
Qu’est-ce que la Détection d’Objets
La détection d’objets en vision par ordinateur fait référence à la tâche d’identifier et de localiser des objets dans une image ou une séquence vidéo. L’objectif est non seulement de classer les objets présents, mais aussi de fournir l’emplacement précis de chaque objet dans l’image. Cela implique généralement de dessiner des boîtes englobantes autour des objets détectés et de les étiqueter avec leurs étiquettes de classe correspondantes.
La détection d’objets est une tâche fondamentale dans de nombreuses applications de vision par ordinateur, notamment :
- Conduite autonome : Détection des piétons, des véhicules, des panneaux de signalisation et d’autres objets sur la route.
- Surveillance et sécurité : Identification des personnes, des véhicules et des activités suspectes dans les flux vidéo des caméras de surveillance.
- Imagerie médicale : Localisation et classification des anomalies dans les images médicales telles que les radiographies, les IRM ou les scanners CT.
- Commerce de détail : Comptage et suivi des produits sur les étagères des magasins ou détection des comportements de vol à l’étalage.
- Automatisation industrielle : Inspection des produits manufacturés pour détecter les défauts ou les anomalies sur les lignes de production.
- Réalité augmentée : Reconnaissance des objets dans l’environnement pour superposer des informations numériques.
- Robotique : Permettre aux robots de percevoir et d’interagir avec les objets dans leur environnement.
Les algorithmes de détection d’objets impliquent généralement plusieurs étapes :
- Extraction de caractéristiques : L’image d’entrée est analysée pour identifier les caractéristiques pertinentes à la détection d’objets. Cela pourrait impliquer des techniques telles que les réseaux neuronaux convolutionnels (CNN) pour extraire des représentations hiérarchiques de l’image.
- Localisation : Cette étape consiste à prédire l’emplacement des objets dans l’image. Cela se fait souvent en régressant les coordonnées des boîtes englobantes par rapport au cadre de l’image.
- Classification : Chaque objet détecté se voit attribuer une étiquette de classe (par exemple, personne, voiture, chien) en fonction de ses caractéristiques visuelles. Cela se fait généralement à l’aide d’un modèle de classification, souvent aux côtés du modèle de localisation.
- Post-traitement : Enfin, les résultats de la détection peuvent subir des étapes de post-traitement telles que la suppression des non-maximaux (NMS) pour affiner les boîtes englobantes et éliminer les détections en double.
Typiquement, les étapes de l’extraction des caractéristiques au post-traitement sont toutes gérées par un Réseau de Neurones Convolutifs Profonds.
Approches Populaires pour la Détection d’Objets
Les approches populaires pour la détection d’objets comprennent :
- Les détecteurs à deux étapes : Ces méthodes proposent d’abord des régions d’intérêt (RoIs) en utilisant des techniques telles que la recherche sélective ou les réseaux de proposition de région (RPN), puis classifient et affinent ces propositions. Les exemples incluent Faster R-CNN, R-FCN et Mask R-CNN.
- Les détecteurs à une étape : Ces méthodes prédisent directement les boîtes englobantes des objets et les probabilités de classe en un seul passage à travers le réseau, sans étape de proposition séparée. Les exemples incluent YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) et RetinaNet.
Bien que les détecteurs à deux étapes offrent une précision supérieure, ils sont souvent plus coûteux en termes de calcul et ne peuvent pas être utilisés pour de nombreuses applications en temps réel. Les détecteurs à une étape sacrifient une certaine précision pour la vitesse. Comme c’est généralement le cas avec les réseaux neuronaux, il est nécessaire de définir des priorités entre la vitesse et la précision lors du choix d’un modèle à utiliser.
La détection d’objets a connu des avancées significatives ces dernières années, grâce aux améliorations des techniques d’apprentissage profond, des tailles de jeux de données et des ressources de calcul.
Qu’est-ce que YOLO
YOLO (You Only Look Once) est une famille de modèles de détection d’objets en temps réel qui sont très efficaces et capables de détecter des objets dans des images ou des séquences vidéo avec une vitesse remarquable. La caractéristique clé des modèles YOLO est leur capacité à effectuer la détection d’objets en un seul passage à travers le réseau neuronal, d’où le nom « You Only Look Once ».
Il y a eu plusieurs itérations et versions des modèles YOLO, chacune avec des améliorations par rapport aux versions précédentes. Cependant, l’architecture et les principes généraux restent cohérents à travers les différentes versions. Voici un aperçu général du fonctionnement des modèles YOLO :
- Approche basée sur la grille : YOLO divise l’image d’entrée en une grille de cellules. Chaque cellule est responsable de prédire des boîtes englobantes et des probabilités de classe pour les objets dont les centres se trouvent dans cette cellule.
- Prédiction : Pour chaque cellule de la grille, YOLO prédit des boîtes englobantes (généralement 2 ou plus par cellule) ainsi que des scores de confiance représentant la probabilité que la boîte englobante contienne un objet et des probabilités de classe pour chaque classe.
- Prédiction en un seul passage : YOLO traite l’ensemble de l’image à travers un réseau neuronal convolutionnel (CNN) en un seul passage vers l’avant pour effectuer ces prédictions. Cela contraste avec certaines autres méthodes de détection d’objets qui nécessitent plusieurs passages ou propositions de régions.
- Format de sortie : La sortie d’un modèle YOLO est un ensemble de boîtes englobantes, de scores de confiance et de probabilités de classe. Ces boîtes englobantes sont directement prédites par le réseau et ne dépendent d’aucune étape de post-traitement comme la suppression des non-maximaux (NMS) pour les affiner.
- Fonction de perte : YOLO utilise une combinaison de perte de localisation (mesurant la précision des prédictions de boîtes englobantes) et de perte de classification (mesurant la précision des prédictions de classe) pour entraîner le modèle. La fonction de perte est conçue pour pénaliser les prédictions inexactes tout en encourageant simultanément le modèle à faire des prédictions confiantes pour les objets.
Introduction à YOLOv9
YOLOv9, la dernière itération de la populaire série You Only Look Once (YOLO), représente une avancée de pointe dans les systèmes de détection d’objets en temps réel. S’appuyant sur le succès de ses prédécesseurs, YOLOv9 introduit des concepts innovants tels que l’Information de Gradient Programmable (PGI) et le Réseau d’Aggrégation de Couches Efficace Généralisé (GELAN) pour améliorer l’efficacité et la précision des tâches de détection d’objets. En incorporant PGI, YOLOv9 aborde le défi de la perte de données dans les réseaux profonds en garantissant la préservation des caractéristiques clés et la génération fiable de gradients pour des résultats d’entraînement optimaux. De plus, l’intégration de GELAN offre une architecture réseau légère qui optimise l’utilisation des paramètres et l’efficacité de calcul, faisant de YOLOv9 une solution polyvalente et performante pour une large gamme d’applications.

Avec un accent sur la détection d’objets en temps réel, YOLOv9 s’appuie sur des méthodologies de pointe telles que CSPNet, ELAN et des techniques améliorées d’intégration de caractéristiques pour offrir des performances supérieures dans diverses tâches de vision par ordinateur. En introduisant la puissance de PGI pour la programmation des informations de gradient et GELAN pour l’agrégation efficace des couches, YOLOv9 établit une nouvelle norme pour les systèmes de détection d’objets, surpassant les détecteurs en temps réel existants en termes d’exactitude, de vitesse et d’utilisation des paramètres. Ce modèle YOLO de nouvelle génération promet de révolutionner le domaine de la vision par ordinateur avec ses capacités avancées et ses performances exceptionnelles sur des ensembles de données comme MS COCO, s’affirmant comme un concurrent de premier plan dans le domaine de la détection d’objets en temps réel.
Les Problèmes Résolus par YOLOv9
YOLOv9 a atteint des performances supérieures grâce à la résolution de plusieurs problèmes qui apparaissent lors de l’entraînement des réseaux neuronaux profonds.
Le problème de l’entonnoir d’information dans les réseaux neuronaux profonds fait référence au phénomène où les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, entraînant une perte d’informations importantes. Au fur et à mesure que les données circulent à travers les couches successives d’un réseau profond, les données d’origine peuvent progressivement perdre leurs caractéristiques distinctes et leurs détails essentiels, entraînant un entonnoir d’information. Cet entonnoir limite la capacité du réseau à conserver des informations complètes sur la cible de prédiction, ce qui peut conduire à des gradients peu fiables pendant l’entraînement et à une mauvaise convergence du modèle.
Pour résoudre le problème de l’entonnoir d’information, les chercheurs ont exploré diverses méthodes telles que les architectures réversibles, la modélisation masquée et la supervision profonde. Les architectures réversibles visent à maintenir explicitement les informations des données d’entrée par une utilisation répétée des données d’entrée. La modélisation masquée vise à maximiser implicitement l’extraction de caractéristiques pour conserver les informations d’entrée. La supervision profonde implique d’établir préalablement une correspondance entre les caractéristiques peu profondes et les cibles pour garantir le transfert d’informations importantes vers les couches plus profondes. Cependant, ces méthodes présentent des limites et des inconvénients, tels que des coûts d’inférence accrus, des conflits entre la perte de reconstruction et la perte de cible, une accumulation d’erreurs et des difficultés dans la modélisation des informations sémantiques de haut niveau.
En introduisant l’Information de Gradient Programmable (PGI) dans leur recherche, les auteurs de YOLOv9 fournissent une nouvelle solution au problème de l’entonnoir d’information. PGI génère des gradients fiables via une branche réversible auxiliaire, permettant aux caractéristiques profondes de conserver les caractéristiques clés nécessaires à l’exécution des tâches cibles. Cette approche garantit que les informations importantes sont préservées et que des gradients précis sont obtenus pour la mise à jour efficace des poids du réseau, améliorant ainsi la convergence et les résultats d’entraînement des réseaux neuronaux profonds.
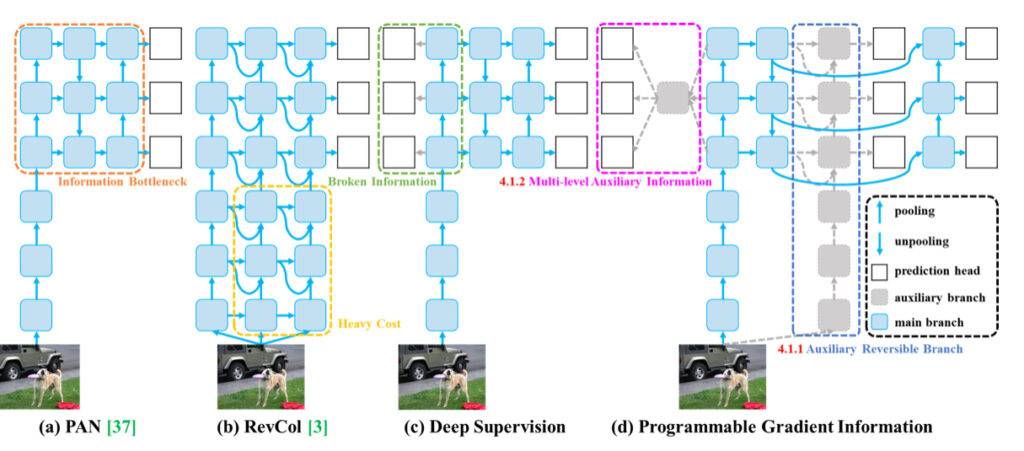
Le deuxième problème résolu par les auteurs de YOLOv9 concerne les inefficacités liées à l’utilisation des paramètres. Le Réseau d’Aggrégation de Couches Efficace Généralisé (GELAN) introduit par les auteurs améliore l’utilisation des paramètres et l’efficacité de calcul dans les réseaux neuronaux profonds en créant une nouvelle architecture réseau légère qui optimise l’utilisation des paramètres et des ressources de calcul. Voici quelques façons clés dont GELAN y parvient :
- Flexibilité des Blocs de Calcul : GELAN permet l’utilisation de différents blocs de calcul tels que les blocs Res, Dark et CSP. En menant des études d’ablation sur ces blocs de calcul, GELAN démontre la capacité à maintenir de bonnes performances tout en offrant aux utilisateurs la flexibilité de choisir et de remplacer les blocs de calcul en fonction de leurs besoins spécifiques. Cette flexibilité permet non seulement de réduire le nombre de paramètres, mais aussi d’améliorer l’efficacité de calcul globale du réseau.
- Efficacité des Paramètres : GELAN est conçu pour atteindre une meilleure utilisation des paramètres par rapport aux méthodes de pointe basées sur la convolution par profondeur. En utilisant efficacement les opérateurs de convolution conventionnels, GELAN maximise l’utilisation des paramètres tout en maintenant de bonnes performances dans les tâches de détection d’objets. Cette utilisation efficace des paramètres contribue à l’efficacité et à l’évolutivité globales du réseau.
- Sensibilité à la Profondeur : La performance de GELAN n’est pas excessivement sensible à la profondeur du réseau. Les expériences montrent que l’augmentation de la profondeur de GELAN n’entraîne pas de rendements décroissants en termes d’utilisation des paramètres et d’efficacité de calcul. Cette caractéristique permet à GELAN de maintenir un niveau de performance cohérent quelle que soit sa complexité, garantissant que le réseau reste efficace et performant quel que soit son niveau de complexité.
- Adaptabilité aux Dispositifs d’Inférence : L’architecture de GELAN est conçue pour être adaptable à divers dispositifs d’inférence, permettant aux utilisateurs de choisir des blocs de calcul adaptés à leurs exigences matérielles spécifiques. Cette adaptabilité garantit que GELAN peut être déployé efficacement sur une large gamme de dispositifs sans compromettre les performances ou l’efficacité de calcul.
En combinant ces facteurs, GELAN améliore l’utilisation des paramètres et l’efficacité de calcul dans les réseaux neuronaux profonds, en en faisant une solution polyvalente et performante pour une variété d’applications, y compris les tâches de détection d’objets en temps réel.
Dans la vidéo suivante comparant YOLOv8 et YOLOv9, vous pouvez également clairement voir les avancées dans la détection des objets plus petits par rapport à YOLOv8.
Comparaison des Performances
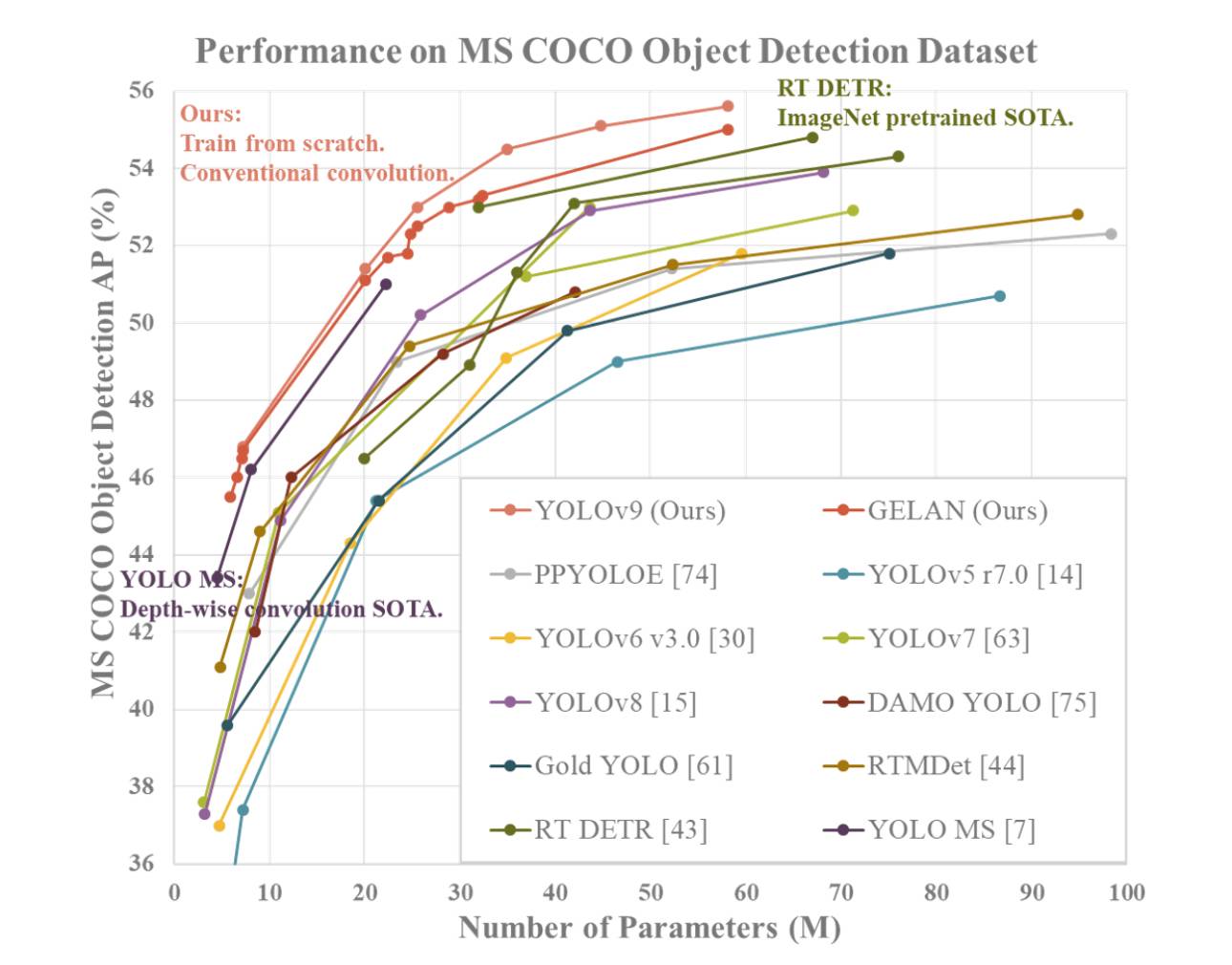
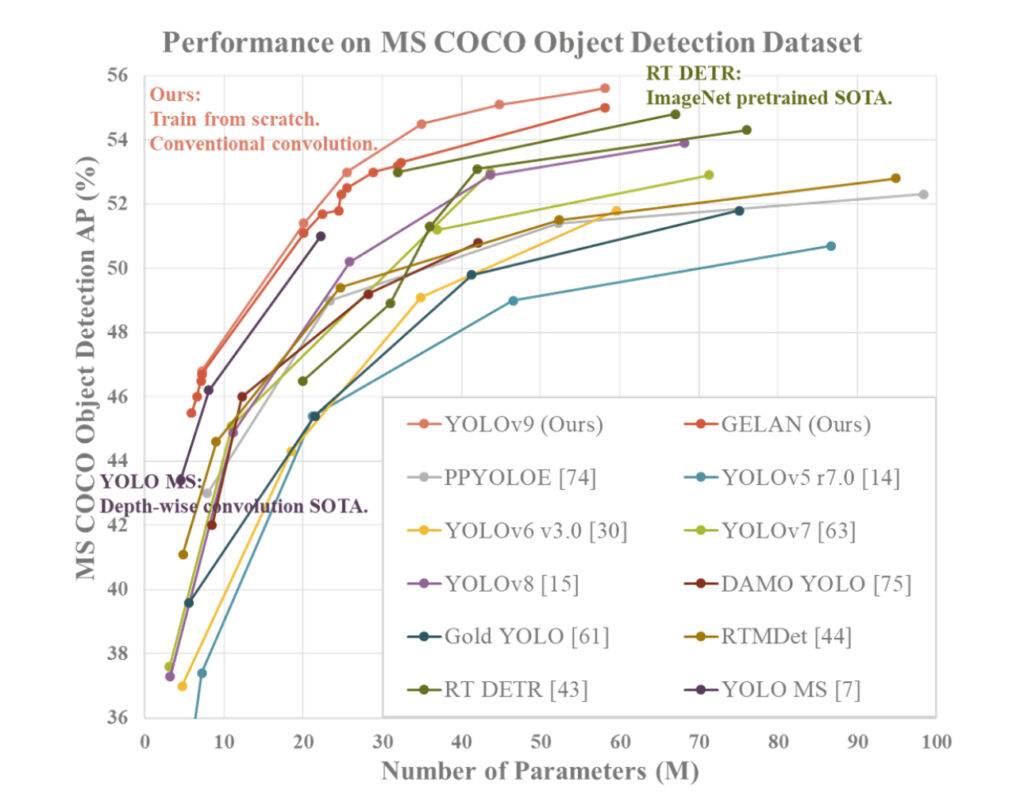
YOLOv9 démontre des performances supérieures par rapport aux détecteurs d’objets en temps réel précédents de pointe sur diverses mesures. Voici un résumé de la comparaison basée sur les informations fournies :
- Réduction des Paramètres : YOLOv9 réalise une réduction significative du nombre de paramètres par rapport aux détecteurs précédents, tels que YOLOv8. Cette réduction des paramètres contribue à une efficacité de calcul améliorée et à des vitesses d’inférence plus rapides.
- Efficacité de Calcul : YOLOv9 réduit également la quantité de calcul nécessaire pour les tâches de détection d’objets, ce qui conduit à une efficacité accrue dans le traitement et l’analyse des données visuelles.
- Amélioration de l’Exactitude : Malgré la réduction des paramètres et du calcul, YOLOv9 parvient à améliorer la métrique de Précision Moyenne (AP) de manière notable sur l’ensemble de données MS COCO. Cette amélioration de l’exactitude met en évidence l’efficacité des mécanismes PGI et GELAN proposés pour améliorer les performances de détection du modèle.
- Compétitivité : YOLOv9 démontre une forte compétitivité par rapport à d’autres détecteurs d’objets en temps réel formés à l’aide de différentes méthodes, notamment l’entraînement à partir de zéro, pré-entraîné par ImageNet, la distillation de connaissances et des processus d’entraînement complexes. Le modèle surpasse ces méthodes en termes d’exactitude, d’efficacité des paramètres et de vitesse de calcul.
- Polyvalence : La combinaison de PGI et de GELAN dans YOLOv9 permet l’intégration réussie d’architectures légères avec des modèles profonds, permettant une large gamme d’applications dans la détection d’objets en temps réel sur différents dispositifs d’inférence.
Dans l’ensemble, YOLOv9 se distingue comme un système de détection d’objets performant qui excelle en termes d’exactitude, d’efficacité et d’utilisation des paramètres, ce qui en fait un choix convaincant pour les tâches de vision par ordinateur en temps réel.
| Modèle | APval (%) | AP50_val (%) | AP75_val (%) | Paramètres (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Performances de YOLOv9
YOLOv9 met en avant les avancées significatives réalisées dans la détection d’objets en temps réel grâce à la mise en œuvre et à l’utilisation de techniques innovantes telles que le Réseau d’Aggrégation de Couches Efficace Généralisé (GELAN) et l’Information de Gradient Programmable (PGI). En abordant des problèmes critiques tels que le problème de l’entonnoir d’information et en optimisant l’utilisation des paramètres et l’efficacité de calcul, YOLOv9 émerge comme un concurrent de premier plan dans le domaine de la détection d’objets.
L’analyse comparative démontre que YOLOv9 surpasse les méthodes existantes en termes d’exactitude, d’efficacité des paramètres et de vitesse de calcul. Sa capacité à réduire les paramètres tout en améliorant la Précision Moyenne (AP) sur des ensembles de données comme MS COCO met en évidence l’efficacité des améliorations architecturales introduites dans le modèle.
En combinant des performances supérieures avec une architecture légère et polyvalente, YOLOv9 offre une solution complète pour les tâches de détection d’objets en temps réel, répondant aux exigences de précision, de vitesse et d’efficacité pour une variété d’applications dans le domaine de la vision par ordinateur.
FAQ sur YOLOv9
Qu’est-ce que YOLOv9 et en quoi diffère-t-il des versions précédentes ?
YOLOv9 est la dernière itération de la série YOLO (You Only Look Once), réputée pour ses capacités de détection d’objets. Il introduit une nouvelle architecture réseau légère, améliorant la vitesse et la précision de la détection. Comparé à son prédécesseur, YOLOv9 offre une précision moyenne (AP) améliorée sur l’ensemble de données MS COCO, grâce aux progrès réalisés dans l’information de gradient programmable et l’intégration de la technologie des transformateurs, le rendant plus efficace dans les applications réelles.
Comment commencer avec YOLOv9 pour la détection d’objets ?
Pour commencer avec YOLOv9, installez d’abord les dépendances requises, notamment Python, PyTorch et CUDA pour l’accélération GPU. Téléchargez le code source de YOLOv9 depuis son référentiel officiel. Entraînez le modèle avec un jeu de données personnalisé ou utilisez des poids pré-entraînés disponibles en ligne pour détecter les objets. Exécutez le script de détection sur une image ou une vidéo pour obtenir une détection d’objets en temps réel, démontrant les capacités de YOLOv9.
Quelles sont les améliorations clés dans les performances de YOLOv9 ?
YOLOv9 introduit des améliorations clés dans les performances de détection d’objets, notamment une augmentation de la précision moyenne (AP) et une réduction du temps d’inférence. Sur l’ensemble de données MS COCO, YOLOv9 démontre une augmentation significative de l’AP, atteignant jusqu’à 55,6 % pour certains modèles, ainsi que des vitesses de détection plus rapides, le rendant très adapté aux applications en temps réel. Ces améliorations sont attribuées à sa nouvelle architecture et à ses techniques d’optimisation.
YOLOv9 peut-il être intégré avec des appareils de calcul à la périphérie ?
Oui, YOLOv9 peut être intégré avec des appareils de calcul à la périphérie tels que NVIDIA Jetson, grâce à son architecture optimisée qui prend en charge un fonctionnement efficace sur du matériel avec des ressources de calcul limitées. Cette compatibilité permet à YOLOv9 d’effectuer une détection d’objets en temps réel dans des scénarios périphériques, tels que les caméras de surveillance et les véhicules autonomes, où le traitement rapide est essentiel.
Quels sont les défis et les solutions dans la formation de YOLOv9 ?
La formation de YOLOv9 pose des défis tels que la diversité des données et les exigences matérielles. Un jeu de données diversifié est crucial pour atteindre une grande précision, tandis qu’un matériel puissant accélère le processus de formation. Les solutions incluent l’augmentation des ensembles de données pour la diversité et l’utilisation de ressources de calcul en nuage ou de matériel spécialisé comme les GPU pour une formation de modèle plus rapide. L’affinage des modèles pré-entraînés peut également réduire considérablement le temps de formation et la consommation de ressources.
Où puis-je trouver des ressources et un soutien communautaire pour YOLOv9 ?
Les ressources et le soutien communautaire pour YOLOv9 sont abondants. Les développeurs peuvent trouver de la documentation, des modèles pré-entraînés et des exemples de code dans le référentiel GitHub officiel de YOLOv9. Pour obtenir un soutien communautaire, des forums tels que Reddit et Stack Overflow hébergent des discussions actives, des conseils et des conseils de dépannage. Ces plateformes fournissent une mine d’informations pour les débutants et les experts souhaitant améliorer leurs projets YOLOv9.