 si basa su metodologie all’avanguardia come CSPNet, ELAN e tecniche di integrazione delle caratteristiche migliorate per offrire prestazioni superiori in vari compiti di visione artificiale. Introducendo il potere di PGI per la programmazione delle informazioni di gradiente e GELAN per l’aggregazione efficiente dei layer, YOLOv9 stabilisce un nuovo standard per i sistemi di rilevamento oggetti, superando i rilevatori in tempo reale esistenti in termini di accuratezza, velocità e utilizzo dei parametri. Questo modello YOLO di prossima generazione promette di rivoluzionare il campo della visione artificiale con le sue capacità avanzate e le prestazioni eccezionali su dataset come MS COCO, affermandosi come un concorrente di primo piano nel campo del rilevamento oggetti in tempo reale.
Quali problemi risolve YOLOv9
YOLOv9 ha ottenuto prestazioni superiori grazie alla risoluzione di diversi problemi che si presentano durante l’addestramento delle reti neurali profonde.
Il problema del collo di bottiglia delle informazioni nelle reti neurali profonde si riferisce al fenomeno in cui i dati in input subiscono un’estrazione delle caratteristiche strato per strato e una trasformazione spaziale, portando alla perdita di informazioni importanti. Man mano che i dati fluiscono attraverso strati successivi di una rete profonda, i dati originali possono gradualmente perdere le loro caratteristiche distinte e i dettagli essenziali, risultando in un collo di bottiglia delle informazioni. Questo collo di bottiglia limita la capacità della rete di mantenere informazioni complete sul target di previsione, il che può portare a gradienti non affidabili durante l’addestramento e a una scarsa convergenza del modello.
Per affrontare il problema del collo di bottiglia delle informazioni, i ricercatori hanno esplorato vari metodi come architetture reversibili, modellazione mascherata e supervisione profonda. Le architetture reversibili mirano a mantenere esplicitamente le informazioni dei dati di input attraverso un uso ripetuto dei dati di input. La modellazione mascherata si concentra sulla massimizzazione delle caratteristiche estratte implicitamente per conservare le informazioni di input. La supervisione profonda comporta l’istituzione prealabile di un mapping dalle caratteristiche superficiali agli obiettivi per garantire il trasferimento di informazioni importanti ai livelli più profondi. Tuttavia, questi metodi hanno limitazioni e svantaggi, come costi di inferenza aumentati, conflitti tra perdita di ricostruzione e perdita di target, accumulo di errori e difficoltà nella modellazione di informazioni semantiche di ordine superiore.
Introducendo Programmable Gradient Information (PGI) nella loro ricerca, gli autori di YOLOv9 forniscono una soluzione innovativa al problema del collo di bottiglia delle informazioni. PGI genera gradienti affidabili attraverso un ramo ausiliario reversibile, consentendo alle caratteristiche profonde di mantenere le caratteristiche chiave necessarie per eseguire compiti target. Questo approccio garantisce che le informazioni importanti siano conservate e che siano ottenuti gradienti accurati per l’aggiornamento efficace dei pesi della rete, migliorando così la convergenza e i risultati di addestramento delle reti neurali profonde.
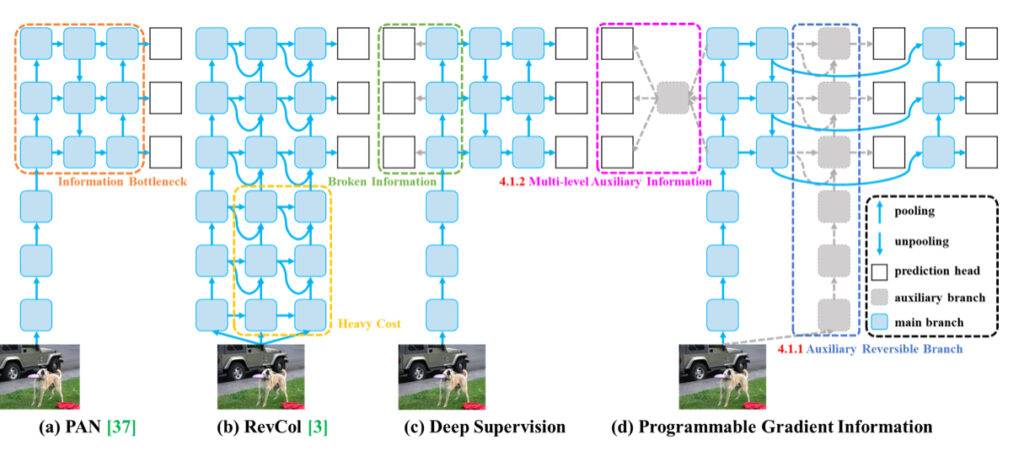
Il secondo problema risolto dagli autori di YOLOv9 è l’inefficienza relativa all’utilizzo dei parametri. Il Generalized Efficient Layer Aggregation Network (GELAN) introdotto dagli autori migliora l’utilizzo dei parametri e l’efficienza computazionale nelle reti neurali profonde creando un’architettura di rete leggera che ottimizza l’utilizzo dei parametri e delle risorse computazionali. Ecco alcuni modi chiave in cui GELAN raggiunge questo obiettivo:
- Flessibilità del blocco computazionale: GELAN consente l’uso di diversi blocchi computazionali come blocchi Res, blocchi Dark e blocchi CSP. Conducenti studi sperimentali su questi blocchi computazionali, GELAN dimostra la capacità di mantenere buone prestazioni offrendo agli utenti la flessibilità di scegliere e sostituire blocchi computazionali in base alle loro specifiche esigenze. Questa flessibilità non solo riduce il numero di parametri, ma migliora anche l’efficienza computazionale complessiva della rete.
- Efficienza dei parametri: GELAN è progettato per ottenere un migliore utilizzo dei parametri rispetto a metodi all’avanguardia basati sulla convoluzione in profondità. Utilizzando efficacemente operatori di convoluzione convenzionali, GELAN massimizza l’utilizzo dei parametri mantenendo al contempo alte prestazioni nei compiti di rilevamento oggetti. Questo utilizzo efficiente dei parametri contribuisce all’efficacia complessiva e alla scalabilità della rete.
- Sensibilità alla profondità: le prestazioni di GELAN non sono eccessivamente sensibili alla profondità della rete. Gli esperimenti mostrano che l’aumento della profondità di GELAN non porta a rendimenti decrescenti in termini di utilizzo dei parametri e di efficienza computazionale. Questa caratteristica consente a GELAN di mantenere un livello di prestazioni costante attraverso diverse profondità, garantendo che la rete rimanga efficiente ed efficace indipendentemente dalla sua complessità.
- Adattabilità del dispositivo di inferenza: l’architettura di GELAN è progettata per essere adattabile a vari dispositivi di inferenza, consentendo agli utenti di scegliere blocchi computazionali adatti alle loro specifiche esigenze hardware. Questa adattabilità garantisce che GELAN possa essere implementato efficientemente su una vasta gamma di dispositivi senza compromettere le prestazioni o l’efficienza computazionale.
Combinate questi fattori, GELAN migliora l’utilizzo dei parametri e l’efficienza computazionale nelle reti neurali profonde, rendendolo una soluzione versatile e ad alte prestazioni per una varietà di applicazioni, compiti di rilevamento oggetti in tempo reale inclusi.
Confronto delle prestazioni
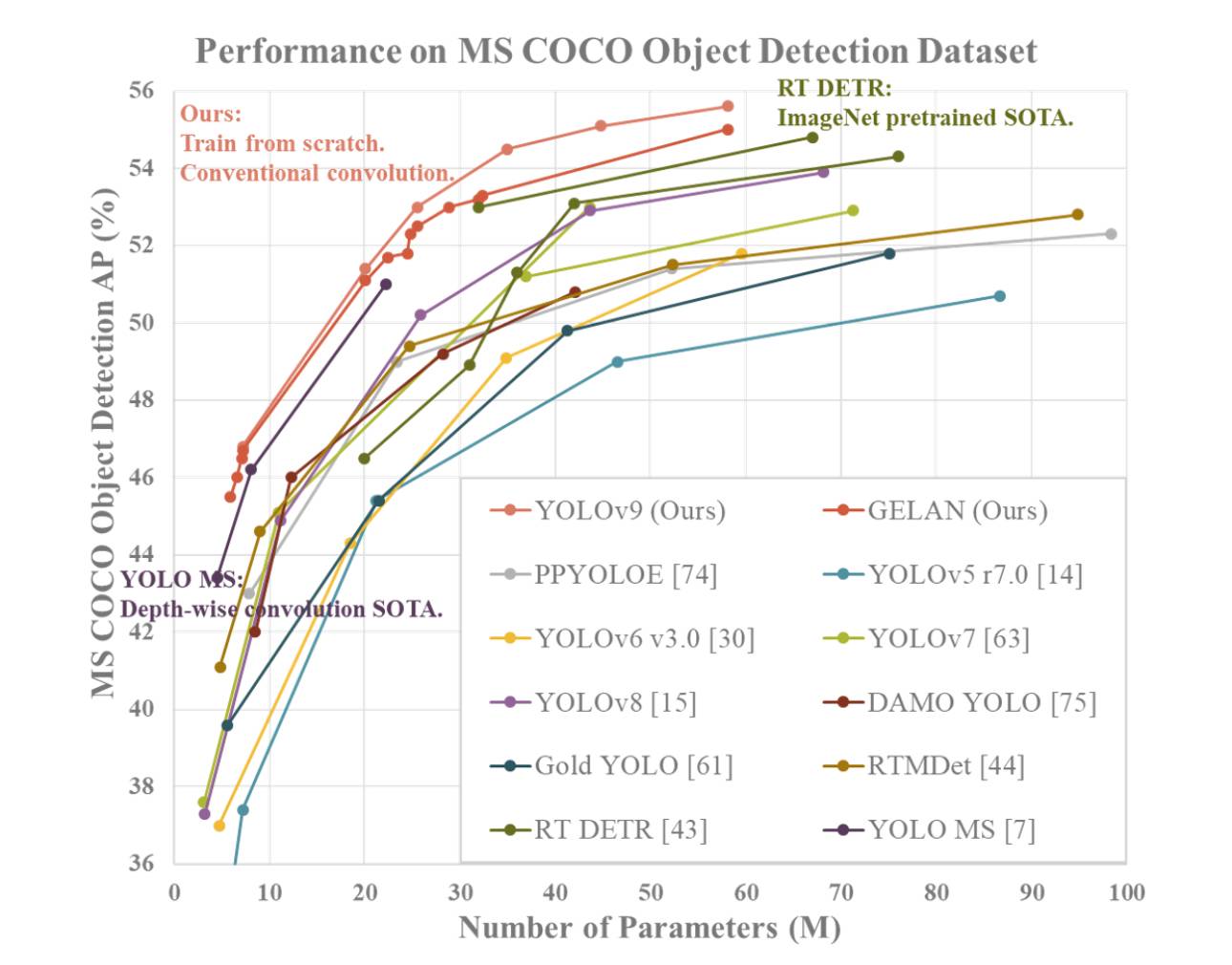
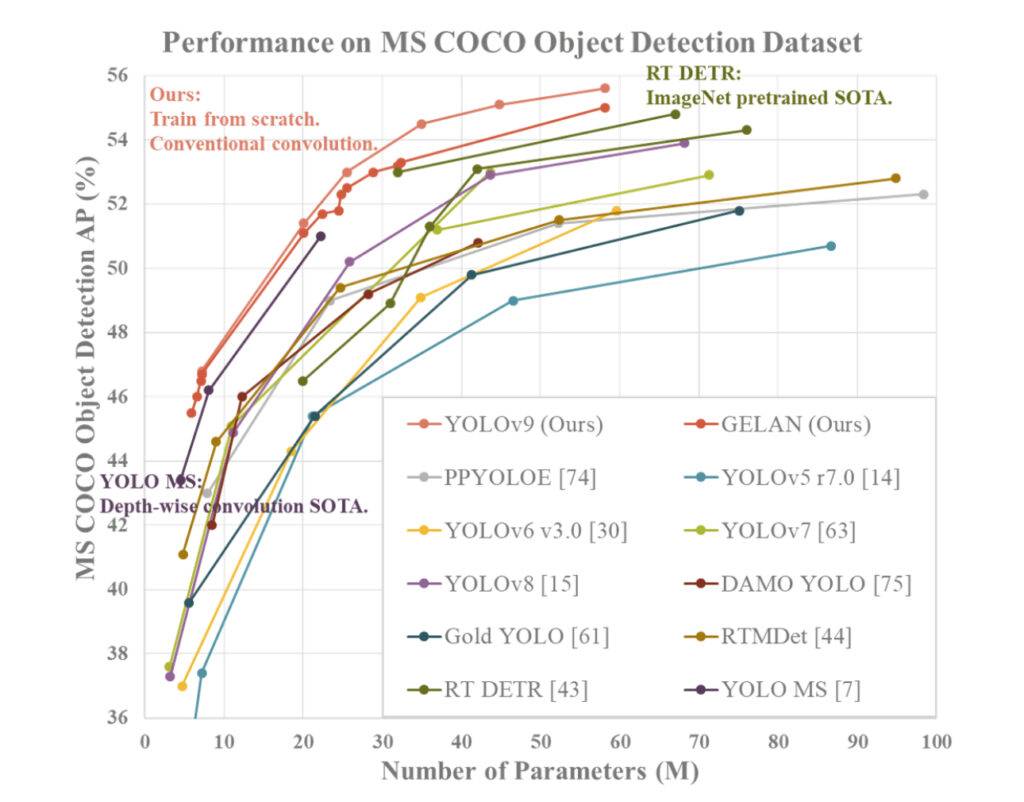
YOLOv9 dimostra prestazioni superiori rispetto ai precedenti rilevatori di oggetti in tempo reale all’avanguardia su varie metriche. Ecco un riassunto del confronto basato sulle informazioni fornite:
- Riduzione dei parametri: YOLOv9 ottiene una significativa riduzione del numero di parametri rispetto ai rilevatori precedenti, come YOLOv8. Questa riduzione dei parametri contribuisce a migliorare l’efficienza computazionale e le velocità di inferenza più rapide.
- Efficienza computazionale: YOLOv9 riduce anche la quantità di calcoli richiesti per i compiti di rilevamento oggetti, portando a un’efficienza migliorata nel trattare e analizzare i dati visivi.
- Miglioramento dell’accuratezza: nonostante la riduzione dei parametri e dei calcoli, YOLOv9 riesce a migliorare in modo significativo la metrica di Precisione Media (AP) su dataset come MS COCO. Questo miglioramento dell’accuratezza dimostra l’efficacia dei meccanismi proposti PGI e GELAN nel migliorare le prestazioni di rilevamento del modello.
- Competitività: YOLOv9 dimostra una forte competitività rispetto ad altri rilevatori di oggetti in tempo reale addestrati utilizzando diversi metodi, tra cui addestramento da zero, preaddestramento su ImageNet, distillazione della conoscenza e processi di addestramento complessi. Il modello supera questi metodi in termini di accuratezza, efficienza dei parametri e velocità computazionale.
- Versatilità: la combinazione di PGI e GELAN in YOLOv9 consente l’integrazione di successo di architetture leggere con modelli profondi, consentendo una vasta gamma di applicazioni nei compiti di rilevamento oggetti in tempo reale su vari dispositivi di inferenza.
Nel complesso, YOLOv9 si distingue come un sistema di rilevamento oggetti di alto livello che eccelle in accuratezza, efficienza e utilizzo dei parametri, rendendolo una scelta convincente per i compiti di visione artificiale in tempo reale.
| Modello | APval (%) | AP50_val (%) | AP75_val (%) | Parametri (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Conclusioni
YOLOv9 mostra i significativi progressi compiuti nel rilevamento oggetti in tempo reale attraverso l’implementazione e il leverage di tecniche innovative come Generalized Efficient Layer Aggregation Network (GELAN) e Programmable Gradient Information (PGI). Affrontando problemi critici come il problema del collo di bottiglia delle informazioni e ottimizzando l’utilizzo dei parametri e l’efficienza computazionale, YOLOv9 emerge come un concorrente di primo piano nel campo del rilevamento oggetti.
L’analisi comparativa dimostra che YOLOv9 supera i metodi esistenti in termini di accuratezza, efficienza dei parametri e velocità computazionale. La sua capacità di ridurre i parametri migliorando la Precisione Media (AP) su dataset come MS COCO evidenzia l’efficacia delle migliorie proposte. Inoltre, l’adattabilità di YOLOv9 a diversi dispositivi di inferenza sottolinea la sua versatilità e applicabilità in scenari di rilevamento oggetti in tempo reale.
Nel complesso, la ricerca non solo fa avanzare lo stato dell’arte nel rilevamento oggetti in tempo reale, ma stabilisce anche un nuovo standard di efficienza, prestazioni e utilizzo dei parametri nelle reti neurali profonde. Il successo di YOLOv9 nel superare sfide chiave e nel fornire risultati superiori sottolinea il suo potenziale nel guidare ulteriori innovazioni nelle applicazioni di visione artificiale e di apprendimento automatico.
FAQ su YOLOv9
Cos’è YOLOv9 e in cosa si differenzia dalle versioni precedenti?
YOLOv9 è l’ultima iterazione della serie YOLO (You Only Look Once), nota per le sue capacità di rilevamento oggetti. Introduce una nuova architettura di rete leggera, migliorando la velocità e l’accuratezza del rilevamento. Rispetto al suo predecessore, YOLOv9 offre un’accuratezza media (AP) migliorata sul dataset MS COCO, grazie agli avanzamenti nelle informazioni programmabili sui gradienti e all’integrazione della tecnologia dei trasformatori, rendendola più efficiente nelle applicazioni reali.
Come iniziare con YOLOv9 per il rilevamento oggetti?
Per iniziare con YOLOv9, prima installa le dipendenze richieste, tra cui Python, PyTorch e CUDA per l’accelerazione GPU. Scarica il codice sorgente di YOLOv9 dal suo repository ufficiale. Addestra il modello con un dataset personalizzato o utilizza pesi preaddestrati disponibili online per rilevare oggetti. Eseguire lo script di rilevamento su un’immagine o un video produrrà un rilevamento oggetti in tempo reale, mostrando le capacità di YOLOv9.
Quali sono i miglioramenti chiave nelle prestazioni di YOLOv9?
YOLOv9 introduce miglioramenti chiave nelle prestazioni di rilevamento oggetti, principalmente un aumento della precisione media (AP) e una riduzione del tempo di inferenza. Sul dataset MS COCO, YOLOv9 dimostra un significativo aumento di AP, raggiungendo fino al 55,6% per alcuni modelli, insieme a tempi di rilevamento più veloci, rendendolo altamente adatto per le applicazioni in tempo reale. Questi miglioramenti sono attribuiti alla sua nuova architettura e alle tecniche di ottimizzazione.
YOLOv9 può essere integrato con dispositivi di edge computing?
Sì, YOLOv9 può essere integrato con dispositivi di edge computing come NVIDIA Jetson, grazie alla sua architettura ottimizzata che supporta un funzionamento efficiente su hardware con risorse computazionali limitate. Questa compatibilità consente a YOLOv9 di eseguire il rilevamento oggetti in tempo reale in scenari di edge, come telecamere di sorveglianza e veicoli autonomi, dove il rapido processamento è fondamentale.
Quali sono le sfide e le soluzioni nell’addestramento di YOLOv9?
Addestrare YOLOv9 comporta sfide come la diversità dei dati e i requisiti hardware. Un dataset diversificato è cruciale per ottenere un’alta precisione, mentre hardware potente accelera il processo di addestramento. Le soluzioni includono il potenziamento dei dataset per la diversità e il sfruttamento delle risorse di calcolo cloud o hardware specializzato come le GPU per un addestramento più veloce del modello. Il raffinamento dei modelli preaddestrati può anche ridurre significativamente il tempo di addestramento e il consumo di risorse.
Dove posso trovare risorse e supporto della comunità per YOLOv9?
Le risorse e il supporto della comunità per YOLOv9 sono abbondanti. Gli sviluppatori possono trovare documentazione, modelli preaddestrati ed esempi di codice nel repository ufficiale di YOLOv9 su GitHub. Per il supporto della comunità, forum come Reddit e Stack Overflow ospitano discussioni attive, consigli e consigli per la risoluzione dei problemi. Queste piattaforme forniscono una ricchezza di informazioni sia per principianti che per esperti che desiderano migliorare i loro progetti YOLOv9.