
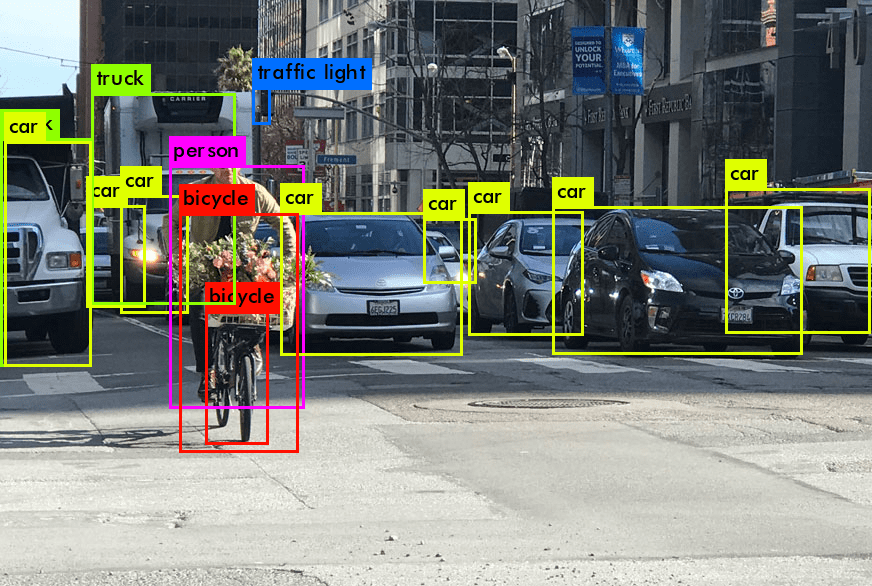
Introduction to Computer Vision and the YOLO Model
Computer vision, a field of artificial intelligence, aims to give machines the ability to interpret and understand the visual world. It involves capturing, processing, and analyzing images or videos to automate tasks that the human visual system can do. This rapidly evolving field encompasses various applications, from facial recognition and object tracking to more advanced activities like autonomous driving. The development of computer vision relies heavily on large datasets, sophisticated algorithms, and powerful computational resources.
A breakthrough in this field came with the development of the YOLO model (You Only Look Once). Designed as a state-of-the-art object detection model, YOLO revolutionized the approach to detecting objects in images. Traditional detection models often involved a two-step process: first identifying regions of interest and then classifying those regions. In contrast, YOLO innovated by predicting both the classifications and bounding boxes in one single pass through the neural network, significantly speeding up the process and improving real-time detection capabilities.
This object detection model has undergone several iterations, with each version introducing new features and enhancements. YOLOv8, the latest version from Ultralytics, builds upon the success of its predecessors like YOLOv5. It incorporates advanced machine learning techniques to improve accuracy and speed, making it a popular choice for computer vision tasks. The open-source nature of the YOLO models, such as the YOLOv8 repository on GitHub, has further contributed to their widespread adoption and continuous development.
YOLO’s effectiveness in object detection, instance segmentation, and classification tasks has made it a staple in computer vision projects. By simplifying the process of identifying and categorizing objects within images, YOLO models like YOLOv8 help machines understand the visual world more accurately and efficiently.
YOLOv8: The New State-of-the-Art in Computer Vision
YOLOv8 represents the pinnacle of progress in the realm of computer vision, standing as the new state-of-the-art in object detection models. Developed by Ultralytics, this version of the YOLO model series brings forth significant advancements over its predecessor, YOLOv5, and earlier YOLO versions. YOLOv8 comes equipped with a range of new features that enhance its detection capabilities, making it more accurate and efficient than ever before.
One of the notable advancements in YOLOv8 is its adoption of anchor-free detection. This new approach diverges from the traditional reliance on anchor boxes, which were a staple in earlier YOLO models. Anchor-free detection simplifies the model’s architecture and improves its ability to predict object locations more accurately. This enhancement is particularly beneficial in scenarios where the dataset includes objects with varying shapes and sizes.
The YOLOv8 model also excels in segmentation tasks, a critical aspect of computer vision. Whether it’s for object detection or instance segmentation or more general segmentation models, YOLOv8, especially the YOLOv8 Nano model, demonstrates a remarkable proficiency. Its ability to precisely segment and classify different parts of an image makes it highly effective in diverse applications, from medical imaging to autonomous vehicle navigation.
Another key aspect of YOLOv8 is its Python package, which facilitates easy integration and use in Python-based projects. This accessibility is crucial, especially considering Python’s popularity in the data science and machine learning communities. Developers can train a YOLOv8 model on a custom dataset using PyTorch, a leading deep learning framework. This flexibility allows for tailored solutions to specific computer vision challenges.
The performance of YOLOv8 is further boosted by its state-of-the-art model performance metrics. These metrics showcase the model’s ability to detect objects with high accuracy and speed, crucial factors in real-time applications. Additionally, as an open-source model available on GitHub, YOLOv8 benefits from continuous improvements and contributions from the global developer community.
In conclusion, YOLOv8 sets a new benchmark in the field of computer vision. Its advancements in object detection, segmentation, and overall model performance make it an invaluable tool for developers and researchers looking to push the boundaries of what’s possible in AI-driven visual interpretation.
YOLOv8 Architecture: The Backbone of New Computer Vision Advances
The YOLOv8 architecture represents a significant leap in the field of computer vision, setting a new state-of-the-art standard. As the latest version of YOLO, YOLOv8 introduces several enhancements over its predecessors, like YOLOv5 and previous YOLO versions. Understanding the YOLOv8 architecture is crucial for those looking to train the model for specialized object detection tasks.
One of the pivotal features of YOLOv8 is its anchor-free detection head, a departure from the traditional anchor box approach used in earlier versions of YOLO. This change simplifies the model while maintaining, and in many cases enhancing, accuracy in detecting objects. YOLOv8 supports a diverse range of applications, from real-time object detection to image segmentation.
The YOLOv8 model is designed for efficiency and performance. The open source YOLOv8 model can be trained on various datasets, including the widely-used COCO dataset. This flexibility allows users to tailor the model for specific needs, whether for general object detection or specialized tasks like pose estimation.
YOLOv8’s architecture is optimized for both speed and accuracy, a crucial factor in real-time applications. The model’s design also includes improvements in image segmentation, making it a comprehensive detection and image segmentation model. The Ultralytics YOLO series, particularly YOLOv8, has always been at the forefront of advancing computer vision models, and YOLOv8 continues this tradition.
For those looking to get started with YOLOv8, the Ultralytics repository provides ample resources. The repository, available on GitHub, offers detailed instructions on how to train the YOLOv8 model, including setting up the training environment and loading model weights.
YOLOv8 Object Detection Model: Revolutionizing Detection and Segmentation
The YOLOv8 object detection model is the newest addition to the YOLO series, created by Joseph Redmon and Ali Farhadi. It stands at the forefront of the field of computer vision advances, embodying the new state-of-the-art in both object detection and image segmentation. YOLOv8’s capabilities extend beyond mere object detection; it also excels in tasks like instance segmentation and real-time detection, making it a versatile tool for a variety of applications.
YOLOv8 uses an innovative approach to detection, integrating features that make it a highly accurate object detector. The model incorporates an anchor-free detection head, which streamlines the detection process and enhances accuracy. This is a significant shift from the anchor box method used in previous YOLO versions.
YOLOv8 training model is a straightforward process, especially with the resources provided in the YOLOv8 GitHub repository. The repository includes detailed instructions on how to train the model using a custom dataset, enabling users to tailor the model to their specific needs. For instance, training models on a dataset for 100 epochs can yield significantly improved model performance, as evidenced by evaluations on the validation set.
Moreover, YOLOv8’s architecture is designed to support object detection and image segmentation tasks effectively. This versatility is evident in its application across various domains, from surveillance to autonomous driving. YOLOv8 introduces new features that enhance its efficiency, such as improvements in the last ten training epochs, which optimize the model’s learning and accuracy.
In summary, YOLOv8 represents a significant advancement in the YOLO series and the broader field of computer vision. Its state-of-the-art architecture and features make it an ideal choice for developers and researchers looking to implement advanced detection and segmentation models in their projects. The Ultralytics repository is an excellent starting point for anyone interested in exploring the capabilities of YOLOv8 and deploying it in real-world scenarios.
YOLOv8 Annotation Format: Preparing Data for Training
Preparing data for training is a critical step in the development of any computer vision model, and YOLOv8 is no exception. The YOLOv8 annotation format plays a pivotal role in this process, as it directly influences the model’s learning and accuracy. Proper annotation ensures that the model can correctly identify and learn from the various elements within a dataset, which is crucial for effective object detection and image segmentation.
The YOLOv8 annotation format is unique and distinct from other formats used in computer vision. It requires precise detailing of objects in images, typically through bounding boxes and labels. Each object in an image is marked with a bounding box, and these boxes are labeled with classes that the model needs to identify. This format is critical for training the YOLOv8 model, as it helps the model understand the location and category of each object within an image.
Preparing a dataset for YOLOv8 involves annotating a large number of images, which can be a time-consuming process. However, the effort is essential for achieving high model performance. The quality and accuracy of annotations directly impact the model’s ability to learn and make accurate predictions.
For those looking to train a YOLOv8 model, understanding and implementing the correct annotation format is key. This process typically involves using specialized annotation tools that allow users to draw bounding boxes and label them appropriately. The annotated dataset is then used to train the model, teaching it to recognize and categorize objects based on the provided labels and bounding box coordinates.
Training YOLOv8: A Step-by-Step Guide
YOLOv8n training is a process that requires careful preparation and execution to achieve optimal model performance. The training process involves several steps, from setting up the environment to fine-tuning the model on a specific dataset. Here is a step-by-step guide to training YOLOv8:
- Environment Setup: The first step is to set up the training environment. This involves installing the necessary software and dependencies. YOLOv8, being a Python-based model, requires a Python environment with libraries such as PyTorch.
- Data Preparation: Next, prepare your dataset according to the YOLOv8 annotation format. This involves annotating images with bounding boxes and labels to define the objects that the model needs to learn to detect.
- Configuring the Model: Before training begins, configure the YOLOv8 model according to your requirements. This might involve adjusting parameters like the learning rate, batch size, and the number of epochs.
- Training the Model: With the environment and data set up, you can start the training process. This involves feeding the annotated dataset to the model and allowing it to learn from the data. The model iteratively adjusts its weights and biases to minimize errors in detection.
- Evaluating Performance: After training, evaluate the model’s performance using metrics such as precision, recall, and mean Average Precision (mAP). This helps to understand how well the model can detect and classify objects in images.
- Fine-Tuning: Based on the evaluation, you might need to fine-tune the model. This could involve retraining the model with adjusted parameters or providing it with additional training data.
- Deployment: Once the model is trained and fine-tuned, it’s ready for deployment in real-world applications.
Training a YOLOv8 model requires attention to detail and a deep understanding of how the model works. However, the effort pays off with a robust, accurate, and efficient object detection model suitable for various applications in computer vision.
Deploying YOLOv8 in Real-World Applications
Deploying YOLOv8 in real-world applications is a critical step in leveraging its advanced object detection capabilities. Successful deployment translates the model’s theoretical proficiency into practical, actionable solutions across various industries. Here’s a comprehensive guide to deploying YOLOv8:
- Choosing the Right Platform: The first step is to decide where the YOLOv8 model will be deployed. This could range from cloud-based servers for large-scale applications to edge devices for real-time, on-site processing like the end-end computer vision platform solution of visionplatform.ai.
- Optimizing the Model: Depending on the deployment platform, it might be necessary to optimize the YOLOv8 model for performance. Techniques like model quantization or pruning can be used to reduce the model size without significantly compromising accuracy, making it suitable for devices with limited computing resources.
- Integration with Existing Systems: In many cases, the YOLOv8 model will need to be integrated into existing software or hardware systems. This requires a thorough understanding of these systems and the ability to interface the YOLOv8 model using appropriate APIs or software frameworks.
- Testing and Validation: Before full-scale deployment, it’s crucial to test the model in a controlled environment to ensure it performs as expected. This involves validating the model’s accuracy, speed, and reliability under different conditions.
- Deployment and Monitoring: Once tested, deploy the model to the chosen platform. Continuous monitoring is essential to ensure the model operates correctly and efficiently over time. This also helps in identifying and rectifying any issues that may arise post-deployment.
- Updates and Maintenance: Like any software, the deployed YOLOv8 model might require periodic updates for improvements or to address new challenges. Regular maintenance ensures the model remains effective and secure.
Deploying YOLOv8 effectively demands a strategic approach, considering factors like the operational environment, computational limitations, and integration challenges. When done right, YOLOv8 can significantly enhance the capabilities of systems across sectors like security, healthcare, transportation, and retail.
YOLOv8 vs YOLOv5: Comparing Object Detection Models
Comparing YOLOv8 and YOLOv5 is essential to understand the advancements in object detection models and to decide which model is more suited for a specific application. Both models are state-of-the-art in their capabilities, but they have distinct features and performance metrics.
- Model Architecture: YOLOv8 introduces several architectural improvements over YOLOv5. These include enhancements in the detection layers and the integration of new technologies like anchor-free detection, which improves the model’s accuracy and efficiency.
- Accuracy and Speed: YOLOv8 has shown improvements in accuracy and detection speed compared to YOLOv5. This is particularly evident in challenging detection scenarios involving small or overlapping objects.
- Training and Flexibility: Both models offer flexibility in training, allowing users to train on custom datasets. However, YOLOv8 provides more advanced features for fine-tuning the model, which can lead to better performance on specific tasks.
- Application Suitability: While YOLOv5 remains a powerful option for many applications, YOLOv8’s advancements make it better suited for scenarios where maximum accuracy and speed are crucial.
- Community and Support: Both models benefit from strong community support and are widely used, ensuring continuous improvement and extensive resources for developers.
In conclusion, while YOLOv5 remains a robust and efficient model for object detection, YOLOv8 represents the latest advancements in the field, offering improved accuracy and performance. The choice between the two depends on the specific requirements of the application, including factors like computational resources, the complexity of the detection task, and the need for real-time processing.
Exploring the Variants of YOLO Models
The YOLO (You Only Look Once) series encompasses a range of models tailored for various applications in object detection, each differing in size, speed, and accuracy. From the lightweight YOLOv8n model, designed for edge devices, to the highly accurate YOLOv8x, suitable for in-depth research, these variants cater to diverse computing environments and application requirements. This exploration provides an overview of the different types of YOLO models, highlighting their unique characteristics and optimal use cases.
| Attribute / Model | YOLOv8n (Nano) | YOLOv8s (Small) | YOLOv8m (Medium) | YOLOv8l (Large) | YOLOv8x (X-Large) | |
|---|---|---|---|---|---|---|
| Size | Very Small | Small | Medium | Large | Very Large | |
| Speed | Very Fast | Fast | Moderate | Slow | Very Slow | |
| Accuracy | Lower | Moderate | High | Very High | Highest | |
| mAP (COCO) | ~30% | ~40% | ~50% | ~60% | ~70% | |
| Resolution | 320×320 | 640×640 | 640×640 | 640×640 | 640×640 |
Comparing Yolo from previous models such as YOLOv5, YOLOv6, YOLOv7 and YOLOv8 shows that YOLOv8 is both better and faster then it’s previous versions.
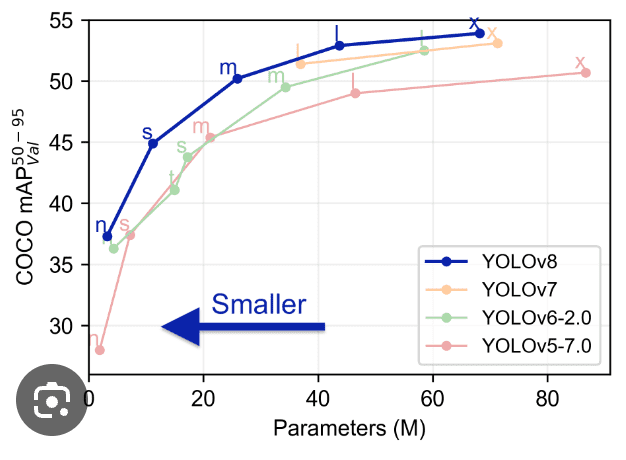
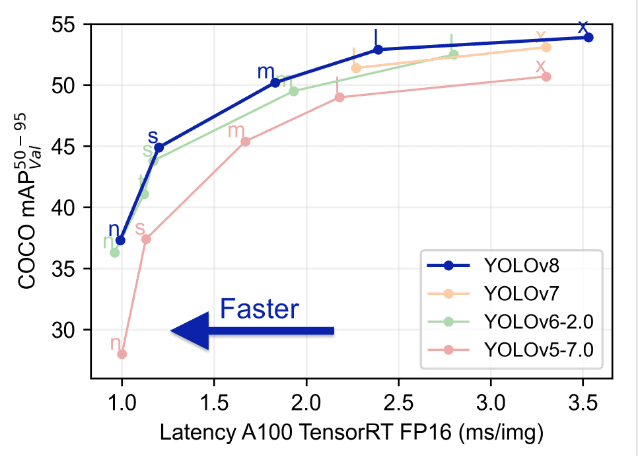
Advanced Features in YOLOv8: Enhancing Model Performance
YOLOv8’s model performance stands out in the field of computer vision, thanks to a suite of advanced features that enhance its capabilities. These features contribute significantly to YOLOv8’s status as a state-of-the-art model for object detection and segmentation tasks. A deep dive into these features reveals why YOLOv8 is a top choice for developers and researchers:
- Anchor-Free Detection: YOLOv8 moves away from traditional anchor boxes to an anchor-free detection system. This simplifies the model’s architecture, including the YOLOv8 Nano model and improves its ability to accurately predict object locations, especially for images with diverse object shapes and sizes.
- Enhanced Convolutional Layers: YOLOv8 introduces changes to its convolutional blocks, replacing the previous
6x6convolutions with3x3ones. This shift enhances the model’s ability to extract and learn detailed features from images, improving its overall detection accuracy. - Mosaic Data Augmentation: Unique to YOLOv8 is the implementation of mosaic data augmentation during training. This technique stitches together four different images, enhancing the model’s ability to detect objects in varied contexts and backgrounds. However, YOLOv8 strategically turns off this augmentation in the last ten training epochs to optimize performance.
- PyTorch Integration: As a Python package, YOLOv8 benefits from seamless integration with PyTorch, a leading framework in machine learning. This integration simplifies the process of training and deploying the model, especially when working with custom datasets.
- Multi-Scale Object Detection: YOLOv8’s architecture is designed for multi-scale object detection. This feature allows the model to detect objects of varying sizes within an image accurately, making it versatile across different application scenarios.
- Real-Time Processing Capabilities: One of the most significant advantages of YOLOv8 is its ability to perform real-time object detection. This feature is crucial for applications requiring immediate analysis and response, such as autonomous driving and real-time surveillance.
These advanced features underscore YOLOv8’s capability as a powerful tool in the realm of computer vision. Its blend of accuracy, speed, and flexibility makes it an excellent choice for a broad spectrum of object detection and segmentation applications.
Getting Started with YOLOv8: From Setup to Deployment
Getting started with YOLOv8, especially for those new to the field of computer vision, can seem daunting. However, with the right guidance, setting up and deploying YOLOv8 can be a streamlined process. Here’s a step-by-step guide to getting started with YOLOv8:
- Understanding the Basics: Before diving into YOLOv8, it’s crucial to have a basic understanding of computer vision concepts and the principles behind object detection models. This foundational knowledge will aid in comprehending how YOLOv8 operates.
- Setting Up the Environment: The first technical step involves setting up the programming environment. This includes installing Python, PyTorch, and other necessary libraries. The YOLOv8 documentation provides detailed guidance on the setup process.
- Accessing YOLOv8 Resources: The YOLOv8 GitHub repository is a valuable resource. It contains the model’s code, pre-trained weights, and extensive documentation. Familiarizing yourself with these resources is crucial for a successful implementation.
- Training the Model: To train YOLOv8, you need a dataset. For beginners, using a standard dataset like COCO is advisable. The training process involves fine-tuning the model on your specific dataset to optimize its performance for your application.
- Evaluating the Model: After training, evaluate the model’s performance using standard metrics like precision, recall, and mean Average Precision (mAP). This step is crucial to ensure the model is accurately detecting objects.
- Deployment: With a trained and tested model, such as the YOLOv8 Nano model, the next step is deployment. This could be on a server for web-based applications or on an edge device for real-time processing using visionplatform.ai.
- Continuous Learning: The field of computer vision is rapidly evolving. Staying updated with the latest advancements and continually learning is key to effectively using YOLOv8 that you do effecitvly via a computer vision platform.
Starting with YOLOv8 involves a blend of theoretical understanding and practical application. By following these steps, one can successfully implement and utilize YOLOv8 in various computer vision tasks, harnessing its full potential in object detection and image segmentation.
The Future of Computer Vision: What’s New in YOLOv8 and Beyond
The future of computer vision is incredibly promising, with YOLOv8 leading the charge as the latest and most advanced model in the YOLO series. YOLOv8’s introduction marks a significant milestone in the ongoing evolution of computer vision technologies, offering unprecedented accuracy and efficiency in object detection tasks. Here’s what’s new in YOLOv8 and the implications for the future of computer vision:
- Technological Advancements: YOLOv8 has introduced several technological enhancements over its predecessors. These include more efficient convolutional networks, anchor-free detection, and improved algorithms for real-time object detection.
- Increased Accessibility and Application: With YOLOv8, the field of computer vision becomes more accessible to a broader range of users, including those without extensive coding expertise. This democratization of technology fosters innovation and encourages diverse applications across various sectors.
- Integration with Emerging Technologies: YOLOv8’s compatibility with advanced machine learning frameworks and its ability to integrate with other cutting-edge technologies, like augmented reality and robotics, signal a future where computer vision solutions are increasingly versatile and powerful.
- Enhanced Performance Metrics: YOLOv8 has set new benchmarks in model performance, particularly in terms of accuracy and processing speed. This improvement is crucial for applications requiring real-time analysis, such as autonomous vehicles and smart city technologies.
- Predictions for Future Developments: Looking ahead, we can anticipate further advancements in computer vision models, with even greater accuracy, speed, and adaptability. The integration of AI with computer vision will likely continue to evolve, leading to more sophisticated and autonomous systems.
The continuous development of YOLOv8 and similar models is a testament to the dynamic nature of the field of computer vision. As technology advances, we can expect to see more groundbreaking innovations that will redefine the limits of what computer vision systems can achieve.
Conclusion: The Impact of YOLOv8 on Computer Vision and AI
In conclusion, YOLOv8 has made a substantial impact on the field of computer vision and AI. Its advanced features and capabilities represent a significant leap forward in object detection technology. The implications of YOLOv8’s advancements extend beyond the technical realm, influencing various industries and applications:
- Advancements in Object Detection: YOLOv8 has set a new standard in object detection with its improved accuracy, speed, and efficiency. This has implications for a wide range of applications, from security and surveillance to healthcare, manufacturing, logistics and environmental monitoring.
- Democratization of AI Technology: By making advanced computer vision technology like the YOLOv8 repository more accessible and user-friendly, YOLOv8 has opened the door for a wider range of users and developers to innovate and create AI-driven solutions.
- Enhanced Real-World Applications: The practical applications of YOLOv8 in real-world scenarios are vast. Its ability to provide accurate, real-time object detection makes it an invaluable tool in areas like autonomous driving, industrial automation, and smart city initiatives.
- Inspiring Future Innovations: YOLOv8’s success serves as an inspiration for future developments in computer vision and AI. It sets the stage for further research and innovation, pushing the boundaries of what these technologies can achieve.
In summary, YOLOv8 has not only advanced the technical aspects of computer vision but also contributed to the broader evolution of AI. Its impact is seen in the enhanced capabilities of AI systems and the new possibilities it opens for innovation and practical application across diverse fields. As we continue to explore the potential of AI and computer vision, YOLOv8 will undoubtedly be remembered as a milestone in this journey of technological advancement.
Frequently Asked Questions About YOLOv8
As YOLOv8 continues to revolutionize the field of computer vision, numerous questions arise regarding its capabilities, applications, and technical aspects. This FAQ section aims to provide clear, concise answers to some of the most common queries about YOLOv8. Whether you’re a seasoned developer or just starting out, these answers will help deepen your understanding of this state-of-the-art object detection model.
What is YOLOv8 and how does it differ from previous YOLO versions?
YOLOv8 is the latest iteration in the YOLO series of real-time object detectors, offering top-tier performance in terms of accuracy and speed. It builds on the advancements of previous versions like YOLOv5 with improvements including advanced backbone and neck architectures, an anchor-free split Ultralytics head for enhanced accuracy, and an optimal balance between accuracy and speed for real-time object detection. It also provides a range of pre-trained models for different tasks and performance requirements.
How does the anchor-free detection in YOLOv8 enhance object detection?
YOLOv8 adopts an anchor-free detection approach, predicting object centers directly, which simplifies the model architecture and improves accuracy. This method is particularly effective in detecting objects of various shapes and sizes. By reducing the number of box predictions, it speeds up the Non-Maximum Suppression process, crucial for refining detection results, making YOLOv8 more efficient and accurate compared to its predecessors that used anchor boxes.
What are the key innovations and improvements in YOLOv8’s architecture?
YOLOv8 introduces several significant architectural innovations, including the CSPNet backbone for efficient feature extraction and the PANet head, enhancing robustness against object occlusion and scale variations. Its mosaic data augmentation during training exposes the model to a wider array of scenarios, enhancing its generalizability. YOLOv8 also combines supervised and unsupervised learning, contributing to its enhanced detection performance in object detection and instance segmentation tasks.How can I get started with using YOLOv8 for my object detection tasks?
To start using YOLOv8, you should first install the YOLOv8 Python package. Then, in your Python script, import the YOLOv8 module, create an instance of the YOLOv8 class, and load the pre-trained weights. Next, use the detect method to perform object detection on an image. The results will contain information about detected objects, including their classes, confidence scores, and bounding box coordinates.
What are some practical applications of YOLOv8 in different industries?
YOLOv8 has versatile applications across various industries due to its high speed and accuracy. In autonomous vehicles, it assists in real-time object identification and classification. It’s used in surveillance systems for real-time object detection and recognition. Retailers utilize YOLOv8 for analyzing customer behavior and managing inventory. In healthcare, it aids in detailed medical image analysis, improving diagnostics and patient care.
How does YOLOv8 perform on the COCO dataset and what does this mean for its accuracy?
YOLOv8 demonstrates remarkable performance on the COCO dataset, a standard benchmark for object detection models. Its mean average precision (mAP) varies by model size, with the largest model, YOLOv8x, achieving the highest mAP. This highlights significant improvements in accuracy compared to previous YOLO versions. The high mAP indicates superior accuracy in detecting a wide range of objects under various conditions.
What are the limitations of YOLOv8, and are there scenarios where it might not be the best choice?
Despite its impressive performance, YOLOv8 has limitations, particularly in supporting models trained at high resolutions like 1280. For applications requiring high-resolution inference, YOLOv8 may not be ideal. However, for most applications, it outperforms previous models in accuracy and performance. Its anchor-free detections and improved architecture make it suitable for a wide range of computer vision projects.
Can I train YOLOv8 on a custom dataset, and what are some tips for effective training?
Yes, YOLOv8 can be trained on custom datasets. Effective training involves experimenting with data augmentation techniques, notably mosaic augmentation, and optimizing hyperparameters like learning rate, batch size, and number of epochs. Regular evaluation and fine-tuning are crucial to maximize performance. Choosing the right dataset and training regimen is key to ensuring the model generalizes well to new data.
What are the key steps to deploy YOLOv8 in a real-world environment? Deploying
YOLOv8 involves optimizing the model for the target platform, integrating it into existing systems, and testing for accuracy and reliability. Continuous monitoring post-deployment ensures efficient operation. For edge devices, model optimization might include quantization or pruning. Regular updates and maintenance are essential to keep the model effective and secure in various applications.
What does the future look like for YOLOv8 and its applications in computer vision?
The future of YOLOv8 in computer vision looks promising, with potential for even greater accuracy, speed, and versatility. Its evolving technology including object detection and instance segmentation could find new applications in areas like medical imaging, wildlife conservation, and more advanced autonomous systems. Continuous research and development efforts are likely to push the boundaries of YOLOv8, further solidifying its position as a leading object detection model.