
O que é Detecção de Objetos
A detecção de objetos na visão computacional refere-se à tarefa de identificar e localizar objetos dentro de uma imagem ou quadro de vídeo. O objetivo é não apenas classificar quais objetos estão presentes, mas também fornecer a localização precisa de cada objeto dentro da imagem. Isso geralmente envolve desenhar caixas delimitadoras ao redor dos objetos detectados e rotulá-los com suas respectivas classes.
A detecção de objetos é uma tarefa fundamental em muitas aplicações de visão computacional, incluindo:
- Condução autônoma: Detecção de pedestres, veículos, sinais de trânsito e outros objetos na estrada.
- Vigilância e segurança: Identificação de pessoas, veículos e atividades suspeitas em feeds de vídeo.
- Imagens médicas: Localização e classificação de anomalias em imagens médicas, como raios-X, ressonâncias magnéticas ou tomografias computadorizadas.
- Varejo: Contagem e rastreamento de produtos nas prateleiras das lojas ou detecção de comportamentos de furto.
- Automação industrial: Inspeção de produtos fabricados em busca de defeitos ou anomalias nas linhas de produção.
- Realidade aumentada: Reconhecimento de objetos no ambiente para sobrepor informações digitais.
- Robótica: Permitindo que robôs percebam e interajam com objetos em seu ambiente.
Os algoritmos de detecção de objetos geralmente envolvem várias etapas:
- Extração de características: A imagem de entrada é analisada para identificar características relevantes para a detecção de objetos. Isso pode envolver técnicas como redes neurais convolucionais (CNNs) para extrair representações hierárquicas da imagem.
- Localização: Esta etapa envolve prever a localização dos objetos dentro da imagem. Isso é frequentemente feito por meio da regressão das coordenadas das caixas delimitadoras em relação ao quadro da imagem.
- Classificação: Cada objeto detectado recebe um rótulo de classe (por exemplo, pessoa, carro, cachorro) com base em suas características visuais. Isso é geralmente feito usando um modelo de classificação, muitas vezes junto com o modelo de localização.
- Pós-processamento: Finalmente, os resultados da detecção podem passar por etapas de pós-processamento, como supressão de não-máximo (NMS) para refinar as caixas delimitadoras e eliminar detecções duplicadas.
Tipicamente, as etapas de extração de características até o pós-processamento são todas tratadas por uma Rede Neural Convolucional Profunda.
Abordagens populares para detecção de objetos incluem:
- Detectores de duas etapas: Esses métodos primeiro propõem regiões de interesse (RoIs) usando técnicas como busca seletiva ou redes de proposição de região (RPNs), e então classificam e refinam essas propostas. Exemplos incluem Faster R-CNN, R-FCN e Mask R-CNN.
- Detectores de uma etapa: Esses métodos preveem diretamente caixas delimitadoras de objetos e probabilidades de classe em uma única passagem pela rede, sem uma etapa de proposição separada. Exemplos incluem YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) e RetinaNet.
Embora os detectores de duas etapas possuam maior precisão, muitas vezes são computacionalmente mais caros de executar e não podem ser usados para muitas aplicações em tempo real. Os detectores de uma etapa sacrificam um pouco de precisão pela velocidade. Como é típico com redes neurais, é necessário definir prioridades entre velocidade e precisão ao selecionar um modelo a ser utilizado.
A detecção de objetos viu avanços significativos nos últimos anos, impulsionados por melhorias em técnicas de aprendizado profundo, tamanhos de conjuntos de dados e recursos computacionais.
O que é YOLO
YOLO (You Only Look Once) é uma família de modelos de detecção de objetos em tempo real que são altamente eficientes e capazes de detectar objetos em imagens ou quadros de vídeo com velocidade notável. A característica-chave dos modelos YOLO é sua capacidade de realizar a detecção de objetos em uma única passagem pela rede neural, daí o nome “You Only Look Once”.
Houve várias iterações e versões dos modelos YOLO, cada uma com melhorias em relação às versões anteriores. No entanto, a arquitetura geral e os princípios permanecem consistentes nas diferentes versões. Aqui está uma visão geral geral de como os modelos YOLO funcionam:
- Abordagem baseada em grade: YOLO divide a imagem de entrada em uma grade de células. Cada célula é responsável por prever caixas delimitadoras e probabilidades de classe para objetos cujos centros estão dentro dessa célula.
- Predição: Para cada célula da grade, YOLO prevê caixas delimitadoras (tipicamente 2 ou mais por célula) junto com pontuações de confiança que representam a probabilidade de que a caixa delimitadora contenha um objeto e probabilidades de classe para cada classe.
- Predição em uma única passagem: YOLO processa a imagem inteira através de uma rede neural convolucional (CNN) em uma única passagem para fazer essas previsões. Isso difere de alguns outros métodos de detecção de objetos que requerem múltiplas passagens ou propostas de região.
- Formato de saída: A saída de um modelo YOLO é um conjunto de caixas delimitadoras, pontuações de confiança e probabilidades de classe. Essas caixas delimitadoras são previstas diretamente pela rede e não dependem de etapas de pós-processamento como supressão de não-máximo (NMS) para refiná-las.
- Função de perda: YOLO usa uma combinação de perda de localização (medindo a precisão das previsões de caixa delimitadora) e perda de classificação (medindo a precisão das previsões de classe) para treinar o modelo. A função de perda é projetada para penalizar previsões imprecisas enquanto incentiva simultaneamente o modelo a fazer previsões confiantes para objetos.
Introdução ao YOLOv9
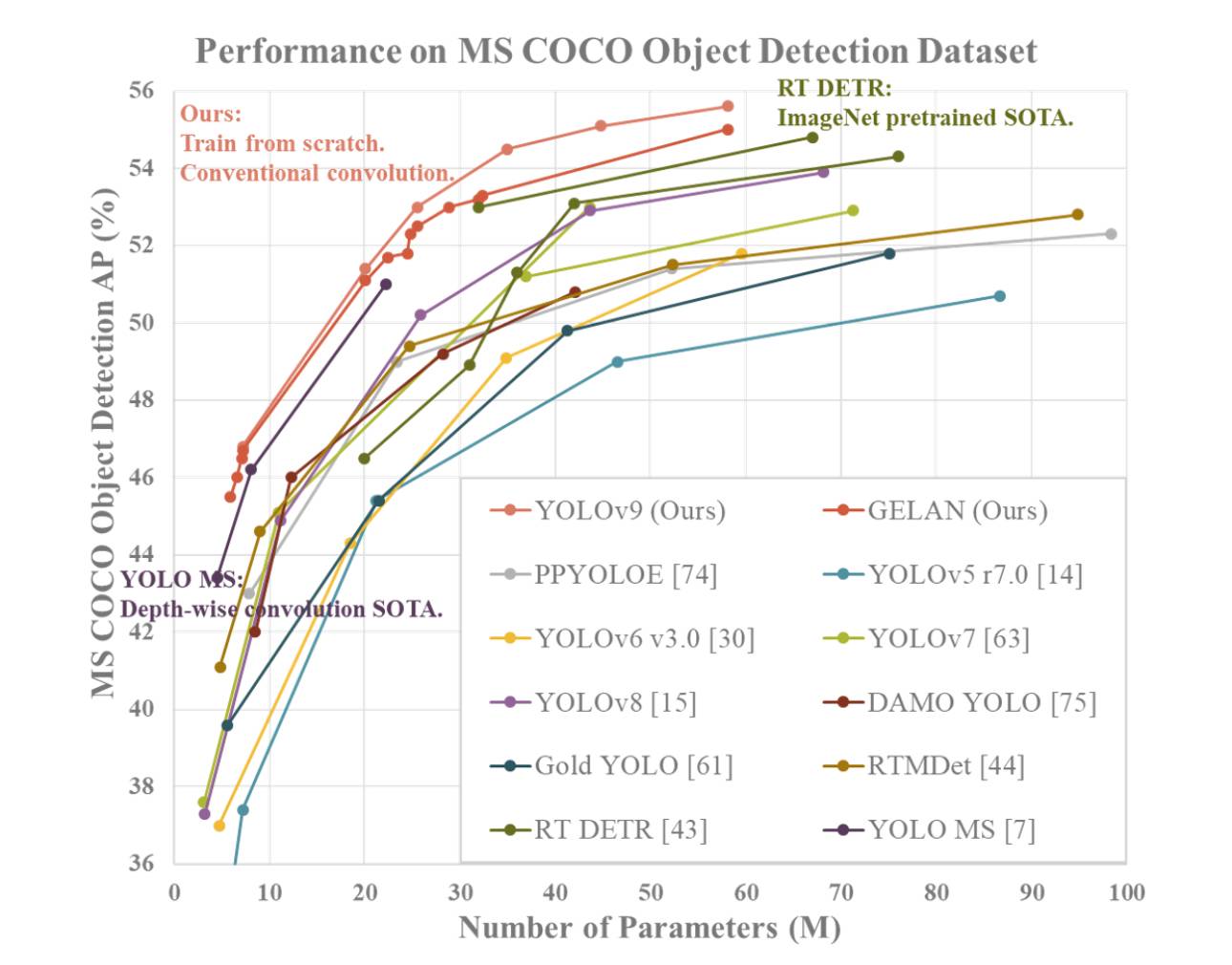
YOLOv9, a última iteração da popular série You Only Look Once (YOLO), representa um avanço de ponta em sistemas de detecção de objetos em tempo real. Construindo sobre o sucesso de seus predecessores, YOLOv9 introduz conceitos inovadores como Informações de Gradiente Programáveis (PGI, do inglês Programmable Gradient Information) e Rede de Agregação de Camada Eficiente Generalizada (GELAN, do inglês Generalized Efficient Layer Aggregation Network) para aprimorar a eficiência e a precisão de tarefas de detecção de objetos. Ao incorporar PGI, YOLOv9 aborda o desafio da perda de dados em redes profundas garantindo a preservação de características-chave e a geração de gradientes confiáveis para resultados de treinamento ótimos. Além disso, a integração de GELAN oferece uma arquitetura de rede leve que otimiza a utilização de parâmetros e eficiência computacional, tornando o YOLOv9 uma solução versátil e de alto desempenho para uma ampla gama de aplicações.
Com foco na detecção de objetos em tempo real, o YOLOv9 se baseia em metodologias de ponta como CSPNet, ELAN e técnicas de integração de características aprimoradas para fornecer desempenho superior em várias tarefas de visão computacional. Ao introduzir o poder do PGI para programação de informações de gradiente e GELAN para agregação eficiente de camadas, o YOLOv9 estabelece um novo padrão para sistemas de detecção de objetos, superando os detectores em tempo real existentes em termos de precisão, velocidade e uso de parâmetros. Este modelo YOLO de próxima geração promete revolucionar o campo da visão computacional com suas capacidades avançadas e desempenho excepcional em conjuntos de dados como MS COCO, estabelecendo-se como um dos principais concorrentes no domínio da detecção de objetos em tempo real.
Problemas Resolvidos pelo YOLOv9
O YOLOv9 alcançou desempenho superior graças à resolução de vários problemas que surgem durante o treinamento de redes neurais profundas.
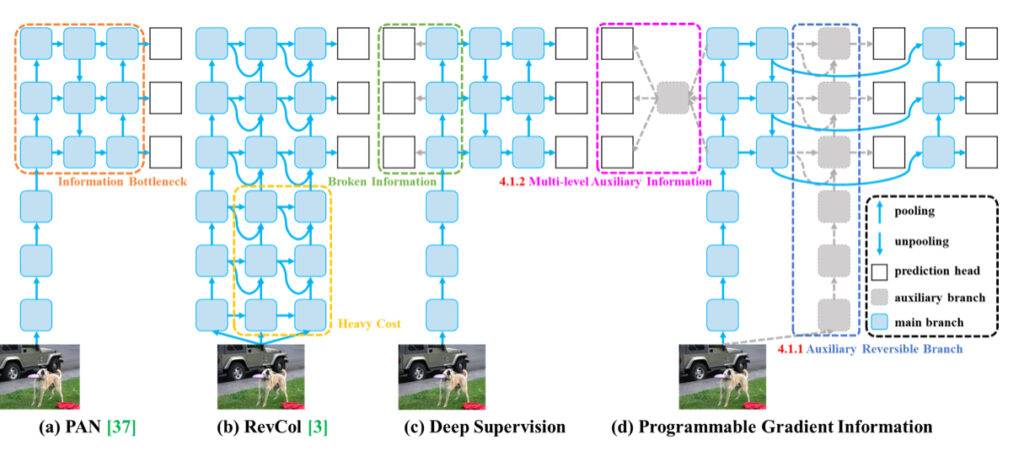
O problema do gargalo de informações em redes neurais profundas refere-se ao fenômeno em que os dados de entrada passam por extração de características camada a camada e transformação espacial, levando a uma perda de informações importantes. Conforme os dados fluem através de camadas sucessivas de uma rede profunda, os dados originais podem gradualmente perder suas características distintas e detalhes essenciais, resultando em um gargalo de informações. Esse gargalo restringe a capacidade da rede de reter informações completas sobre o alvo de previsão, o que pode levar a gradientes pouco confiáveis durante o treinamento e convergência ruim do modelo.

Para resolver o problema do gargalo de informações, os pesquisadores exploraram vários métodos, como arquiteturas reversíveis, modelagem mascarada e supervisão profunda. As arquiteturas reversíveis visam manter explicitamente as informações dos dados de entrada por meio do uso repetido de dados de entrada. A modelagem mascarada foca na maximização de características extraídas implicitamente para reter informações de entrada. A supervisão profunda envolve o estabelecimento prévio de um mapeamento de características rasas para alvos para garantir a transferência de informações importantes para camadas mais profundas. No entanto, esses métodos têm limitações e desvantagens, como custos de inferência aumentados, conflitos entre perda de reconstrução e perda de alvo, acumulação de erros e dificuldade na modelagem de informações semânticas de alta ordem.
Ao introduzir Informações de Gradiente Programáveis (PGI) em sua pesquisa, os autores do YOLOv9 fornecem uma solução inovadora para o problema do gargalo de informações. PGI gera gradientes confiáveis por meio de um ramo reversível auxiliar, permitindo que as características profundas mantenham características-chave necessárias para executar tarefas-alvo. Esta abordagem garante que informações importantes sejam preservadas e gradientes precisos sejam obtidos para atualizar eficazmente os pesos da rede, melhorando assim a convergência e os resultados de treinamento de redes neurais profundas.
O segundo problema resolvido pelos autores do YOLOv9 são as ineficiências relacionadas à utilização de parâmetros.
A Rede de Agregação de Camada Eficiente Generalizada (GELAN) introduzida pelos autores melhora a utilização de parâmetros e a eficiência computacional em redes neurais profundas, criando uma arquitetura leve que otimiza a utilização de parâmetros e recursos computacionais. Aqui estão algumas maneiras-chave pelas quais o GELAN alcança isso:
- Flexibilidade de Bloco Computacional: O GELAN permite o uso de diferentes blocos computacionais, como blocos Res, blocos Dark e blocos CSP. Ao realizar estudos de ablação sobre esses blocos computacionais, o GELAN demonstra a capacidade de manter um bom desempenho enquanto oferece aos usuários a flexibilidade de escolher e substituir blocos computacionais com base em seus requisitos específicos. Essa flexibilidade não apenas reduz o número de parâmetros, mas também melhora a eficiência computacional geral da rede.
- Eficiência de Parâmetros: O GELAN é projetado para alcançar melhor utilização de parâmetros em comparação com métodos de ponta baseados em convolução de profundidade. Ao utilizar operadores de convolução convencionais de forma eficaz, o GELAN maximiza a utilização de parâmetros enquanto mantém alto desempenho em tarefas de detecção de objetos. Este uso eficiente de parâmetros contribui para a eficácia geral e escalabilidade da rede.
- Sensibilidade à Profundidade: O desempenho do GELAN não é excessivamente sensível à profundidade da rede. Experimentos mostram que aumentar a profundidade do GELAN não leva a retornos decrescentes em termos de utilização de parâmetros e eficiência computacional. Esta característica permite que o GELAN mantenha um nível consistente de desempenho em diferentes profundidades, garantindo que a rede permaneça eficiente e eficaz independentemente de sua complexidade.
- Adaptabilidade ao Dispositivo de Inferência: A arquitetura do GELAN é projetada para ser adaptável a vários dispositivos de inferência, permitindo que os usuários escolham blocos computacionais adequados para seus requisitos de hardware específicos. Esta adaptabilidade garante que o GELAN possa ser implantado eficientemente em uma ampla gama de dispositivos sem comprometer o desempenho ou a eficiência computacional.
Ao combinar esses fatores, o GELAN melhora a utilização de parâmetros e a eficiência computacional em redes neurais profundas, tornando-o uma solução versátil e de alto desempenho para uma variedade de aplicações, incluindo tarefas de detecção de objetos em tempo real.
Comparação de Desempenho
O YOLOv9 demonstra desempenho superior em comparação com os detectores de objetos em tempo real do estado da arte anteriores em várias métricas. Aqui está um resumo da comparação com base nas informações fornecidas:
- Redução de Parâmetros: O YOLOv9 alcança uma redução significativa no número de parâmetros em comparação com detectores anteriores, como o YOLOv8. Esta redução de parâmetros contribui para uma eficiência computacional aprimorada e velocidades de inferência mais rápidas.
- Eficiência Computacional: O YOLOv9 também reduz a quantidade de computação necessária para tarefas de detecção de objetos, levando a uma eficiência aprimorada no processamento e análise de dados visuais.
- Melhoria de Precisão: Apesar da redução de parâmetros e computação, o YOLOv9 consegue melhorar a métrica de Precisão Média (AP) em uma margem notável no conjunto de dados MS COCO. Essa melhoria na precisão destaca a eficácia dos mecanismos PGI e GELAN propostos no aprimoramento do desempenho de detecção do modelo.
- Competitividade: O YOLOv9 demonstra forte competitividade quando comparado a outros detectores de objetos em tempo real treinados usando diferentes métodos, incluindo treinamento do zero, pré-treinamento por ImageNet, destilação de conhecimento e processos de treinamento complexos. O modelo supera esses métodos em termos de precisão, eficiência de parâmetros e velocidade computacional.
- Versatilidade: A combinação de PGI e GELAN no YOLOv9 permite a integração bem-sucedida de arquiteturas leves com modelos profundos, possibilitando uma ampla gama de aplicações em detecção de objetos em tempo real em vários dispositivos de inferência.
No geral, o YOLOv9 destaca-se como um sistema de detecção de objetos de alto desempenho que se destaca em precisão, eficiência e utilização de parâmetros, tornando-o uma escolha convincente para tarefas de visão computacional em tempo real.
| Modelo | APval (%) | AP50_val (%) | AP75_val (%) | Parâmetros (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Conclusão
O YOLOv9 demonstra os avanços significativos realizados na detecção de objetos em tempo real por meio da implementação e alavancagem de técnicas inovadoras como Rede de Agregação de Camada Eficiente Generalizada (GELAN) e Informações de Gradiente Programáveis (PGI). Ao abordar questões críticas como o problema do gargalo de informações e otimizar a utilização de parâmetros e eficiência computacional, o YOLOv9 emerge como um dos principais concorrentes no campo da detecção de objetos.
Análises comparativas demonstram que o YOLOv9 supera os métodos existentes em termos de precisão, eficiência de parâmetros e velocidade computacional. Sua capacidade de reduzir parâmetros enquanto melhora a Precisão Média (AP) em conjuntos de dados como MS COCO destaca a eficácia das melhorias propostas. Além disso, a adaptabilidade do YOLOv9 a diferentes dispositivos de inferência sublinha sua versatilidade e aplicabilidade em vários cenários de detecção de objetos em tempo real.
No geral, a pesquisa não apenas avança o estado da arte na detecção de objetos em tempo real, mas também estabelece um novo padrão de eficiência, desempenho e utilização de parâmetros em redes neurais profundas. O sucesso do YOLOv9 em superar desafios-chave e fornecer resultados superiores destaca seu potencial para impulsionar novas inovações em aplicações de visão computacional e aprendizado de máquina.
FAQ sobre YOLOv9
No campo em rápida evolução da visão computacional, o YOLOv9 se destaca como um avanço significativo, combinando eficiência com precisão inovadora. Conforme o interesse neste modelo avançado de detecção de objetos cresce, também crescem as perguntas sobre sua aplicação, desempenho e acessibilidade. Abaixo, abordamos as perguntas mais comuns para ajudar tanto os novatos quanto os profissionais experientes a terem uma imagem mais clara do que o YOLOv9 oferece e como ele pode transformar seus projetos baseados em visão.
O que é YOLOv9 e como ele difere das versões anteriores?
O YOLOv9 é a última iteração na série YOLO (You Only Look Once), conhecida por suas capacidades de detecção de objetos. Ele introduz uma nova arquitetura de rede leve, aprimorando a velocidade e precisão da detecção. Comparado ao seu predecessor, o YOLOv9 oferece uma média de precisão (AP) melhorada no conjunto de dados MS COCO, graças aos avanços em informações de gradiente programáveis e à integração da tecnologia transformer, tornando-o mais eficiente em aplicações do mundo real.
Como começar com o YOLOv9 para detecção de objetos?
Para começar com o YOLOv9, primeiro, instale as dependências necessárias, incluindo Python, PyTorch e CUDA para aceleração GPU. Baixe o código-fonte do YOLOv9 de seu repositório oficial. Treine o modelo com um conjunto de dados personalizado ou use pesos pré-treinados disponíveis online para detectar objetos. Executar o script de detecção em uma imagem ou vídeo resultará em detecção de objetos em tempo real, mostrando as capacidades do YOLOv9.
Quais são as principais melhorias no desempenho do YOLOv9?
O YOLOv9 introduz melhorias importantes no desempenho de detecção de objetos, especialmente um aumento na precisão média (AP) e uma redução no tempo de inferência. No conjunto de dados MS COCO, o YOLOv9 demonstra um impulso significativo na AP, atingindo até 55,6% para alguns modelos, ao lado de velocidades de detecção mais rápidas, tornando-o altamente adequado para aplicações em tempo real. Essas melhorias são atribuídas à sua nova arquitetura e técnicas de otimização.
O YOLOv9 pode ser integrado a dispositivos de computação de borda?
Sim, o YOLOv9 pode ser integrado a dispositivos de computação de borda, como NVIDIA Jetson, graças à sua arquitetura otimizada que suporta operação eficiente em hardware com recursos computacionais limitados. Essa compatibilidade permite que o YOLOv9 realize detecção de objetos em tempo real em cenários de borda, como câmeras de vigilância e veículos autônomos, onde o processamento rápido é crucial.
Quais são os desafios e soluções no treinamento do YOLOv9?
O treinamento do YOLOv9 apresenta desafios como diversidade de dados e requisitos de hardware. Um conjunto de dados diversificado é crucial para alcançar alta precisão, enquanto hardware poderoso acelera o processo de treinamento. As soluções incluem aumentar conjuntos de dados para diversidade e aproveitar recursos de computação em nuvem ou hardware especializado como GPUs para treinamento de modelo mais rápido. A afinação de modelos pré-treinados também pode reduzir significativamente o tempo de treinamento e o consumo de recursos.
Onde posso encontrar recursos e suporte da comunidade para o YOLOv9?
Os recursos e o suporte da comunidade para o YOLOv9 são abundantes. Os desenvolvedores podem encontrar documentação, modelos pré-treinados e exemplos de código no repositório oficial do GitHub do YOLOv9. Para suporte da comunidade, fóruns como Reddit e Stack Overflow hospedam discussões ativas, dicas e conselhos para solução de problemas. Essas plataformas fornecem uma riqueza de informações tanto para iniciantes quanto para especialistas que desejam aprimorar seus projetos YOLOv9.