
Wat is Objectdetectie
Objectdetectie in de computervisie verwijst naar de taak van het identificeren en lokaliseren van objecten binnen een afbeelding of videoframe. Het doel is niet alleen om te classificeren welke objecten aanwezig zijn, maar ook om de precieze locatie van elk object binnen de afbeelding te verstrekken. Dit omvat doorgaans het tekenen van begrenzingsvakken rond de gedetecteerde objecten en het labelen ervan met hun overeenkomstige klassen.
Objectdetectie is een fundamentele taak in veel toepassingen van computervisie, waaronder:
- Autonoom rijden: Het detecteren van voetgangers, voertuigen, verkeersborden en andere objecten op de weg.
- Surveillance en beveiliging: Het identificeren van mensen, voertuigen en verdachte activiteiten in videofeeds.
- Medische beeldvorming: Het lokaliseren en classificeren van afwijkingen in medische beelden zoals röntgenfoto’s, MRI’s of CT-scans.
- Detailhandel: Het tellen en volgen van producten op winkelschappen of het detecteren van winkeldiefstalgedrag.
- Industriële automatisering: Het inspecteren van geproduceerde producten op defecten of afwijkingen op productielijnen.
- Augmented reality: Het herkennen van objecten in de omgeving om digitale informatie te overlayen.
- Robotica: Het mogelijk maken voor robots om objecten in hun omgeving waar te nemen en ermee te interacteren.
Objectdetectie-algoritmen omvatten doorgaans verschillende stappen:
- Feature-extractie: De invoerafbeelding wordt geanalyseerd om kenmerken te identificeren die relevant zijn voor objectdetectie. Dit kan technieken omvatten zoals convolutionele neurale netwerken (CNN’s) om hiërarchische representaties van de afbeelding te extraheren.
- Lokalisatie: Deze stap omvat het voorspellen van de locatie van objecten binnen de afbeelding. Dit wordt vaak gedaan door regressie van de begrenzingsvakcoördinaten ten opzichte van het afbeeldingskader.
- Classificatie: Elk gedetecteerd object wordt een klassenlabel toegewezen (bijv. persoon, auto, hond) op basis van de visuele kenmerken ervan. Dit wordt meestal gedaan met behulp van een classificatiemodel, vaak samen met het lokaliseringsmodel.
- Post-processing: Tot slot kunnen de detectieresultaten post-processingstappen ondergaan zoals non-maximum suppression (NMS) om de begrenzingsvakken te verfijnen en dubbele detecties te elimineren.
Typisch worden de stappen van feature-extractie tot post-processing allemaal afgehandeld door een Deep Convolutional Neural Network.
Populaire benaderingen voor objectdetectie zijn onder andere:
- Twee-traps detectoren: Deze methoden stellen eerst regio’s van belang (RoI’s) voor met behulp van technieken zoals selectieve zoekopdracht of regio-voorstellen netwerken (RPN’s), en classificeren en verfijnen vervolgens deze voorstellen. Voorbeelden zijn Faster R-CNN, R-FCN en Mask R-CNN.
- Eén-traps detectoren: Deze methoden voorspellen direct objectbegrenzingsvakken en klassenwaarschijnlijkheden in één keer door het netwerk, zonder aparte voorstelstap. Voorbeelden zijn YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector) en RetinaNet.
Hoewel twee-traps detectoren superieure nauwkeurigheid hebben, zijn ze vaak rekenkundig duurder om uit te voeren en kunnen ze niet worden gebruikt voor veel real-time toepassingen. Eén-traps detectoren offeren enige nauwkeurigheid op voor snelheid. Zoals typisch het geval is bij neurale netwerken, moeten prioriteiten tussen snelheid en nauwkeurigheid worden gedefinieerd bij het selecteren van een model om te gebruiken.
Objectdetectie heeft de afgelopen jaren aanzienlijke vooruitgang geboekt, gedreven door verbeteringen in deep learning-technieken, datasetgroottes en rekenmiddelen.
Wat is YOLO
YOLO (You Only Look Once) is een familie van real-time objectdetectiemodellen die zeer efficiënt zijn en in staat zijn om objecten in afbeeldingen of videoframes met opmerkelijke snelheid te detecteren. Het belangrijkste kenmerk van YOLO-modellen is hun vermogen om objectdetectie uit te voeren in één doorgang door het neurale netwerk, vandaar de naam “You Only Look Once”.
Er zijn verschillende iteraties en versies van YOLO-modellen geweest, elk met verbeteringen ten opzichte van de vorige versies. De algemene architectuur en principes blijven echter consistent over de verschillende versies. Hier is een algemeen overzicht van hoe YOLO-modellen werken:
- Grid-gebaseerde benadering: YOLO verdeelt de invoerafbeelding in een raster van cellen. Elke cel is verantwoordelijk voor het voorspellen van begrenzingsvakken en klassenwaarschijnlijkheden voor objecten waarvan de centra binnen die cel vallen.
- Voorspelling: Voor elke gridcel voorspelt YOLO begrenzingsvakken (meestal 2 of meer per cel) samen met vertrouwensscores die de waarschijnlijkheid vertegenwoordigen dat het begrenzingsvak een object bevat, en klassenwaarschijnlijkheden voor elke klasse.
- Enkele doorgang van voorspelling: YOLO verwerkt de hele afbeelding via een convolutioneel neurale netwerk (CNN) in één voorwaartse doorgang om deze voorspellingen te doen. Dit staat in contrast met sommige andere methoden voor objectdetectie die meerdere doorgangen of regio-voorstellen vereisen.
- Uitvoerformaat: De uitvoer van een YOLO-model is een set begrenzingsvakken, vertrouwensscores en klassenwaarschijnlijkheden. Deze begrenzingsvakken worden rechtstreeks voorspeld door het netwerk en zijn niet afhankelijk van enige post-processingstappen zoals non-maximum suppression (NMS) om ze te verfijnen.
- Verliesfunctie: YOLO gebruikt een combinatie van lokalisatieverlies (het meten van de nauwkeurigheid van begrenzingsvakvoorspellingen) en classificatieverlies (het meten van de nauwkeurigheid van klassevoorspellingen) om het model te trainen. De verliesfunctie is ontworpen om onnauwkeurige voorspellingen te bestraffen en tegelijkertijd het model aan te moedigen zelfverzekerde voorspellingen te doen voor objecten.
Introductie van YOLOv9
YOLOv9, de nieuwste iteratie van de populaire You Only Look Once (YOLO) -serie, vertegenwoordigt een state-of-the-art vooruitgang in real-time objectdetectiesystemen. Voortbouwend op het succes van zijn voorgangers, introduceert YOLOv9 innovatieve concepten zoals Programmable Gradient Information (PGI) en Generalized Efficient Layer Aggregation Network (GELAN) om de efficiëntie en nauwkeurigheid van objectdetectietaken te verbeteren. Door PGI op te nemen, adresseert YOLOv9 de uitdaging van gegevensverlies in diepe netwerken door te zorgen voor het behoud van belangrijke kenmerken en betrouwbare gradiëntgeneratie voor optimale trainingsresultaten. Bovendien biedt de integratie van GELAN een lichtgewicht netwerkarchitectuur die de parameterbenutting en rekenkundige efficiëntie optimaliseert, waardoor YOLOv9 een veelzijdige en hoogwaardige oplossing is voor een breed scala aan toepassingen.
Met een focus op real-time objectdetectie bouwt YOLOv9 voort op state-of-the-art methodologieën zoals CSPNet, ELAN en verbeterde functie-integratietechnieken om superieure prestaties te leveren in verschillende taken op het gebied van computervisie. Door de kracht van PGI voor gradiëntinformatieprogrammering en GELAN voor efficiënte laagaggregatie te introduceren, stelt YOLOv9 een nieuwe standaard voor objectdetectiesystemen, die bestaande real-time detectoren overtreft qua nauwkeurigheid, snelheid en parametergebruik. Dit YOLO-model van de volgende generatie belooft de sector van computervisie te revolutioneren met zijn geavanceerde mogelijkheden en uitzonderlijke prestaties op datasets zoals MS COCO, en vestigt zich als een topkandidaat op het gebied van real-time objectdetectie.
Welke problemen lost YOLOv9 op
YOLOv9 heeft superieure prestaties behaald door verschillende problemen op te lossen die zich voordoen bij het trainen van diepe neurale netwerken.
Het informatieknelpuntprobleem in diepe neurale netwerken verwijst naar het fenomeen waarbij invoergegevens laagsgewijs worden geëxtraheerd en ruimtelijk worden getransformeerd, wat leidt tot verlies van belangrijke informatie. Naarmate gegevens door opeenvolgende lagen van een diep netwerk stromen, kan de oorspronkelijke data geleidelijk zijn onderscheidende kenmerken en essentiële details verliezen, wat resulteert in een informatieknelpunt. Dit knelpunt beperkt het vermogen van het netwerk om complete informatie over het voorspellingsdoel te behouden, wat kan leiden tot onbetrouwbare gradiënten tijdens de training en een slechte convergentie van het model.

Om het probleem van het informatieknelpunt aan te pakken, hebben onderzoekers verschillende methoden verkend zoals omkeerbare architecturen, gemaskerde modellering en diepe supervisie. Omkeerbare architecturen hebben tot doel de informatie van invoergegevens expliciet te behouden door herhaaldelijk gebruik van invoergegevens. Gemaskerde modellering richt zich op het maximaliseren van geëxtraheerde kenmerken impliciet om invoerinformatie te behouden. Diepe supervisie houdt in dat een mapping van ondiepe kenmerken naar doelen vooraf wordt vastgesteld om ervoor te zorgen dat belangrijke informatie wordt overgedragen naar diepere lagen. Deze methoden hebben echter beperkingen en nadelen, zoals verhoogde inferentiekosten, conflicten tussen reconstructieverlies en doelverlies, foutenaccumulatie en moeilijkheden bij het modelleren van semantische informatie van hoog niveau.
Door Programmable Gradient Information (PGI) in hun onderzoek te introduceren, bieden de auteurs van YOLOv9 een nieuwe oplossing voor het probleem van het informatieknelpunt. PGI genereert betrouwbare gradiënten via een hulp-reversibele tak, waardoor diepe kenmerken belangrijke kenmerken behouden die nodig zijn voor het uitvoeren van doeltaken. Deze aanpak zorgt ervoor dat belangrijke informatie behouden blijft en nauwkeurige gradiënten worden verkregen voor het effectief bijwerken van netwerkgewichten, waardoor de convergentie en trainingsresultaten van diepe neurale netwerken worden verbeterd.
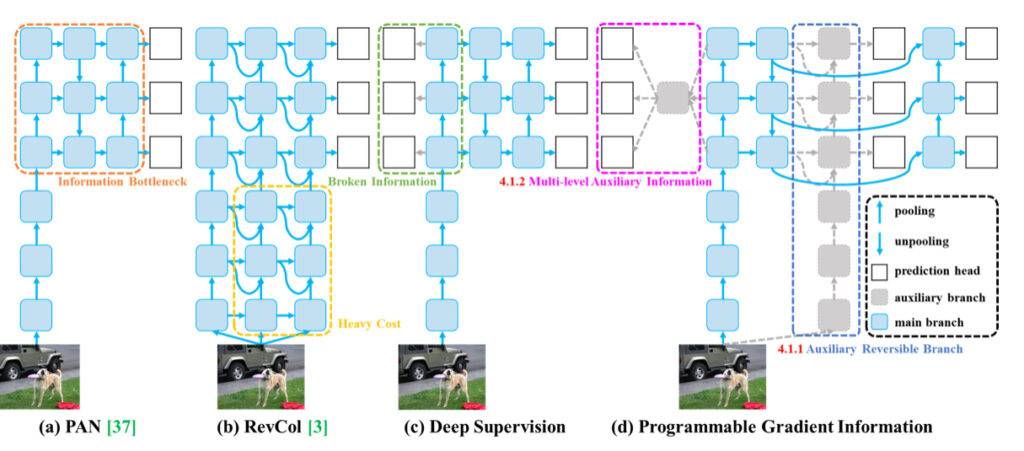
Het tweede probleem dat wordt opgelost door de auteurs van YOLOv9 is inefficiënties met betrekking tot parameterbenutting. Het Generalized Efficient Layer Aggregation Network (GELAN) dat door de auteurs wordt geïntroduceerd, verbetert de parameterbenutting en rekenkundige efficiëntie in diepe neurale netwerken door een nieuwe lichtgewicht architectuur te creëren die de benutting van parameters en rekenbronnen optimaliseert. Hier zijn enkele belangrijke manieren waarop GELAN dit bereikt:
- Flexibiliteit van computationele blokken: GELAN staat toe dat verschillende computationele blokken worden gebruikt, zoals Res-blokken, Dark-blokken en CSP-blokken. Door ablatiestudies uit te voeren op deze computationele blokken, toont GELAN aan dat het goede prestaties kan behouden terwijl gebruikers de flexibiliteit hebben om computationele blokken te kiezen en te vervangen op basis van hun specifieke vereisten. Deze flexibiliteit vermindert niet alleen het aantal parameters, maar verbetert ook de algehele rekenkundige efficiëntie van het netwerk.
- Parameterbenutting: GELAN is ontworpen om een betere benutting van parameters te bereiken in vergelijking met state-of-the-art methoden op basis van diepte-gewijze convolutie. Door conventionele convolutie-operatoren effectief te gebruiken, maximaliseert GELAN het gebruik van parameters en behoudt tegelijkertijd hoge prestaties in objectdetectietaken. Dit efficiënte gebruik van parameters draagt bij aan de algehele effectiviteit en schaalbaarheid van het netwerk.
- Dieptegevoeligheid: De prestaties van GELAN zijn niet overdreven gevoelig voor de diepte van het netwerk. Experimenten tonen aan dat het verhogen van de diepte van GELAN niet leidt tot afnemende opbrengsten wat betreft parameterbenutting en rekenkundige efficiëntie. Deze eigenschap stelt GELAN in staat om een consistent prestatieniveau te handhaven over verschillende diepten, waardoor het netwerk efficiënt en effectief blijft ongeacht de complexiteit ervan.
- Aanpasbaarheid van inferentieapparaat: De architectuur van GELAN is ontworpen om aanpasbaar te zijn aan verschillende inferentieapparaten, waardoor gebruikers computationele blokken kunnen kiezen die geschikt zijn voor hun specifieke hardwarevereisten. Deze aanpasbaarheid zorgt ervoor dat GELAN efficiënt kan worden ingezet op een breed scala van apparaten zonder dat dit ten koste gaat van de prestaties of rekenkundige efficiëntie.
Door deze factoren te combineren, verbetert GELAN de parameterbenutting en rekenkundige efficiëntie in diepe neurale netwerken, waardoor het een veelzijdige en hoogwaardige oplossing is voor een verscheidenheid aan toepassingen, waaronder realtime objectdetectietaken.
Prestatievergelijking
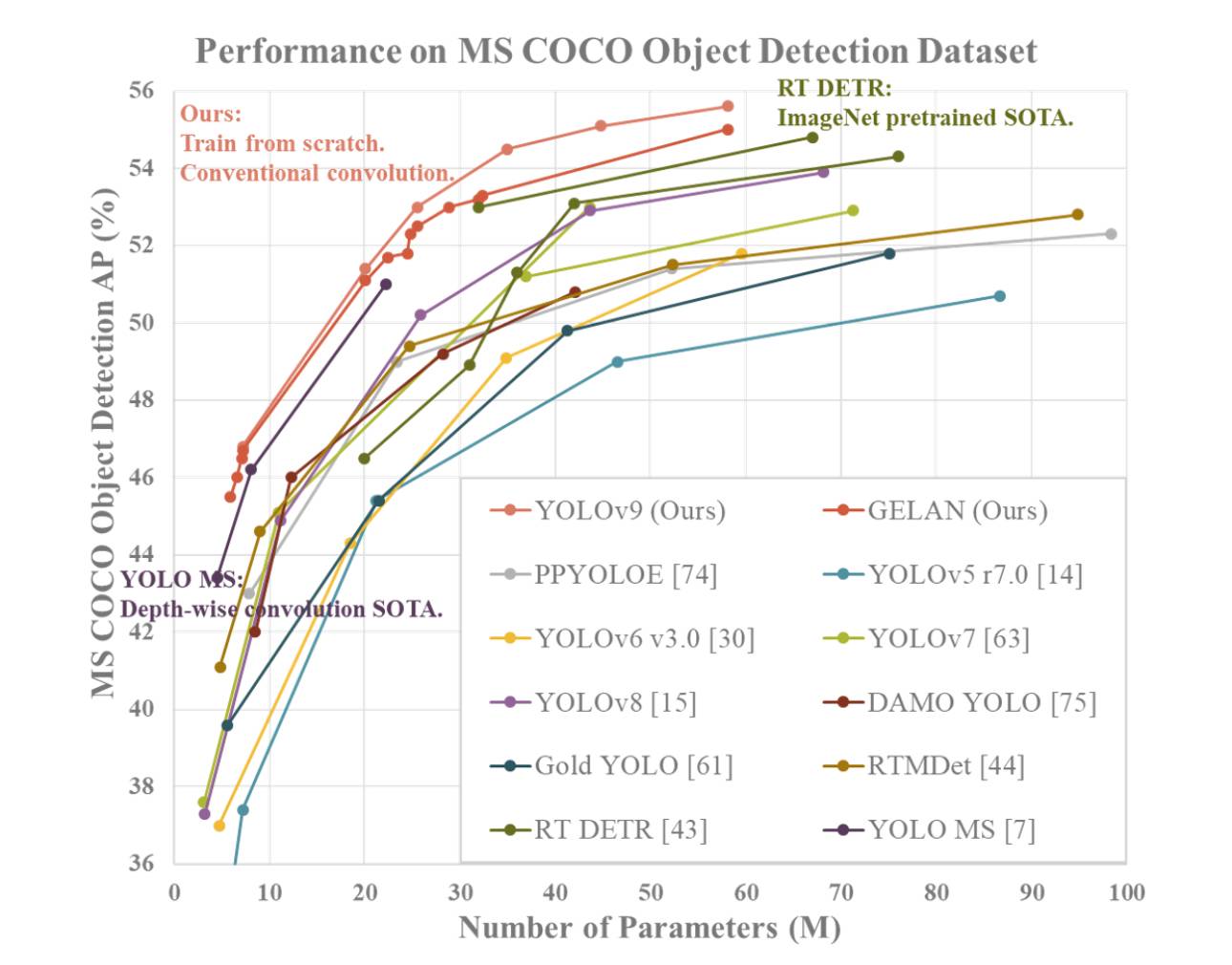
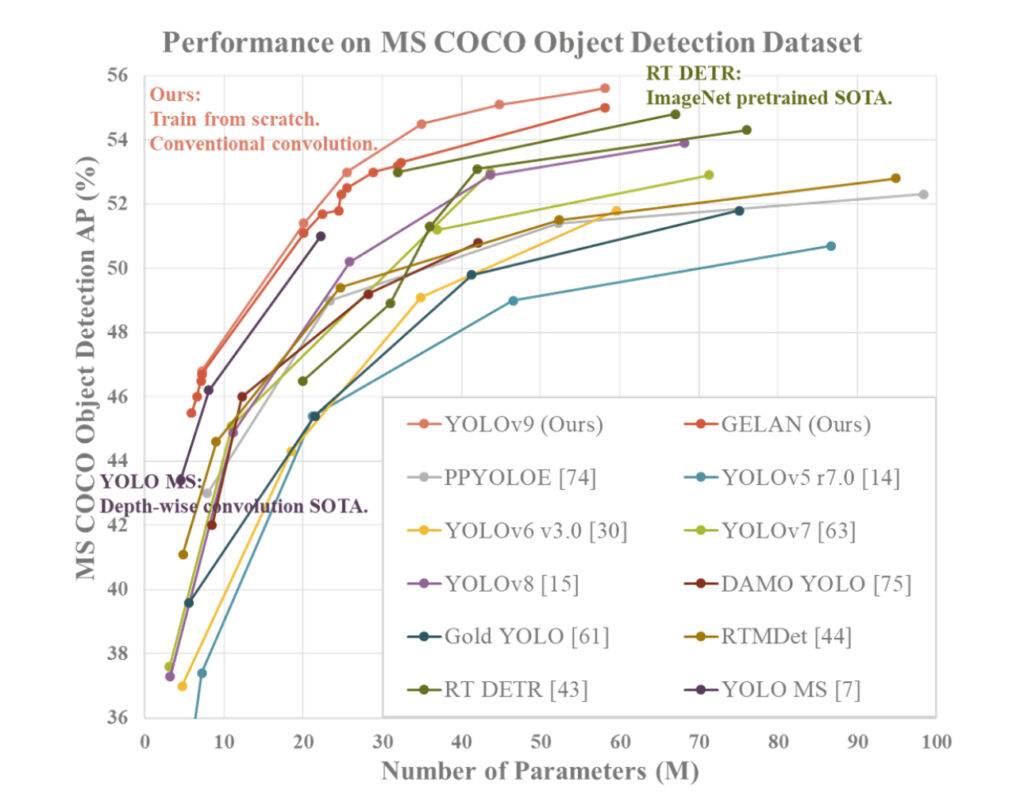
YOLOv9 toont superieure prestaties in vergelijking met eerdere state-of-the-art realtime objectdetectoren over verschillende metrieken. Hier volgt een samenvatting van de vergelijking op basis van de verstrekte informatie:
- Parametersvermindering: YOLOv9 bereikt een aanzienlijke vermindering van het aantal parameters in vergelijking met eerdere detectoren, zoals YOLOv8. Deze vermindering van parameters draagt bij aan een verbeterde rekenkundige efficiëntie en snellere inferentiesnelheden.
- Rekenkundige efficiëntie: YOLOv9 vermindert ook de hoeveelheid berekening die nodig is voor objectdetectietaken, wat leidt tot verbeterde efficiëntie in de verwerking en analyse van visuele gegevens.
- Nauwkeurigheidsverbetering: Ondanks de vermindering van parameters en berekeningen slaagt YOLOv9 erin de gemiddelde precisie (AP) -metriek aanzienlijk te verbeteren op de MS COCO-dataset. Deze verbetering in nauwkeurigheid toont de effectiviteit aan van de voorgestelde PGI- en GELAN-mechanismen bij het verbeteren van de detectieprestaties van het model.
- Concurrentiekracht: YOLOv9 vertoont sterke concurrentiekracht in vergelijking met andere realtime objectdetectoren die zijn getraind met verschillende methoden, waaronder trainen vanaf nul, vooraf getraind door ImageNet, kennisdestillatie en complexe trainingsprocessen. Het model presteert beter dan deze methoden op het gebied van nauwkeurigheid, parameterefficiëntie en rekenkundige snelheid.
- Veelzijdigheid: De combinatie van PGI en GELAN in YOLOv9 maakt een succesvolle integratie van lichtgewicht architecturen met diepe modellen mogelijk, waardoor een breed scala aan toepassingen mogelijk is voor realtime objectdetectie op verschillende inferentieapparaten.
Al met al onderscheidt YOLOv9 zich als een top presterend objectdetectiesysteem dat uitblinkt in nauwkeurigheid, efficiëntie en parameterbenutting, waardoor het een overtuigende keuze is voor realtime taken op het gebied van computervisie.
| Model | APval (%) | AP50_val (%) | AP75_val (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 63.4 | 50.7 | 7.2 | 26.7 |
| YOLOv9-M | 51.4 | 68.1 | 56.1 | 20.1 | 76.8 |
| YOLOv9-C | 53.0 | 70.2 | 57.8 | 25.5 | 102.8 |
| YOLOv9-E | 55.6 | 72.8 | 60.6 | 58.1 | 192.5 |
Conclusie
YOLOv9 toont de significante vooruitgang die is geboekt in real-time objectdetectie door de implementatie en het benutten van innovatieve technieken zoals Generalized Efficient Layer Aggregation Network (GELAN) en Programmable Gradient Information (PGI). Door kritieke problemen zoals het informatieknelpuntprobleem aan te pakken en de parameterbenutting en rekenkundige efficiëntie te optimaliseren, komt YOLOv9 naar voren als een topkandidaat op het gebied van objectdetectie.
Een vergelijkende analyse toont aan dat YOLOv9 bestaande methoden overtreft qua nauwkeurigheid, parameterefficiëntie en rekenkundige snelheid. Het vermogen om parameters te verminderen terwijl de gemiddelde precisie (AP) op datasets zoals MS COCO wordt verbeterd, benadrukt de effectiviteit van de voorgestelde verbeteringen. Bovendien onderstreept de aanpasbaarheid van YOLOv9 aan verschillende inferentieapparaten zijn veelzijdigheid en toepasbaarheid in verschillende scenario’s voor real-time objectdetectie.
Over het algemeen bevordert het onderzoek niet alleen de stand van de techniek op het gebied van real-time objectdetectie, maar opent het ook de deur naar nieuwe mogelijkheden voor efficiënte en nauwkeurige analyse van visuele gegevens in uiteenlopende toepassingsgebieden.
Veelgestelde vragen over YOLOv9
In het snel evoluerende veld van computervisie springt YOLOv9 eruit als een significante sprong voorwaarts, waarbij efficiëntie wordt gecombineerd met baanbrekende nauwkeurigheid. Naarmate de interesse in dit geavanceerde objectdetectiemodel groeit, doen zich vragen voor over de toepassing, prestaties en toegankelijkheid ervan. Hieronder behandelen we de meest voorkomende vragen om zowel nieuwkomers als ervaren professionals een duidelijker beeld te geven van wat YOLOv9 biedt en hoe het hun op visie gebaseerde projecten kan transformeren.
Wat is YOLOv9 en hoe verschilt het van eerdere versies?
YOLOv9 is de nieuwste iteratie in de YOLO (You Only Look Once) -serie, bekend om zijn objectdetectiemogelijkheden. Het introduceert een nieuwe lichtgewicht netwerkarchitectuur, die de detectiesnelheid en -nauwkeurigheid verbetert. In vergelijking met zijn voorganger biedt YOLOv9 een verbeterde gemiddelde precisie (AP) op de MS COCO-dataset, dankzij vooruitgang in programmeerbare gradiëntinformatie en de integratie van transformatortechnologie, waardoor het efficiënter wordt in real-world toepassingen.
Hoe begin ik met YOLOv9 voor objectdetectie?
Om te beginnen met YOLOv9, installeer eerst de benodigde afhankelijkheden, waaronder Python, PyTorch en CUDA voor GPU-versnelling. Download de YOLOv9-broncode uit de officiële repository. Train het model met een aangepaste dataset of gebruik vooraf getrainde gewichten die online beschikbaar zijn om objecten te detecteren. Het uitvoeren van het detectiescript op een afbeelding of video zal realtime objectdetectie opleveren, waarbij de mogelijkheden van YOLOv9 worden gedemonstreerd.
Wat zijn de belangrijkste verbeteringen in de prestaties van YOLOv9?
YOLOv9 introduceert belangrijke verbeteringen in de prestaties van objectdetectie, met name een toename van de gemiddelde precisie (AP) en een vermindering van de inferentietijd. Op de MS COCO-dataset toont YOLOv9 een significante stijging in AP, tot wel 55,6% voor sommige modellen, naast snellere detectiesnelheden, waardoor het zeer geschikt is voor real-time toepassingen. Deze verbeteringen zijn toe te schrijven aan de nieuwe architectuur en optimalisatietechnieken.
Kan YOLOv9 worden geïntegreerd met randcomputingapparaten?
Ja, YOLOv9 kan worden geïntegreerd met randcomputingapparaten dankzij zijn geoptimaliseerde architectuur die efficiënte werking ondersteunt op hardware met beperkte rekenbronnen. Deze compatibiliteit maakt het mogelijk voor YOLOv9 om realtime objectdetectie uit te voeren in randscenario’s, zoals bewakingscamera’s en autonome voertuigen, waar snelle verwerking essentieel is.
Wat zijn de uitdagingen en oplossingen bij het trainen van YOLOv9?
Het trainen van YOLOv9 brengt uitdagingen met zich mee, zoals datadiversiteit en hardwarevereisten. Een diverse dataset is cruciaal voor het bereiken van hoge nauwkeurigheid, terwijl krachtige hardware het trainingsproces versnelt. Oplossingen omvatten het verrijken van datasets voor diversiteit en het gebruik van cloudcomputingresources of gespecialiseerde hardware zoals GPU’s voor snellere modeltraining. Het fijnafstemmen van vooraf getrainde modellen kan ook aanzienlijk de trainingsduur en resourceconsumptie verminderen.
Waar kan ik bronnen en community-ondersteuning vinden voor YOLOv9?
Bronnen en community-ondersteuning voor YOLOv9 zijn overvloedig. Ontwikkelaars kunnen documentatie, vooraf getrainde modellen en codevoorbeelden vinden in de officiële YOLOv9 GitHub-opslagplaats. Voor community-ondersteuning hosten forums zoals Reddit en Stack Overflow actieve discussies, tips en probleemoplossingsadvies. Deze platforms bieden een schat aan informatie voor zowel beginners als experts die hun YOLOv9-projecten willen verbeteren.