
Introduction
Connectionist Temporal Classification(CTC) Explained and RCNN + CTC based OCR Experiment
Optical Character Recognition (OCR) refers to handwritten or printed text in a wide range of backgrounds (e.g. documents, photo of document, and other background scenes) stored in a digital format. The research of OCR has been a classical issue in Computer Vision and Natural Language Processing field. With the development of artificial intelligence, the OCR algorithms are able to tackle with more and more complicated issues.
In most of the traditional visual classification tasks, the prediction results are binary or multi- class. A simple softmax is a common method of the categorical output function. CTC is a type of neural network output used for time series model dealing with sequential data, for example, RNN and LSTM.
Here are some major differences between traditional classification and time series based classification.
| Traditional classification | Time series based classification |
| Individual data points | Sequential data |
| Typically assign a single class output | A sequential of class, vary length |
| Loss that measure the different between predictions and ground truth, e.g. Cross-entropy | Specialised loss function that consider all possible alignments between input and output sequences |
One input at least has one output | In consistent input and output, accounting for possible repetitions and deletions |
So why do we need CTC in OCR? The OCR data is text in the vision format, which successes the feature of text data——sequential.
The CTC method explained
The image of the size [L× H]can be sliced into a series of image pieces.
x= {x1, x2, ⋯ , xl}
The output of sequential model is
y= {y1, y2, ⋯ , yl}
For xtxtin x, t is the position of the image pieces, n∈ [1, l].
xt= [xt,1, xt,2, ⋯ xt,h]T
Define the corresponding output ytof every xt, c is the class of predict characters.
yt= {yt,1, yt,2, ⋯ , yt,c}
You may notice that the inconsistency of dimension. How can we bridge between the 2- dimensional matrix [l× c] and the 1-dimensional output [l× 1]?
Encoding
Generally, there will be a sequential output series that greedily taking one predict character with highest probability.
l
π= argmaxπ∏ yt, πt
n=1
If you input an image contains “ac02” (classes: alphabet (26) and numbers(10)). Then, you will get a sequence output might looks like this:
π= {_aa_c_000_22}
π= {a__c_00__22}
Although the correct prediction classes, it doesn’t looks like the output sequence we want. We only want the label v= {ac02}. This valid character sequence vis the true prediction we acquire.
CTC is the algorithm that help deduce the label vfrom prediction π.
Decoding
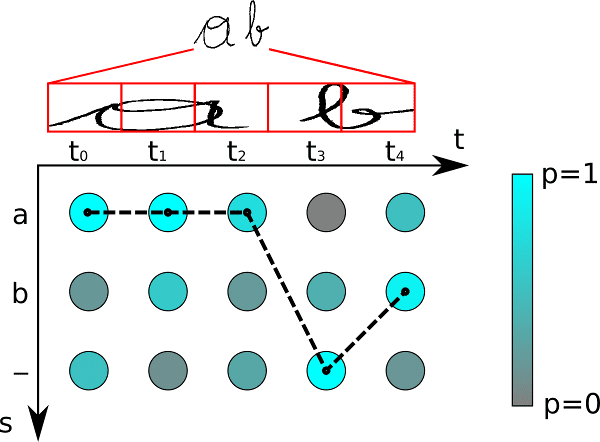
The decoding is a dynamic programming process that align the characters.
When training the algorithm, the ground truth label vis represent as {_a_c_0_2_}, where
the blank insert between the characters. As the example in the paper, the image shows the possible route with the arrows.
This decoding method greatly simplify the time complexity and easier to calculate the back propagation.
Prediction
After training the model, there are two common output schemes. Greedy search and beam search.
In this policy, the blue nodes represent the previous prediction, and the red nodes represent the possible extensions with highest 3 probability of being the next hypotheses. The final output would be the chain that has the highest overall probability.
Experiment: CRNN and CTC based OCR
We had an experiment on CRNN and CTC based OCR detection. The training set contains 20000 crops of text. The text is in the format of 2 alphabet characters and 2 numbers. All the possible combination are 26*26*10*10 = 67600, we sample 20000 among them without duplication. Then sample 2000 in the rest as the test set.
Because there is no semantic between each character, we will analysis on character wise. The model get the character test accuracy of 90.12. The confusion matrix is showing as follow:
The confusion matrix shows the prediction and ground truth situation, where ‘-’ means no prediction character. There is a small bug of the first row of the confusion matrix that there shouldn’t have any ‘-’ in ground truth.
First let’s take a look at alphabet . In alphabet prediction, the shape of each character seems more distinguish. ‘D’ is wrongly predict as ‘Q’ , and ‘Q’ is recognized as ‘O’ often. Since these letters look similar in many fonts, it is an acceptable result.
The number ‘6’ and ‘8’ are the pair that easily confused, ‘8’ is predicted as ‘9’ or ‘5’, and ‘8’ is also sometimes recognized as ‘6’ or ‘5’. In the current model, numbers seems more easier to be recognized as none. A possible reason for this circumstance could be explained with prediction policy. The letters are located the first two bits, if the chain route at this stage isn’t the optimal chain route among all the route, when it comes to the prediction of numbers, the chain route is already deviate from the best solution that predict the empty instead of a number.
Future work
CRNN and CTC based OCR is a classical method that performs for a decade. As the birth of res-net and transformer, they are widely used in novel OCR algorithms that be able to handle more complex scenes, which will be discussed in next article.
Reference
Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (ICML ’06). Association for Computing Machinery, New York, NY, USA, 369–376. https://doi.org/10.1145/1143844.1143891
B. Shi, X. Bai and C. Yao, “An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 11, pp. 2298-2304, 1 Nov. 2017, doi: 10.1109/TPAMI.2016.2646371.
Hannun, “Sequence Modeling with CTC”, Distill, 2017. https://distill.pub/2017/ctc/ https://zhuanlan.zhihu.com/p/35026742