
What is Object Detection
Object detection in computer vision refers to the task of identifying and locating objects within an image or video frame. The goal is to not only classify what objects are present but also to provide the precise location of each object within the image. This typically involves drawing bounding boxes around the detected objects and labeling them with their corresponding class labels.
Object detection is a fundamental task in many computer vision applications, including:
- Autonomous driving: Detecting pedestrians, vehicles, traffic signs, and other objects on the road.
- Surveillance and security: Identifying people, vehicles, and suspicious activities in video feeds from CCTV.
- Medical imaging: Locating and classifying anomalies in medical images such as X-rays, MRIs, or CT scans.
- Retail: Counting and tracking products on store shelves or detecting shoplifting behaviors.
- Industrial automation: Inspecting manufactured products for defects or anomalies on production lines.
- Augmented reality: Recognizing objects in the environment to overlay digital information.
- Robotics: Enabling robots to perceive and interact with objects in their environment.
Object detection algorithms typically involve several steps:
- Feature extraction: The input image is analyzed to identify features that are relevant for object detection. This could involve techniques such as convolutional neural networks (CNNs) to extract hierarchical representations of the image.
- Localization: This step involves predicting the location of objects within the image. This is often done by regressing bounding box coordinates relative to the image frame.
- Classification: Each detected object is assigned a class label (e.g., person, car, dog) based on its visual characteristics. This is typically done using a classification model, often alongside the localization model.
- Post-processing: Finally, the detection results may undergo post-processing steps such as non-maximum suppression (NMS) to refine the bounding boxes and eliminate duplicate detections.
Typically the steps from feature extraction to post-processing are all handled by a Deep Convolutional Neural Network.
Popular approaches for object detection include:
- Two-stage detectors: These methods first propose regions of interest (RoIs) using techniques like selective search or region proposal networks (RPNs), and then classify and refine these proposals. Examples include Faster R-CNN, R-FCN, and Mask R-CNN.
- One-stage detectors: These methods directly predict object bounding boxes and class probabilities in a single pass through the network, without a separate proposal stage. Examples include YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector), and RetinaNet.
While two-stage detectors boast superior accuracy, they are often computationally more expensive to run and can not be used for many real-time applications. One-stage detectors sacrifice some accuracy for speed. As is typically the case with neural networks, one must define priorities between speed and accuracy when selecting a model to use.
Object detection has seen significant advancements in recent years, driven by improvements in deep learning techniques, dataset sizes, and computational resources.
What is YOLO
YOLO (You Only Look Once) is a family of real-time object detection models that are highly efficient and capable of detecting objects in images or video frames with remarkable speed. The key characteristic of YOLO models is their ability to perform object detection in a single pass through the neural network, hence the name “You Only Look Once.”
There have been several iterations and versions of YOLO models, each with improvements over the previous versions. However, the general architecture and principles remain consistent across the different versions. Here’s a general overview of how YOLO models work:
1. Grid-based approach: YOLO divides the input image into a grid of cells. Each cell is responsible for predicting bounding boxes and class probabilities for objects whose centers fall within that cell.
2. Prediction: For each grid cell, YOLO predicts bounding boxes (typically 2 or more per cell) along with confidence scores representing the likelihood that the bounding box contains an object and class probabilities for each class.
3. Single-pass prediction: YOLO processes the entire image through a convolutional neural network (CNN) in a single forward pass to make these predictions. This is in contrast to some other object detection methods that require multiple passes or region proposals.
4. Output format: The output of a YOLO model is a set of bounding boxes, confidence scores, and class probabilities. These bounding boxes are directly predicted by the network and do not rely on any post-processing steps like non-maximum suppression (NMS) to refine them.
5. Loss function: YOLO uses a combination of localization loss (measuring the accuracy of bounding box predictions) and classification loss (measuring the accuracy of class predictions) to train the model. The loss function is designed to penalize inaccurate predictions while simultaneously encouraging the model to make confident predictions for objects.
YOLOv9 intro
YOLOv9, the latest iteration of the popular You Only Look Once (YOLO) series, represents a cutting-edge advancement in real-time object detection systems. Building upon the success of its predecessors, YOLOv9 introduces innovative concepts such as Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) to enhance the efficiency and accuracy of object detection tasks. By incorporating PGI, YOLOv9 addresses the challenge of data loss in deep networks by ensuring the preservation of key features and reliable gradient generation for optimal training outcomes. Additionally, the integration of GELAN offers a lightweight network architecture that optimizes parameter utilization and computational efficiency, making YOLOv9 a versatile and high-performing solution for a wide range of applications.

With a focus on real-time object detection, YOLOv9 builds on state-of-the-art methodologies such as CSPNet, ELAN, and improved feature integration techniques to deliver superior performance in various computer vision tasks. By introducing the power of PGI for gradient information programming and GELAN for efficient layer aggregation, YOLOv9 sets a new standard for object detection systems, surpassing existing real-time detectors in terms of accuracy, speed, and parameter usage. This next-generation YOLO model promises to revolutionize the field of computer vision with its advanced capabilities and exceptional performance on datasets like MS COCO, establishing itself as a top contender in the realm of real-time object detection.
What issues YOLOv9 solves
YOLOv9 has achieved superior performance thanks to solving several problems that appear when training deep neural networks.
The information bottleneck problem in deep neural networks refers to the phenomenon where input data undergoes layer-by-layer feature extraction and spatial transformation, leading to a loss of important information. As data flows through successive layers of a deep network, the original data may gradually lose its distinct characteristics and essential details, resulting in an information bottleneck. This bottleneck restricts the network’s ability to retain complete information about the prediction target, which can lead to unreliable gradients during training and poor convergence of the model.
To address the information bottleneck problem, researchers in the paper have explored various methods such as reversible architectures, masked modeling, and deep supervision. Reversible architectures aim to maintain the information of input data explicitly through repeated input data usage. Masked modeling focuses on maximizing extracted features implicitly to retain input information. Deep supervision involves pre-establishing a mapping from shallow features to targets to ensure important information transfer to deeper layers. However, these methods have limitations and drawbacks, such as increased inference costs, conflicts between reconstruction loss and target loss, error accumulation, and difficulty in modeling high-order semantic information.
By introducing Programmable Gradient Information (PGI) in their research, the authors of YOLOv9 provide a novel solution to the information bottleneck problem. PGI generates reliable gradients through an auxiliary reversible branch, enabling deep features to maintain key characteristics necessary for executing target tasks. This approach ensures that important information is preserved and accurate gradients are obtained for updating network weights effectively, thereby improving the convergence and training outcomes of deep neural networks.
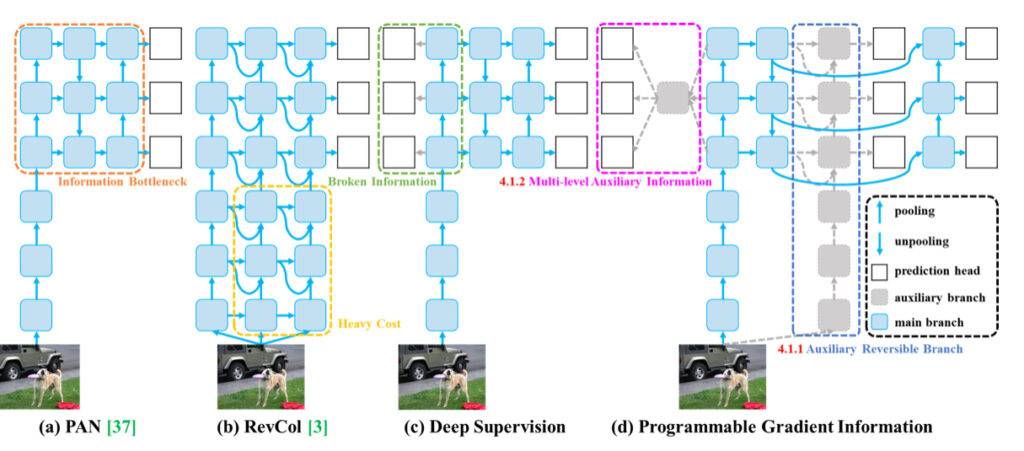
The second problem solved by the authors of YOLOv9 is inefficiencies relating to parameter utilization.
The Generalized Efficient Layer Aggregation Network (GELAN) introduced by the authors enhances parameter utilization and computational efficiency in deep neural networks by creating a novel lightweight architecture that optimizes the utilization of parameters and computational resources. Here are some key ways in which GELAN achieves this:
1. Computational Block Flexibility: GELAN allows for the use of different computational blocks such as Res blocks, Dark blocks, and CSP blocks. By conducting ablation studies on these computational blocks, GELAN demonstrates the ability to maintain good performance while offering users the flexibility to choose and replace computational blocks based on their specific requirements. This flexibility not only reduces the number of parameters but also improves the overall computational efficiency of the network.
2. Parameter Efficiency: GELAN is designed to achieve better parameter utilization compared to state-of-the-art methods based on depth-wise convolution. By utilizing conventional convolution operators effectively, GELAN maximizes the utilization of parameters while maintaining high performance in object detection tasks. This efficient parameter usage contributes to the overall effectiveness and scalability of the network.
3. Depth Sensitivity: GELAN’s performance is not overly sensitive to the depth of the network. Experiments show that increasing the depth of GELAN does not lead to diminishing returns in terms of parameter utilization and computational efficiency. This characteristic allows GELAN to maintain a consistent level of performance across different depths, ensuring that the network remains efficient and effective regardless of its complexity.
4. Inference Device Adaptability: GELAN’s architecture is designed to be adaptable to various inference devices, allowing users to choose computational blocks that are suitable for their specific hardware requirements. This adaptability ensures that GELAN can be efficiently deployed on a wide range of devices without compromising performance or computational efficiency.
By combining these factors, GELAN enhances parameter utilization and computational efficiency in deep neural networks, making it a versatile and high-performing solution for a variety of applications, including real-time object detection tasks.
In the following video comparing YOLOv8 and YOLOv9 you can also clearly see the advancements on detecting smaller objects versus YOLOv8.
Performance Comparison
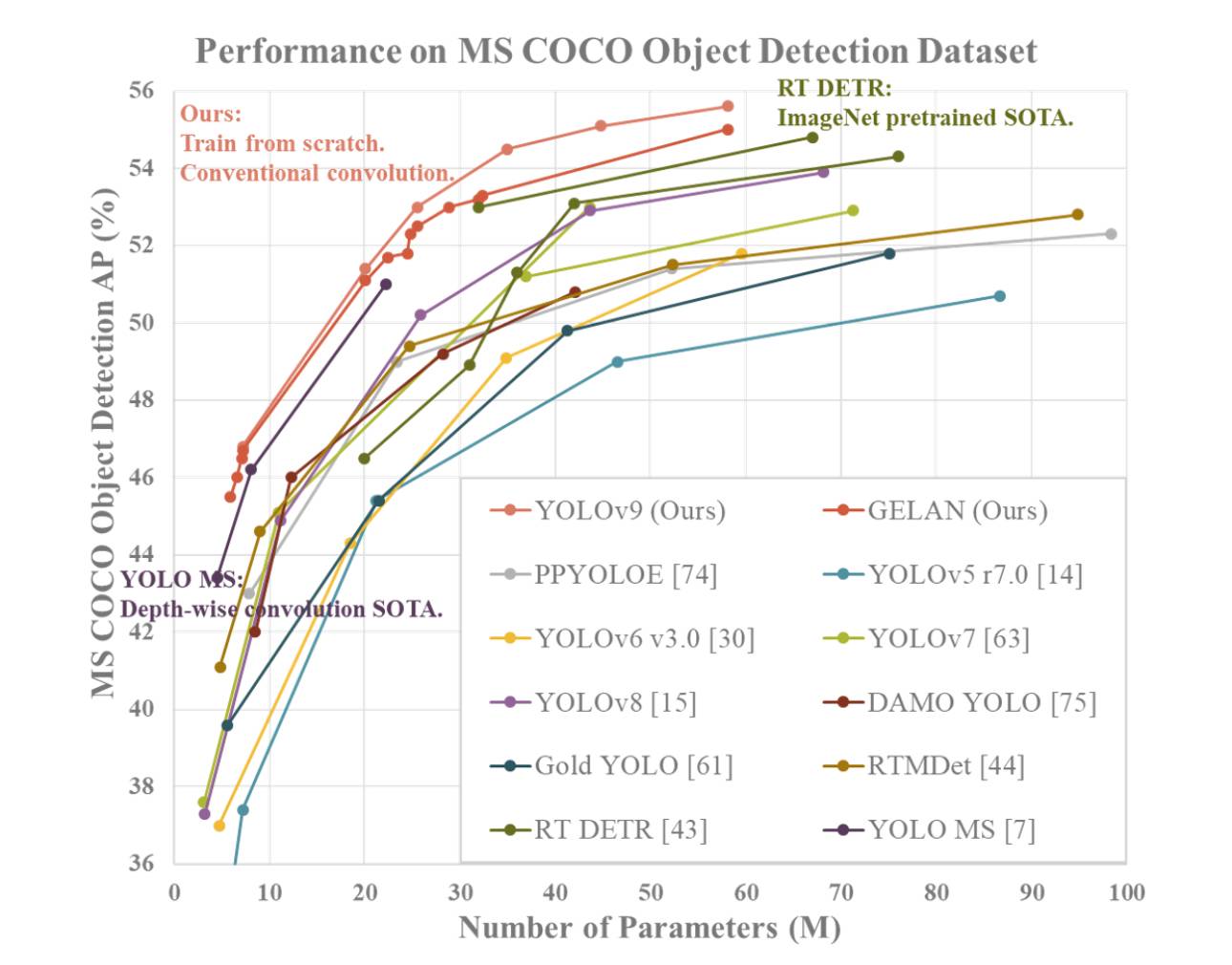
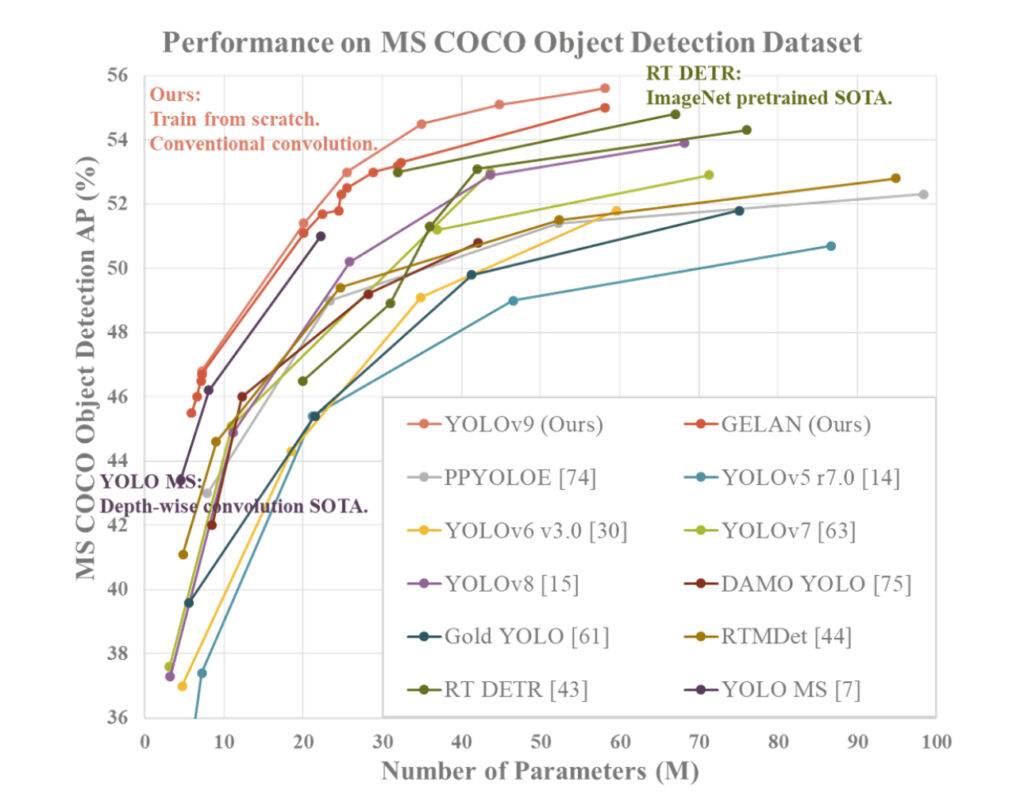
YOLOv9 demonstrates superior performance compared to previous state-of-the-art real-time object detectors across various metrics. Here is a summary of the comparison based on the provided information:
1. Parameter Reduction: YOLOv9 achieves a significant reduction in the number of parameters compared to previous detectors, such as YOLOv8. This reduction in parameters contributes to improved computational efficiency and faster inference speeds.
2. Computational Efficiency: YOLOv9 also reduces the amount of computation required for object detection tasks, leading to enhanced efficiency in processing and analyzing visual data.
3. Accuracy Improvement: Despite the reduction in parameters and computation, YOLOv9 manages to improve the Average Precision (AP) metric by a notable margin on the MS COCO dataset. This improvement in accuracy showcases the effectiveness of the proposed PGI and GELAN mechanisms in enhancing the detection performance of the model.
4. Competitiveness: YOLOv9 demonstrates strong competitiveness when compared to other real-time object detectors trained using different methods, including train-from-scratch, pretrained by ImageNet, knowledge distillation, and complex training processes. The model outperforms these methods in terms of accuracy, parameter efficiency, and computational speed.
5. Versatility: The combination of PGI and GELAN in YOLOv9 allows for the successful integration of lightweight architectures with deep models, enabling a wide range of applications in real-time object detection across various inference devices.
Overall, YOLOv9 stands out as a top-performing object detection system that excels in accuracy, efficiency, and parameter utilization, making it a compelling choice for real-time computer vision tasks.
| Model | APval (%) | AP50_val (%) | AP75_val (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Conclusion
YOLOv9 showcases the significant advancements made in real-time object detection through implementation and leveraging of innovative techniques such as Generalized Efficient Layer Aggregation Network (GELAN) and Programmable Gradient Information (PGI). By addressing critical issues like the information bottleneck problem and optimizing parameter utilization and computational efficiency, YOLOv9 emerges as a top contender in the field of object detection.
Comparative analysis demonstrates that YOLOv9 outperforms existing methods in terms of accuracy, parameter efficiency, and computational speed. Its ability to reduce parameters while improving Average Precision (AP) on datasets like MS COCO highlights the effectiveness of the proposed enhancements. Furthermore, the adaptability of YOLOv9 to different inference devices underscores its versatility and applicability across various real-time object detection scenarios.
Overall, the research not only advances the state of the art in real-time object detection but also sets a new standard for efficiency, performance, and parameter utilization in deep neural networks. The success of YOLOv9 in overcoming key challenges and delivering superior results underscores its potential to drive further innovations in computer vision and machine learning applications.
FAQ on YOLOv9
In the rapidly evolving field of computer vision, YOLOv9 stands out as a significant leap forward, combining efficiency with groundbreaking accuracy. As interest in this advanced object detection model grows, so do questions about its application, performance, and accessibility. Below, we address the most common inquiries to help both newcomers and seasoned professionals get a clearer picture of what YOLOv9 offers and how it can transform their vision-based projects.
What Is YOLOv9 and How Does It Differ from Previous Versions?
YOLOv9 is the latest iteration in the YOLO (You Only Look Once) series, known for its object detection capabilities. It introduces a new lightweight network architecture, enhancing detection speed and accuracy. Compared to its predecessor, YOLOv9 offers improved average precision (AP) on the MS COCO dataset, thanks to advancements in programmable gradient information and the integration of transformer technology, making it more efficient in real-world applications.
How to Get Started with YOLOv9 for Object Detection?
To start with YOLOv9, first, install the required dependencies, including Python, PyTorch, and CUDA for GPU acceleration. Download the YOLOv9 source code from its official repository. Train the model with a custom dataset or use pre-trained weights available online to detect objects. Running the detection script on an image or video will yield real-time object detection, showcasing YOLOv9’s capabilities.
What Are the Key Improvements in YOLOv9’s Performance?
YOLOv9 introduces key improvements in object detection performance, notably an increase in average precision (AP) and a reduction in inference time. On the MS COCO dataset, YOLOv9 demonstrates a significant boost in AP, reaching up to 55.6% for some models, alongside faster detection speeds, making it highly suitable for real-time applications. These enhancements are attributed to its new architecture and optimization techniques.
Can YOLOv9 Be Integrated with Edge Computing Devices?
Yes, YOLOv9 can be integrated with edge computing devices such as NVIDIA Jetson, thanks to its optimized architecture that supports efficient operation on hardware with limited computational resources. This compatibility enables YOLOv9 to perform real-time object detection in edge scenarios, such as surveillance cameras and autonomous vehicles, where quick processing is critical.
What Are the Challenges and Solutions in Training YOLOv9?
Training YOLOv9 poses challenges such as data diversity and hardware requirements. A diverse dataset is crucial for achieving high accuracy, while powerful hardware accelerates the training process. Solutions include augmenting datasets for diversity and leveraging cloud computing resources or specialized hardware like GPUs for faster model training. Fine-tuning pre-trained models can also significantly reduce training time and resource consumption.
Where Can I Find Resources and Community Support for YOLOv9?
Resources and community support for YOLOv9 are abundant. Developers can find documentation, pre-trained models, and code examples in the official YOLOv9 GitHub repository. For community support, forums such as Reddit and Stack Overflow host active discussions, tips, and troubleshooting advice. These platforms provide a wealth of information for both beginners and experts looking to enhance their YOLOv9 projects.