
¿Qué es la Detección de Objetos?
La detección de objetos en visión por computadora se refiere a la tarea de identificar y localizar objetos dentro de una imagen o fotograma de video. El objetivo no es solo clasificar qué objetos están presentes, sino también proporcionar la ubicación precisa de cada objeto dentro de la imagen. Esto suele implicar dibujar cuadros delimitadores alrededor de los objetos detectados y etiquetarlos con sus etiquetas de clase correspondientes.
La detección de objetos es una tarea fundamental en muchas aplicaciones de visión por computadora, incluyendo:
- Conducción autónoma: Detección de peatones, vehículos, señales de tráfico y otros objetos en la carretera.
- Vigilancia y seguridad: Identificación de personas, vehículos y actividades sospechosas en flujos de video.
- Imágenes médicas: Localización y clasificación de anomalías en imágenes médicas como radiografías, resonancias magnéticas o tomografías computarizadas.
- Retail: Conteo y seguimiento de productos en estantes de tiendas o detección de comportamientos de robo.
- Automatización industrial: Inspección de productos fabricados en busca de defectos o anomalías en las líneas de producción.
- Realidad aumentada: Reconocimiento de objetos en el entorno para superponer información digital.
- Robótica: Permitir que los robots perciban e interactúen con objetos en su entorno.
Los algoritmos de detección de objetos típicamente involucran varios pasos:
- Extracción de características: La imagen de entrada se analiza para identificar características relevantes para la detección de objetos. Esto podría implicar técnicas como redes neuronales convolucionales (CNN) para extraer representaciones jerárquicas de la imagen.
- Localización: Este paso implica predecir la ubicación de los objetos dentro de la imagen. A menudo se hace regresando coordenadas de cuadros delimitadores en relación con el marco de la imagen.
- Clasificación: A cada objeto detectado se le asigna una etiqueta de clase (por ejemplo, persona, coche, perro) según sus características visuales. Esto se hace típicamente usando un modelo de clasificación, a menudo junto con el modelo de localización.
- Post-procesamiento: Finalmente, los resultados de detección pueden pasar por pasos de post-procesamiento como supresión de no máximos (NMS) para refinar los cuadros delimitadores y eliminar detecciones duplicadas.
Típicamente, los pasos desde la extracción de características hasta el post-procesamiento son manejados por una Red Neuronal Convolucional Profunda.
Enfoques populares para la detección de objetos incluyen:
- Detectores de dos etapas: Estos métodos primero proponen regiones de interés (RoIs) utilizando técnicas como búsqueda selectiva o redes de propuestas de región (RPNs), y luego clasifican y refinan estas propuestas. Ejemplos incluyen Faster R-CNN, R-FCN y Mask R-CNN.
- Detectores de una sola etapa: Estos métodos predicen directamente cuadros delimitadores de objetos y probabilidades de clase en un solo paso a través de la red, sin una etapa de propuesta separada. Ejemplos incluyen YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) y RetinaNet.
Si bien los detectores de dos etapas tienen una precisión superior, a menudo son computacionalmente más costosos de ejecutar y no se pueden utilizar para muchas aplicaciones en tiempo real. Los detectores de una sola etapa sacrifican algo de precisión por velocidad. Como suele ser el caso con las redes neuronales, es necesario definir prioridades entre velocidad y precisión al seleccionar un modelo para usar.
La detección de objetos ha visto avances significativos en los últimos años, impulsados por mejoras en técnicas de aprendizaje profundo, tamaños de conjuntos de datos y recursos computacionales.
¿Qué es YOLO?
YOLO (You Only Look Once) es una familia de modelos de detección de objetos en tiempo real que son altamente eficientes y capaces de detectar objetos en imágenes o fotogramas de video con una velocidad notable. La característica clave de los modelos YOLO es su capacidad para realizar la detección de objetos en un solo paso a través de la red neuronal, de ahí el nombre «You Only Look Once».
Ha habido varias iteraciones y versiones de los modelos YOLO, cada una con mejoras sobre las versiones anteriores. Sin embargo, la arquitectura general y los principios permanecen consistentes en las diferentes versiones. Aquí hay una visión general de cómo funcionan los modelos YOLO:
- Enfoque basado en cuadrícula: YOLO divide la imagen de entrada en una cuadrícula de celdas. Cada celda es responsable de predecir cuadros delimitadores y probabilidades de clase para los objetos cuyos centros caen dentro de esa celda.
- Predicción: Para cada celda de la cuadrícula, YOLO predice cuadros delimitadores (típicamente 2 o más por celda) junto con puntuaciones de confianza que representan la probabilidad de que el cuadro delimitador contenga un objeto y probabilidades de clase para cada clase.
- Predicción de un solo paso: YOLO procesa la imagen completa a través de una red neuronal convolucional (CNN) en un solo paso hacia adelante para hacer estas predicciones. Esto contrasta con algunos otros métodos de detección de objetos que requieren múltiples pasadas o propuestas de región.
- Formato de salida: La salida de un modelo YOLO es un conjunto de cuadros delimitadores, puntuaciones de confianza y probabilidades de clase. Estos cuadros delimitadores son predichos directamente por la red y no dependen de ningún paso de post-procesamiento como supresión de no máximos (NMS) para refinarlos.
- Función de pérdida: YOLO utiliza una combinación de pérdida de localización (que mide la precisión de las predicciones de cuadros delimitadores) y pérdida de clasificación (que mide la precisión de las predicciones de clase) para entrenar el modelo. La función de pérdida está diseñada para penalizar predicciones inexactas al mismo tiempo que fomenta que el modelo haga predicciones confiables para los objetos.
Introducción a YOLOv9
YOLOv9, la última iteración de la popular serie You Only Look Once (YOLO), representa un avance de vanguardia en los sistemas de detección de objetos en tiempo real. Basándose en el éxito de sus predecesores, YOLOv9 introduce conceptos innovadores como Información de Gradiente Programable (PGI) y Red de Agregación de Capas Eficientes Generalizadas (GELAN) para mejorar la eficiencia y precisión de las tareas de detección de objetos. Al incorporar PGI, YOLOv9 aborda el desafío de la pérdida de datos en redes profundas al garantizar la preservación de características clave y la generación confiable de gradientes para obtener resultados de entrenamiento óptimos. Además, la integración de GELAN ofrece una arquitectura de red ligera que optimiza la utilización de parámetros y la eficiencia computacional, convirtiendo a YOLOv9 en una solución versátil y de alto rendimiento para una amplia gama de aplicaciones.

Con un enfoque en la detección de objetos en tiempo real, YOLOv9 se basa en metodologías de última generación como CSPNet, ELAN y técnicas mejoradas de integración de características para ofrecer un rendimiento superior en diversas tareas de visión por computadora. Al introducir la potencia de PGI para la programación de información de gradiente y GELAN para la agregación eficiente de capas, YOLOv9 establece un nuevo estándar para los sistemas de detección de objetos, superando a los detectores en tiempo real existentes en términos de precisión, velocidad y uso de parámetros. Este modelo YOLO de próxima generación promete revolucionar el campo de la visión por computadora con sus capacidades avanzadas y su rendimiento excepcional en conjuntos de datos como MS COCO, estableciéndose como un competidor destacado en el ámbito de la detección de objetos en tiempo real.
Problemas Resueltos por YOLOv9
YOLOv9 ha logrado un rendimiento superior gracias a la resolución de varios problemas que surgen al entrenar redes neuronales profundas.
El problema del cuello de botella de información en redes neuronales profundas se refiere al fenómeno en el que los datos de entrada sufren extracción de características capa por capa y transformación espacial, lo que conduce a una pérdida de información importante. A medida que los datos fluyen a través de capas sucesivas de una red profunda, los datos originales pueden perder gradualmente sus características distintivas y detalles esenciales, lo que resulta en un cuello de botella de información. Este cuello de botella restringe la capacidad de la red para retener información completa sobre el objetivo de predicción, lo que puede llevar a gradientes poco confiables durante el entrenamiento y una convergencia deficiente del modelo.
Para abordar el problema del cuello de botella de información, los investigadores han explorado varios métodos como arquitecturas reversibles, modelado enmascarado y supervisión profunda. Las arquitecturas reversibles tienen como objetivo mantener la información de los datos de entrada de manera explícita a través del uso repetido de datos de entrada. El modelado enmascarado se centra en maximizar las características extraídas implícitamente para retener la información de entrada. La supervisión profunda implica establecer previamente un mapeo de características superficiales a objetivos para garantizar la transferencia de información importante a capas más profundas. Sin embargo, estos métodos tienen limitaciones y desventajas, como costos de inferencia aumentados, conflictos entre pérdida de reconstrucción y pérdida de objetivo, acumulación de errores y dificultad para modelar información semántica de alto orden.
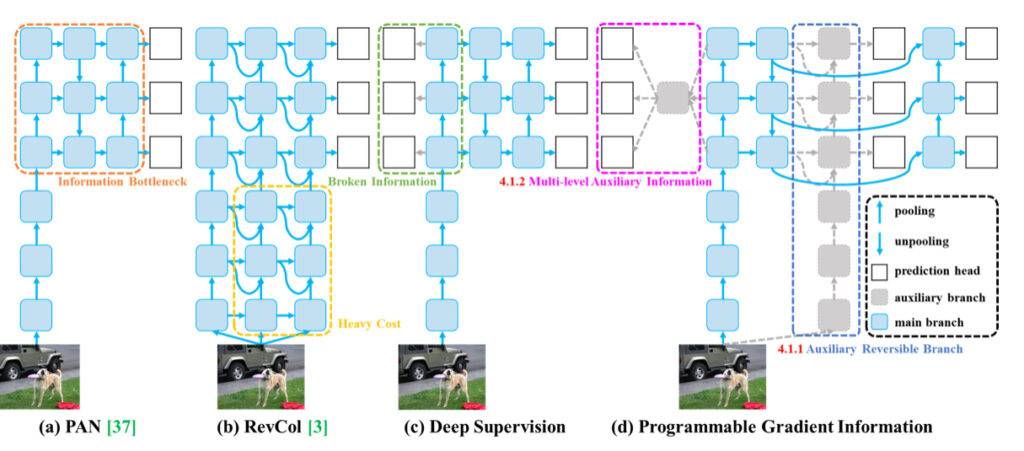
Al introducir Información de Gradiente Programable (PGI) en su investigación, los autores de YOLOv9 proporcionan una solución novedosa al problema del cuello de botella de información. PGI genera gradientes confiables a través de una rama reversible auxiliar, permitiendo que las características profundas mantengan características clave necesarias para ejecutar tareas de objetivo. Este enfoque garantiza que la información importante se conserve y se obtengan gradientes precisos para actualizar los pesos de la red de manera efectiva, mejorando así la convergencia y los resultados de entrenamiento de las redes neuronales profundas.
El segundo problema resuelto por los autores de YOLOv9 es la ineficiencia relacionada con la utilización de parámetros. La Red de Agregación de Capas Eficientes Generalizadas (GELAN) introducida por los autores mejora la utilización de parámetros y la eficiencia computacional en redes neuronales profundas mediante la creación de una arquitectura de red ligera que optimiza la utilización de parámetros y recursos computacionales. Aquí hay algunas formas clave en las que GELAN logra esto:
- Flexibilidad de Bloques Computacionales: GELAN permite el uso de diferentes bloques computacionales como bloques Res, bloques Dark y bloques CSP. Al realizar estudios de abstracción en estos bloques computacionales, GELAN demuestra la capacidad de mantener un buen rendimiento mientras ofrece a los usuarios la flexibilidad de elegir y reemplazar bloques computacionales según sus requisitos específicos. Esta flexibilidad no solo reduce el número de parámetros, sino que también mejora la eficiencia computacional general de la red.
- Eficiencia de Parámetros: GELAN está diseñado para lograr una mejor utilización de parámetros en comparación con los métodos de vanguardia basados en convolución a nivel de profundidad. Al utilizar operadores de convolución convencionales de manera efectiva, GELAN maximiza la utilización de parámetros mientras mantiene un alto rendimiento en tareas de detección de objetos. Este uso eficiente de parámetros contribuye a la efectividad y escalabilidad general de la red.
- Sensibilidad a la Profundidad: El rendimiento de GELAN no es excesivamente sensible a la profundidad de la red. Los experimentos muestran que aumentar la profundidad de GELAN no conduce a rendimientos decrecientes en términos de utilización de parámetros y eficiencia computacional. Esta característica permite que GELAN mantenga un nivel de rendimiento consistente en diferentes profundidades, asegurando que la red permanezca eficiente y efectiva independientemente de su complejidad.
- Adaptabilidad del Dispositivo de Inferencia: La arquitectura de GELAN está diseñada para ser adaptable a diversos dispositivos de inferencia, lo que permite a los usuarios elegir bloques computacionales que sean adecuados para sus requisitos de hardware específicos. Esta adaptabilidad garantiza que GELAN se pueda implementar de manera eficiente en una amplia gama de dispositivos sin comprometer el rendimiento o la eficiencia computacional.
Al combinar estos factores, GELAN mejora la utilización de parámetros y la eficiencia computacional en redes neuronales profundas, convirtiéndolo en una solución versátil y de alto rendimiento para una variedad de aplicaciones, incluidas tareas de detección de objetos en tiempo real.
Comparación de Rendimiento
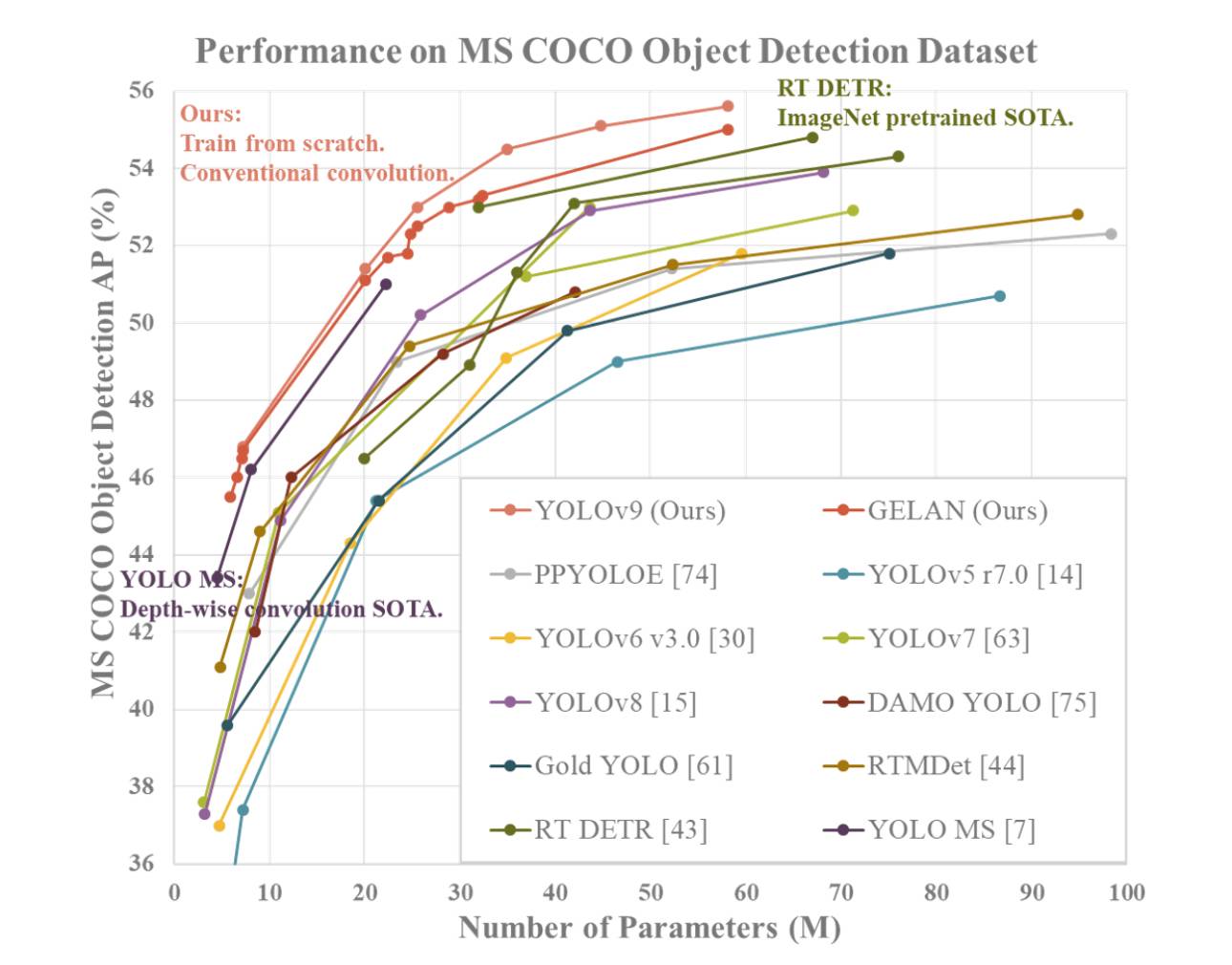
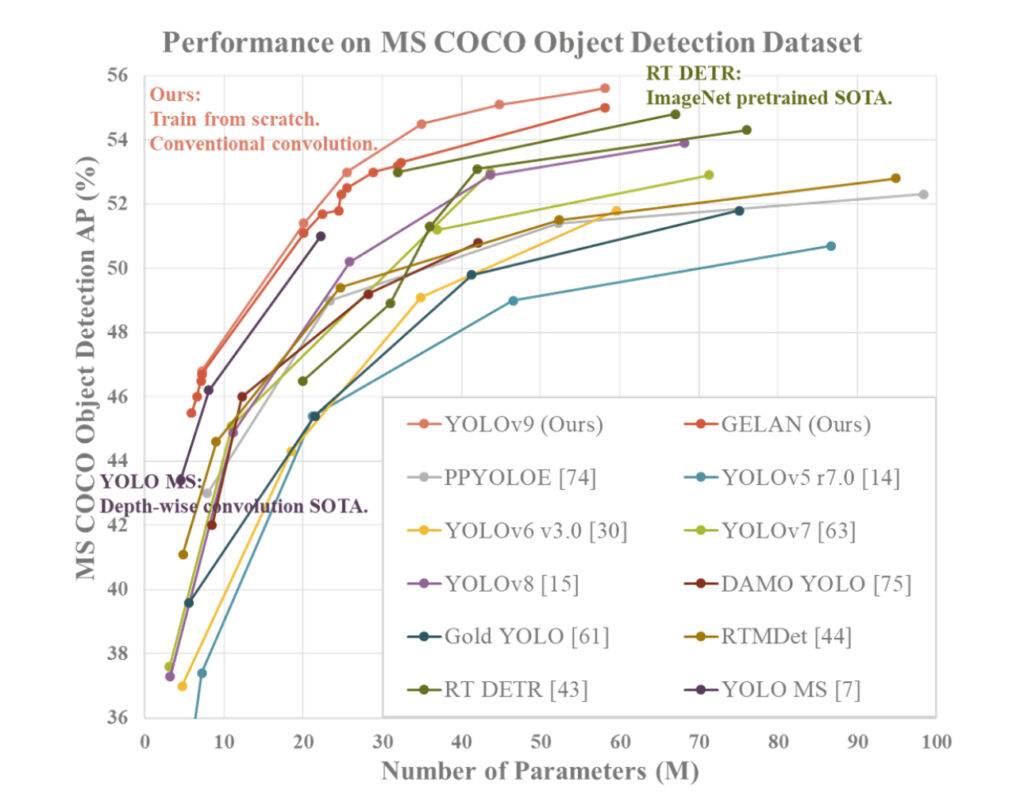
YOLOv9 demuestra un rendimiento superior en comparación con los detectores de objetos en tiempo real previos de vanguardia en diversas métricas. Aquí hay un resumen de la comparación basada en la información proporcionada:
- Reducción de Parámetros: YOLOv9 logra una reducción significativa en el número de parámetros en comparación con detectores previos, como YOLOv8. Esta reducción en los parámetros contribuye a una mayor eficiencia computacional y velocidades de inferencia más rápidas.
- Eficiencia Computacional: YOLOv9 también reduce la cantidad de cálculos requeridos para tareas de detección de objetos, lo que conduce a una mayor eficiencia en el procesamiento y análisis de datos visuales.
- Mejora de Precisión: A pesar de la reducción en parámetros y cálculos, YOLOv9 logra mejorar la métrica de Precisión Promedio (AP) en el conjunto de datos MS COCO en un margen notable. Esta mejora en la precisión muestra la efectividad de los mecanismos PGI y GELAN propuestos en mejorar el rendimiento de detección del modelo.
- Competitividad: YOLOv9 muestra una fuerte competitividad en comparación con otros detectores de objetos en tiempo real entrenados utilizando diferentes métodos, incluyendo entrenamiento desde cero, pre-entrenados por ImageNet, destilación de conocimientos y procesos de entrenamiento complejos. El modelo supera a estos métodos en términos de precisión, eficiencia de parámetros y velocidad computacional.
- Versatilidad: La combinación de PGI y GELAN en YOLOv9 permite la integración exitosa de arquitecturas ligeras con modelos profundos, lo que permite una amplia gama de aplicaciones en tareas de detección de objetos en tiempo real en diversos dispositivos de inferencia.
En general, YOLOv9 se destaca como un sistema de detección de objetos de alto rendimiento que sobresale en precisión, eficiencia y utilización de parámetros, lo que lo convierte en una opción convincente para tareas de visión por computadora en tiempo real.
| Model | APval (%) | AP50_val (%) | AP75_val (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Conclusión
YOLOv9 muestra los avances significativos realizados en la detección de objetos en tiempo real mediante la implementación y el aprovechamiento de técnicas innovadoras como la Red de Agregación de Capas Eficientes Generalizadas (GELAN) e Información de Gradiente Programable (PGI). Al abordar problemas críticos como el problema del cuello de botella de información y optimizar la utilización de parámetros y la eficiencia computacional, YOLOv9 emerge como un competidor destacado en el campo de la detección de objetos.
El análisis comparativo demuestra que YOLOv9 supera a los métodos existentes en términos de precisión, eficiencia de parámetros y velocidad computacional. Su capacidad para reducir parámetros mientras mejora la Precisión Promedio (AP) en conjuntos de datos como MS COCO resalta la efectividad de las mejoras propuestas. Además, la adaptabilidad de YOLOv9 a diferentes dispositivos de inferencia subraya su versatilidad y aplicabilidad en diversos escenarios de detección de objetos en tiempo real.
En general, la investigación no solo avanza en el estado del arte en la detección de objetos en tiempo real, sino que también establece un nuevo estándar para la eficiencia, el rendimiento y la utilización de parámetros en redes neuronales profundas. El éxito de YOLOv9 en superar desafíos clave y ofrecer resultados superiores subraya su potencial para impulsar nuevas innovaciones en aplicaciones de visión por computadora y aprendizaje automático.
FAQ sobre YOLOv9
En el campo en constante evolución de la visión por computadora, YOLOv9 se destaca como un avance significativo, combinando eficiencia con una precisión revolucionaria. A medida que crece el interés en este modelo avanzado de detección de objetos, también surgen preguntas sobre su aplicación, rendimiento y accesibilidad. A continuación, abordamos las consultas más comunes para ayudar tanto a los recién llegados como a los profesionales experimentados a tener una imagen más clara de lo que ofrece YOLOv9 y cómo puede transformar sus proyectos basados en visión.
¿Qué es YOLOv9 y cómo difiere de las versiones anteriores?
YOLOv9 es la última iteración en la serie YOLO (You Only Look Once), conocida por sus capacidades de detección de objetos. Introduce una nueva arquitectura de red ligera, mejorando la velocidad y precisión de detección. En comparación con su predecesor, YOLOv9 ofrece una mejora en la precisión promedio (AP) en el conjunto de datos MS COCO, gracias a avances en información de gradiente programable e integración de tecnología transformadora, lo que lo hace más eficiente en aplicaciones del mundo real.
¿Cómo empezar con YOLOv9 para la detección de objetos?
Para comenzar con YOLOv9, primero, instale las dependencias requeridas, incluyendo Python, PyTorch y CUDA para aceleración GPU. Descargue el código fuente de YOLOv9 desde su repositorio oficial. Entrene el modelo con un conjunto de datos personalizado o use pesos pre-entrenados disponibles en línea para detectar objetos. Ejecutar el script de detección en una imagen o video producirá detección de objetos en tiempo real, mostrando las capacidades de YOLOv9.
¿Cuáles son las mejoras clave en el rendimiento de YOLOv9?
YOLOv9 introduce mejoras clave en el rendimiento de detección de objetos, especialmente un aumento en la precisión promedio (AP) y una reducción en el tiempo de inferencia. En el conjunto de datos MS COCO, YOLOv9 demuestra un aumento significativo en AP, alcanzando hasta un 55.6% para algunos modelos, junto con velocidades de detección más rápidas, lo que lo hace altamente adecuado para aplicaciones en tiempo real. Estas mejoras se atribuyen a su nueva arquitectura y técnicas de optimización.
¿Se puede integrar YOLOv9 con dispositivos de cómputo en el borde?
Sí, YOLOv9 se puede integrar con dispositivos de cómputo en el borde, gracias a su arquitectura optimizada que admite una operación eficiente en hardware con recursos computacionales limitados. Esta compatibilidad permite que YOLOv9 realice detección de objetos en tiempo real en escenarios en el borde, como cámaras de vigilancia y vehículos autónomos, donde el procesamiento rápido es crítico.
¿Cuáles son los desafíos y soluciones en el entrenamiento de YOLOv9?
Entrenar YOLOv9 plantea desafíos como la diversidad de datos y los requisitos de hardware. Un conjunto de datos diverso es crucial para lograr una alta precisión, mientras que un hardware potente acelera el proceso de entrenamiento. Las soluciones incluyen aumentar los conjuntos de datos para obtener diversidad y aprovechar los recursos de computación en la nube o hardware especializado como GPUs para un entrenamiento más rápido del modelo. Ajustar modelos pre-entrenados también puede reducir significativamente el tiempo de entrenamiento y el consumo de recursos.
¿Dónde puedo encontrar recursos y soporte comunitario para YOLOv9?
Los recursos y el soporte comunitario para YOLOv9 son abundantes. Los desarrolladores pueden encontrar documentación, modelos pre-entrenados y ejemplos de código en el repositorio oficial de YOLOv9 en GitHub. Para el soporte comunitario, foros como Reddit y Stack Overflow alojan discusiones activas, consejos y asesoramiento para resolver problemas. Estas plataformas proporcionan una gran cantidad de información tanto para principiantes como para expertos que buscan mejorar sus proyectos de YOLOv9.