
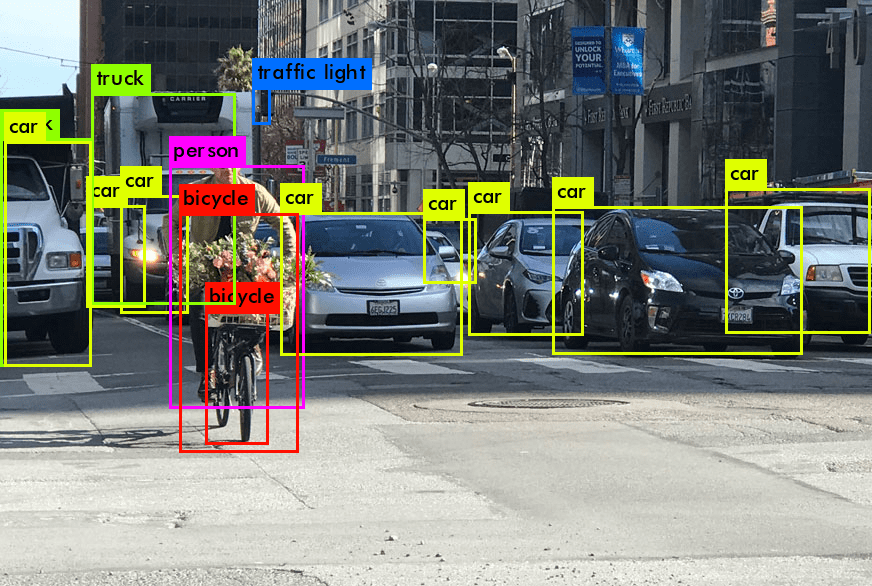
Introduction to Object Detection in Computer Vision
Using object detection, a fundamental computer vision task, has revolutionized how machines interpret the visual world. Unlike image classification, where the objective is to classify an entire image, object detection can be used to identify and locate objects within an image or video frame (which is the same as a image / picture). This process includes recognizing the specific object, object localization and object determining its position through a bounding box. Object detection bridges the gap between image classification and more complex tasks like image segmentation, where the goal is to label each pixel of the image as belonging to a particular single object.
The emergence of deep learning, particularly the use of Convolutional Neural Networks (CNNs), has significantly advanced object detection. These neural networks effectively process and analyze visual data, making them ideal for detecting objects in an image or video. Key developments like YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector), and region proposal-based networks like Mask R-CNN have further enhanced the accuracy and efficiency of object detection systems. These models can perform detection in real-time, a crucial factor for applications like autonomous driving or real-time surveillance.
Moreover, the integration of machine learning techniques has allowed object detection systems to classify and segment various objects in complex environments. This ability is vital for a range of applications, from pedestrian detection in smart city infrastructures to quality control in manufacturing.
Understanding the Dataset for Object Detection
The foundation of any successful object detection system lies in its dataset. A dataset for object detection consists of images or videos annotated to train a detector. These annotations typically include bounding boxes around objects and labels indicating the class of each object. The quality, diversity, and size of the dataset play a crucial role in the performance of object detection models. For instance, larger datasets with a wide variety of objects and scenarios enable the neural network to learn more robust and generalizable features.
Datasets like PASCAL VOC, MS COCO, and ImageNet have been instrumental in the advancement of object detection. They provide a vast range of annotated images, from everyday objects to specific scenarios, aiding in the development of versatile and accurate detection models. These datasets not only facilitate the training of models but also serve as benchmarks to evaluate and compare the performance of various object detection algorithms.
Training a model for object detection also involves using techniques like transfer learning, where a model pre-trained on a large dataset is fine-tuned with a smaller, specific dataset. This approach is particularly beneficial when the available data for object detection is limited or when training a model from scratch is computationally expensive.
In summary, the dataset is a crucial component in object detection, directly influencing the ability of a model to detect objects accurately in different contexts and environments. As related computer vision tasks and technology continues to evolve, the creation and refinement of datasets remain a key focus for researchers and practitioners in the field.
Exploring Object Detection Models: From Traditional to Deep Learning
Object detection is a computer vision task that has evolved significantly, especially with the advancement of deep learning technologies. Originally, object detection relied on simpler computer vision techniques and machine learning algorithms, where features for object classification were manually crafted and the models were trained to detect objects in images based on these features. The introduction of deep learning, particularly deep Convolutional Neural Networks (CNNs), revolutionized this field. CNNs automatically learn feature hierarchies from the data, enabling more accurate object detection and semantic segmentation. This transition to deep learning models marked a significant improvement in object detection capabilities.
Early CNN-based object detection models, such as R-CNN, employed a region proposal method to identify potential locations of objects in an image and then classified each region. Successors like Fast R-CNN and Faster R-CNN improved upon this by enhancing detection accuracy and processing speed. Further developments led to the introduction of Mask R-CNN, which extended the capabilities of its predecessors by adding a branch for pixel-level segmentation, facilitating detailed object localization and recognition.
YOLO: Revolutionizing Real-Time Object Detection
In the realm of real-time object detection, the YOLO (You Only Look Once) model represents a significant breakthrough. YOLO uniquely conceptualizes object detection as a single regression problem, directly predicting bounding box coordinates and class probabilities from the image pixels in one evaluation. This approach allows YOLO to achieve exceptional processing speeds, essential for applications requiring real-time detection such as pedestrian detection and vehicle tracking in smart cities.
YOLO’s architecture processes the entire image during training, allowing it to understand contextual information about object classes and their appearance. This contrasts with the region proposal-based methods, which might overlook some contextual details. The real-time processing capability of YOLO makes it indispensable in scenarios demanding fast and accurate object detection. The YOLO model family, including advanced versions like YOLOv3 and YOLOv4, has pushed the boundaries in terms of detection speed and accuracy, establishing YOLO as a state-of-the-art system in real-time object detection advancing all the way up to YOLOv8.
Object detection real-time video analytics on the drone while flying with visionplatform.ai and our NVIDIA Jetson Edge computer mounted on the drone. We turn ANY camera into an AI camera.
Key Components in Object Detection: Classification and Bounding Box
The introduction to object detection unveils two fundamental aspects: classification and the bounding box. Classification refers to identifying the object class (e.g., pedestrian, vehicle) in an image. It’s a critical step in distinguishing between different object categories within a detection system. The bounding box, on the other hand, involves locating the object within the image, usually represented by coordinates outlining the object. Together, these components form the basis of object detection and tracking.
Object detection can help models, such as the YOLO family of models and the Single Shot Multibox Detector (SSD), the combination of classification and bounding boxes ensures detection accuracy. These models, often developed and shared on platforms like GitHub, utilize deep learning-based approaches. They can also be used without a line of code on vision platforms like visionplatform.ai. They are capable of detecting multiple objects in an image and accurately predicting each object’s location with a bounding box around it. This dual approach is essential in various use cases of object detection, ranging from face detection in security systems to anomaly detection in industrial settings.
The Role of Deep Learning in Object Detection
Deep learning methods have revolutionized computer vision and object detection. These methods, primarily involving deep neural networks like CNNs, have enabled more accurate object detection and semantic segmentation. TensorFlow, a popular open-source library for machine learning and deep learning, offers robust tools to train and deploy deep learning models for object detection.
The effectiveness of deep learning in object detection can be observed in its application to complex tasks like pedestrian detection and text detection. These models learn feature hierarchies for accurate object detection, significantly improving over traditional machine learning algorithms that required hand-engineered features. Deep learning-based object detection models are typically evaluated according to their detection accuracy and speed, making them ideal for real-time applications.
With the advancement of deep learning techniques, object detection systems have become more versatile, capable of handling a wide range of computer vision tasks including object tracking, people detection, and image recognition. This advancement has led to the development of robust object detection algorithms that can reliably classify and localize objects, even in challenging environments.
Segmentation and Object Recognition: Enhancing Detection with Detailed Analysis
The introduction to object detection in computer vision often leads to the exploration of related tasks like segmentation and object recognition. Whereas object detection identifies and locates objects within an image, segmentation goes a step further by dividing the image into segments to simplify its analysis or change its representation. Object recognition, on the other hand, involves identifying the specific object present in the image.
Deep learning-based techniques, especially deep convolutional neural networks, have significantly advanced these areas. Segmentation, particularly semantic segmentation, is integral to understanding the context within which objects exist in images. This is crucial in use cases such as medical imaging, where precise identification of tissues or anomalies is essential. Object detection algorithms that include segmentation, like Mask R-CNN, provide detailed insights by not only locating the “bounding box around” an object but also delineating the exact “shape of the object.”
Processing the Input Image: The Journey through Object Detection Systems
The process of object detection begins with an input image, which undergoes several stages within a detection network. Initially, the image is preprocessed to fit the object detection model’s requirements. This can involve resizing, normalization, and augmentation. Following this, the image is fed into a deep learning model, typically a type of model like CNNs, for feature extraction.
The extracted features are then used to classify objects and predict their location. Object detection used in real-time scenarios, such as pedestrian detection or vehicle tracking, requires the model to quickly analyze the input image and provide accurate “predicted bounding boxes” for each “object is present.” This is where models like YOLO excel, offering fast and efficient processing suitable for real-time applications.
Training a model for such complex tasks involves a substantial amount of data for object detection. This data, usually comprising diverse images with annotated objects, helps the model learn various object categories and their characteristics. Popular object detection frameworks like TensorFlow offer tools and libraries to build, train, and deploy these models efficiently. The entire process highlights the synergy between computer vision and image processing techniques, machine learning algorithms, and deep learning methods, culminating in a robust object detection system.
Use Cases of Object Detection in Various Industries
Object detection, powered by deep learning-based models, has found applications across diverse industries, each with unique requirements and challenges. These models are typically evaluated according to their accuracy, speed, and ability to detect multiple objects under varying conditions. In the healthcare sector, object detection aids in identifying anomalies in medical imaging, significantly contributing to early diagnosis and treatment planning. In retail, it plays a vital role in customer behavior analysis and inventory management.
One notable use case of object detection is in the automotive industry, where it is crucial for the development of autonomous vehicles. Here, the ability to detect and differentiate between two objects, such as pedestrians and other vehicles, is paramount for safety. Object detection systems, using advanced algorithms and neural networks, enable these vehicles to navigate safely by accurately interpreting their surroundings.
TensorFlow in Object Detection: Leveraging Deep Learning Models
TensorFlow, an open-source framework available on platforms like GitHub, has become synonymous with building and deploying deep learning models, especially in the field of object detection. Its comprehensive library allows developers to build a model from scratch or use pre-trained models for object detection. TensorFlow’s flexibility in handling various object proposal mechanisms and its efficient processing of large datasets make it a preferred choice for many developers.
In object detection, the learning approach is critical. TensorFlow facilitates the implementation of complex algorithms that can differentiate ‘detection vs. classification’ tasks, essential for nuanced object detection scenarios. The platform supports a wide range of models, from those requiring intensive computational resources to lightweight models suitable for mobile devices. This adaptability ensures that TensorFlow-based models can be deployed in various environments, from server-based systems to edge devices such as the Jetson Nano Orin, Jetson NX orin or Jetson AGX orin, expanding the scope and accessibility of object detection technology.
Exploring the YOLO Model in Depth
The YOLO (You Only Look Once) model, a deep learning-based framework for object detection, represents a significant shift in the learning approach for detecting objects. Unlike traditional models where the system first proposes potential regions (object proposal) and then classifies each region, YOLO applies a single neural network to the full image, predicting bounding boxes and class probabilities for multiple objects in one evaluation. This approach, focusing on the entire image rather than on separate proposals, allows YOLO to detect objects in real-time effectively.
YOLO models are typically evaluated according to their speed and accuracy in detecting multiple objects. In scenarios where two objects are close together, YOLO’s ability to distinguish between them accurately is crucial. The model’s architecture enables it to understand the context within an image, making it robust in complex environments. This capability is a result of its unique network design, which looks at the entire image during prediction, thereby capturing contextual information that might be missed when focusing on parts of the image.
Data for Object Detection: Gathering and Utilization
The success of any object detection model, including those built on deep learning-based frameworks like YOLO, heavily relies on the quality and quantity of data used for training. The process to build a model for object detection starts with data collection, which involves gathering a diverse set of images and annotating them with labels and bounding boxes. This data collection is a critical step in training a model, as it provides the foundation for the model to learn from.
The data for object detection must encompass a wide variety of scenarios and object types to ensure that the model can generalize well to new, unseen images. This includes accounting for variations in object size, lighting conditions, and backgrounds. Annotated datasets available on platforms like GitHub offer a valuable resource for training and benchmarking object detection models.
In the learning approach for object detection, the model is trained to detect ‘object vs. no object’ and to classify the detected objects. This training involves not only recognizing the presence of an object but also precisely determining its location within the image. The use of advanced deep learning methods and large, annotated datasets has substantially increased the detection accuracy and reliability of object detection models, making them essential tools in various computer vision applications.
Detection vs. Recognition: Understanding the Differences
In the field of computer vision, it’s crucial to differentiate between ‘detection vs. recognition.’ Detection involves locating objects within an image, typically using bounding boxes, whereas recognition delves deeper, aiming to identify the specific nature or class of the detected objects. This distinction is important in tailoring computer vision systems for specific applications. For instance, while a detection system might be sufficient for counting cars on a road, a recognition system would be necessary to differentiate between car models.
The complexity of recognition tasks usually demands more sophisticated models compared to detection tasks. Recognition often involves not just identifying that an object is present but also classifying it into one of several possible categories. This process requires a more nuanced understanding of the object’s features and is crucial in scenarios where detailed identification is essential, such as differentiating between benign and malignant cells in medical imaging.
Conclusion and Future Trends in Object Detection
As we conclude, it’s evident that object detection is a rapidly evolving field, with new advancements continually emerging. Future trends are likely to focus on improving accuracy, speed, and the ability to handle more complex scenes. The integration of AI with other technologies like augmented reality and the Internet of Things (IoT) opens new horizons for object detection applications.
Moreover, the demand for more efficient and less data-intensive models is driving research towards few-shot learning and unsupervised learning approaches. These methods aim to train models effectively with limited data, addressing one of the significant challenges in the field. As technology progresses, we can anticipate more innovative solutions, enhancing the capabilities and applications of object detection in various sectors, from healthcare to autonomous vehicles.
The continuous refinement of models and algorithms in object detection will undoubtedly contribute to more sophisticated and accurate systems, cementing its importance in the realm of computer vision and beyond.
Object Detection FAQ: Understanding the Core Concepts
Dive into the essentials of object detection with our FAQ section. Here, we address common questions, clarifying how object detection works, its applications, and the technology behind it. Whether you’re new to computer vision or looking to refine your knowledge, these answers provide concise insights into the exciting world of object detection.
What is Object Detection?
Object detection is a computer vision solution that identifies and locates objects within an image or video. It not only recognizes the presence of objects but also pinpoints their positions with bounding boxes. The system assigns confidence levels to predictions, indicating the likelihood of accuracy. Object detection is distinct from image recognition, which assigns a class label to an image, and image segmentation, which identifies objects at the pixel level.
How Does Object Detection Work?
Object detection generally involves two stages: detecting potential object regions (Region of Interest, or RoI) and then classifying these regions. Deep learning-based approaches, especially using neural networks like Convolutional Neural Networks (CNNs), are common. Models like R-CNN, YOLO, and SSD first analyze the image to find RoIs and then classify each RoI into object categories, often using features learned during training on datasets like COCO or ImageNet.
What are the Types of Object Detection Models?
Popular object detection models include R-CNN and its variants (Fast R-CNN, Faster R-CNN, and Mask R-CNN), YOLO (You Only Look Once), SSD (Single Shot Multibox Detector), and CenterNet. These models differ in their approach to identifying RoIs and classifying them. R-CNN models use region proposals, while YOLO and SSD predict bounding boxes directly from the image, improving speed and efficiency.
What is the Difference Between Object Detection and Object Recognition?
Object detection and object recognition are distinct tasks. Object detection involves locating objects within an image and identifying their boundaries, typically with bounding boxes. Object recognition goes a step further by not only locating but also classifying the objects into predefined categories, like distinguishing between different types of animals, vehicles, or other items.
How are Object Detection Models Trained?
Training object detection models involves feeding a neural network with labeled images. These images are annotated with bounding boxes around objects and their corresponding class labels. The neural network learns to recognize patterns and features from these training images. The effectiveness of training depends on the diversity and size of the dataset, with larger, varied datasets leading to more accurate and generalizable models. Models are often trained using frameworks like TensorFlow or PyTorch.
What are the Uses of Object Detection?
Object detection is widely used in various fields. In security and surveillance, it aids in face detection and monitoring activities. In retail, it helps in analyzing customer behavior and managing inventories. In autonomous vehicles, it’s crucial for identifying obstacles and navigating safely. Object detection also finds applications in healthcare for identifying abnormalities in medical images, and in agriculture for crop and pest monitoring.
What is YOLO in Object Detection?
YOLO (You Only Look Once) is a popular object detection model known for its speed and efficiency. Unlike traditional models that process an image in parts, YOLO examines the entire image in a single pass, making it significantly faster. This makes it ideal for real-time object detection applications. YOLO has several versions, with YOLOv5 and YOLOv8 being the most recent, offering improvements in accuracy and speed.
How Accurate are Object Detection Models?
The accuracy of object detection models varies depending on their architecture and the quality of the training data. Models like YOLOv4 and YOLOv5 demonstrate high accuracy, often with precision rates above 90% in ideal conditions. The accuracy is measured using metrics like mAP (mean Average Precision) and IoU (Intersection over Union). The mAP for top models on standard datasets like MS COCO can be as high as 60-70%.
What is the Role of Convolutional Neural Networks in Object Detection?
Convolutional Neural Networks (CNNs) play a critical role in object detection, primarily in feature extraction. They process images through convolutional layers to learn and identify key features, which are crucial for detecting objects. Models like R-CNN, Faster R-CNN, and SSD utilize CNNs for their efficiency in handling image data, significantly enhancing the accuracy and speed of object detection.
How to Get Started with Building an Object Detection Model?
To start building an object detection model, first, define the objects you want to detect. Gather and annotate a dataset with images containing these objects. Use tools like TensorFlow or PyTorch to train a model on this dataset. Start with a simple architecture like SSD or YOLO for easier implementation. Experiment with different configurations and hyperparameters to optimize your model’s performance.