
Hyperparameter Optimization for YOLOv8 with Weights & Biases: An Adventure with object detection algorithms
Introduction
When working with object detection tasks, getting your model to perform optimally is crucial. This involves selecting the right hyperparameters. In this blog post, we’ll walk through my journey of hyperparameter optimization for the YOLOv8 object detection model using Weights & Biases (W&B) and the Bayesian Optimization method.
By Justas Andriuškevičius– Machine Learning Engineer at visionplatform.ai
Why Hyperparameter Optimization?
Every machine learning model comes with its set of dials and knobs — hyperparameters. Selecting the right combination can make the difference between an average model and a top-performing one. But, with countless possible combinations, how do you choose? That’s where hyperparameter optimization, and specifically W&B, comes into play.
Dataset Selection
Before we deep dive into the hyperparameters, let’s discuss dataset selection. Hyperparameter optimization is a resource-intensive task. Conducting it on a full dataset would take an incredibly long time — and let’s be real; no one has time for that, especially when dealing with voluminous datasets.
To strike a balance between computational efficiency and a representative dataset, I adopted a clever approach. Given a large dataset with images in timestamp order, I curated a subset by sorting them by timestamp, which is only 1/4 of the original set. This method ensures that the model trains on diverse data, encapsulating both day and night scenes, vital for an object detection task. All the while, this method significantly reduces the computational time compared to using the full set. For evaluation, I stuck with the original validation set, since it provides a more comprehensive and unbiased evaluation of the model’s performance on unseen data, and it is already just a fraction of a original train set size.
The YOLOv8 Model and Its Hyperparameters
The YOLOv8 (You Only Look Once) model is a favourite in object detection tasks because of its efficiency. Several hyperparameters influence its performance:
- Batch size (batch): It determines the number of samples processed before the model updates its weights.
- Image size (imgsz): It affects the resolution of images fed into the model.
- Learning rate (lr0): It controls how much to adjust the model in response to the estimated error each time the model weights are updated.
- Optimizer: It influences how the model updates its weights.
- Augmentation (augment): It denotes whether to introduce random changes to the input data, increasing the model’s robustness.
- Dropout (dropout): It’s a regularization technique to prevent overfitting.
Why Bayesian Optimization?
Choosing the right hyperparameters can feel like looking for a needle in a haystack. Bayesian optimization makes this search smarter. Imagine you’re trying to get the highest score on a game. Instead of randomly trying out every possible move (which could take forever!), Bayesian optimization looks at your past moves, learns from them, and smartly suggests the next best move. It balances between trying proven moves (exploitation) and experimenting with new ones (exploration).
Why Maximize mAP50?
mAP50 stands for Mean Average Precision at an IoU of 0.5. In simple terms, it evaluates how well our model’s predicted bounding boxes overlap with the ground truth boxes. Maximizing mAP50 means our model is not just detecting objects but accurately pinpointing their locations. Because the goal is to detect vehicle types during day, night, and severe weather conditions, ensuring high mAP50 becomes even more critical. It’s not just about detecting vehicles, but ensuring they’re accurately recognized in varied and challenging scenarios. Now why I choose to maximize mAP50 over mAP50–95? When training our model first time with default hyperparameters, I observed that mAP50 reached its optimal value around the 30-epoch mark, whereas mAP50–95 took longer, stabilizing only around 50 epochs. Notably, a high mAP50 was often indicative of a similarly high mAP50–95. Given this behaviour, for hyperparameter optimization purposes, I chose to focus on maximizing mAP50. This approach allows us to shorten each evaluation run, enabling a more efficient exploration of diverse parameter combinations.
Using W&B for Hyperparameter Optimization
W&B’s sweep functionality streamlines the optimization process. I set up the sweep using the Bayesian method to search for the best hyperparameters. Interestingly, I chose 30 epochs for training because, in my initial tests with the full dataset, the model started showing signs of optimal performance around this mark.
Results and Insights
Diving into the results of hyperparameter optimization reveals important insights:
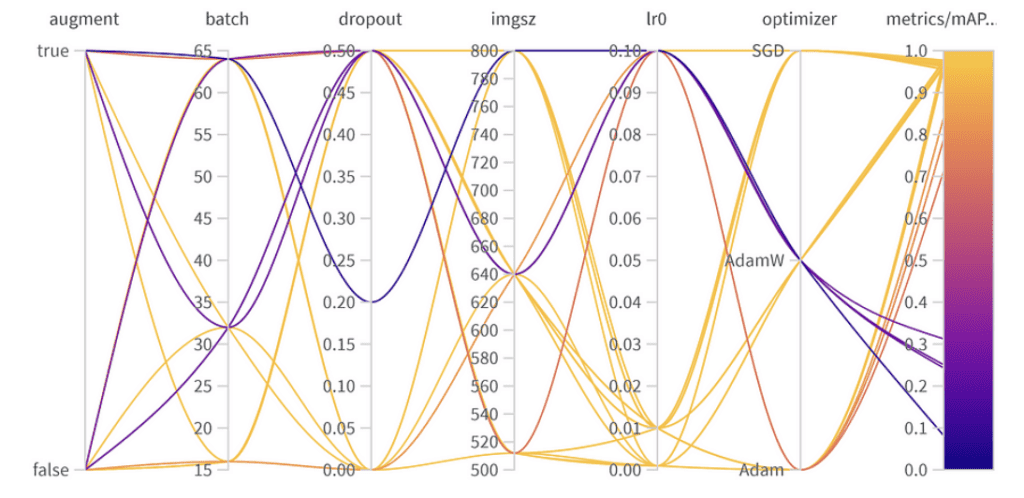
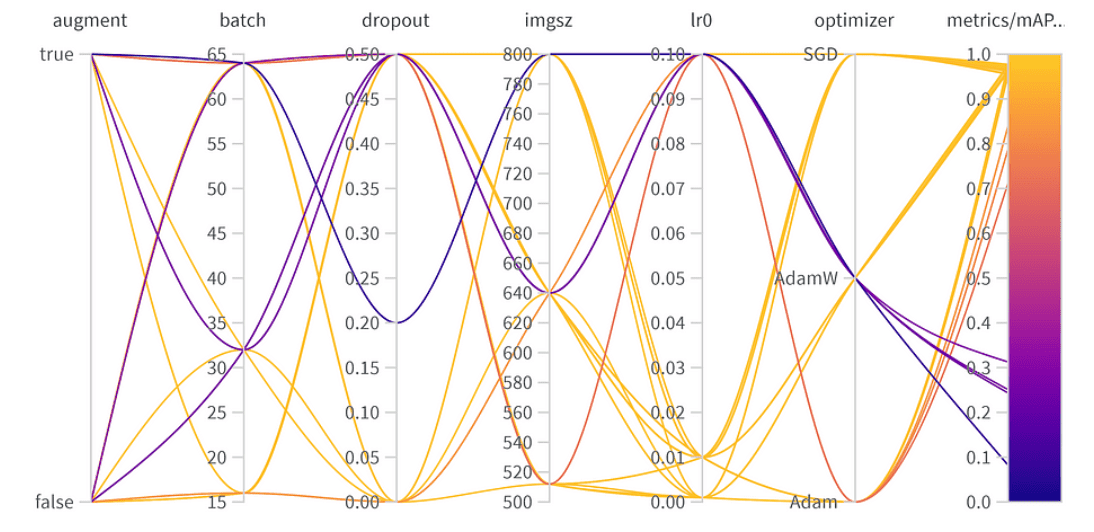
Hyperparameter optimization results
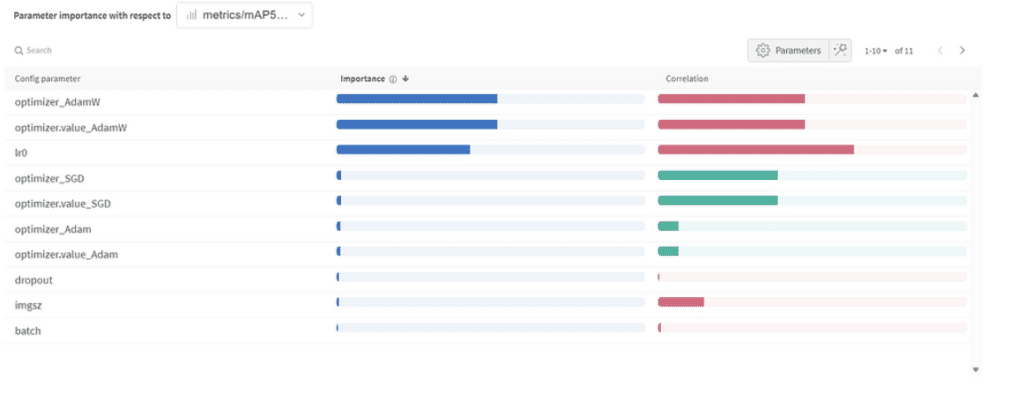
Hyperparameter importance and correlation
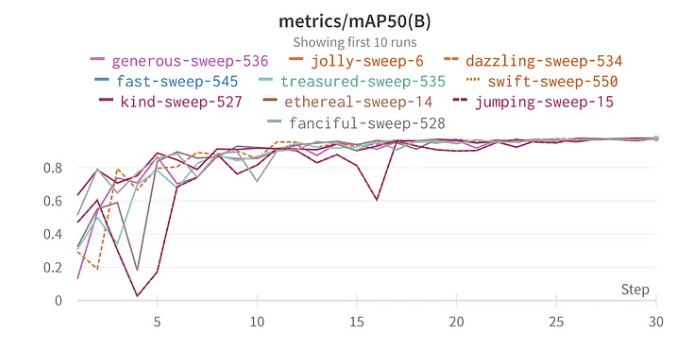
top 10 mAP50 results
Parameter Importance:
- Optimizer (AdamW): With an importance of 0.521 and a negative correlation, it suggests AdamW can significantly impact performance, but not always positively.
- Learning Rate (lr0): High importance (0.433) and a negative correlation (-0.634) hint that a smaller learning rate might be better for our task.
- Others: Optimizers like SGD & Adam, and parameters like dropout, image size, and batch size show minimal importance, indicating their lesser influence on our model’s performance.
Final Hyperparameters:
The best hyperparameter combination is as follows with the best mAP50 of 0.9776 on the validation set:
- Augmentation: The best model skipped data augmentation, indicating enough data diversity.
- Batch Size: Chose 64, balancing computational efficiency and model performance.
- Dropout: A rate of 0, suggesting the model didn’t need this regularization.
- Image Size: 640 is the sweet spot for our task.
- Learning Rate: Opted for 0.001, aligning with our earlier observation about lower rates being beneficial.
- Optimizer: Interestingly, even though AdamW seemed important, Adam was chosen in the best combo. It’s a reminder that hyperparameters often have interconnected effects.
Striking a Balance: Top Performance vs. Generalizability
While the best mAP50 achieved on our validation set was 0.9776, there was another configuration with a close mAP50 of 0.9761. This “runner-up” model differs notably in that it employed data augmentation and used a dropout rate of 0.5. Considering the slight drop in mAP50 (a mere 0.0015), it might be beneficial to favour this model in deployment scenarios, especially if we anticipate a wide range of situations the model will encounter. The minimal compromise in immediate performance might be outweighed by the model’s enhanced ability to generalize.
Conclusion
Hyperparameter optimization can significantly boost the performance of your model. With tools like W&B and methods like Bayesian optimization, this process becomes systematic and insightful. While some parameters like optimizer and learning rate are crucial, others have a minor impact. It emphasizes the need for task-specific tuning rather than general deep learning best practices. When deploying a model, it’s essential to weigh the trade-offs between peak validation performance and robustness in varied real-world situations. In some cases, a model with slightly lower validation accuracy but better generalizability due to regularization might be the better choice. Experimentation, backed by data, is key!