
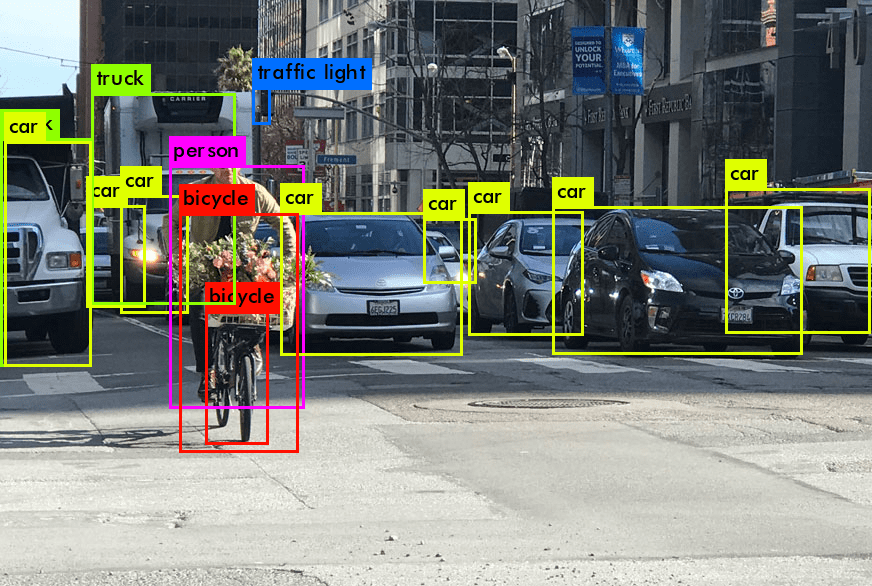
Introduzione alla Visone Artificiale (computer vision) e al Modello YOLO
La visone artificale (computer vision), un campo dell’intelligenza artificiale, mira a fornire alle macchine la capacità di interpretare e comprendere il mondo visivo. Coinvolge la cattura, l’elaborazione e l’analisi di immagini o video per automatizzare compiti che il sistema visivo umano può fare. Questo campo in rapida evoluzione comprende varie applicazioni, dal riconoscimento facciale e il tracciamento degli oggetti a attività più avanzate come la guida autonoma. Lo sviluppo della visone artificale (computer vision) si basa fortemente su grandi dataset, algoritmi sofisticati e potenti risorse computazionali.
Una svolta in questo campo è avvenuta con lo sviluppo del modello YOLO (You Only Look Once). Progettato come un modello di rilevamento oggetti all’avanguardia, YOLO ha rivoluzionato l’approccio al rilevamento degli oggetti nelle immagini. I modelli di rilevamento tradizionali spesso comportavano un processo in due fasi: prima identificare le regioni di interesse e poi classificare quelle regioni. Al contrario, YOLO ha innovato prevedendo sia le classificazioni che i riquadri di delimitazione in un unico passaggio attraverso la rete neurale, accelerando notevolmente il processo e migliorando le capacità di rilevamento in tempo reale.
Questo modello di rilevamento oggetti ha subito diverse iterazioni, con ogni versione che introduce nuove funzionalità e miglioramenti. YOLOv8, l’ultima versione di Ultralytics, si basa sul successo dei suoi predecessori come YOLOv5. Incorpora tecniche avanzate di apprendimento automatico per migliorare l’accuratezza e la velocità, rendendolo una scelta popolare per le attività di visone artificale (computer vision). La natura open-source dei modelli YOLO, come il repository YOLOv8 su GitHub, ha ulteriormente contribuito alla loro diffusa adozione e sviluppo continuo.
L’efficacia di YOLO nel rilevamento degli oggetti, nella segmentazione delle istanze e nei compiti di classificazione ha reso questo modello un pilastro nei progetti di visone artificale (computer vision). Semplificando il processo di identificazione e categorizzazione degli oggetti all’interno delle immagini, i modelli YOLO come YOLOv8 aiutano le macchine a comprendere il mondo visivo in modo più accurato ed efficiente.
YOLOv8: Il nuovo stato dell’arte nella visone artificale (computer vision)
YOLOv8 rappresenta il culmine del progresso nel campo della visone artificale (computer vision), stabilendosi come il nuovo stato dell’arte nei modelli di rilevamento degli oggetti. Sviluppato da Ultralytics, questa versione della serie di modelli YOLO introduce significativi avanzamenti rispetto al suo predecessore, YOLOv5, e alle versioni precedenti di YOLO. YOLOv8 è dotato di una serie di nuove funzionalità che migliorano le sue capacità di rilevamento, rendendolo più accurato ed efficiente che mai.
Uno degli avanzamenti notevoli di YOLOv8 è l’adozione della rilevazione senza ancoraggi. Questo nuovo approccio si discosta dalla tradizionale dipendenza dalle scatole di ancoraggio, che erano un elemento fondamentale nei modelli YOLO precedenti. La rilevazione senza ancoraggi semplifica l’architettura del modello e migliora la sua capacità di prevedere con maggiore precisione le posizioni degli oggetti. Questo miglioramento è particolarmente vantaggioso in scenari in cui il dataset include oggetti di forme e dimensioni variabili.
Il modello YOLOv8 eccelle anche nei compiti di segmentazione, un aspetto critico della visone artificale (computer vision). Che si tratti di rilevamento di oggetti, segmentazione di istanze o modelli di segmentazione più generali, YOLOv8, in particolare il modello YOLOv8 Nano, dimostra una notevole competenza. La sua capacità di segmentare e classificare con precisione diverse parti di un’immagine lo rende estremamente efficace in applicazioni diverse, dalla diagnostica medica alla navigazione di veicoli autonomi.
Un altro aspetto chiave di YOLOv8 è il suo pacchetto Python, che facilita l’integrazione e l’uso in progetti basati su Python. Questa accessibilità è cruciale, soprattutto considerando la popolarità di Python nelle comunità di data science e machine learning. Gli sviluppatori possono addestrare un modello YOLOv8 su un dataset personalizzato utilizzando PyTorch, un framework di deep learning di primo piano. Questa flessibilità consente soluzioni su misura per specifiche sfide della visone artificale (computer vision).
Le prestazioni di YOLOv8 sono ulteriormente potenziate dalle sue metriche di prestazione del modello all’avanguardia. Queste metriche evidenziano la capacità del modello di rilevare oggetti con alta precisione e velocità, fattori cruciali nelle applicazioni in tempo reale. Inoltre, essendo un modello open source disponibile su GitHub, YOLOv8 beneficia di continui miglioramenti e contributi dalla comunità globale di sviluppatori.
In conclusione, YOLOv8 stabilisce un nuovo punto di riferimento nel campo della visone artificale (computer vision). I suoi avanzamenti nel rilevamento degli oggetti, nella segmentazione e nelle prestazioni generali del modello lo rendono uno strumento inestimabile per sviluppatori e ricercatori che cercano di spingere i confini di ciò che è possibile nell’interpretazione visiva guidata dall’IA.
Architettura YOLOv8: La Colonna Vertebrale dei Nuovi Progressi in Visone Artificale (computer vision)
L’architettura YOLOv8 rappresenta un significativo salto in avanti nel campo della visone artificale (computer vision), stabilendo un nuovo standard all’avanguardia. Come ultima versione di YOLO, YOLOv8 introduce diverse migliorie rispetto ai suoi predecessori, come YOLOv5 e le versioni precedenti di YOLO. Comprendere l’architettura YOLOv8 è fondamentale per coloro che cercano di addestrare il modello per compiti specializzati di rilevamento degli oggetti.
Una delle caratteristiche fondamentali di YOLOv8 è la sua testa di rilevamento senza ancoraggi, una deviazione dall’approccio tradizionale delle scatole di ancoraggio utilizzato nelle versioni precedenti di YOLO. Questo cambiamento semplifica il modello mantenendo, e in molti casi migliorando, l’accuratezza nel rilevamento degli oggetti. YOLOv8 supporta una vasta gamma di applicazioni, dalla rilevazione di oggetti in tempo reale alla segmentazione delle immagini.
Il modello YOLOv8 è progettato per l’efficienza e la performance. Il modello YOLOv8 open source può essere addestrato su vari dataset, inclusi il diffuso dataset COCO. Questa flessibilità permette agli utenti di personalizzare il modello per esigenze specifiche, sia per la rilevazione di oggetti generale che per compiti specializzati come la stima della posa.
L’architettura di YOLOv8 è ottimizzata sia per la velocità che per l’accuratezza, un fattore cruciale nelle applicazioni in tempo reale. Il design del modello include anche miglioramenti nella segmentazione delle immagini, rendendolo un modello completo di rilevamento e segmentazione delle immagini. La serie Ultralytics YOLO, in particolare YOLOv8, è sempre stata all’avanguardia nell’avanzamento dei modelli di visone artificale (computer vision), e YOLOv8 continua questa tradizione.
Per coloro che desiderano iniziare con YOLOv8, il repository di Ultralytics offre ampie risorse. Il repository, disponibile su GitHub, offre istruzioni dettagliate su come addestrare il modello YOLOv8, inclusa la configurazione dell’ambiente di addestramento e il caricamento dei pesi del modello.
Modello di rilevamento oggetti YOLOv8: Rivoluzionare il rilevamento e la segmentazione
Il modello di rilevamento oggetti YOLOv8 è l’ultima aggiunta alla serie YOLO, creato da Joseph Redmon e Ali Farhadi. Si pone all’avanguardia nel campo degli avanzamenti della visone artificale (computer vision), incarnando il nuovo stato dell’arte sia nel rilevamento degli oggetti che nella segmentazione delle immagini. Le capacità di YOLOv8 vanno oltre il semplice rilevamento di oggetti; eccelle anche in compiti come la segmentazione di istanze e il rilevamento in tempo reale, rendendolo uno strumento versatile per una varietà di applicazioni.
YOLOv8 utilizza un approccio innovativo al rilevamento, integrando caratteristiche che lo rendono un rilevatore di oggetti molto accurato. Il modello incorpora una testa di rilevamento senza ancoraggi, che semplifica il processo di rilevamento e aumenta l’accuratezza. Questo rappresenta un cambiamento significativo rispetto al metodo delle scatole di ancoraggio utilizzato nelle versioni precedenti di YOLO.
Il processo di addestramento del modello YOLOv8 è semplice, specialmente con le risorse fornite nel repository GitHub di YOLOv8. Il repository include istruzioni dettagliate su come addestrare il modello utilizzando un dataset personalizzato, permettendo agli utenti di adattare il modello alle loro specifiche esigenze. Ad esempio, addestrare modelli su un dataset per 100 epoche può portare a un miglioramento significativo delle prestazioni del modello, come dimostrato dalle valutazioni sul set di validazione.
Inoltre, l’architettura di YOLOv8 è progettata per supportare efficacemente compiti di rilevamento di oggetti e segmentazione di immagini. Questa versatilità è evidente nella sua applicazione in vari domini, dalla sorveglianza alla guida autonoma. YOLOv8 introduce nuove caratteristiche che ne aumentano l’efficienza, come i miglioramenti negli ultimi dieci epoche di addestramento, che ottimizzano l’apprendimento e l’accuratezza del modello.
In sintesi, YOLOv8 rappresenta un significativo avanzamento nella serie YOLO e nel campo più ampio della visone artificale (computer vision). La sua architettura e le caratteristiche all’avanguardia lo rendono una scelta ideale per sviluppatori e ricercatori che cercano di implementare modelli avanzati di rilevamento e segmentazione nei loro progetti. Il repository di Ultralytics è un eccellente punto di partenza per chiunque sia interessato a esplorare le capacità di YOLOv8 e a implementarlo in scenari del mondo reale.
Formato di annotazione YOLOv8: Preparazione dei dati per l’addestramento
Preparare i dati per l’addestramento è un passaggio critico nello sviluppo di qualsiasi modello di visone artificiale (computer vision), e YOLOv8 non fa eccezione. Il formato di annotazione YOLOv8 gioca un ruolo fondamentale in questo processo, in quanto influenza direttamente l’apprendimento e la precisione del modello. Un’annotazione adeguata garantisce che il modello possa identificare e apprendere correttamente dai vari elementi all’interno di un dataset, il che è cruciale per un efficace rilevamento degli oggetti e segmentazione delle immagini.
Il formato di annotazione YOLOv8 è unico e si distingue dagli altri formati utilizzati nella visone artificiale (computer vision). Richiede una dettagliata descrizione degli oggetti nelle immagini, tipicamente attraverso caselle di riquadro e etichette. Ogni oggetto in un’immagine è marcato con una casella di riquadro, e queste caselle sono etichettate con classi che il modello deve identificare. Questo formato è fondamentale per l’addestramento del modello YOLOv8, in quanto aiuta il modello a comprendere la posizione e la categoria di ogni oggetto all’interno dell’immagine.
Preparare un dataset per YOLOv8 comporta l’annotazione di un grande numero di immagini, che può essere un processo che richiede tempo. Tuttavia, lo sforzo è essenziale per ottenere alte prestazioni del modello. La qualità e l’accuratezza delle annotazioni influenzano direttamente la capacità del modello di apprendere e fare previsioni accurate.
Per coloro che cercano di addestrare un modello YOLOv8, comprendere e implementare il formato di annotazione corretto è fondamentale. Questo processo tipicamente coinvolge l’uso di strumenti di annotazione specializzati che permettono agli utenti di disegnare caselle di riquadro e etichettarle in modo appropriato. Il dataset annotato viene poi utilizzato per addestrare il modello, insegnandogli a riconoscere e categorizzare gli oggetti in base alle etichette fornite e alle coordinate delle caselle di riquadro.
Formazione YOLOv8: Una Guida Passo-Passo
La formazione di YOLOv8 è un processo che richiede una preparazione e un’esecuzione attente per ottenere prestazioni ottimali del modello. Il processo di formazione comporta diversi passaggi, dall’impostazione dell’ambiente alla messa a punto del modello su un dataset specifico. Ecco una guida passo-passo per formare YOLOv8:
- Configurazione dell’Ambiente: Il primo passo è configurare l’ambiente di formazione. Questo comporta l’installazione del software e delle dipendenze necessarie. YOLOv8, essendo un modello basato su Python, richiede un ambiente Python con librerie come PyTorch.
- Preparazione dei Dati: Successivamente, prepara il tuo dataset secondo il formato di annotazione di YOLOv8. Questo comporta l’annotazione delle immagini con riquadri di delimitazione ed etichette per definire gli oggetti che il modello deve imparare a rilevare.
- Configurazione del Modello: Prima di iniziare la formazione, configura il modello YOLOv8 secondo le tue esigenze. Questo potrebbe comportare l’aggiustamento di parametri come il tasso di apprendimento, la dimensione del batch e il numero di epoche.
- Formazione del Modello: Con l’ambiente e i dati configurati, puoi iniziare il processo di formazione. Questo comporta l’alimentazione del dataset annotato al modello e permettendogli di apprendere dai dati. Il modello regola iterativamente i suoi pesi e bias per minimizzare gli errori nella rilevazione.
- Valutazione delle Prestazioni: Dopo la formazione, valuta le prestazioni del modello utilizzando metriche come precisione, richiamo e Precisione Media Media (mAP). Questo aiuta a capire quanto bene il modello può rilevare e classificare oggetti nelle immagini.
- Messa a Punto: In base alla valutazione, potresti dover mettere a punto il modello. Questo potrebbe comportare la riformazione del modello con parametri aggiustati o fornendogli ulteriori dati di formazione.
- Implementazione: Una volta che il modello è stato formato e messo a punto, è pronto per l’implementazione in applicazioni del mondo reale.
Formare un modello YOLOv8 richiede attenzione ai dettagli e una profonda comprensione del funzionamento del modello. Tuttavia, lo sforzo ripaga con un modello di rilevamento oggetti robusto, accurato ed efficiente adatto per varie applicazioni nella visone artificale (computer vision).
Distribuzione di YOLOv8 in Applicazioni del Mondo Reale
Distribuire YOLOv8 in applicazioni del mondo reale è un passo critico per sfruttare le sue avanzate capacità di rilevamento degli oggetti. Una distribuzione di successo traduce la competenza teorica del modello in soluzioni pratiche e attuabili in vari settori. Ecco una guida completa alla distribuzione di YOLOv8:
- Scegliere la Piattaforma Giusta: Il primo passo è decidere dove verrà distribuito il modello YOLOv8. Questo potrebbe variare dai server basati su cloud per applicazioni su larga scala ai dispositivi edge per l’elaborazione in tempo reale sul sito, come la soluzione di piattaforma di visone artificale (computer vision) di visionplatform.ai.
- Ottimizzazione del Modello: A seconda della piattaforma di distribuzione, potrebbe essere necessario ottimizzare il modello YOLOv8 per le prestazioni. Tecniche come la quantizzazione del modello o il pruning possono essere utilizzate per ridurre le dimensioni del modello senza compromettere significativamente l’accuratezza, rendendolo adatto per dispositivi con risorse di calcolo limitate.
- Integrazione con Sistemi Esistenti: In molti casi, il modello YOLOv8 dovrà essere integrato in sistemi software o hardware esistenti. Questo richiede una profonda comprensione di questi sistemi e la capacità di interfacciare il modello YOLOv8 utilizzando API appropriate o framework software.
- Test e Validazione: Prima della distribuzione su larga scala, è cruciale testare il modello in un ambiente controllato per assicurarsi che funzioni come previsto. Questo comporta la validazione dell’accuratezza, della velocità e dell’affidabilità del modello in diverse condizioni.
- Distribuzione e Monitoraggio: Una volta testato, distribuire il modello sulla piattaforma scelta. Il monitoraggio continuo è essenziale per garantire che il modello funzioni correttamente ed efficientemente nel tempo. Questo aiuta anche a identificare e correggere eventuali problemi che possono sorgere dopo la distribuzione.
- Aggiornamenti e Manutenzione: Come qualsiasi software, il modello YOLOv8 distribuito potrebbe richiedere aggiornamenti periodici per miglioramenti o per affrontare nuove sfide. La manutenzione regolare garantisce che il modello rimanga efficace e sicuro.
Distribuire efficacemente YOLOv8 richiede un approccio strategico, considerando fattori come l’ambiente operativo, le limitazioni computazionali e le sfide di integrazione. Quando fatto correttamente, YOLOv8 può migliorare significativamente le capacità dei sistemi in settori come la sicurezza, la sanità, i trasporti e il commercio al dettaglio.
YOLOv8 vs YOLOv5: Confronto tra modelli di rilevamento oggetti
Confrontare YOLOv8 e YOLOv5 è essenziale per comprendere i progressi nei modelli di rilevamento oggetti e per decidere quale modello sia più adatto per una specifica applicazione. Entrambi i modelli sono all’avanguardia nelle loro capacità, ma presentano caratteristiche e metriche di prestazione distintive.
- Architettura del Modello: YOLOv8 introduce diversi miglioramenti architettonici rispetto a YOLOv5. Questi includono miglioramenti nei livelli di rilevamento e l’integrazione di nuove tecnologie come il rilevamento senza ancoraggi, che migliora l’accuratezza e l’efficienza del modello.
- Accuratezza e Velocità: YOLOv8 ha mostrato miglioramenti nell’accuratezza e nella velocità di rilevamento rispetto a YOLOv5. Questo è particolarmente evidente in scenari di rilevamento impegnativi che coinvolgono oggetti piccoli o sovrapposti.
- Formazione e Flessibilità: Entrambi i modelli offrono flessibilità nella formazione, permettendo agli utenti di allenarsi su dataset personalizzati. Tuttavia, YOLOv8 fornisce funzionalità più avanzate per il perfezionamento del modello, che possono portare a migliori prestazioni in compiti specifici.
- Idoneità dell’Applicazione: Mentre YOLOv5 rimane un’opzione potente per molte applicazioni, i progressi di YOLOv8 lo rendono più adatto per scenari in cui sono cruciali massima accuratezza e velocità.
- Comunità e Supporto: Entrambi i modelli beneficiano di un forte supporto della comunità e sono ampiamente utilizzati, garantendo miglioramenti continui e ampie risorse per gli sviluppatori.
In conclusione, mentre YOLOv5 rimane un modello robusto ed efficiente per il rilevamento oggetti, YOLOv8 rappresenta gli ultimi progressi nel campo, offrendo una maggiore accuratezza e prestazioni. La scelta tra i due dipende dai requisiti specifici dell’applicazione, inclusi fattori come risorse computazionali, la complessità del compito di rilevamento e la necessità di elaborazione in tempo reale.
Esplorazione delle Varianti dei Modelli YOLO
La serie YOLO (You Only Look Once) comprende una gamma di modelli progettati per varie applicazioni nel rilevamento degli oggetti, ognuno differisce per dimensioni, velocità e accuratezza. Dal modello YOLOv8n leggero, progettato per dispositivi edge, al YOLOv8x altamente accurato, adatto per ricerche approfondite, queste varianti soddisfano ambienti di calcolo diversi e requisiti applicativi. Questa esplorazione fornisce una panoramica dei diversi tipi di modelli YOLO, evidenziando le loro caratteristiche uniche e i casi d’uso ottimali.
| Attributo / Modello | YOLOv8n (Nano) | YOLOv8s (Piccolo) | YOLOv8m (Medio) | YOLOv8l (Grande) | YOLOv8x (Molto Grande) | |
|---|---|---|---|---|---|---|
| Dimensione | Molto Piccolo | Piccolo | Medio | Grande | Molto Grande | |
| Velocità | Molto Veloce | Veloce | Moderata | Lenta | Molto Lenta | |
| Accuratezza | Inferiore | Moderata | Alta | Molto Alta | Massima | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Risoluzione | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
Confrontando Yolo con i modelli precedenti come YOLOv5, YOLOv6, YOLOv7 e YOLOv8 si nota che YOLOv8 è sia migliore che più veloce delle sue versioni precedenti.
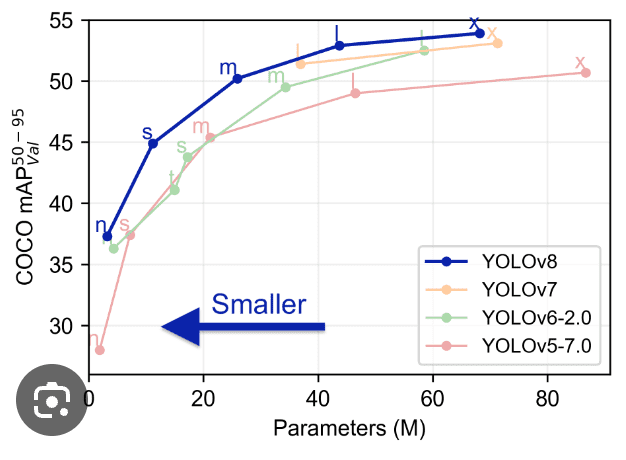
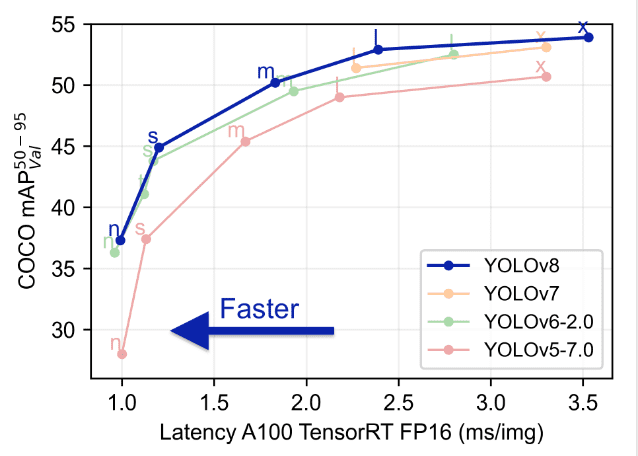
Funzionalità Avanzate in YOLOv8: Miglioramento delle Prestazioni del Modello
Le prestazioni del modello YOLOv8 si distinguono nel campo della visone artificale (computer vision), grazie a una serie di funzionalità avanzate che ne potenziano le capacità. Queste caratteristiche contribuiscono significativamente allo status di YOLOv8 come modello all’avanguardia per compiti di rilevamento e segmentazione degli oggetti. Un’analisi approfondita di queste funzionalità rivela perché YOLOv8 è una scelta top per sviluppatori e ricercatori:
- Rilevamento Senza Ancore: YOLOv8 si allontana dalle tradizionali scatole di ancoraggio verso un sistema di rilevamento senza ancore. Questo semplifica l’architettura del modello, inclusa la versione YOLOv8 Nano, e migliora la sua capacità di prevedere accuratamente le posizioni degli oggetti, specialmente per immagini con forme e dimensioni degli oggetti diverse.
- Strati Convolutivi Migliorati: YOLOv8 introduce modifiche ai suoi blocchi convoluzionali, sostituendo le convoluzioni
6x6con quelle3x3. Questo cambiamento potenzia la capacità del modello di estrarre e apprendere dettagli accurati dalle immagini, migliorando la sua precisione di rilevamento complessiva. - Incremento dei Dati con Mosaico: Unico di YOLOv8 è l’implementazione dell’incremento dei dati con mosaico durante l’addestramento. Questa tecnica unisce insieme quattro immagini diverse, potenziando la capacità del modello di rilevare oggetti in contesti e sfondi variati. Tuttavia, YOLOv8 disattiva strategicamente questo incremento negli ultimi dieci epoche di addestramento per ottimizzare le prestazioni.
- Integrazione con PyTorch: Essendo un pacchetto Python, YOLOv8 beneficia di un’integrazione senza soluzione di continuità con PyTorch, un framework leader nell’apprendimento automatico. Questa integrazione semplifica il processo di addestramento e implementazione del modello, specialmente quando si lavora con dataset personalizzati.
- Rilevamento di Oggetti Multi-Scale: L’architettura di YOLOv8 è progettata per il rilevamento di oggetti multi-scala. Questa caratteristica permette al modello di rilevare accuratamente oggetti di dimensioni variabili all’interno di un’immagine, rendendolo versatile in diversi scenari applicativi.
- Capacità di Elaborazione in Tempo Reale: Uno dei vantaggi più significativi di YOLOv8 è la sua capacità di eseguire il rilevamento degli oggetti in tempo reale. Questa caratteristica è cruciale per applicazioni che richiedono un’analisi e una risposta immediate, come la guida autonoma e la sorveglianza in tempo reale.
Queste funzionalità avanzate sottolineano la capacità di YOLOv8 come strumento potente nel regno della visone artificale (computer vision). La sua combinazione di accuratezza, velocità e flessibilità lo rende un’ottima scelta per un ampio spettro di applicazioni di rilevamento e segmentazione degli oggetti.
Iniziare con YOLOv8: Dall’installazione al deployment
Iniziare con YOLOv8, specialmente per chi è nuovo nel campo della visone artificale (computer vision), può sembrare scoraggiante. Tuttavia, con la guida giusta, configurare e implementare YOLOv8 può essere un processo semplificato. Ecco una guida passo dopo passo per iniziare con YOLOv8:
- Comprendere le Basi: Prima di immergersi in YOLOv8, è fondamentale avere una comprensione di base dei concetti di visone artificale (computer vision) e dei principi dietro ai modelli di rilevamento degli oggetti. Questa conoscenza di base aiuterà a comprendere come funziona YOLOv8.
- Configurazione dell’Ambiente: Il primo passo tecnico comporta la configurazione dell’ambiente di programmazione. Questo include l’installazione di Python, PyTorch e altre librerie necessarie. La documentazione di YOLOv8 fornisce indicazioni dettagliate sul processo di configurazione.
- Accesso alle Risorse YOLOv8: Il repository GitHub di YOLOv8 è una risorsa preziosa. Contiene il codice del modello, i pesi pre-allenati e una documentazione estesa. Familiarizzare con queste risorse è cruciale per un’implementazione di successo.
- Allenamento del Modello: Per allenare YOLOv8, hai bisogno di un dataset. Per i principianti, è consigliabile utilizzare un dataset standard come COCO. Il processo di allenamento comporta il perfezionamento del modello sul tuo dataset specifico per ottimizzare le sue prestazioni per la tua applicazione.
- Valutazione del Modello: Dopo l’allenamento, valuta le prestazioni del modello utilizzando metriche standard come precisione, recall e mean Average Precision (mAP). Questo passaggio è fondamentale per garantire che il modello rilevi accuratamente gli oggetti.
- Deployment: Con un modello allenato e testato, come il modello YOLOv8 Nano, il passo successivo è il deployment. Questo potrebbe essere su un server per applicazioni web o su un dispositivo edge per l’elaborazione in tempo reale utilizzando visionplatform.ai.
- Apprendimento Continuo: Il campo della visone artificale (computer vision) è in rapida evoluzione. Mantenersi aggiornati con gli ultimi progressi e continuare a imparare è fondamentale per utilizzare efficacemente YOLOv8 tramite una piattaforma di visone artificale (computer vision).
Iniziare con YOLOv8 comporta una combinazione di comprensione teorica e applicazione pratica. Seguendo questi passaggi, si può implementare e utilizzare con successo YOLOv8 in varie attività di visone artificale (computer vision), sfruttando appieno il suo potenziale nel rilevamento degli oggetti e nella segmentazione delle immagini.
Il futuro della visone artificale (computer vision): Novità in YOLOv8 e oltre
Il futuro della visone artificale (computer vision) è incredibilmente promettente, con YOLOv8 che guida l’avanguardia come il modello più recente e avanzato della serie YOLO. L’introduzione di YOLOv8 segna una pietra miliare significativa nell’evoluzione continua delle tecnologie di visone artificale (computer vision), offrendo una precisione e un’efficienza senza precedenti nei compiti di rilevamento degli oggetti. Ecco le novità di YOLOv8 e le implicazioni per il futuro della visone artificale (computer vision):
- Avanzamenti Tecnologici: YOLOv8 ha introdotto diversi miglioramenti tecnologici rispetto ai suoi predecessori. Questi includono reti convoluzionali più efficienti, rilevamento senza ancoraggi e algoritmi migliorati per il rilevamento degli oggetti in tempo reale.
- Maggiore Accessibilità e Applicazione: Con YOLOv8, il campo della visone artificale (computer vision) diventa più accessibile a una gamma più ampia di utenti, inclusi quelli senza una vasta esperienza di codifica. Questa democratizzazione della tecnologia favorisce l’innovazione e incoraggia applicazioni diverse in vari settori.
- Integrazione con Tecnologie Emergenti: La compatibilità di YOLOv8 con framework avanzati di apprendimento automatico e la sua capacità di integrarsi con altre tecnologie all’avanguardia, come la realtà aumentata e la robotica, segnalano un futuro in cui le soluzioni di visone artificale (computer vision) sono sempre più versatili e potenti.
- Miglioramento delle Metriche di Prestazione: YOLOv8 ha stabilito nuovi benchmark nelle prestazioni del modello, in particolare in termini di accuratezza e velocità di elaborazione. Questo miglioramento è cruciale per applicazioni che richiedono analisi in tempo reale, come i veicoli autonomi e le tecnologie per le città intelligenti.
- Previsioni per Sviluppi Futuri: Guardando avanti, possiamo prevedere ulteriori avanzamenti nei modelli di visone artificale (computer vision), con ancora maggiore accuratezza, velocità e adattabilità. L’integrazione dell’IA con la visone artificale (computer vision) continuerà probabilmente a evolversi, portando a sistemi più sofisticati e autonomi.
Lo sviluppo continuo di YOLOv8 e modelli simili è una testimonianza della natura dinamica del campo della visone artificale (computer vision). Con l’avanzamento della tecnologia, possiamo aspettarci di vedere ulteriori innovazioni rivoluzionarie che ridefiniranno i limiti di ciò che i sistemi di visone artificale (computer vision) possono raggiungere.
Conclusione: L’impatto di YOLOv8 sulla visone artificale e sull’IA
In conclusione, YOLOv8 ha avuto un impatto sostanziale sul campo della visone artificale (computer vision) e dell’IA. Le sue caratteristiche avanzate e le sue capacità rappresentano un significativo passo avanti nella tecnologia di rilevamento degli oggetti. Le implicazioni degli avanzamenti di YOLOv8 si estendono oltre il regno tecnico, influenzando varie industrie e applicazioni:
- Avanzamenti nel Rilevamento degli Oggetti: YOLOv8 ha stabilito un nuovo standard nel rilevamento degli oggetti con la sua migliorata accuratezza, velocità ed efficienza. Questo ha implicazioni per una vasta gamma di applicazioni, dalla sicurezza e sorveglianza alla sanità, produzione, logistica e monitoraggio ambientale.
- Democratizzazione della Tecnologia IA: Rendendo la tecnologia di visone artificale (computer vision) avanzata come il repository di YOLOv8 più accessibile e facile da usare, YOLOv8 ha aperto la porta a un più ampio spettro di utenti e sviluppatori per innovare e creare soluzioni basate sull’IA.
- Miglioramento delle Applicazioni nel Mondo Reale: Le applicazioni pratiche di YOLOv8 in scenari del mondo reale sono vastissime. La sua capacità di fornire un rilevamento degli oggetti accurato e in tempo reale lo rende uno strumento inestimabile in aree come la guida autonoma, l’automazione industriale e le iniziative per le città intelligenti.
- Ispirazione per Future Innovazioni: Il successo di YOLOv8 serve da ispirazione per futuri sviluppi nella visone artificale (computer vision) e nell’IA. Prepara il terreno per ulteriori ricerche e innovazioni, spingendo i limiti di ciò che queste tecnologie possono raggiungere.
In sintesi, YOLOv8 non ha solo avanzato gli aspetti tecnici della visone artificale (computer vision), ma ha anche contribuito all’evoluzione più ampia dell’IA. Il suo impatto si vede nelle capacità migliorate dei sistemi IA e nelle nuove possibilità che apre per l’innovazione e l’applicazione pratica in diversi campi. Mentre continuiamo ad esplorare il potenziale dell’IA e della visone artificale (computer vision), YOLOv8 sarà senza dubbio ricordato come una pietra miliare in questo viaggio di avanzamento tecnologico.
Domande Frequenti su YOLOv8
Mentre YOLOv8 continua a rivoluzionare il campo della visone artificale (computer vision), sorgono numerose domande riguardo le sue capacità, applicazioni e aspetti tecnici. Questa sezione FAQ mira a fornire risposte chiare e concise ad alcune delle domande più comuni su YOLOv8. Che tu sia uno sviluppatore esperto o solo all’inizio, queste risposte aiuteranno ad approfondire la tua comprensione di questo modello di rilevamento oggetti all’avanguardia.
Cos’è YOLOv8 e in cosa differisce dalle versioni precedenti di YOLO?
YOLOv8 è l’ultima iterazione nella serie YOLO di rilevatori di oggetti in tempo reale, offrendo prestazioni di primo livello in termini di accuratezza e velocità. Si basa sui progressi delle versioni precedenti come YOLOv5 con miglioramenti che includono architetture avanzate di backbone e neck, una testa Ultralytics senza ancoraggi per una maggiore accuratezza, e un equilibrio ottimale tra accuratezza e velocità per il rilevamento di oggetti in tempo reale. Fornisce anche una gamma di modelli pre-allenati per diverse attività e requisiti di prestazione.
Come il rilevamento senza ancoraggi in YOLOv8 migliora il rilevamento degli oggetti?
YOLOv8 adotta un approccio di rilevamento senza ancoraggi, prevedendo direttamente i centri degli oggetti, il che semplifica l’architettura del modello e migliora l’accuratezza. Questo metodo è particolarmente efficace nel rilevare oggetti di varie forme e dimensioni. Riducendo il numero di previsioni di box, accelera il processo di soppressione non massima, cruciale per affinare i risultati del rilevamento, rendendo YOLOv8 più efficiente e accurato rispetto ai suoi predecessori che utilizzavano box di ancoraggio.
Quali sono le principali innovazioni e miglioramenti nell’architettura di YOLOv8?
YOLOv8 introduce diverse innovazioni architettoniche significative, tra cui il backbone CSPNet per un’estrazione efficiente delle caratteristiche e la testa PANet, che migliora la robustezza contro l’occlusione degli oggetti e le variazioni di scala. La sua augmentazione dei dati a mosaico durante l’allenamento espone il modello a una più ampia gamma di scenari, migliorando la sua generalizzabilità. YOLOv8 combina anche apprendimento supervisionato e non supervisionato, contribuendo al miglioramento delle prestazioni di rilevamento in compiti di rilevamento oggetti e segmentazione istanze.
Per iniziare a utilizzare YOLOv8, dovresti prima installare il pacchetto Python di YOLOv8. Poi, nel tuo script Python, importa il modulo YOLOv8, crea un’istanza della classe YOLOv8 e carica i pesi pre-allenati. Successivamente, utilizza il metodo detect per eseguire il rilevamento degli oggetti su un’immagine. I risultati conterranno informazioni sugli oggetti rilevati, inclusi le loro classi, punteggi di fiducia e coordinate del box di delimitazione.
Quali sono alcune applicazioni pratiche di YOLOv8 in diverse industrie?
YOLOv8 ha applicazioni versatili in varie industrie grazie alla sua alta velocità e accuratezza. Nei veicoli autonomi, assiste nell’identificazione e classificazione degli oggetti in tempo reale. È utilizzato nei sistemi di sorveglianza per il rilevamento e il riconoscimento degli oggetti in tempo reale. I rivenditori utilizzano YOLOv8 per analizzare il comportamento dei clienti e gestire l’inventario. In sanità, aiuta nell’analisi dettagliata delle immagini mediche, migliorando la diagnostica e la cura dei pazienti.
Come si comporta YOLOv8 sul dataset COCO e cosa significa questo per la sua accuratezza?
YOLOv8 dimostra prestazioni notevoli sul dataset COCO, un benchmark standard per i modelli di rilevamento oggetti. La sua precisione media media (mAP) varia in base alla dimensione del modello, con il modello più grande, YOLOv8x, che raggiunge la mAP più alta. Questo evidenzia miglioramenti significativi nell’accuratezza rispetto alle versioni precedenti di YOLO. L’alta mAP indica un’accuratezza superiore nel rilevare una vasta gamma di oggetti in varie condizioni.
Quali sono i limiti di YOLOv8 e ci sono scenari in cui potrebbe non essere la scelta migliore?
Nonostante le sue impressionanti prestazioni, YOLOv8 ha delle limitazioni, in particolare nel supportare modelli allenati ad alte risoluzioni come 1280. Per applicazioni che richiedono inferenze ad alta risoluzione, YOLOv8 potrebbe non essere ideale. Tuttavia, per la maggior parte delle applicazioni, supera i modelli precedenti in termini di accuratezza e prestazioni. Le sue rilevazioni senza ancoraggi e l’architettura migliorata lo rendono adatto per un’ampia gamma di progetti di visone artificale (computer vision).
Posso allenare YOLOv8 su un dataset personalizzato e quali sono alcuni consigli per un allenamento efficace?
Sì, YOLOv8 può essere allenato su dataset personalizzati. Un allenamento efficace implica sperimentare con tecniche di augmentazione dei dati, in particolare l’augmentazione a mosaico, e ottimizzare gli iperparametri come il tasso di apprendimento, la dimensione del batch e il numero di epoche. La valutazione regolare e il perfezionamento sono cruciali per massimizzare le prestazioni. Scegliere il dataset giusto e il regime di allenamento è fondamentale per garantire che il modello si generalizzi bene ai nuovi dati.
Quali sono i passaggi chiave per distribuire YOLOv8 in un ambiente reale?
La distribuzione di YOLOv8 implica ottimizzare il modello per la piattaforma target, integrarlo nei sistemi esistenti e testarlo per accuratezza e affidabilità. Il monitoraggio continuo dopo la distribuzione garantisce un funzionamento efficiente. Per i dispositivi edge, l’ottimizzazione del modello potrebbe includere la quantizzazione o la potatura. Aggiornamenti e manutenzione regolari sono essenziali per mantenere il modello efficace e sicuro in varie applicazioni.
Come si prospetta il futuro per YOLOv8 e le sue applicazioni nella visone artificale (computer vision)?
Il futuro di YOLOv8 nella visone artificale (computer vision) appare promettente, con potenzialità per una maggiore accuratezza, velocità e versatilità. La sua tecnologia in evoluzione, inclusi il rilevamento degli oggetti e la segmentazione delle istanze, potrebbe trovare nuove applicazioni in aree come l’imaging medico, la conservazione della fauna selvatica e sistemi autonomi più avanzati. Gli sforzi continui di ricerca e sviluppo sono probabili spingere i confini di YOLOv8, consolidando ulteriormente la sua posizione come modello di rilevamento oggetti leader.